







inner = func()
inner()
## 5函数的参数
#### 5.1定义阶段
** 位置形参**
在定义阶段从左往右的顺序依次定义的形参
**默认形参**
在定义阶段已经为其初始化赋值
**关键字参数**
自由主题
可变长度的形参args
溢出的位置参数,打包成元组,给接受,赋给args的变量名
**命名关键字参数**
放在\*和之间的参数,必须按照key=value形式传值
**可变长度的位置形参kwargs**
溢出的关键字实参,打包成字典,给\*\*接受,赋给变量kwargs
**形参和实参关系:** 在调用函数时,会将实参的值绑定给形参的变量名,这种绑定关系临时生效,在调用结束后就失效了
#### 5.2调用阶段
** 位置实参**
调用阶段按照从左往右依次传入的传入的值,会与形参一一对应
**关键字实参**
在调用阶段,按照key=value形式指名道姓的为形参传值
**实参中带\*的**,再传值前先将打散成位置实参,再进行赋值
**实参中带**的\*\*,在传值前先将其打散成关键字实参,再进行赋值
## 6.装饰器:闭包函数的应用
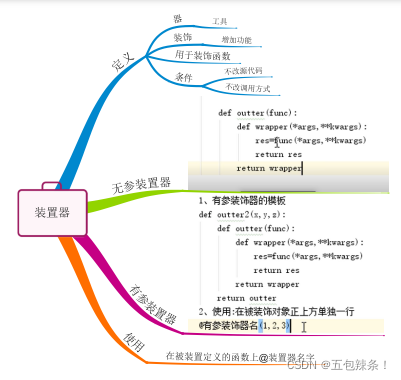
装饰器就是用来为被装饰器对象添加新功能的工具
\*\*注意:\*\*装饰器本身可以是任意可调用对象,被装饰器的对象也可以是任意可调用对象
**为何使用装饰器**
\*\*开放封闭原则:\*\*封闭指的是对修改封闭,对扩展开放
#### 6.1装饰器的实现必须遵循两大原则:
1. 不修改被装饰对象的源代码`
2. 不修改被装饰器对象的调用方式
装饰器的目标:就是在遵循1和2原则的前提下为被装饰对象添加上新功能
#### 6.2装饰器语法糖
在被装饰对象正上方单独一行写@装饰器的名字
python解释器一旦运行到@装饰器的名字,就会调用装饰器,然后将被装饰函数的内存地址当作参数传给装饰器,最后将装饰器调用的结果赋值给原函数名 foo=auth(foo) 此时的foo是闭包函数wrapper
#### 6.3无参装饰器
import time
def timmer(func):
def wrapper(*args,**kwargs):
start_time=time.time()
res=func(*args,**kwargs)
stop_time=time.time()
print(‘run time is %s’ %(stop_time-start_time))
return res
return wrapper
@timmer
def foo():
time.sleep(3)
print(‘from foo’)
foo()
#### 6.4有参装饰器
def auth(driver=‘file’):
def auth2(func):
def wrapper(*args,**kwargs):
name=input("user: ")
pwd=input("pwd: ")
if driver == 'file':
if name == 'egon' and pwd == '123':
print('login successful')
res=func(\*args,\*\*kwargs)
return res
elif driver == 'ldap':
print('ldap')
return wrapper
return auth2
@auth(driver=‘file’)
def foo(name):
print(name)
foo(‘egon’)
## 7.题目
#题目一:
db=‘db.txt’
login_status={‘user’:None,‘status’:False}
def auth(auth_type=‘file’):
def auth2(func):
def wrapper(*args,**kwargs):
if login_status[‘user’] and login_status[‘status’]:
return func(*args,**kwargs)
if auth_type == ‘file’:
with open(db,encoding=‘utf-8’) as f:
dic=eval(f.read())
name=input('username: ').strip()
password=input('password: ').strip()
if name in dic and password == dic[name]:
login_status[‘user’]=name
login_status[‘status’]=True
res=func(*args,**kwargs)
return res
else:
print(‘username or password error’)
elif auth_type == ‘sql’:
pass
else:
pass
return wrapper
return auth2
@auth()
def index():
print(‘index’)
@auth(auth_type=‘file’)
def home(name):
print(‘welcome %s to home’ %name)
index()
home(‘egon’)
#题目二
import time,random
user={‘user’:None,‘login_time’:None,‘timeout’:0.000003,}
def timmer(func):
def wrapper(*args,**kwargs):
s1=time.time()
res=func(*args,**kwargs)
s2=time.time()
print(‘%s’ %(s2-s1))
return res
return wrapper
def auth(func):
def wrapper(*args,**kwargs):
if user[‘user’]:
timeout=time.time()-user[‘login_time’]
if timeout < user[‘timeout’]:
return func(*args,**kwargs)
name=input('name>>: ').strip()
password=input('password>>: ').strip()
if name == ‘egon’ and password == ‘123’:
user[‘user’]=name
user[‘login_time’]=time.time()
res=func(*args,**kwargs)
return res
return wrapper
@auth
def index():
time.sleep(random.randrange(3))
print(‘welcome to index’)
@auth
def home(name):
time.sleep(random.randrange(3))
print('welcome %s to home ’ %name)
index()
home(‘egon’)
#题目三:简单版本
import requests
import os
cache_file=‘cache.txt’
def make_cache(func):
def wrapper(*args,**kwargs):
if not os.path.exists(cache_file):
with open(cache_file,‘w’):pass
if os.path.getsize(cache_file):
with open(cache_file,'r',encoding='utf-8') as f:
res=f.read()
else:
res=func(\*args,\*\*kwargs)
with open(cache_file,'w',encoding='utf-8') as f:
f.write(res)
return res
return wrapper
@make_cache
def get(url):
return requests.get(url).text
res=get(‘https://www.python.org’)
print(res)
#题目四:扩展版本
import requests,os,hashlib
engine_settings={
‘file’:{‘dirname’:‘./db’},
‘mysql’:{
‘host’:‘127.0.0.1’,
‘port’:3306,
‘user’:‘root’,
‘password’:‘123’},
‘redis’:{
‘host’:‘127.0.0.1’,
‘port’:6379,
‘user’:‘root’,
‘password’:‘123’},
}
def make_cache(engine=‘file’):
if engine not in engine_settings:
raise TypeError(‘egine not valid’)
def deco(func):
def wrapper(url):
if engine == ‘file’:
m=hashlib.md5(url.encode(‘utf-8’))
cache_filename=m.hexdigest()
cache_filepath=r’%s/%s’ %(engine_settings[‘file’][‘dirname’],cache_filename)
if os.path.exists(cache_filepath) and os.path.getsize(cache_filepath):
return open(cache_filepath,encoding='utf-8').read()
res=func(url)
with open(cache_filepath,'w',encoding='utf-8') as f:
f.write(res)
return res
elif engine == 'mysql':
pass
elif engine == 'redis':
pass
else:
pass
return wrapper
return deco
@make_cache(engine=‘file’)
def get(url):
return requests.get(url).text
print(get(‘https://www.python.org’))
print(get(‘https://www.baidu.com’))
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









