






前言
刚接触Stable Diffusion不久的你,是否有这样的疑问:
Q1: Stable Diffusion中的主模型CKPT是什么?
Q2: Stable Diffusion中的Lora模型又是什么?
Q3: 在哪儿可以下载好用的AI绘图模型?
Q4: Stable Diffusion 如何导出高清图纸?
本篇文章就将对这些问题逐一解答,并将教会你如何通过SU素模生成手工模型图片。就像这样:
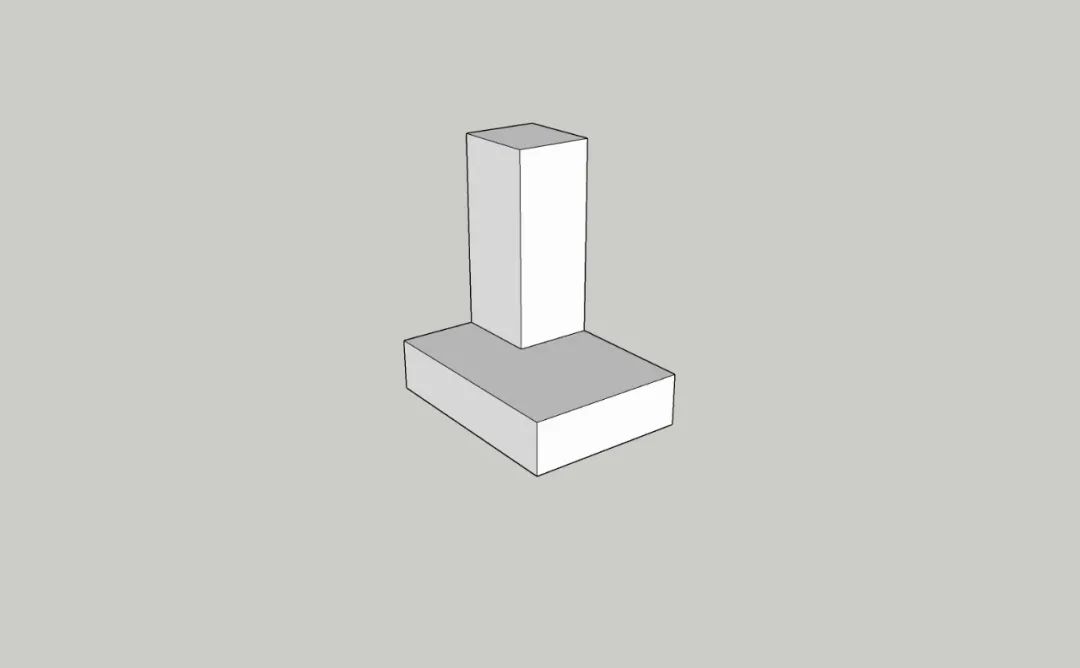


©绘图空间
01
什么是CKPT模型?
What is the CKPT model?
CKPT模型,也常被称为主模型或基础模型,它是一种经过训练的图片合集,全称是CheckPoint(检查点)。早期的文件后缀名称为ckpt,现在一般为safetensors。体积一般在几个G左右。
如果要搞懂CKPT模型的原理,这里将会赘述不少计算机术语,而你只要简单的将其理解为——CKPT模型决定了创作的基础方向。比如我们要进行建筑方向的创作,那么就要加载建筑方向的CKPT模型,而不是加载人物CKPT模型等等。
02
什么是LORA模型?
What is the LORA model?
我们常在AI绘画的讨论场景中提到lora。那么lora究竟指的是什么呢?(绝对不是一位叫做劳拉的女孩…)
lora模型其实是一种主模型的微调模型。文件后缀名称为safetensors,体积一般在几十到几百兆不等。与CKPT模型一次绘画只能加载一个不同,你可以同时加载多个lora模型。
我们也将lora模型的原理简化,你可以简单的将其理解为——lora模型就像主模型的风格滤镜。它的加载方式就像是游戏中的MOD补丁、DLC扩展包。
03
Stable Diffusion中各类模型的获取与下载
Acquisition and download of various models in Stable Diffusion
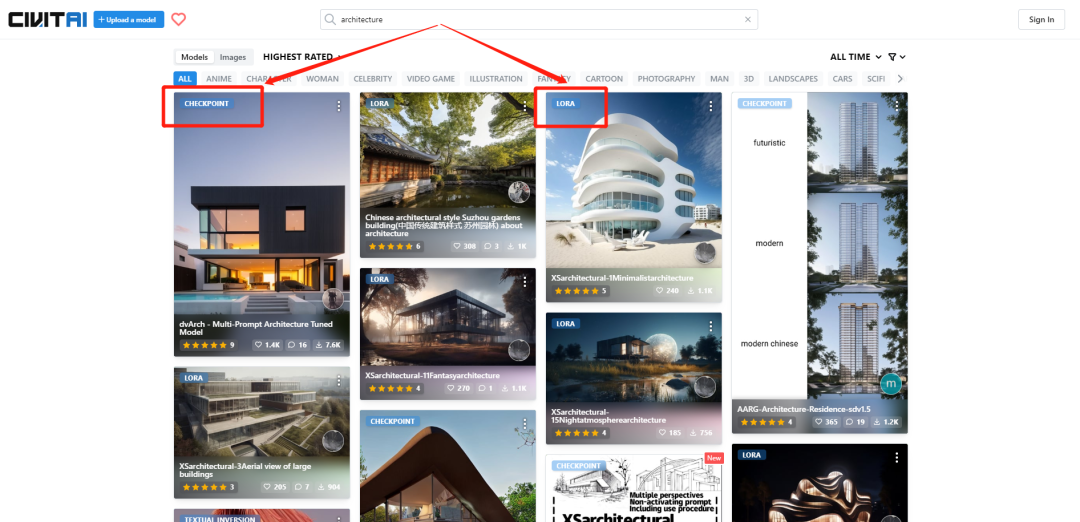
请大家牢记这个网站——civitai,也就是说我们常说的C站**。**C站是目前全球品类最全、质量最优的AI绘画模型网站,其中有各类优质的CKPT模型与lora模型。
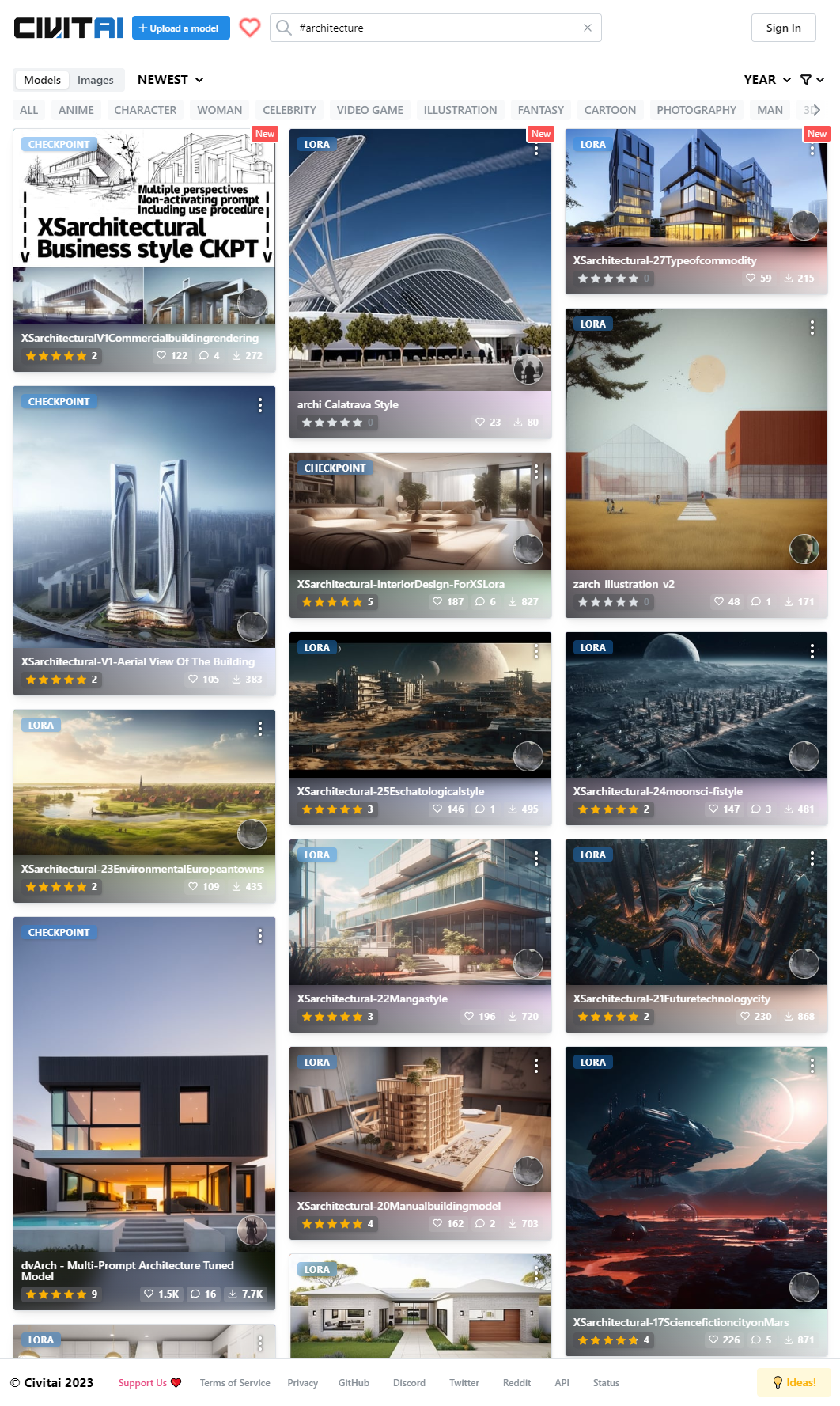
我们在搜索栏输入architecture,就可以得到许多建筑方向的模型信息,它们上面都有对应的模型标签,方便用户进行筛选与下载。
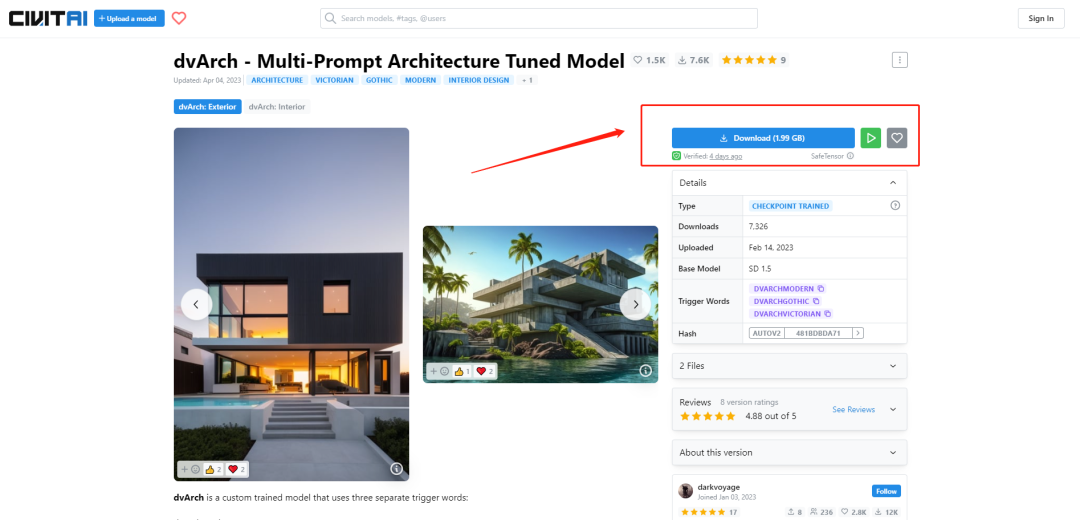
点开一个模型信息,单击Download按钮,就可以将对应的模型下载到本地计算机:
那么下载好的模型要放在哪里呢?
CKPT模型存储路径:models\Stable-diffusion:
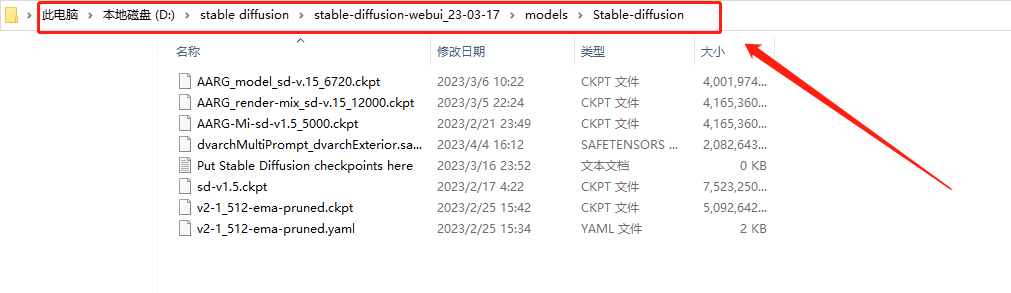
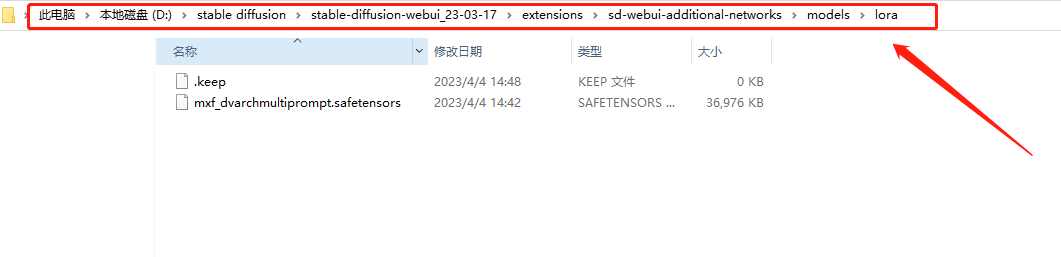
lora模型存储路径:extensions\sd-webui-additional-networks\models\lora
需要注意的是,该网站的登录需在“科学上网”前提下进行。
04
CKPT模型与lora模型的加载方式
How to load CKPT model and lora model
当我们下载好了需要使用的模型之后,需要在Stable Diffusion中对其进行加载。以下是它们对应的加载方式。
CKPT模型加载方式
在Stable Diffusion界面左上角,点击刷新按钮(蓝色循环图标)之后,下拉列表就可以看到本地CKPT模型,单击选中即可完成对应模型加载:

Lora模型加载方式
第1步:点击Stable Diffusion界面中的Additional Networks按钮。
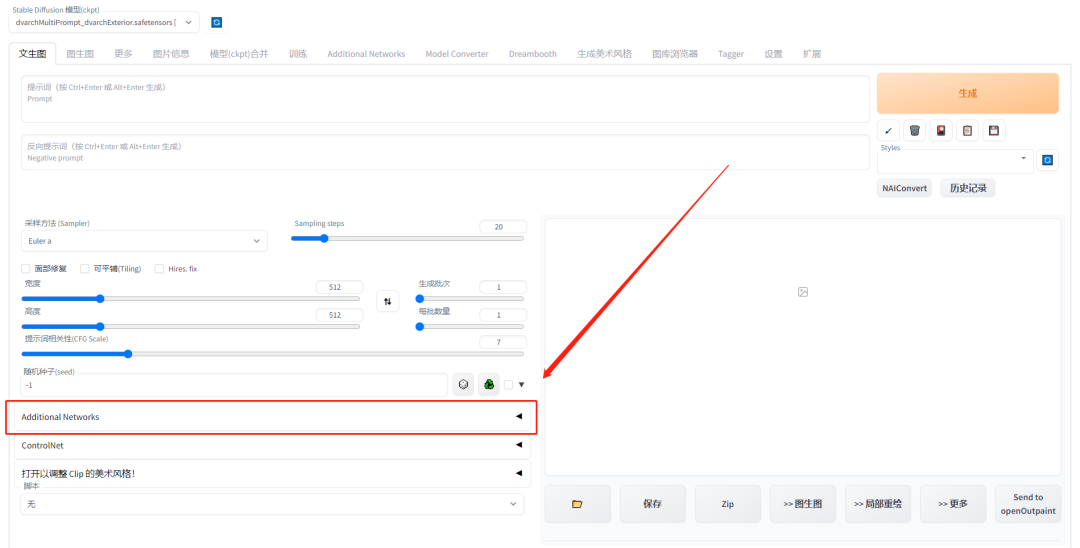
第2步:点击Refresh models按钮。
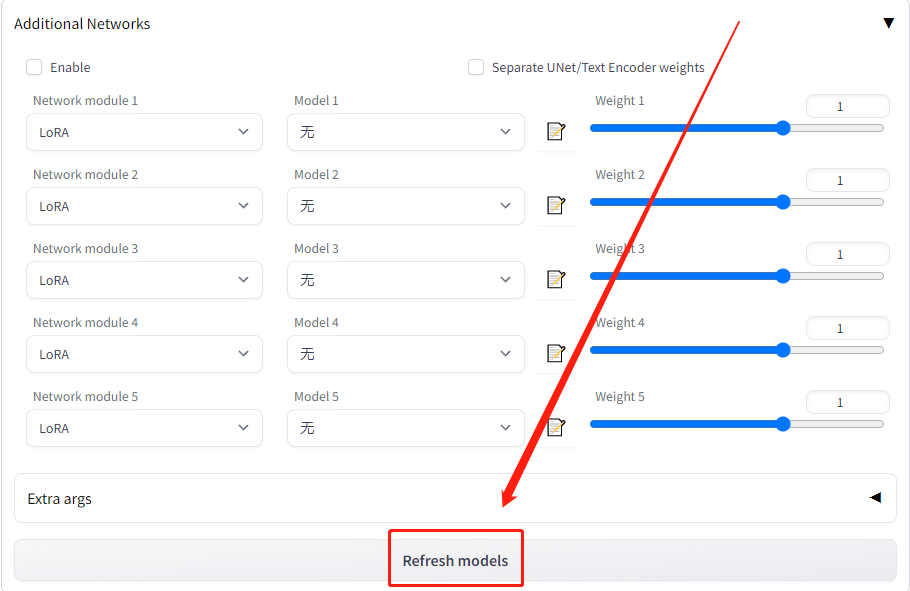
第3步:下拉model列表即可找到本地lora模型。
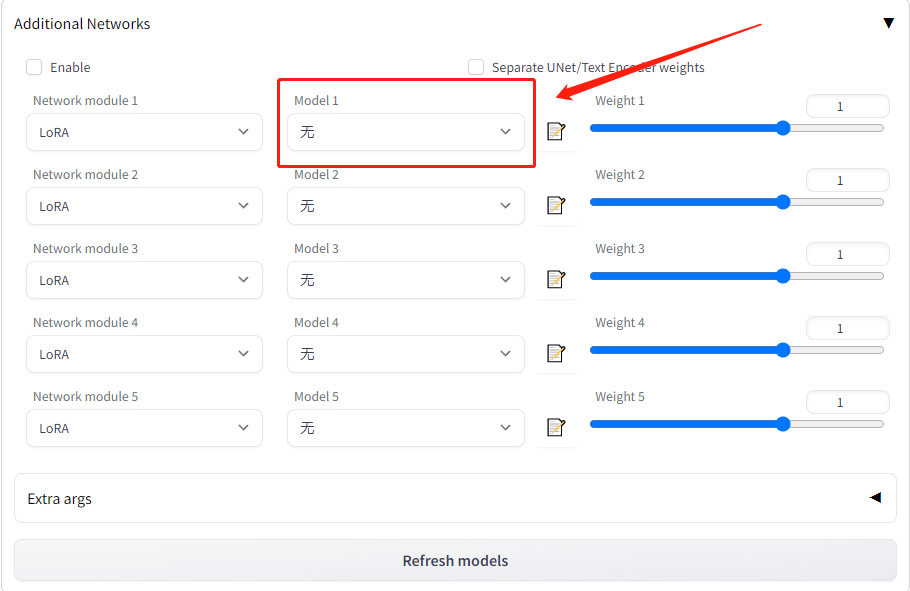
第4步:点击Enable按钮,即可完成lora模型的加载启用。

第5步:调节weight权重参数,即可控制lora模型对主模型的影响程度。

整理和输出教程属实不易,觉得这篇教程对你有所帮助的话,可以点击👇二维码领取资料😘

05
案例教学
Case Teaching
我们将通过一个“SU素模生成手工模型图片”的案例,带大家具体的看一遍CKPT模型与lora模型相结合的使用方法。
第1步:在C站上下载好要用到的CKPT模型与lora模型,并在Stable Diffusion中完成模型加载。
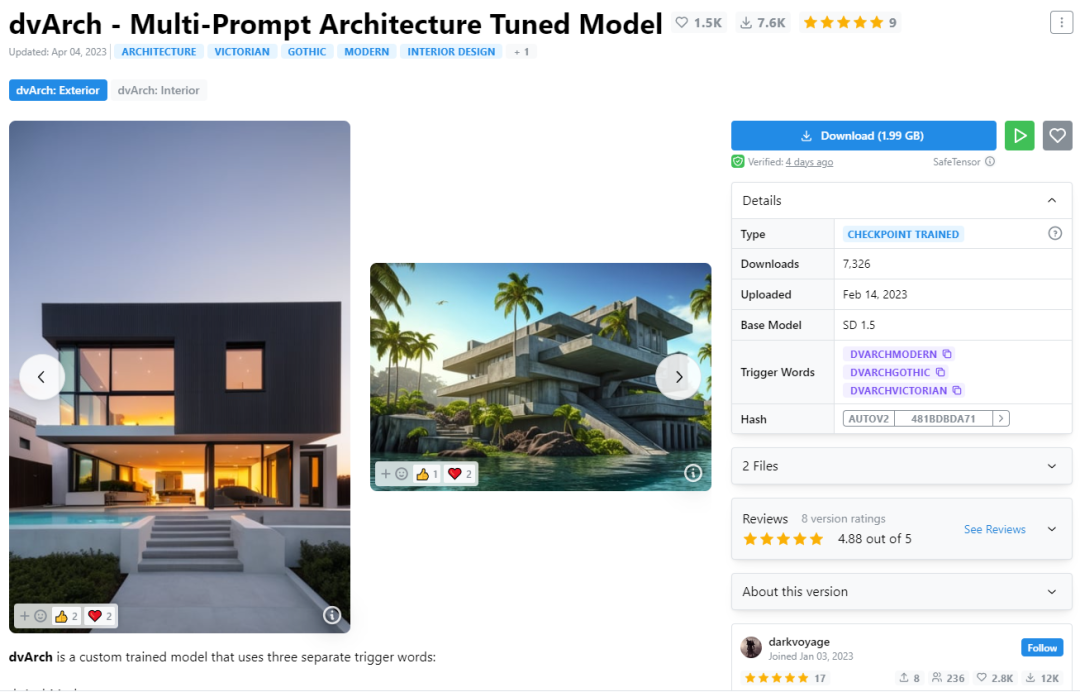
建筑方向CKPT模型©C站darkvoyage
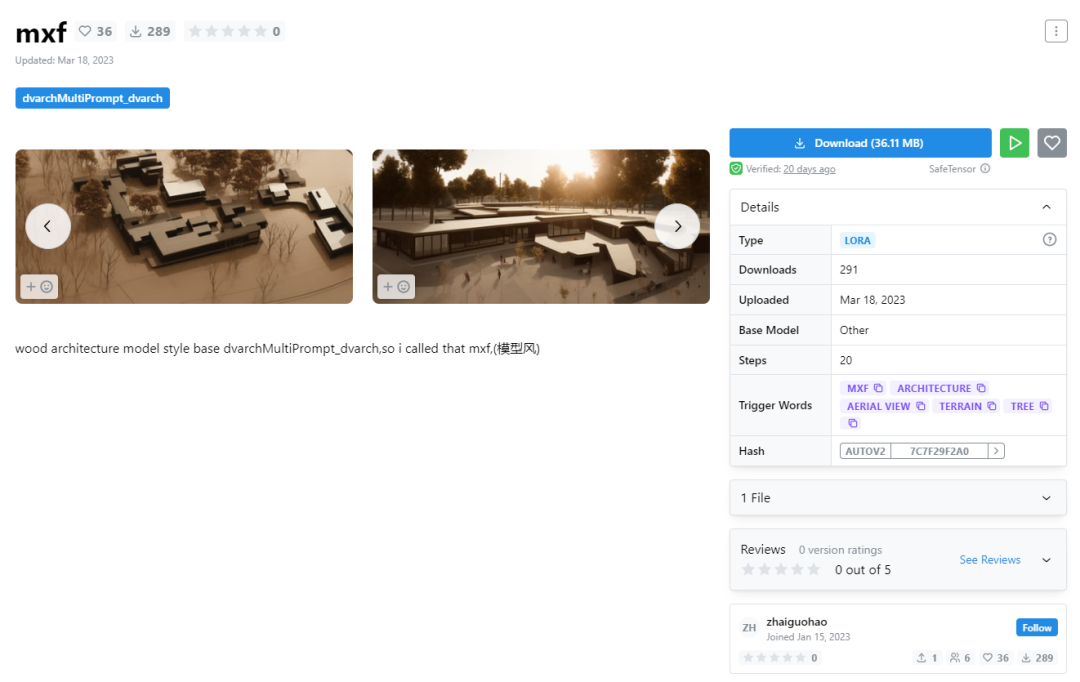
建筑方向lora模型©C站zhaiguohao
第2步:将SU素模图片拖入到ControlNet中,并调节好各项参数。对此处有疑问的朋友,可稍后阅读我们的往期文章《[“喂饭级”教程!建筑AI生成设计Stable Diffusion看这篇就够了!,里面有对ControlNet插件的使用讲解。
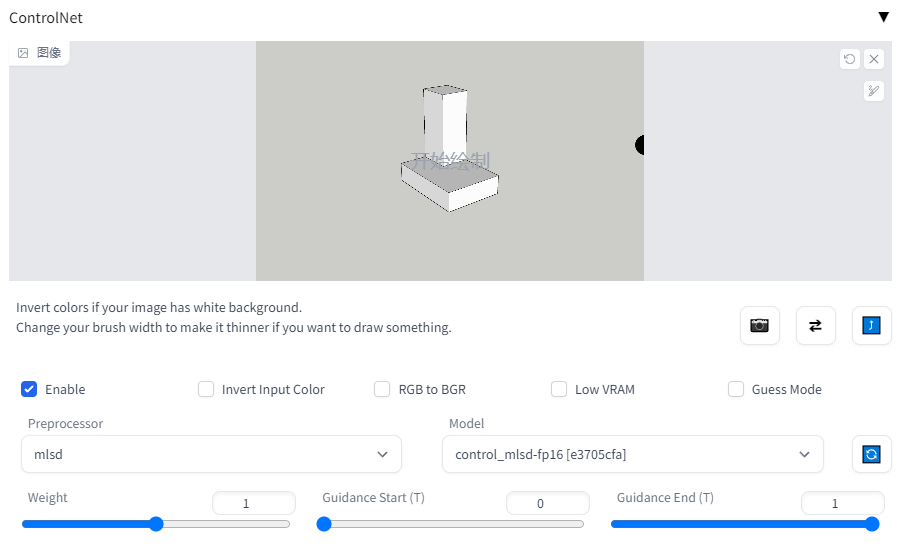
第3步:填写好提示词与反提示词。需要注意的是,在CKPT模型与lora模型的下载界面都有其对应的触发提示词,输入对应的触发词,生成的图片将更加贴合模型所展示的效果。
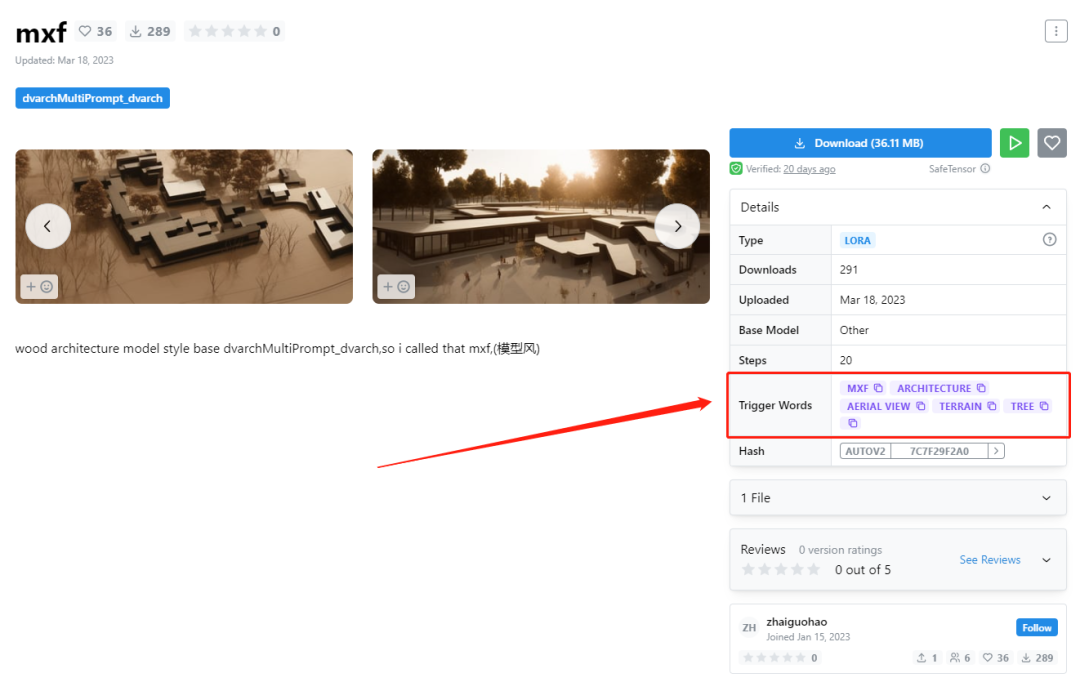

**第4步:选择好生成批次与每批数量**之后,就可以进行作品创作了。我们选择一次生成4张图片,就可以得到如下结果:
©绘图空间
本次案例所用到的模型,我们都将会上传到绘图空间AI设计讨论群,感兴趣的朋友可以联系我们的客服加群下载。
06
高清图导出
HD image export
当下载的作品清晰度不够时,我们可以使用Stable Diffusion中自带的功能提高****图片清晰度。
第1步:点击Stable Diffusion中的“更多”按钮(某些版本里也叫作附加功能)。
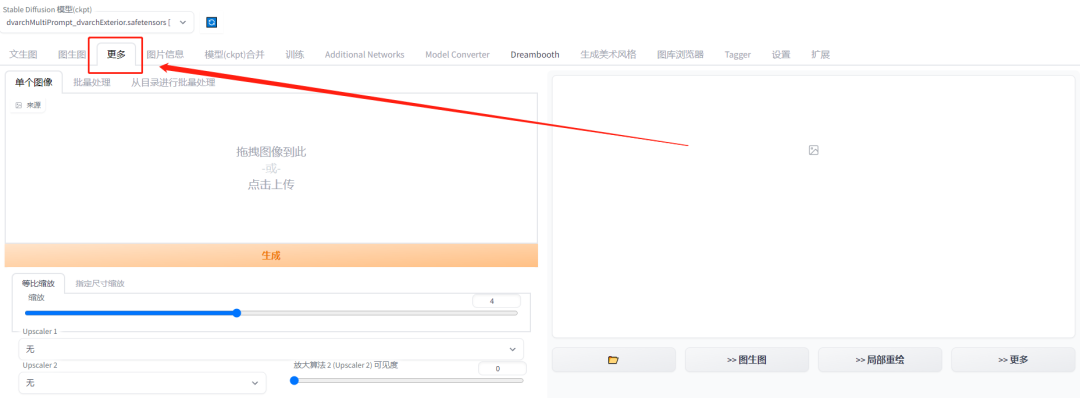
第2步:上传需要提高清晰度的图片,这里以刚刚生成的手工模型图片为例。
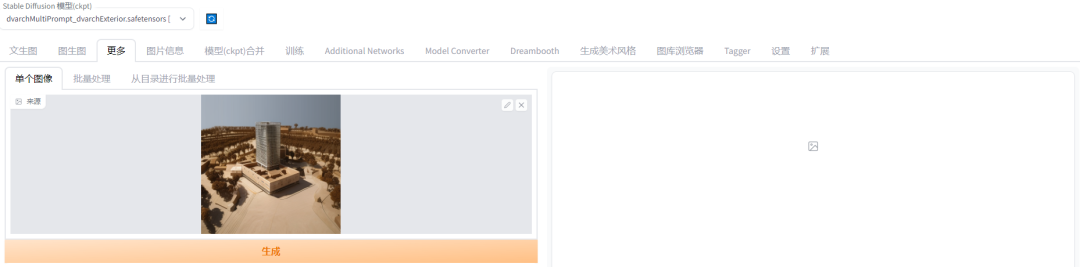
第3步:选择算法模型。图中框选的两个模型是无损提高清晰度常用的两个模型。
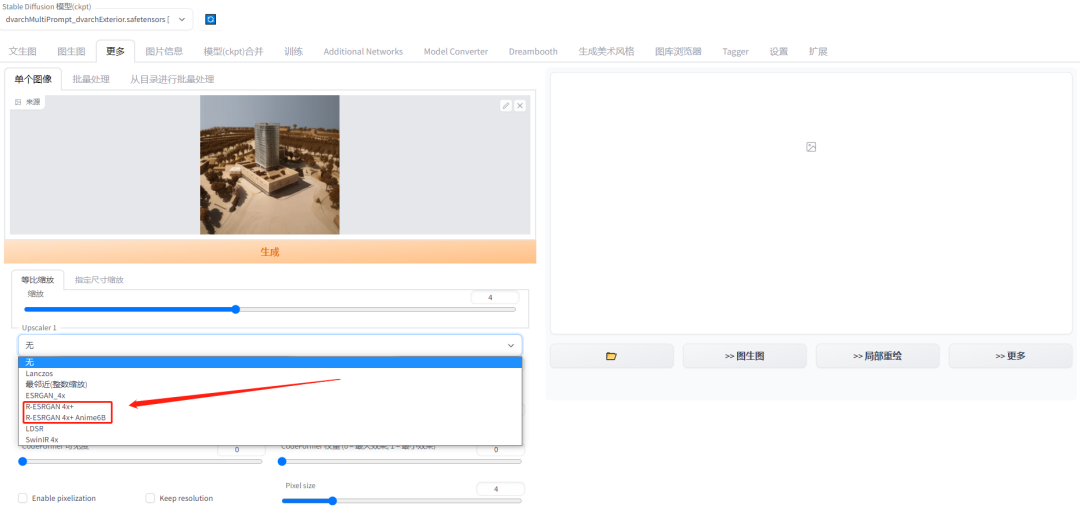
第4步:选择放大倍数。这里我们选择4就可以了。
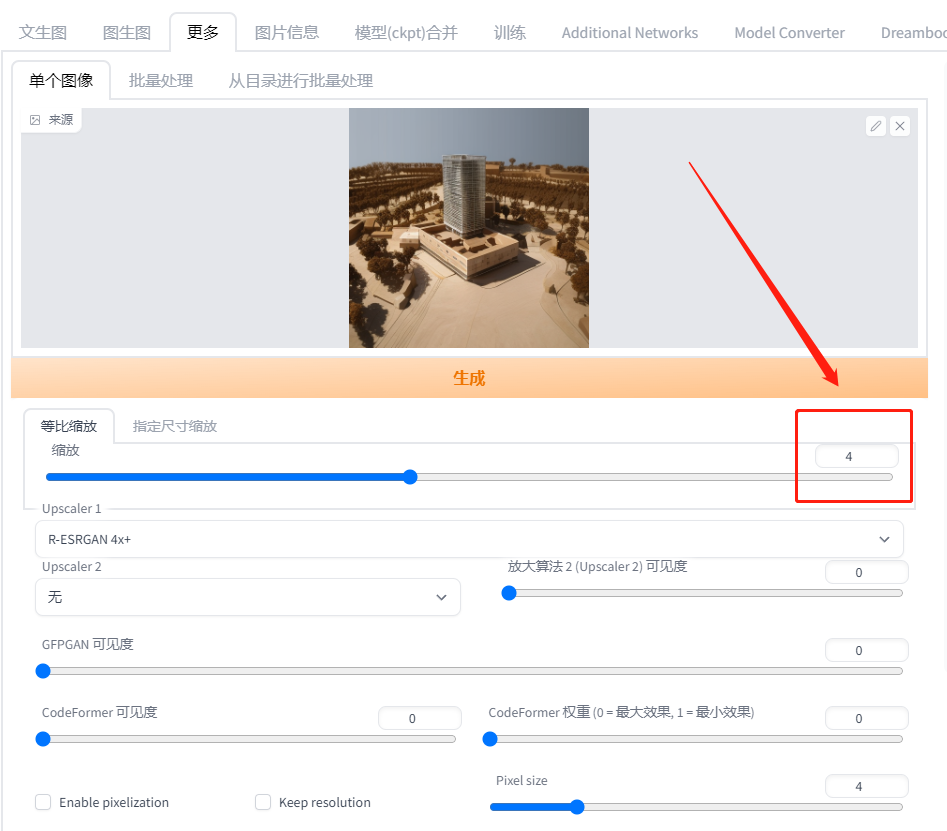
第5步:点击生成。让我们看一下修复前后的对比。


©绘图空间
07
总结
Summarize
在这个“全新”的设计时代来临之际,愿大家都可以尽快掌握新时代的设计工具。借用一句网络上略显危言耸听的话——“当蒸汽机面世的时候,淘汰的不是全部纺织工人,而是那些不会用蒸汽机的纺织工人。”
而本篇文章是绘图空间发布的第四篇建筑方向AI出图教程(错过之前文章的朋友可点击下方链接进行阅读),也是Stable Diffusion这款工具的第二篇文章。之所以选择对Stable Diffusion进行深化讲解,也是由于对于建筑方向来说,Stable Diffusion显得更加“实用”与“可控”。
当然,我们也不会“放过”Midjourney。请期待我们的后续教程,如果你有什么想了解的内容,也欢迎在评论区与我们留言互动。
08
AI训练手工模型作品分享
work sharing
在小红书上,我们也收集了一些AI建筑手工模型案例图片,与大家共同欣赏:

©小红书****FAKE千四

©小红书FAKE千四****

©小红书不是靖靖****

©小红书不是靖靖****

©小红书****不是靖靖

©小红书CreativeLab

©小红书CreativeLab

但由于AIGC刚刚爆火,网上相关内容的文章博客五花八门、良莠不齐。要么杂乱、零散、碎片化,看着看着就衔接不上了,要么内容质量太浅,学不到干货。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:

AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。

AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。


















 443
443

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









