






前言
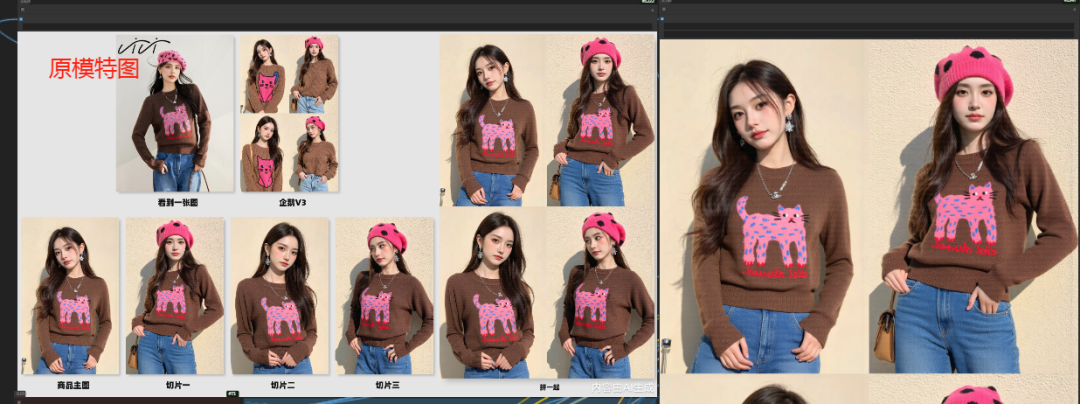
一键更换模特姿势,ComfyUI工作流分享
在创意图像生成领域,ComfyUI 正成为一款不可忽视的神器。作为一款专为 Stable Diffusion 设计的基于节点的图形用户界面(GUI),它通过链接不同的模块(称为“节点”)来实现图像生成的高自由度和高度定制化。今天,我们就来分享一个精彩的 ComfyUI 工作流:一键更换模特姿势,让你的创作效率直线飙升!

所有的AI设计工具,安装包、模型和插件,都已经整理好了,👇获取~

什么是 ComfyUI?
简单来说,ComfyUI 是一款为图像生成爱好者量身打造的工具,它以轻量化、快速、高效著称。与传统工具相比,ComfyUI 不仅运行速度更快,对硬件的要求也相对较低,非常适合低配置设备使用。
更重要的是,它提供了一个独立的 GUI 界面,用户可以在本地环境中轻松构建和执行复杂的图像生成工作流,无需依赖其他平台或云端环境。
它的核心亮点包括:
-
节点式操作:数据流清晰可见,构建逻辑直观。
-
高度灵活性:支持高度自定义和工作流复用。
-
易于分享:每个工作流文件都可复现,非常适合分享和交流。
ComfyUI 的节点工作流
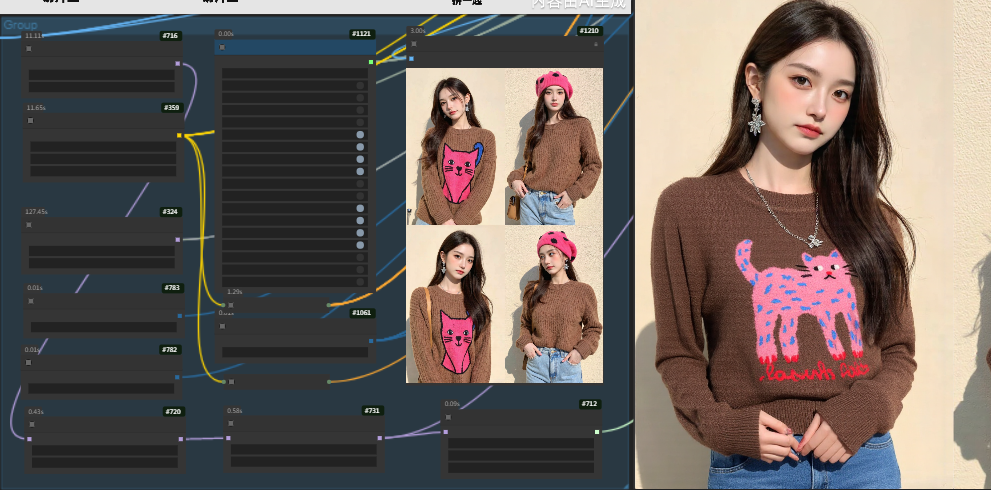
在这个一键更换模特姿势的工作流中,节点是核心。以下是本次工作流中的 Primitive Nodes(基础节点) 和 Custom Nodes(自定义节点):
基础节点(Primitive Nodes):
-
CLIPTextEncode:文本编码,解析提示词。
-
CLIPVisionLoader:加载 CLIP 模型以支持视觉操作。
-
LoadImage、SaveImage:图像加载与保存,支持快速输入输出。
-
UNETLoader、VAELoader:用于模型的加载和解码,支持高效生成。
自定义节点(Custom Nodes):
-
Image To Mask、GrowMask:处理图像遮罩,精准控制需要更改的区域。
-
BasicScheduler、DifferentialDiffusion:调度与扩散,调整生成策略。
-
RandomNoise:增加噪声,为模型生成提供更多随机性。
-
ImageCrop+、ImageBlendAdvance V2:裁剪和混合图像,提供更精细的图像操作。
-
LayerUtility: ColorPicker:为图像上色,进一步提升画面质感。
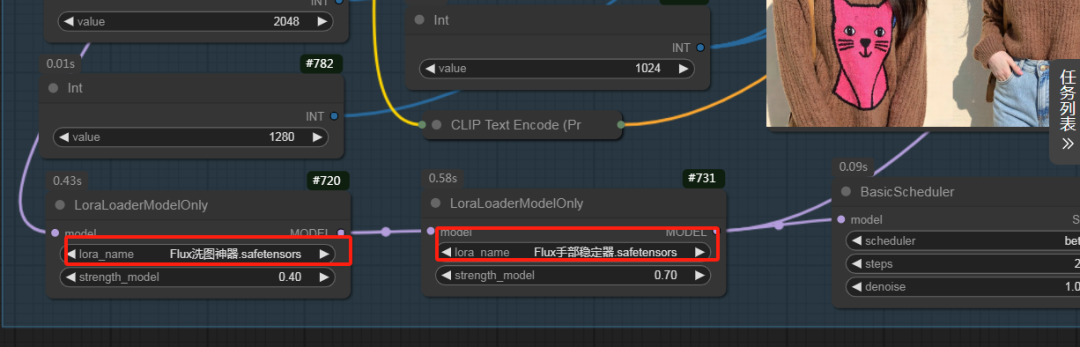
一键更换模特姿势的实现原理
-
导入图像:通过
LoadImage节点加载目标模特图像。 -
生成遮罩:使用
Image To Mask和GrowMask节点标记需要修改的区域,例如模特的身体姿态。 -
应用扩散算法:借助
DifferentialDiffusion节点对目标区域进行扩散生成。 -
更新姿势:结合
RandomNoise节点,为模特重新生成姿势,并通过CLIPTextEncode调整提示词实现控制。 -
导出结果:生成图像后,通过
SaveImage节点保存文件,同时可一键分享整个工作流文件。
为什么选择 ComfyUI?
-
上手容易,功能强大
无论是新手还是高级用户,都能轻松驾驭 ComfyUI 的工作流。其模块化设计直观、灵活,特别适合尝试不同风格和效果。 -
社区支持强大
作为开源项目,ComfyUI 的 GitHub 社区提供了丰富的资源。用户不仅可以获取最新的节点,还能下载他人分享的优秀工作流,省去了复杂调试的过程。 -
低配置友好
对于硬件性能有限的用户来说,ComfyUI 无疑是绝佳选择。它在低配置设备上的表现依然流畅,让更多创作者能够体验图像生成的乐趣。
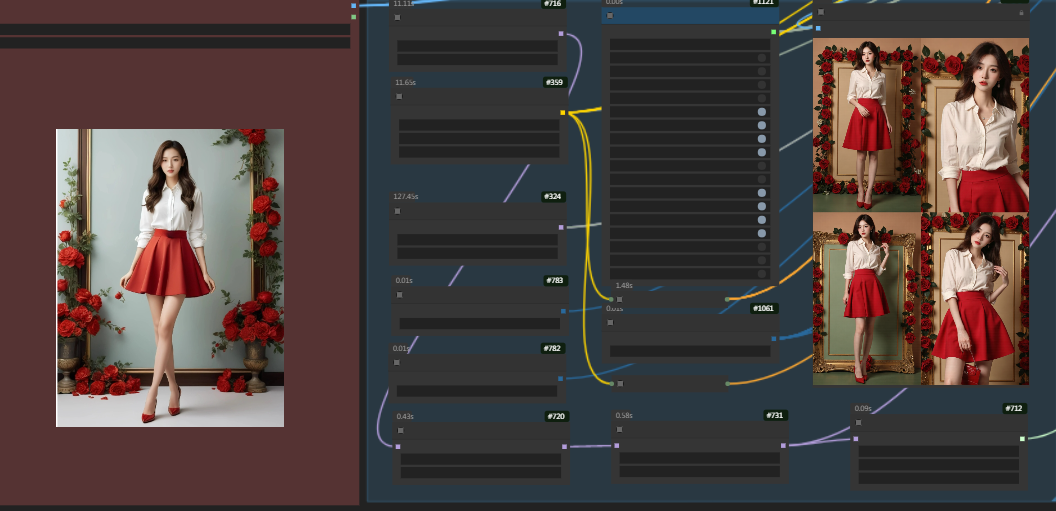
应用场景
-
电商设计:快速更改模特姿势,实现多样化的产品展示。
-
数字艺术:创作风格多变的插画和艺术作品。
-
视频与动画制作:结合图片动画化功能,实现动态视觉效果。
ComfyUI 的一键更换模特姿势工作流,不仅让创作者能更高效地探索图像生成的可能性,还能大幅降低操作门槛。无论是对技术有深入研究的老手,还是刚接触 AI 图像生成的新手,ComfyUI 都提供了无与伦比的创作自由。
快试试这款神器,搭建属于自己的工作流吧!
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈

👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 4609
4609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









