







最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
最终的结果是一个面部标记检测器,可用于实时检测具有高质量预测的面部标记。
=======================================================================
dlib库中预先训练的面部标记检测器用于估计映射到面部结构的68(x,y)坐标的位置。
68个坐标的索引可在下图中显示:

这些注释是68点iBUG 300-W数据集的一部分,dlib面部标记预测器是在该数据集上训练的。
值得注意的是,还有其他风格的面部标记检测器,包括可以在HELEN数据集上训练的194点模型。
无论使用哪一个数据集,都可以利用相同的dlib框架在输入训练数据上训练形状预测器-如果您想训练面部标记检测器或自定义形状预测器,这非常有用。
在这篇博文的剩余部分,我将演示如何在图像中检测这些面部标记。
=====================================================================================
这篇博文使用到了imutils库face_utils.py中的两个函数。
第一个实用函数是rect_to_bb,是“矩形到边框”的缩写:
def rect_to_bb(rect):
#获取dlib预测的边界并将其转换
#按照我们通常使用的格式(x,y,w,h)
#使用OpenCV
x = rect.left()
y = rect.top()
w = rect.right() - x
h = rect.bottom() - y
返回一个元组 (x, y, w, h)
return (x, y, w, h)
此函数接受一个参数rect,该参数假定为dlib检测器(即面部检测器)生成的边框矩形。
rect对象包括检测的(x,y)-坐标。
然而,在OpenCV中,我们通常认为边界框是“(x,y,width,height)”,因此为了方便起见,rect_to_bb函数将这个rect对象转换为4元组坐标。
第二,shape_to_np函数:
def shape_to_np(shape, dtype=“int”):
#初始化(x,y)-坐标列表
coords = np.zeros((68, 2), dtype=dtype)
#在68个面部标记上循环并转换它们
#到(x,y)-坐标的2元组
for i in range(0, 68):
coords[i] = (shape.part(i).x, shape.part(i).y)
#返回(x,y)坐标的列表
return coords
dlib面部标记检测器将返回一个包含面部标记区域68(x,y)坐标的形状对象。
使用shape_to_np函数,我们可以将这个对象转换成一个NumPy数组。
有了这两个辅助函数,我们现在就可以检测图像中的面部标记了。
打开一个新文件,将其命名为facial_landmarks.py,然后插入以下代码:
import the necessary packages
from imutils import face_utils
import numpy as np
import argparse
import imutils
import dlib
import cv2
#构造参数解析器并解析参数
ap = argparse.ArgumentParser()
ap.add_argument(“-p”, “–shape-predictor”, required=True,
help=“path to facial landmark predictor”)
ap.add_argument(“-i”, “–image”, required=True,
help=“path to input image”)
args = vars(ap.parse_args())
导入所需的Python包。
将使用imutils的face_utils子模块访问上面详述的助手函数。
然后将导入dlib。
解析我们的命令行参数:
–shape-predictor:这是通往dlib预先训练的面部标记检测器的路径。你可以在这里下载检测器模型,也可以使用本文的“下载”部分来获取代码+示例图像+预先训练过的检测器。
–image:我们要检测面部标记的输入图像的路径。
既然我们的导入和命令行参数已经处理完毕,让我们初始化dlib的面部检测器和面部标记预测器:
初始化dlib的人脸检测器(基于HOG)然后创建
面部标记预测器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args[“shape_predictor”])
初始化dlib的预训练人脸检测器,该检测器基于对用于对象检测的定向梯度标准直方图+线性SVM方法的修改。
然后使用提供的shape_predictor的路径加载面部标记预测器。
但是,在我们能够实际检测面部标记点之前,我们首先需要检测输入图像中的面部:
加载输入图像,调整大小,并将其转换为灰度
image = cv2.imread(args[“image”])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
在灰度图像中检测人脸
rects = detector(gray, 1)
通过OpenCV从磁盘加载我们的输入图像,然后通过调整图像大小使其具有500像素的宽度并将其转换为灰度来预处理图像。
处理检测图像中面的边界框。
探测器的第一个参数是我们的灰度图像(尽管这种方法也可以用于彩色图像)。
第二个参数是在应用检测器之前放大图像时要应用的图像金字塔层的数量(这相当于在图像上计算cv2.N次)。
在人脸检测之前提高输入图像分辨率的好处是,它可能允许我们检测图像中的更多人脸-缺点是输入图像越大,检测过程的计算成本就越高。
给定图像中人脸的(x,y)-坐标,我们现在可以对每个人脸区域应用人脸标记检测:
循环面部检测
for (i, rect) in enumerate(rects):
确定面部区域的面部标志,然后
将面部标志 (x, y) 坐标转换为 NumPy数组
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
将 dlib 的矩形转换为 OpenCV 样式的边界框
[即(x, y, w, h)],然后绘制人脸边界框
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(image, (x, y), (x + w, y + h), (255, 255, 0), 2)
显示人脸编号
cv2.putText(image, “Face #{}”.format(i + 1), (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 0), 2)
循环面部标志的 (x, y) 坐标
并将它们绘制在图像上
for (x, y) in shape:
cv2.circle(image, (x, y), 1, (0, 255, 0), -1)
显示带有人脸检测 + 人脸标记的输出图像
cv2.imshow(“Output”, image)
cv2.waitKey(0)
循环每个人脸检测。
对于每个人脸检测,给出68(x,y)-坐标,该坐标映射到图像中的特定人脸特征。
然后将dlib形状对象转换为具有形状(68,2)的NumPy数组。
绘制图像上检测到的人脸周围的边界框,绘制人脸的索引。
最后,在检测到的面部标记上循环并分别绘制它们。
将输出图像显示到屏幕上。
测试结果
打开终端输入:
python facial_landmarks.py --shape-predictor shape_predictor_68_face_landmarks.dat --image 11.jpg
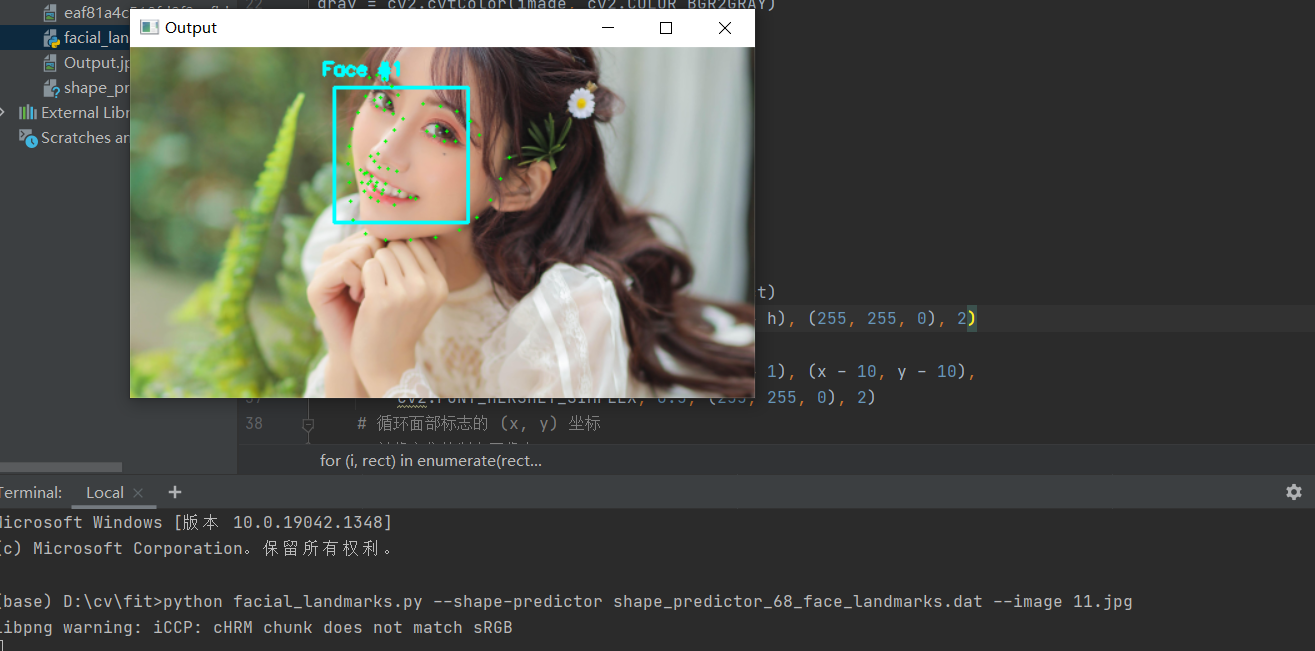
让我们继续开始这个面部标记的例子。这次调用摄像头
打开一个新文件,将其命名为 video_facial_landmarks.py ,并插入以下代码:
import the necessary packages
from imutils.video import VideoStream
from imutils import face_utils
import datetime
import argparse
import imutils
import time
import dlib
import cv2
导入需要的包。
然后,让我们解析命令行参数:
构造参数 parse 并解析参数
ap = argparse.ArgumentParser()
ap.add_argument(“-p”, “–shape-predictor”, required=True,
help=“path to facial landmark predictor”)
ap.add_argument(“-r”, “–picamera”, type=int, default=-1,
help=“whether or not the Raspberry Pi camera should be used”)
args = vars(ap.parse_args())
脚本需要一个命令行参数,然后是第二个可选参数,每个参数的详细信息如下:
–shape-predictor :dlib 的预训练面部标志检测器的路径。
–picamera :可选的命令行参数,此开关指示是否应使用 Raspberry Pi 摄像头模块而不是默认的网络摄像头/USB 摄像头。 提供一个 > 0 的值以使用您的 Raspberry Pi 相机。
现在我们的命令行参数已经解析完毕,我们需要初始化 dlib 的基于 HOG + 线性 SVM 的人脸检测器,然后加载面部标志预测器:
初始化dlib的人脸检测器(基于HOG)然后创建
面部标志预测器
print(“[INFO] loading facial landmark predictor…”)
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args[“shape_predictor”])
下一个代码块简单地处理初始化我们的 VideoStream 并允许相机传感器预热:
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









