







做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
d
[
i
]
d[i]
d[i],就不必往下搜索了(因为即便继续往后枚举,能够得到的解必定不会比之前更长);反之,则需要更新
d
[
i
]
d[i]
d[i] 的值。
- 如图二-3-1,红色路径表示第一次搜索得到的一个最长子序列1、2、3、5,蓝色路径表示第二次搜索,当枚举第3个元素取的情况时,发现以第3个数结尾的最长长度
d
[
3
]
=
3
d[3] = 3
d[3]=3,比本次枚举的长度要大(本次枚举的长度为2),所以放弃往下枚举,大大减少了搜索的状态空间。

图二-3-1
- 这时候,我们其实已经不经意间设计好了状态,就是上文中提到的那个
d
[
i
]
d[i]
d[i] 数组,它表示的是以
a
[
i
]
a[i]
a[i] 结尾的最长单调子序列的长度,那么对于任意的
i
i
i,
d
[
i
]
d[i]
d[i] 一定等于
d
[
j
]
1
(
j
<
i
)
d[j] + 1 \ ( j < i )
d[j]+1 (j<i),而且还得满足
a
[
j
]
<
a
[
i
]
a[j] < a[i]
a[j]<a[i]。因为这里的
d
[
i
]
d[i]
d[i] 表示的是最长长度,所以
d
[
i
]
d[i]
d[i] 的表达式可以更加明确,即:
d
[
i
]
=
m
a
x
(
d
[
j
]
∣
j
<
i
,
a
[
j
]
<
a
[
i
]
)
1
d[i] = max ( d[j] | j < i, a[j] < a[i] ) + 1
d[i]=max(d[j]∣j<i,a[j]<a[i])+1
- 这个表达式很好的阐释了最优化原理,其中
d
[
j
]
d[j]
d[j] 作为
d
[
i
]
d[i]
d[i] 的子问题,
d
[
i
]
d[i]
d[i] 最长(优)当且仅当
d
[
j
]
d[j]
d[j] 最长(优)。当然,这个方程就是这个问题的状态转移方程。状态总数量
O
(
n
)
O(n)
O(n), 每次转移需要用到前
i
i
i 项的结果,平摊下来也是
O
(
n
)
O(n)
O(n) 的, 所以该问题的时间复杂度是
O
(
n
2
)
O(n^2)
O(n2)。
4、决策和无后效性
- 一个状态演变到另一个状态,往往是通过“决策”来进行的。有了“决策”,就会有状态转移。而无后效性,就是一旦某个状态确定后,它之前的状态无法对它之后的状态产生“效应”(影响)。
【例题4】老王想在未来的
n
n
n 年内每年都持有电脑,
m
(
y
,
z
)
m(y, z)
m(y,z) 表示第
y
y
y 年到第
z
z
z 年的电脑维护费用,其中
y
y
y 的范围为
[
1
,
n
]
[1, n]
[1,n],
z
z
z 的范围为
[
y
,
n
]
[y, n]
[y,n],
c
c
c 表示买一台新的电脑的固定费用。 给定矩阵
m
m
m,固定费用
c
c
c,求在未来
n
n
n 年都有电脑的最少花费。
- 考虑第
i
i
i 年是否要换电脑,换和不换是不一样的决策,那么我们定义一个二元组
(
a
,
b
)
(a, b)
(a,b),其中
a
<
b
a < b
a<b,它表示了第 a 年和第 b 年都要换电脑(第 a 年和第 b 年之间不再换电脑),如果假设我们到第 a 年为止换电脑的最优方案已经确定,那么第 a 年以前如何换电脑的一些列步骤变得不再重要,因为它并不会影响第 b 年的情况,这就是无后效性。
- 接下来,会对这题进行一个详细的解释,当然看不懂没关系,可以跳过这个步骤,直接去看 第三章 - 动态规划的经典模型。毕竟,本文是入门级别的,后面还会花更多的时间来讲解动态规划的内容,可以和搜索一起逐步理解状态的概念。
- 更加具体得,令
d
[
i
]
d[i]
d[i] 表示在第 i 年买了一台电脑的最小花费(由于这台电脑能用多久不确定,所以第 i 年的维护费用暂时不计在这里面),如果上一次更换电脑的时间在第 j 年,那么第 j 年更换电脑到第 i 年之前的总开销就是
c
m
(
j
,
i
−
1
)
c + m(j, i-1)
c+m(j,i−1)
- 于是有状态转移方程:
d
[
i
]
=
m
i
n
(
d
[
j
]
m
(
j
,
i
−
1
)
∣
1
<
=
j
<
i
)
c
d[i] = min( d[j] + m(j, i-1) | 1 <= j < i ) + c
d[i]=min(d[j]+m(j,i−1)∣1<=j<i)+c
- 这里的
d
[
i
]
d[i]
d[i] 并不是最后问题的解,因为它漏算了第 i 年到第 n 年的维护费用,所以最后问题的答案:
a
n
s
=
m
i
n
(
d
[
i
]
m
(
i
,
n
)
∣
1
<
=
i
<
n
)
ans = min( d[i] + m(i, n) | 1 <= i < n )
ans=min(d[i]+m(i,n)∣1<=i<n)
- 我们发现两个方程看起来很类似,其实是可以合并的,我们可以假设第 n+1 年必须换电脑,并且第 n+1 年换电脑的费用为 0,那么整个阶段的状态转移方程就是:
d
[
i
]
=
m
i
n
(
d
[
j
]
m
(
j
,
i
−
1
)
∣
1
<
=
j
<
i
)
w
(
i
)
d[i] = min( d[j] + m(j, i-1) | 1 <= j < i ) + w(i)
d[i]=min(d[j]+m(j,i−1)∣1<=j<i)+w(i)
w
(
i
)
=
{
c
i
<
n
1
0
i
=
n
1
w(i) = \begin{cases} c & i < n+1\ 0 & i=n+1 \end{cases}
w(i)={c0i<n+1i=n+1
- d
[
n
1
]
d[n+1]
d[n+1] 就是我们需要求的最小费用了。
三、动态规划的经典模型
- 本章节作者会通过图的方式,带读者了解一些基本模型,以加深对动态规划状态的理解;
- 黄色 ■ 代表当前状态;
- 绿色 ■ 代表子状态(已经求出的状态);
- 红色 ■ 代表尚未求出的状态;
- 灰色 ■ 代表永远不存在的状态;
1、线性模型
- 线性模型是动态规划中最常见的模型,上文讲到的最长单调子序列就是经典的线性模型。
- 线性模型的状态一般是通过 一维数组表示的,如图三-1-1所示,图中黄色块的状态为
d
[
i
]
d[i]
d[i],绿色块的状态为
d
[
j
]
d[j]
d[j],并且满足
(
j
<
i
)
(j < i)
(j<i),只有当
d
[
j
]
d[j]
d[j] 全部计算出来以后,
d
[
i
]
d[i]
d[i]的值才能够被确定。

图三-1-1
- 线性模型最经典的问题莫过于 背包问题 了,有关背包问题的内容,可以参考以下这篇文章:夜深人静写算法(十九)- 背包总览。
2、区间模型
- 对比线性模型,区间模型状态一般是通过:一个二维数组来表示的。
- 区间模型的状态表示一般为
d
[
i
]
[
j
]
d[i][j]
d[i][j],表示区间
[
i
,
j
]
[i, j]
[i,j] 上的最优解,最终要求的肯定是
[
1
,
n
]
[1, n]
[1,n] 的最优解。
- 如图三-2-1所示,既然是表示区间,所以对于状态
d
[
i
]
[
j
]
d[i][j]
d[i][j],当
i
j
i>j
i>j时,肯定是不合法的状态,所以标记为灰色;
d
[
i
]
[
j
]
d[i][j]
d[i][j] 表当前状态,标记为黄色;

图三-2-1
- 区间模型的详细内容可以参考以下这篇文章:夜深人静写算法(二十七)- 区间DP。
3、树状模型
- 树形动态规划(树形DP),是指状态图是一棵树,状态转移也发生在树上,父结点的状态值通过所有子结点状态值计算完毕后得出,后续会专门开辟一个章节来讲述树形动态规划。
- 状态表示如图三-3-1所示。

图三-3-1
4、状态压缩模型
- 状态压缩的含义其实是对状态进行重新编码,来看下面这个例子。
- 假设状态是一个五维的数组,并且每一维的取值为
[
0
,
3
]
[0,3]
[0,3],状态表示如下:
d
[
a
]
[
b
]
[
c
]
[
d
]
[
e
]
(
0
<
=
a
,
b
,
c
,
d
,
e
<
=
3
)
d[a][b][c][d][e] \ (0 <= a,b,c,d,e <= 3)
d[a][b][c][d]e
- 那么,写代码的过程中需要操作五维数组,十分繁琐,我们可以通过将状态压缩,将它重新编码到一个一维数组中。
- 其实只要能够找到一个映射函数,满足
x
x
x 和
(
a
,
b
,
c
,
d
,
e
)
(a,b,c,d,e)
(a,b,c,d,e) 一一映射,即:
f
(
x
)
=
(
a
,
b
,
c
,
d
,
e
)
f(x) = (a,b,c,d,e)
f(x)=(a,b,c,d,e)
- 因为每一维的取值为
[
0
,
3
]
[0,3]
[0,3],我们可以把每一维当成是 4进制数的每一位,于是有:
- x
=
a
×
4
4
b
×
4
3
c
×
4
2
d
×
4
1
e
×
4
0
x = a \times 4^4 + b \times 4^3 + c \times 4^2 + d \times 4^1 + e \times 4^0
x=a×44+b×43+c×42+d×41+e×40
- 那么,我们只需要用一个一维数组来表示状态即可:
d
[
x
]
d[x]
d[x]。
四、动态规划的常用状态转移方程
动态规划算法三要素(摘自黑书,总结的很好,很有概括性):
①所有不同的子问题组成的表
②解决问题的依赖关系可以看成是一个图
③填充子问题的顺序(即对②的图进行拓扑排序,填充的过程称为状态转移);
- 则如果子问题的数目为
O
(
n
t
)
O(n^t)
O(nt),每个子问题需要用到
O
(
n
e
)
O(n^e)
O(ne) 个子问题的结果,那么我们称它为 tD/eD 的问题,于是可以总结出四类常用的动态规划方程:(下面会把opt作为取最优值的函数(一般取
m
i
n
min
min 或
m
a
x
max
max ),
w
(
j
,
i
)
w(j, i)
w(j,i)为一个实函数,其它变量都可以在常数时间计算出来)。
1、1D/1D
- d
[
i
]
=
o
p
t
(
d
[
j
]
w
(
j
,
i
)
∣
0
<
=
i
<
j
)
d[i] = opt( d[j] + w(j, i) | 0 <= i < j )
d[i]=opt(d[j]+w(j,i)∣0<=i<j)
- 状态转移如图四-1-1所示(黄色块代表
d
[
i
]
d[i]
d[i],绿色块代表
d
[
j
]
d[j]
d[j]):

图四-1-1
- 这类状态转移方程一般出现在线性模型中。
2、2D/0D
- d
[
i
]
[
j
]
=
o
p
t
(
d
[
i
−
1
]
[
j
]
x
i
,
d
[
i
]
[
j
−
1
]
y
j
,
d
[
i
−
1
]
[
j
−
1
]
z
i
j
)
d[i][j] = opt( d[i-1][j] + x_i, d[i][j-1] + y_j, d[i-1][j-1] + z_{ij} )
d[i][j]=opt(d[i−1][j]+xi,d[i][j−1]+yj,d[i−1][j−1]+zij)
- 状态转移如图四-2-1所示:
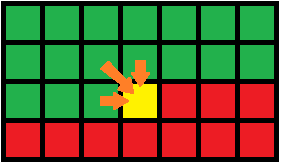
图四-2-1
- 比较经典的问题是最长公共子序列、最小编辑距离。
- 有关最长公共子序列的问题,可以参考以下文章:夜深人静写算法(二十一)- 最长公共子序列
- 有关最小编辑距离的问题,可以参考以下文章:夜深人静写算法(二十二)- 最小编辑距离
3、2D/1D
- d
[
i
]
[
j
]
=
w
(
i
,
j
)
o
p
t
(
d
[
i
]
[
k
−
1
]
d
[
k
]
[
j
]
)
d[i][j] = w(i, j) + opt( d[i][k-1] + d[k][j] )
d[i][j]=w(i,j)+opt(d[i][k−1]+d[k][j])
- 区间模型常用方程,如图四-3-1所示:
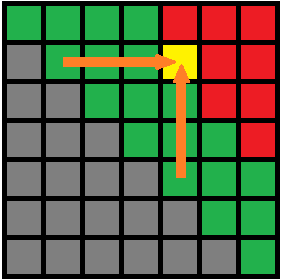
四-3-1
- 另外一种常用的 2D/1D 的方程为:
- d
[
i
]
[
j
]
=
o
p
t
(
d
[
i
−
1
]
[
k
]
w
(
i
,
j
,
k
)
∣
k
<
j
)
d[i][j] = opt( d[i-1][k] + w(i, j, k) | k < j )
d[i][j]=opt(d[i−1][k]+w(i,j,k)∣k<j)
-
- 区间模型的详细内容可以参考以下这篇文章:夜深人静写算法(二十七)- 区间DP
4、2D/2D
- d
[
i
]
[
j
]
=
o
p
t
(
d
[
i
′
]
[
j
′
]
w
(
i
′
,
j
′
,
i
,
j
)
∣
0
<
=
i
′
<
i
,
0
<
=
j
′
<
j
)
d[i][j] = opt( d[i’][j’] + w(i’, j’, i, j) | 0 <= i’ < i, 0 <= j’ < j)
d[i][j]=opt(d[i′][j′]+w(i′,j′,i,j)∣0<=i′<i,0<=j′<j)
- 如图四-4-1所示:

四-4-1
- 常见于二维的迷宫问题,由于复杂度比较大,所以一般配合数据结构优化,如线段树、树状数组等。
- 对于一个tD/eD 的动态规划问题,在不经过任何优化的情况下,可以粗略得到一个时间复杂度是
O
(
n
t
e
)
O(n^ {t+e})
O(nt+e),空间复杂度是
O
(
n
t
)
O(n^t)
O(nt) 的算法,大多数情况下空间复杂度是很容易优化的,难点在于时间复杂度,后续章节将详细讲解各种情况下的动态规划优化算法。
- 关于 动态规划入门 的内容到这里就结束了。
- 如果还有不懂的问题,可以 想方设法 找到作者的微信进行在线咨询。

五、动态规划题集整理
1、递推
| 题目链接 | 难度 | 解法 |
|---|---|---|
| Recursion Practice | ★☆☆☆☆ | 几个初级递推 |
| Put Apple | ★☆☆☆☆ | |
| Tri Tiling | ★☆☆☆☆ | 【例题1】 |
| Computer Transformation | ★☆☆☆☆ | 【例题2】 |
| Train Problem II | ★☆☆☆☆ | |
| How Many Trees? | ★☆☆☆☆ | |
| Buy the Ticket | ★☆☆☆☆ | |
| Game of Connections | ★☆☆☆☆ | |
| Count the Trees | ★☆☆☆☆ | |
| Circle | ★☆☆☆☆ | |
| Combinations, Once Again | ★★☆☆☆ | |
| Closing Ceremony of Sunny Cup | ★★☆☆☆ | |
| Rooted Trees Problem | ★★☆☆☆ | |
| Water Treatment Plants | ★★☆☆☆ | |
| One Person | ★★☆☆☆ | |
| Relax! It’s just a game | ★★☆☆☆ | |
| Minimum Heap | ★★★☆☆ | |
| N Knight | ★★★☆☆ | |
| Connected Graph | ★★★★★ | 楼天城“男人八题”之一 |
2、记忆化搜索
| 题目链接 | 难度 | 解法 |
|---|---|---|
| Function Run Fun | ★☆☆☆☆ | |
| FatMouse and Cheese | ★☆☆☆☆ | 经典迷宫问题 |
| Cheapest Palindrome | ★★☆☆☆ | |
| A Mini Locomotive | ★★☆☆☆ | |
| Millenium Leapcow | ★★☆☆☆ | |
| Unidirectional TSP | ★★☆☆☆ | |
| Honeycomb Walk | ★★☆☆☆ | 利用记忆化简化递推 |
| Brackets Sequence | ★★★☆☆ | 经典记忆化 |
| Chessboard Cutting | ★★★☆☆ | 《算法艺术和信息学竞赛》例题 |
| Number Cutting Game | ★★★☆☆ |
3、最长单调子序列
| 题目链接 | 难度 | 解法 |
|---|---|---|
| Constructing Roads In JG Kingdom | ★★☆☆☆ | |
| Stock Exchange | ★★☆☆☆ | |
| Wooden Sticks | ★★☆☆☆ | |
| Bridging signals | ★★☆☆☆ | |
| BUY LOW, BUY LOWER | ★★☆☆☆ | 要求需要输出方案数 |
| Longest Ordered Subsequence | ★★☆☆☆ | |
| Crossed Matchings | ★★☆☆☆ | |
| Jack’s struggle | ★★★☆☆ | 稍微做点转化 |
4、最大M子段和
| 题目链接 | 难度 | 解法 |
|---|---|---|
| Max Sum | ★☆☆☆☆ | 最大子段和 |
| Max Sum Plus Plus | ★★☆☆☆ | 最大M子段和 |
| To The Max | ★★☆☆☆ | 最大子矩阵 |
| Max Sequence | ★★☆☆☆ | 最大2子段和 |
| Maximum sum | ★★☆☆☆ | 最大2子段和 |
| 最大连续子序列 | ★★☆☆☆ | 最大子段和 |
| Largest Rectangle in a Histogram | ★★☆☆☆ | 最大子矩阵变形 |
| City Game | ★★☆☆☆ | 最大子矩阵扩展 |
| Matrix Swapping II | ★★★☆☆ | 最大子矩阵变形后扩展 |
5、线性模型
| 题目链接 | 难度 | 解法 |
|---|---|---|
| Skiing | ★☆☆☆☆ | |
| Super Jumping! Jumping! Jumping! | ★☆☆☆☆ | |
| Milking Time | ★★☆☆☆ | 区间问题的线性模型 |
| Computers | ★★☆☆☆ | 【例题4】 |
| Bridge over a rough river | ★★★☆☆ | |
| Crossing River | ★★★☆☆ | |
| Blocks | ★★★☆☆ | |
| Parallel Expectations | ★★★★☆ | 线性模型黑书案例 |
6、区间模型
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









