






针对openmv使用云端生成神经网络模型过程中,可能出现的报错,还有0特征点现象,所以我将手把手从一而终教会你整个流程,解决出现的报错等问题,保证能成功训练出神经网络模型,实现目标识别。
(1)准备好OpenMV4 Plus(低版本的openmv可能算力不够不支持)
(2)打开openmv软件如图所示,点击新数据集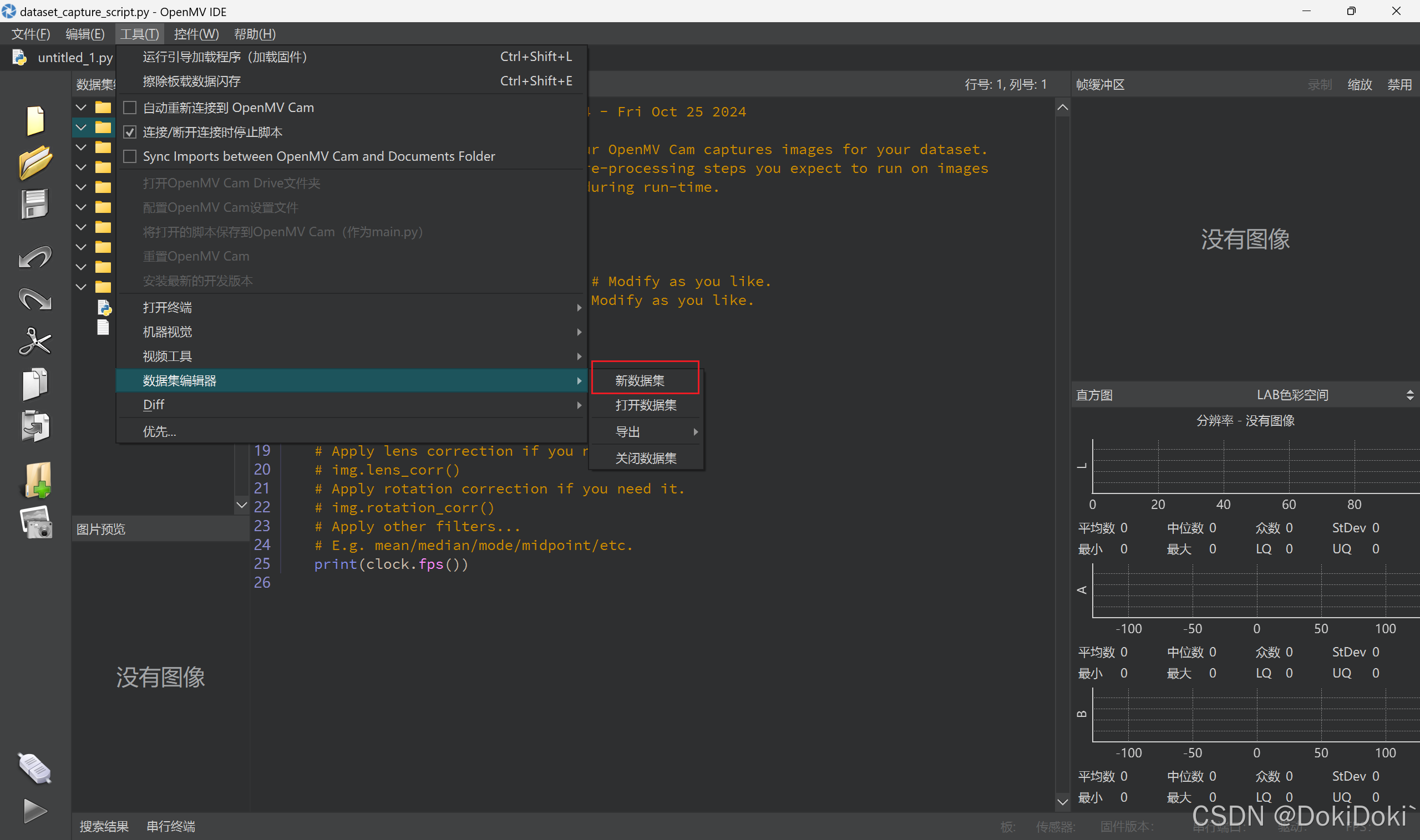
在磁盘里创建一个新的文件夹,用来放置一会要存放的数据集:
(这里找个自己喜欢的位置存放即可)
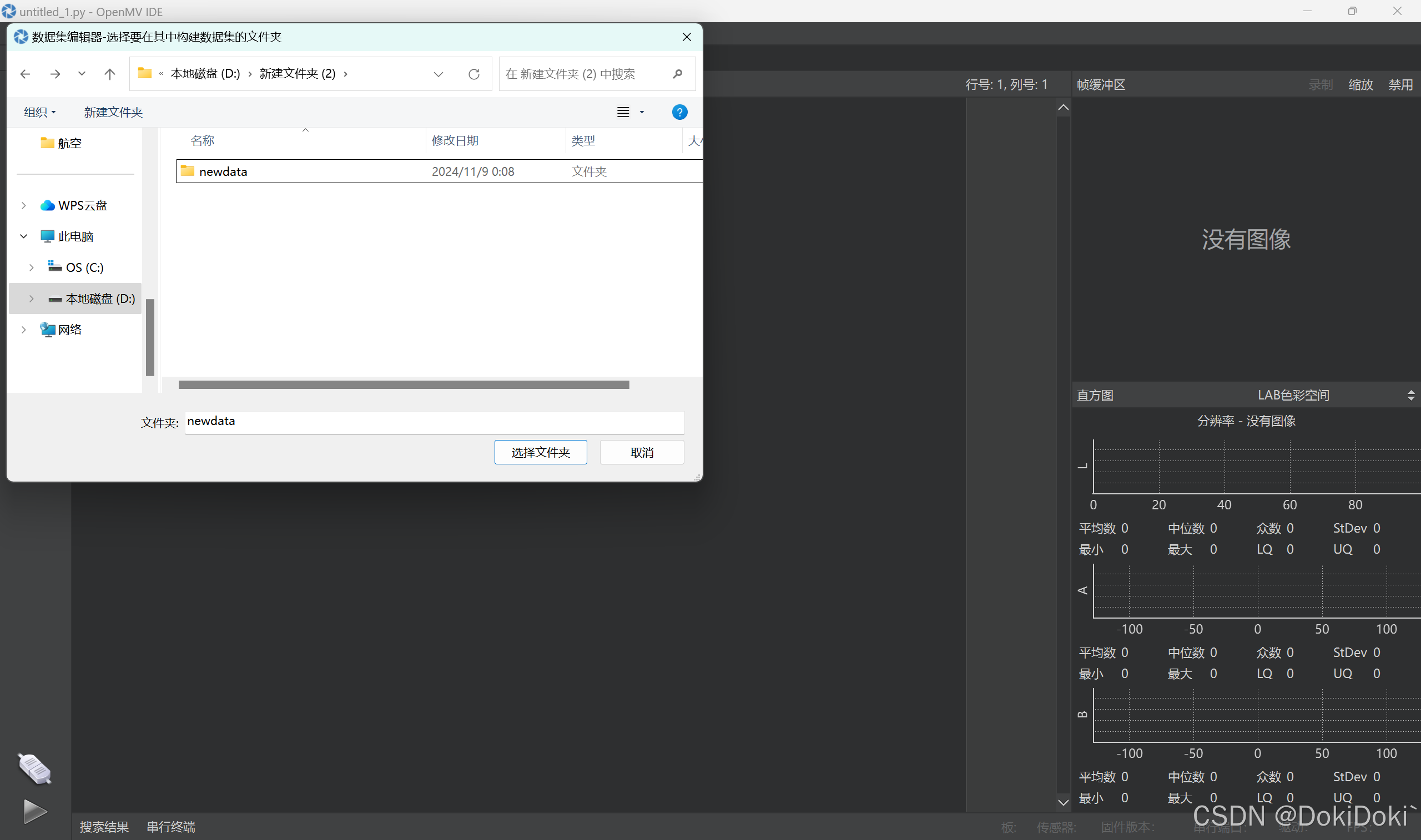
(3)选择之后,点击红框框起来的地方
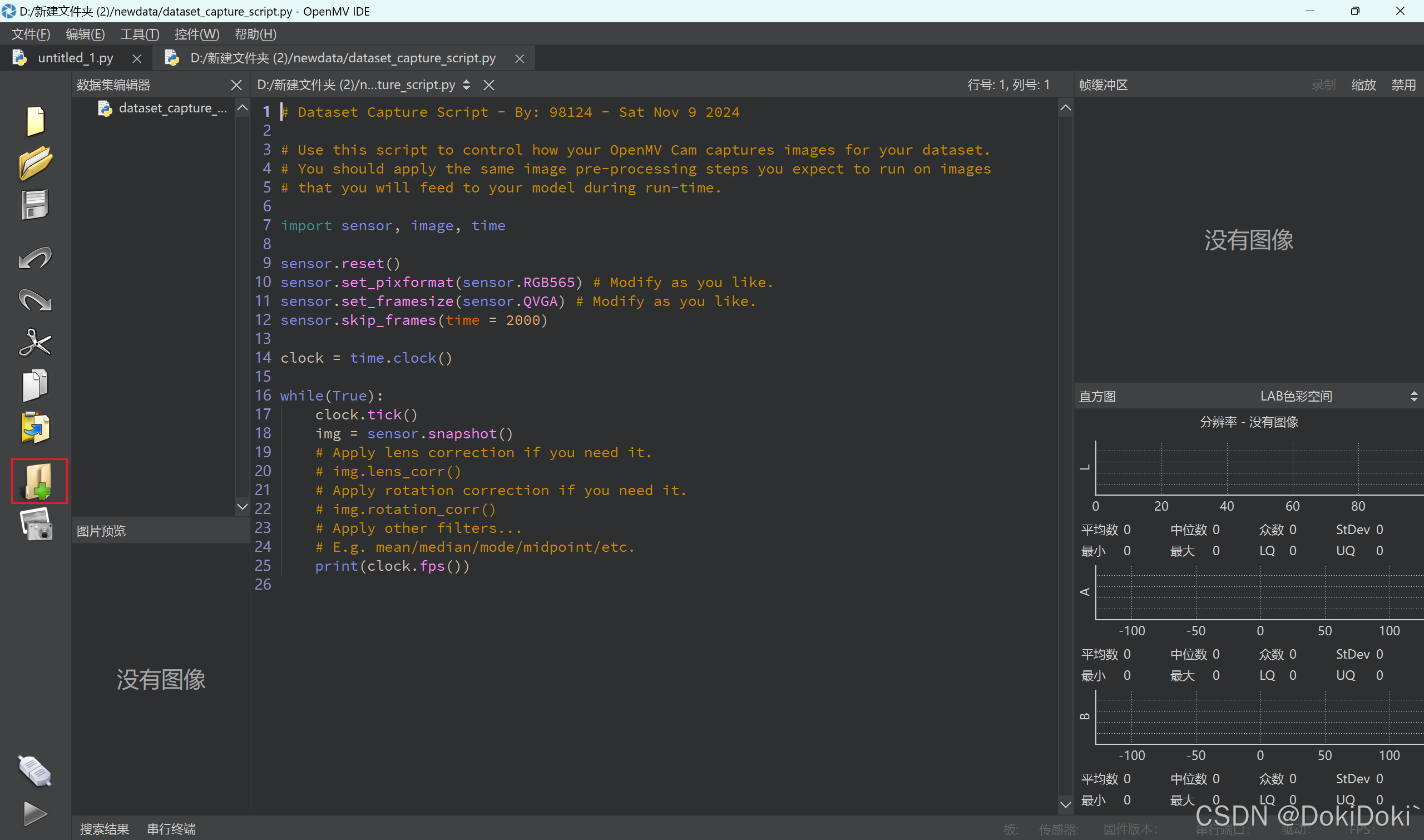
然后创建需要识别的对象的列表名称:(类似于这样)
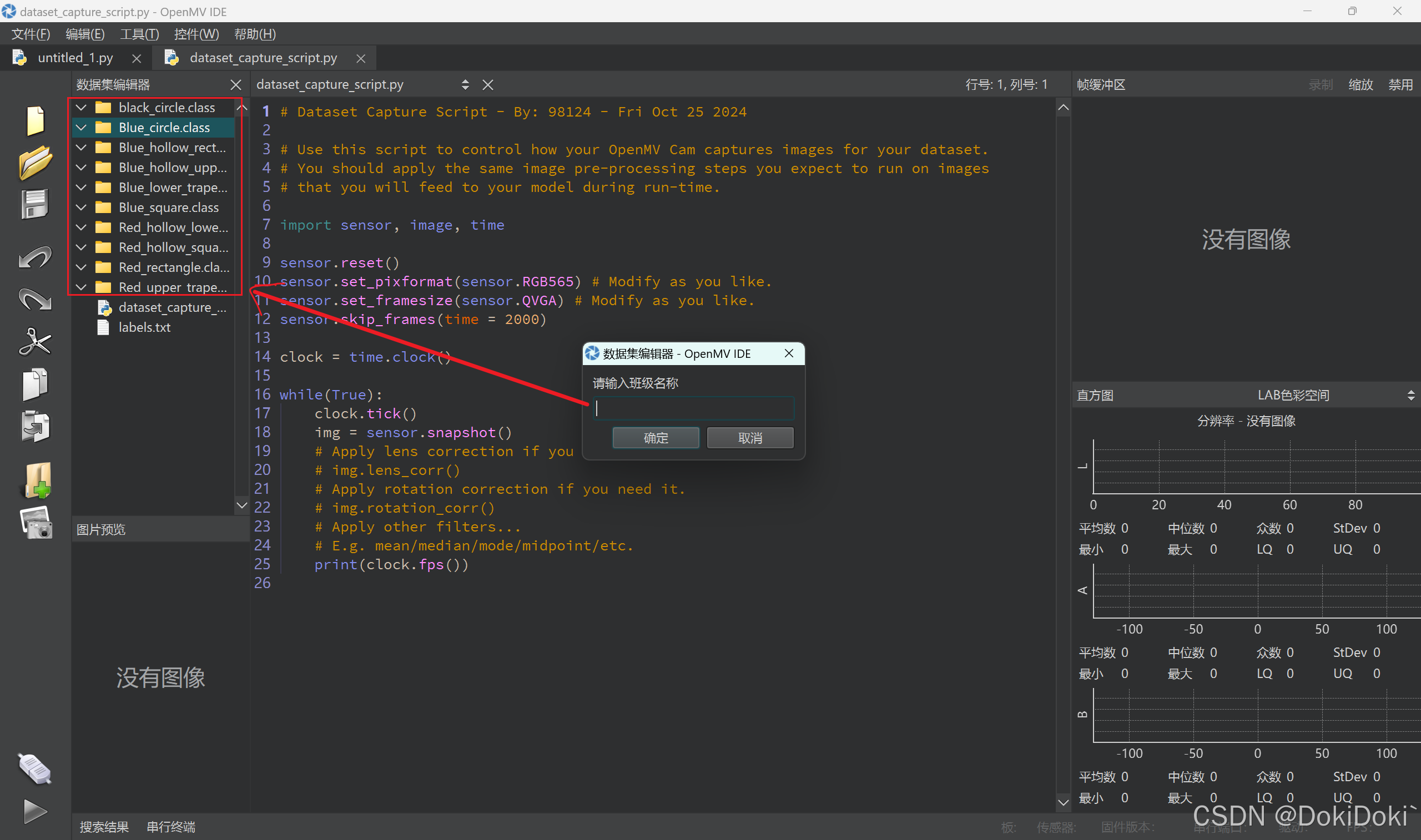 (4)在列表中对所需要的识别进行拍照取样:(需要连上openmv并打开,对着你需要识别的目标点击红框进行拍照取样,可以选择拍150~200张,理论上拍照角度越多,并且保证其特征明显,这样训练出来的模型准确率越高,识别效果越好)
(4)在列表中对所需要的识别进行拍照取样:(需要连上openmv并打开,对着你需要识别的目标点击红框进行拍照取样,可以选择拍150~200张,理论上拍照角度越多,并且保证其特征明显,这样训练出来的模型准确率越高,识别效果越好)
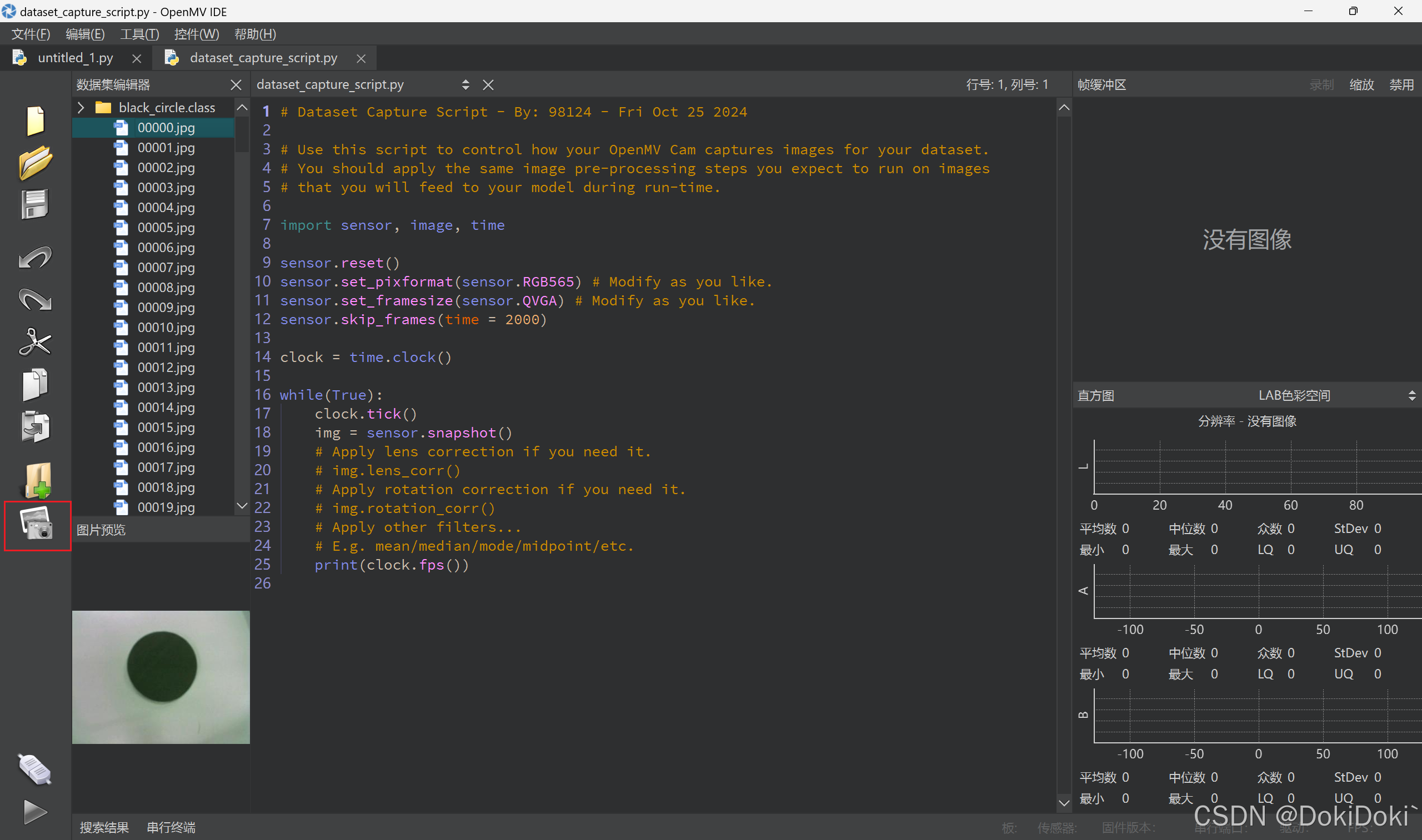 (5)依次对你需要识别的目标拍完照后,在浏览器上搜索Login - Edge Impulse,进行注册。
(5)依次对你需要识别的目标拍完照后,在浏览器上搜索Login - Edge Impulse,进行注册。
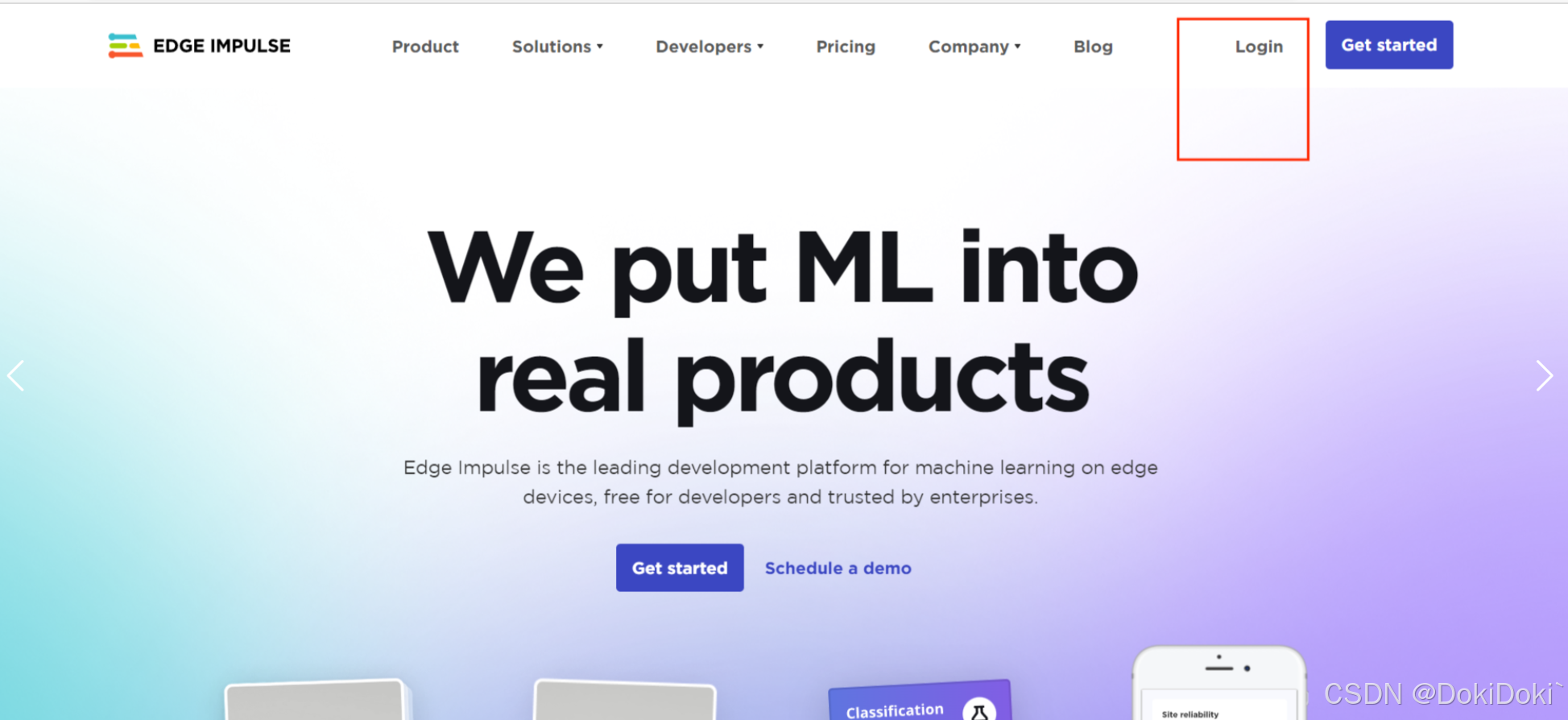
注册完成后,点击一下头像,出现这个下拉菜单,点击红框创建新项目。
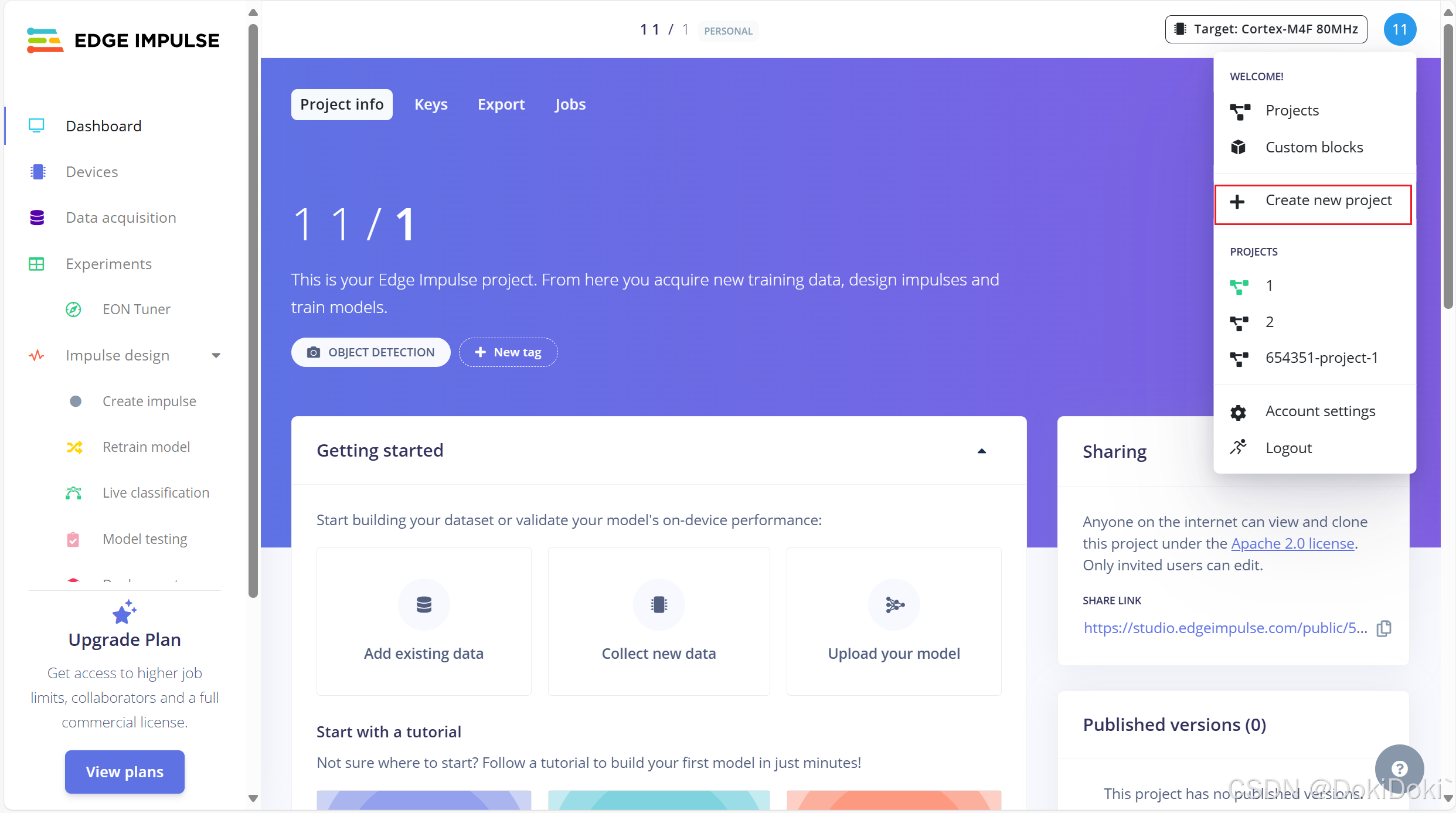
只需在方框中填入你要创建的文件名字,然后点击创建。
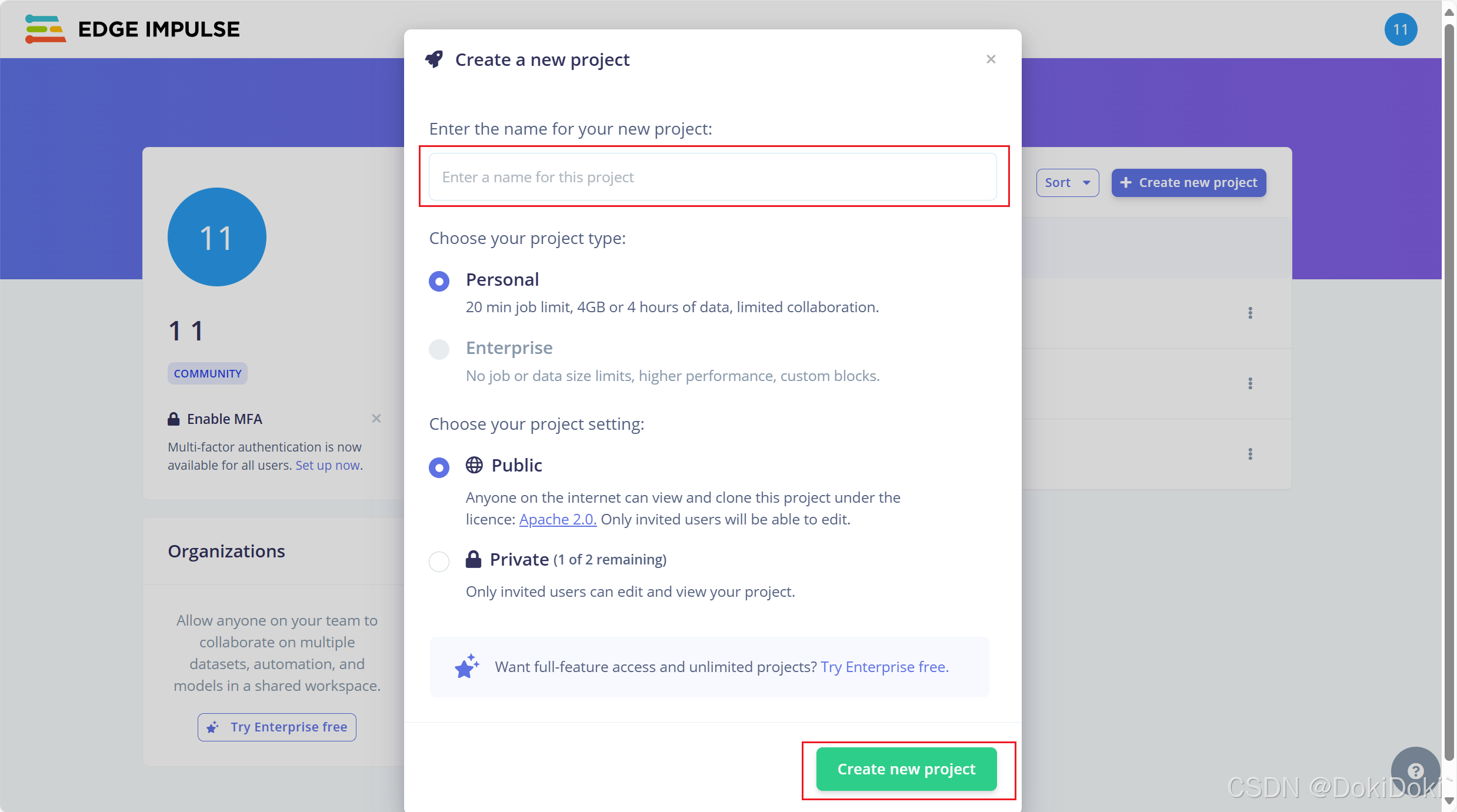
创建完成后会进入这个页面,点击红框keys
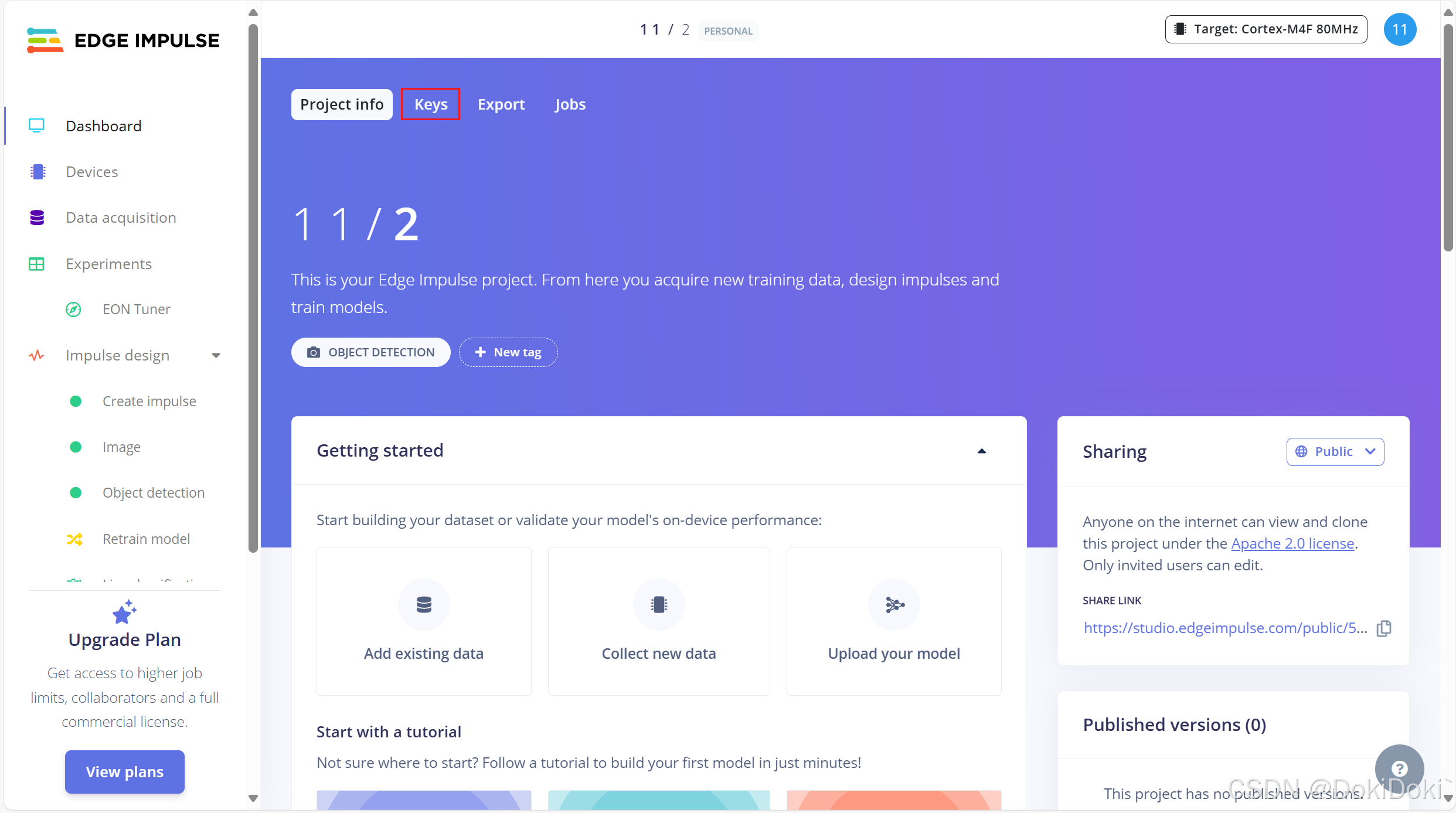
然后复制它的API Key
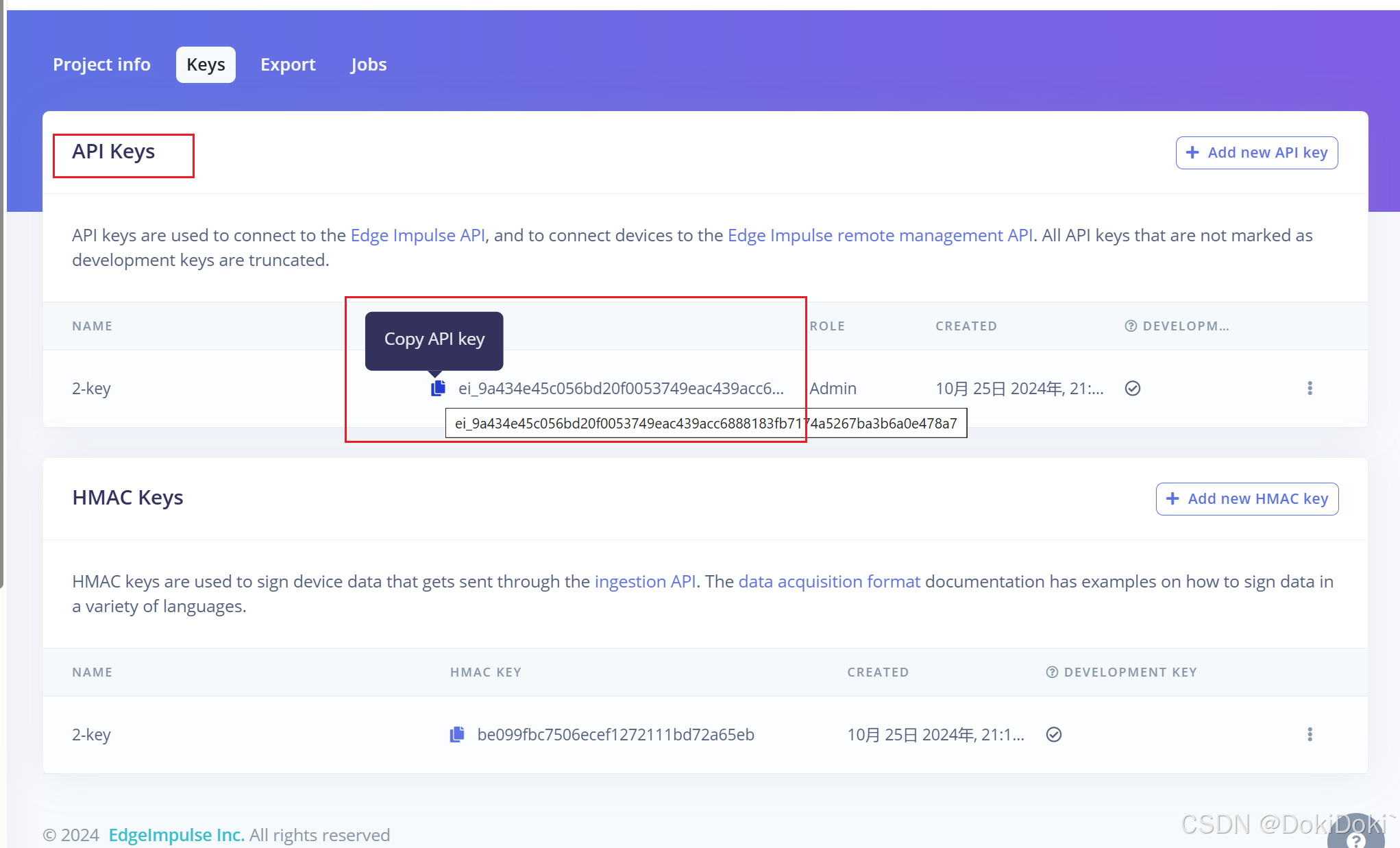
再将你复制到的API Key输入进去,就可实现将拍摄的数据集上传到该云端。
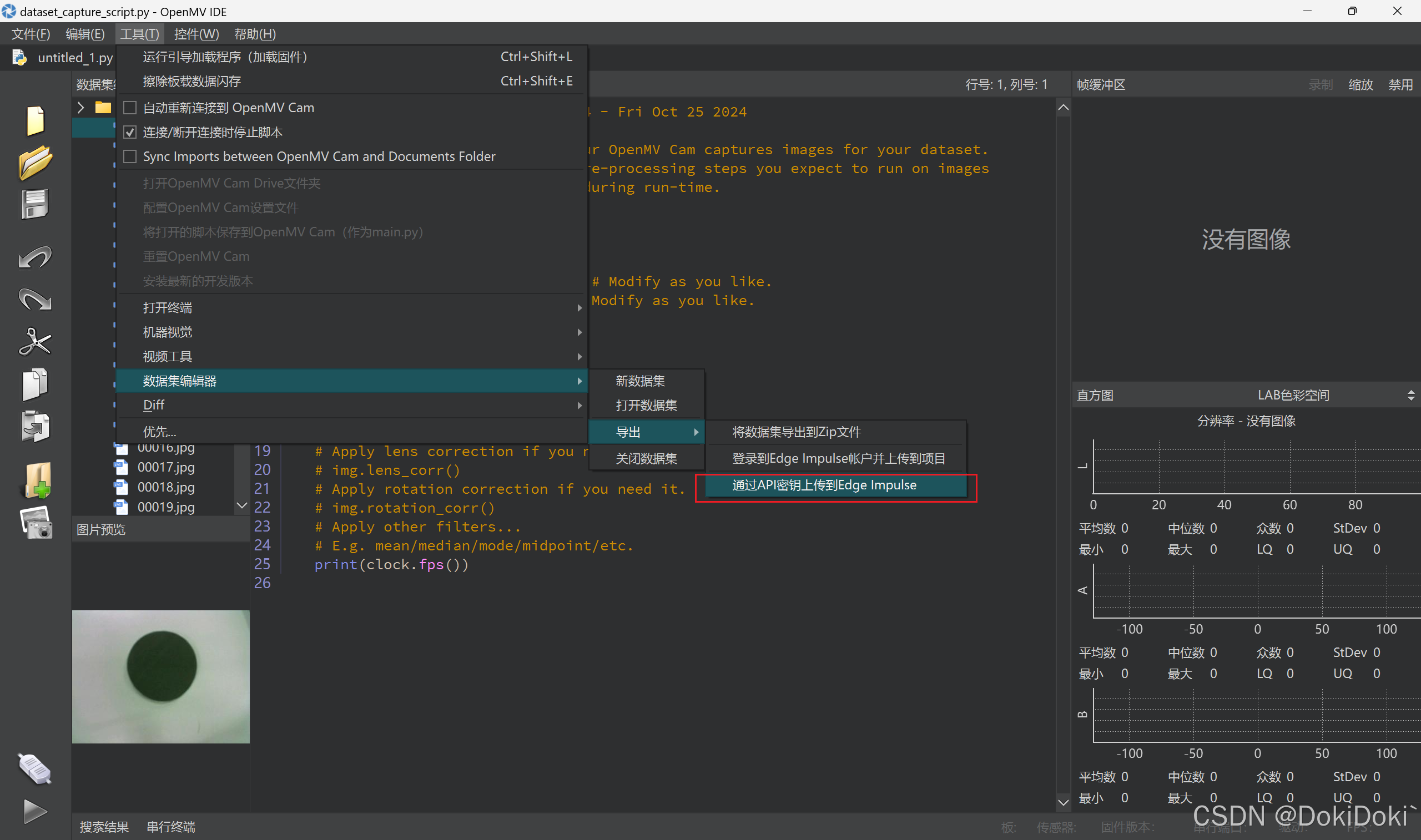

(6)接下来一步很关键,我看了很多教程包括星瞳科技,都没有人说这一步,是我自己琢磨出来的,包括有些教程最后没有出来结果,也是因为没有这一步——也就是所说的框图
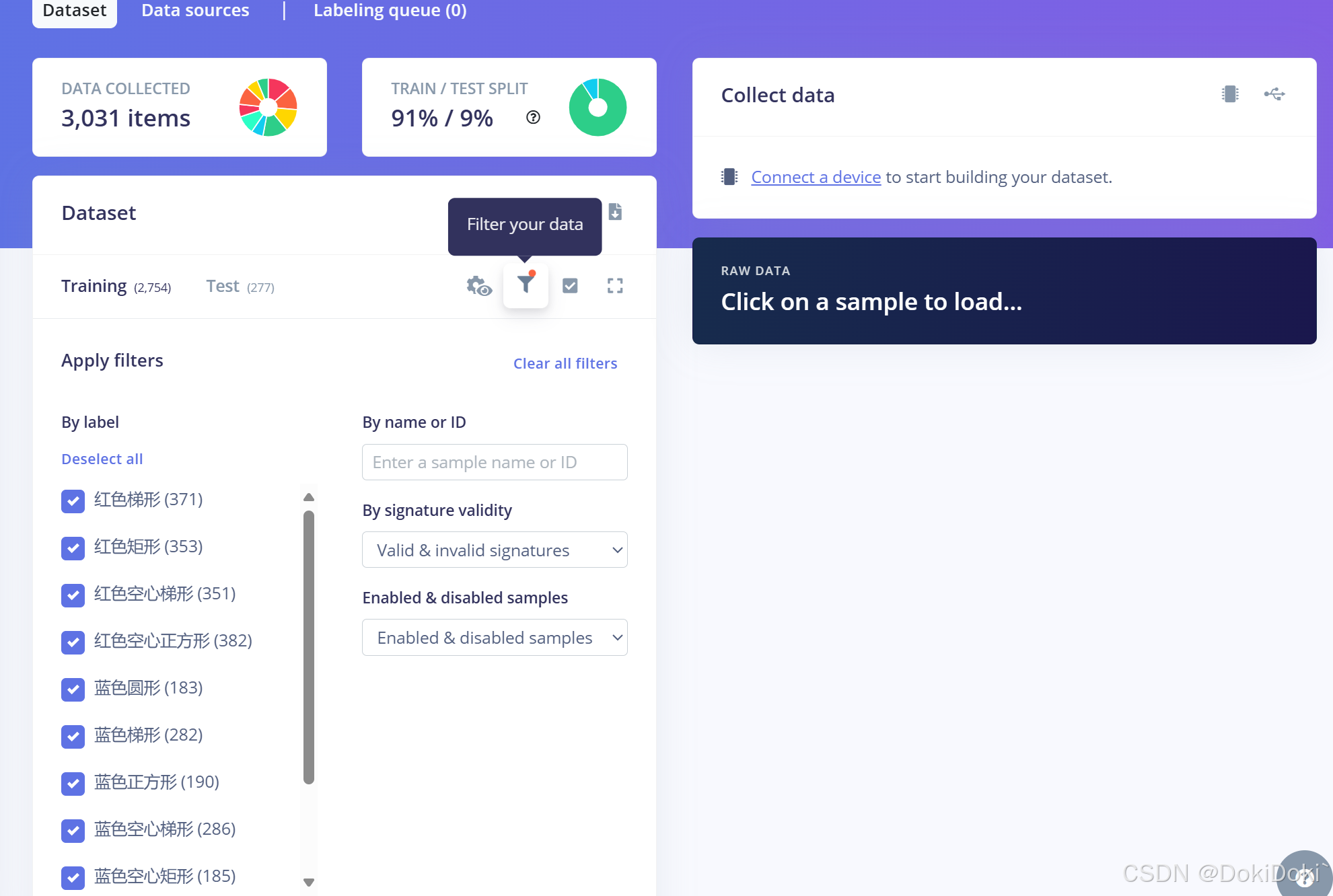
在Data acquisition界面里,点击红框2:(我这里显示的是0,是因为我已经全部框完了,给每个照片都附上了标签)
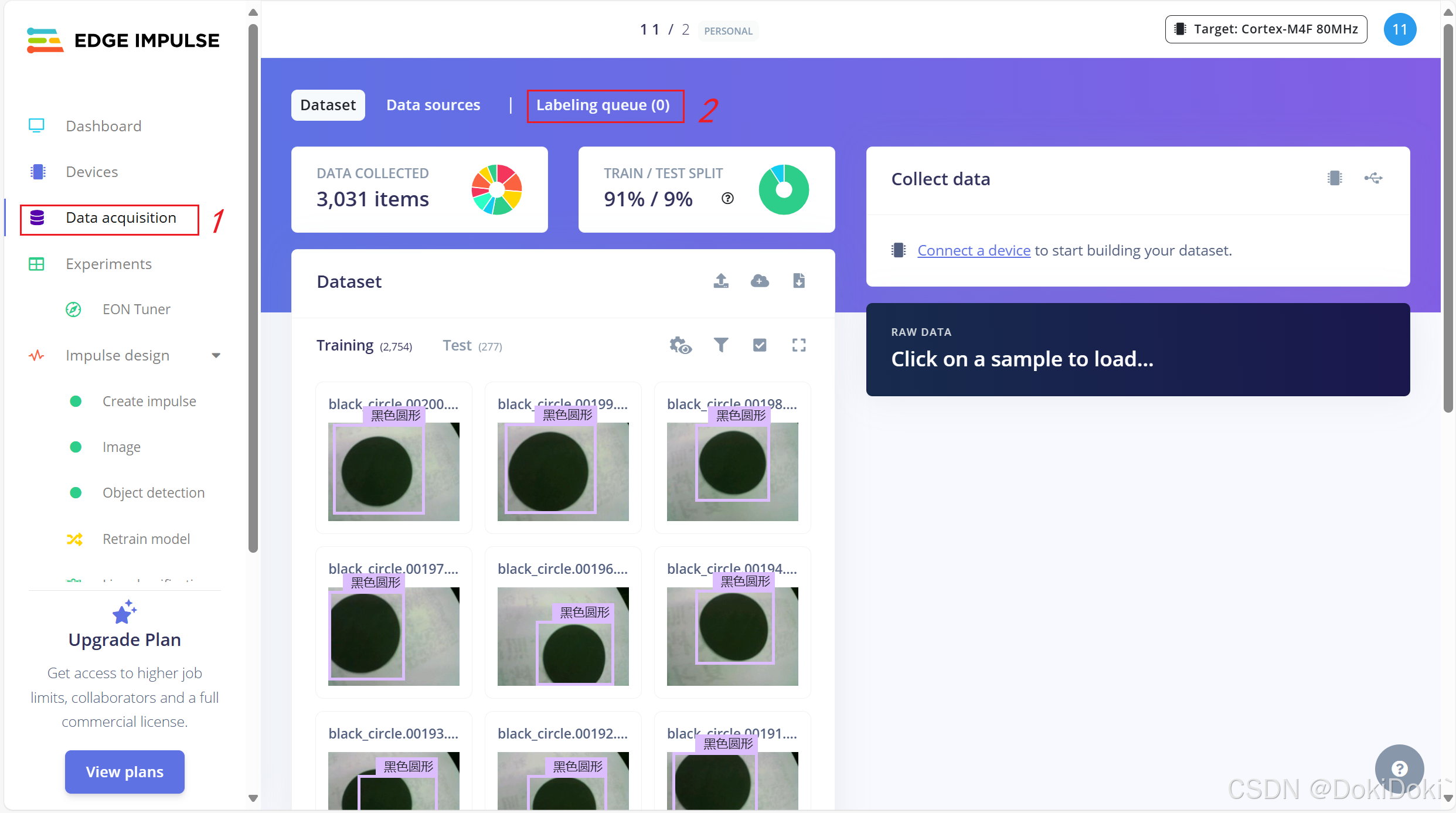
红框2里会显示你拍过的照片,需要你对你拍摄的目标画框,给标签
(这个还是相对人性化的设计,框了一个之后后面AI会自动帮你框住,不过有时候不大准确需要手动调整,其他的只要不是变换识别目标时,需要重新给标签,就只需要库库点击save即可,)
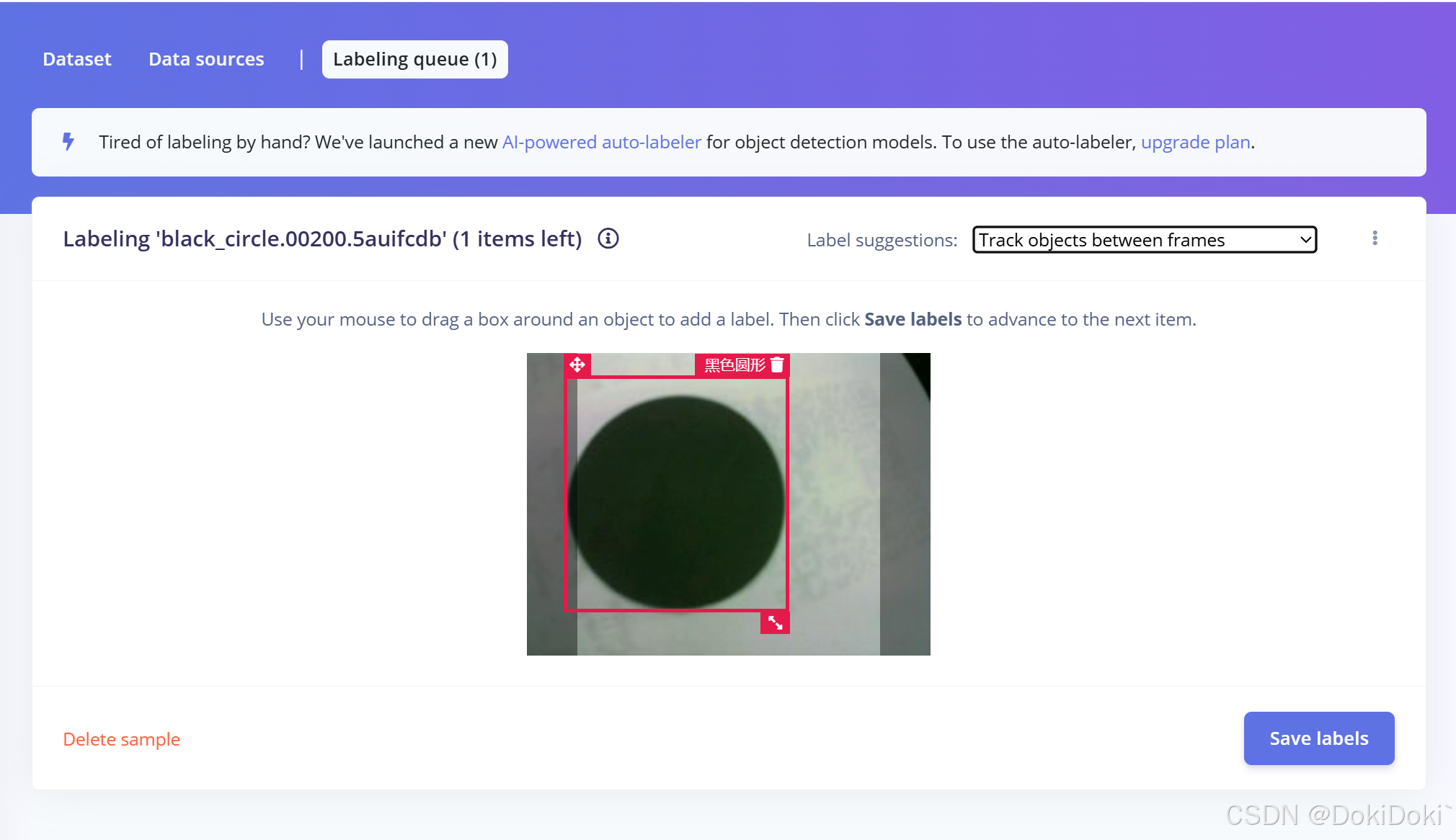
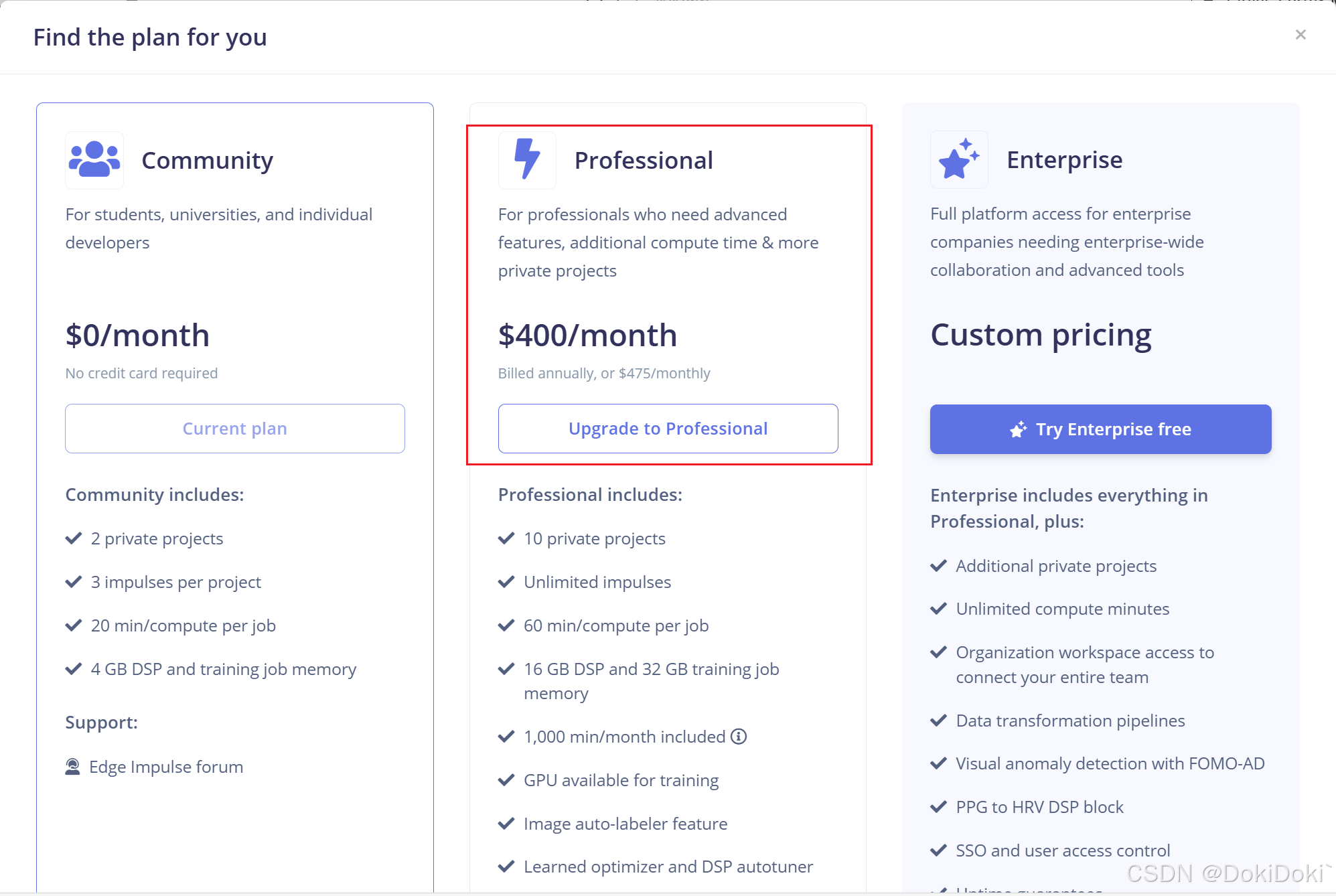
(当然,要是实在是不想点,也可以点击 upgrade plan,花费400美刀每月,即可获得全AI服务)

画完框之后,你也可以在这里看到你的标签和里面的目标个数,你可以对里面画框不满意的选择删除或者重新画框
(7) 找到impulse design ,点击creat impulse,会进入下面这个界面:(我的impulse design下面的子列表开头是绿圈圈,是因为我已经操作过了,要是没操作过是灰圈圈)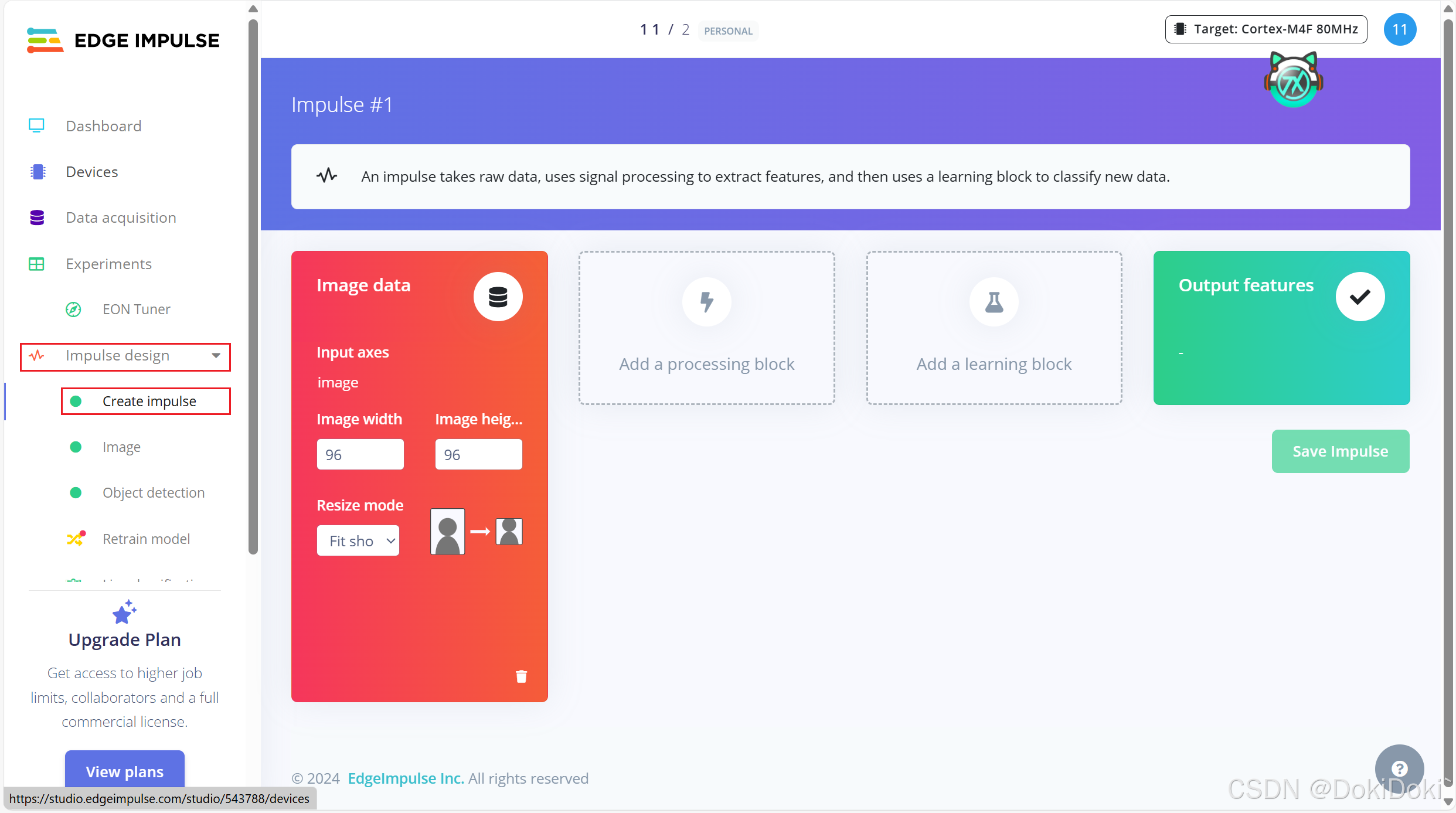
然后点击 Add block,选第一个推荐即可
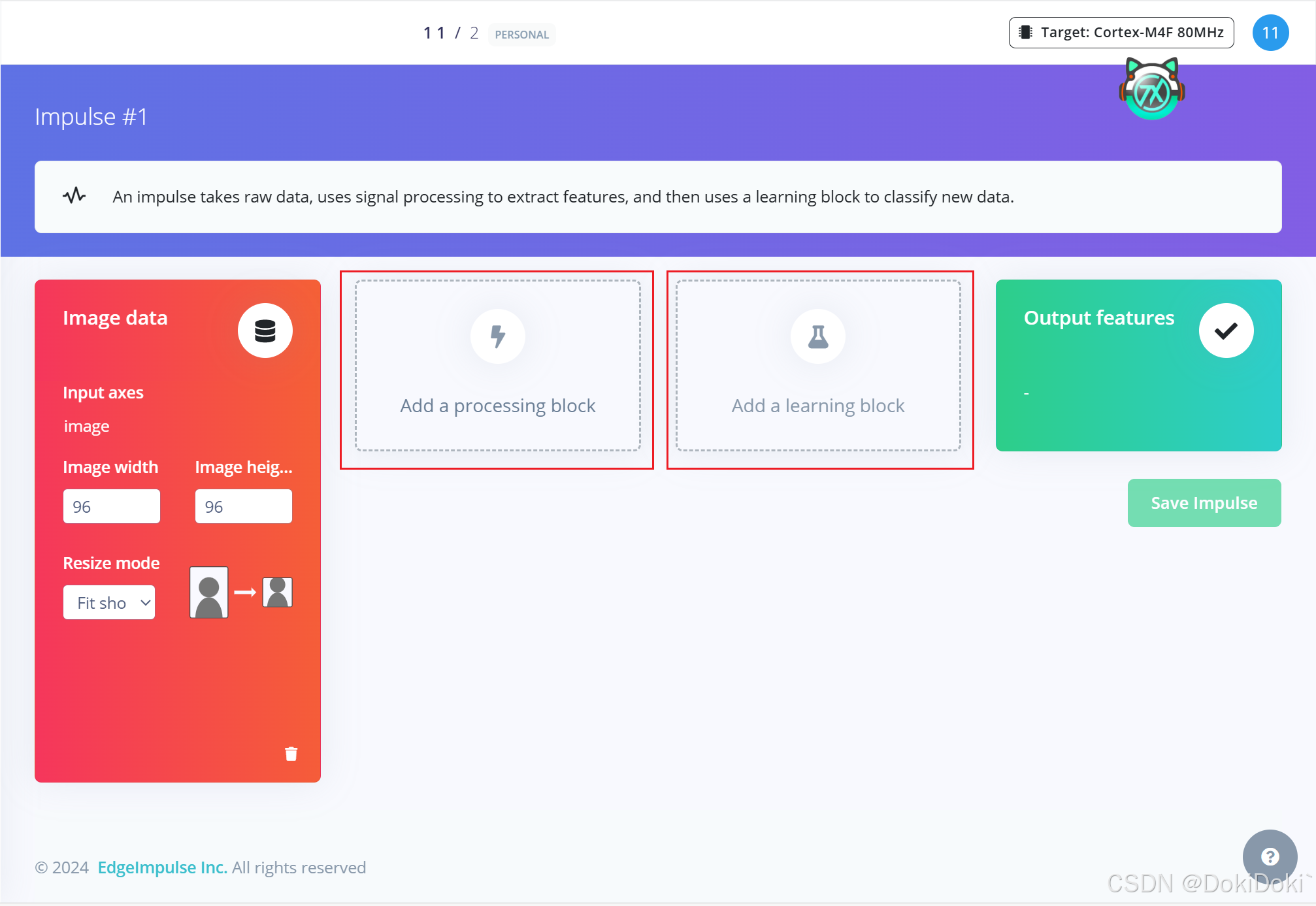
添加完之后会自动出现输出特性,对应你画框的标签,这个一定要出现的,要是没出现特征,后续操作会出错,出不来结果。如果出现了你设立的标签,点击save,进行下一步
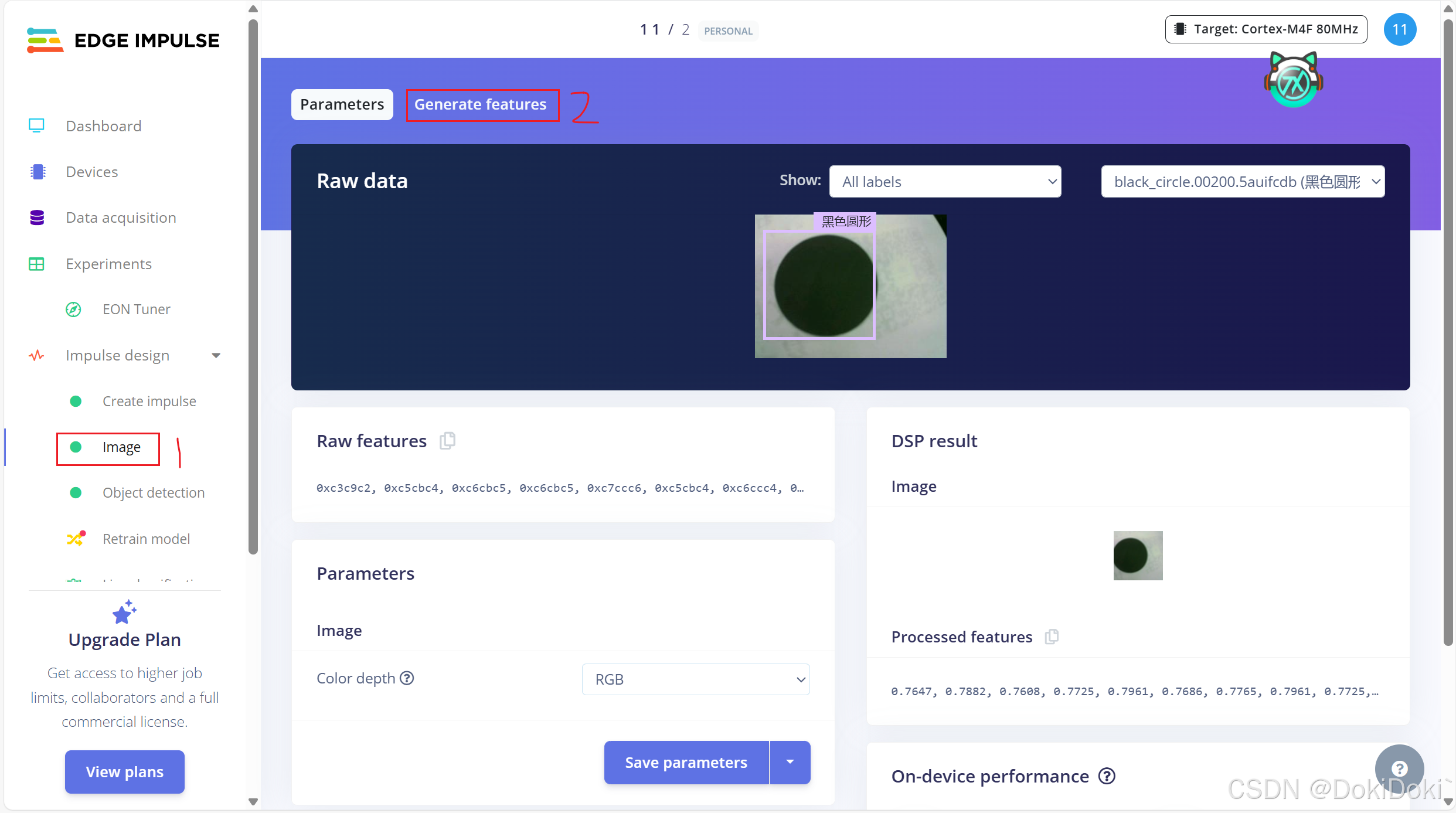
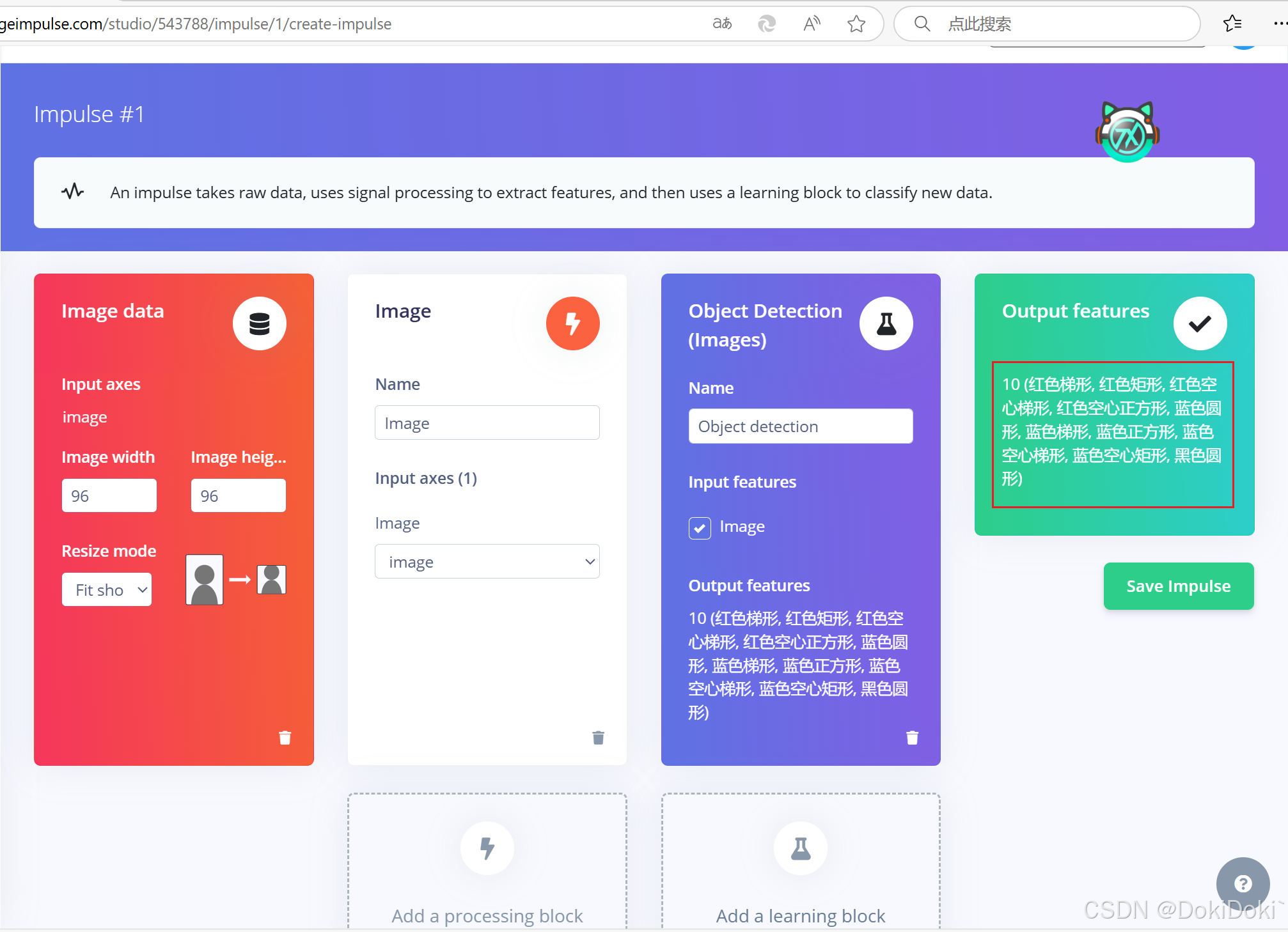 (8)点击image,根据你的需求选择是使用RGB还是灰度,在下方Color depth中更改即可,记得保存。默认是RGB。接着点击Generate features生成特征
(8)点击image,根据你的需求选择是使用RGB还是灰度,在下方Color depth中更改即可,记得保存。默认是RGB。接着点击Generate features生成特征
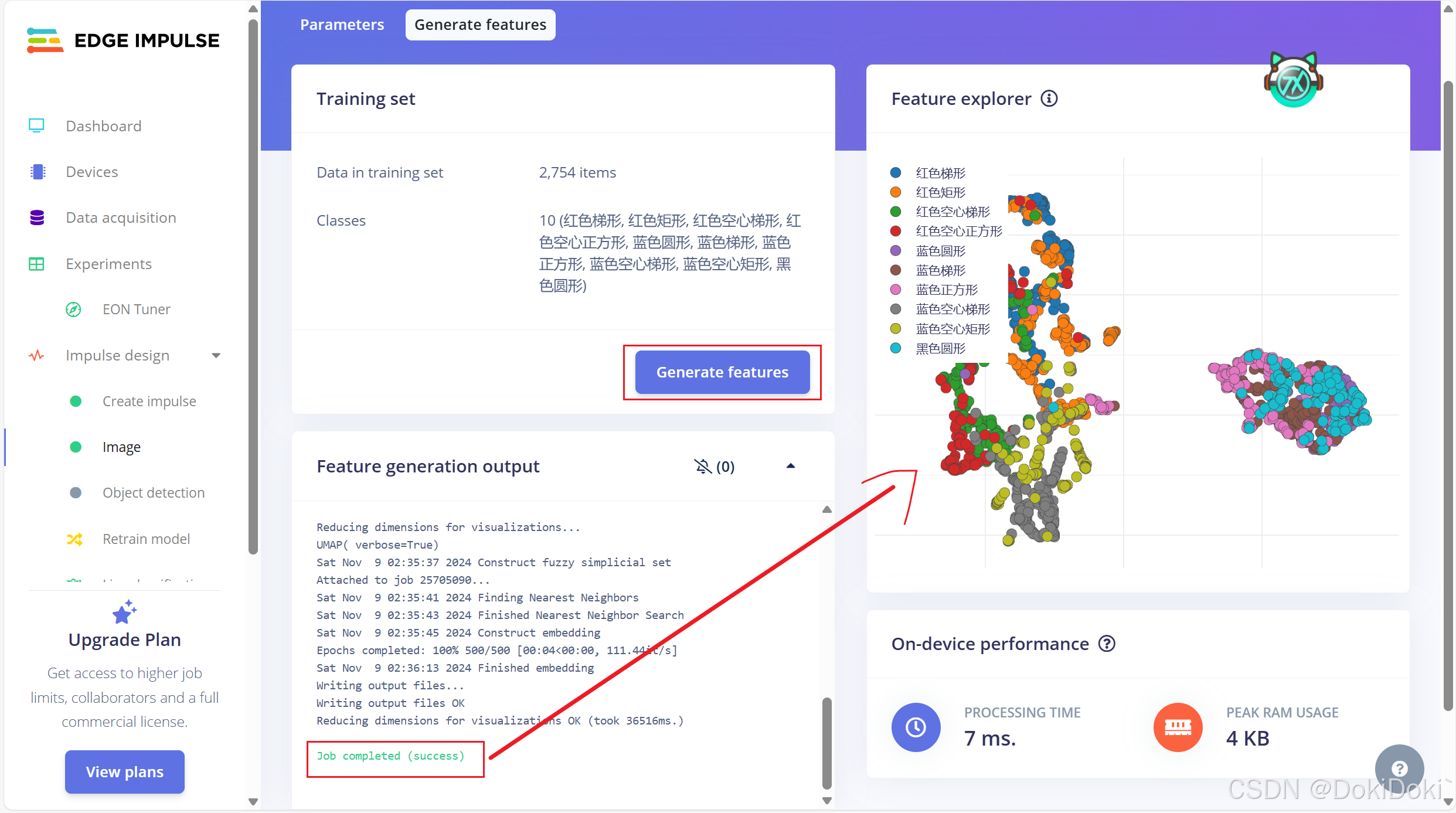
点击生成特征,出现success就说明生成好了,右边是样本特征的分布的图式。
 (9)点击红框,出现下面这个界面,不需要更改model,然后点击下面的训练
(9)点击红框,出现下面这个界面,不需要更改model,然后点击下面的训练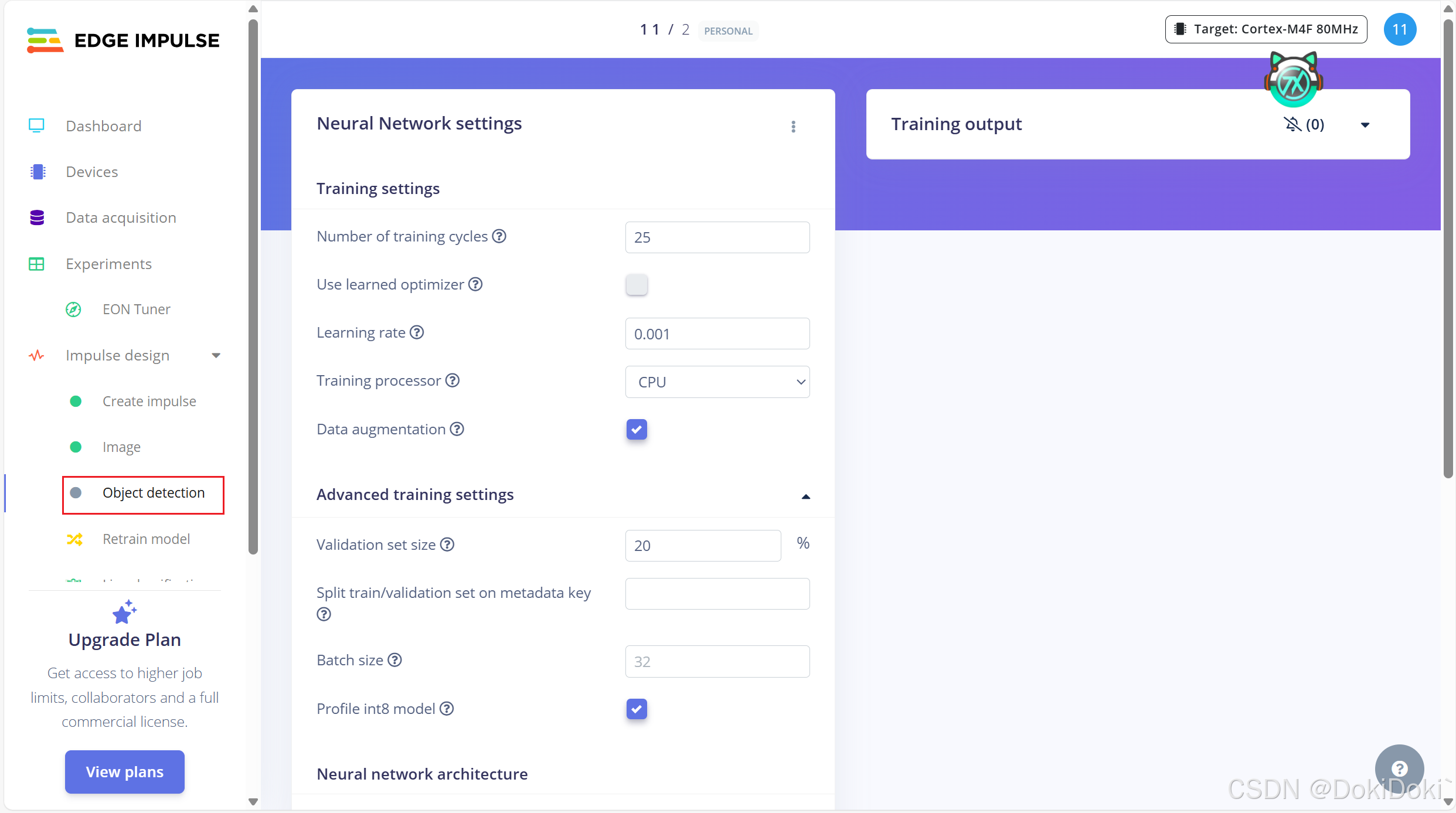
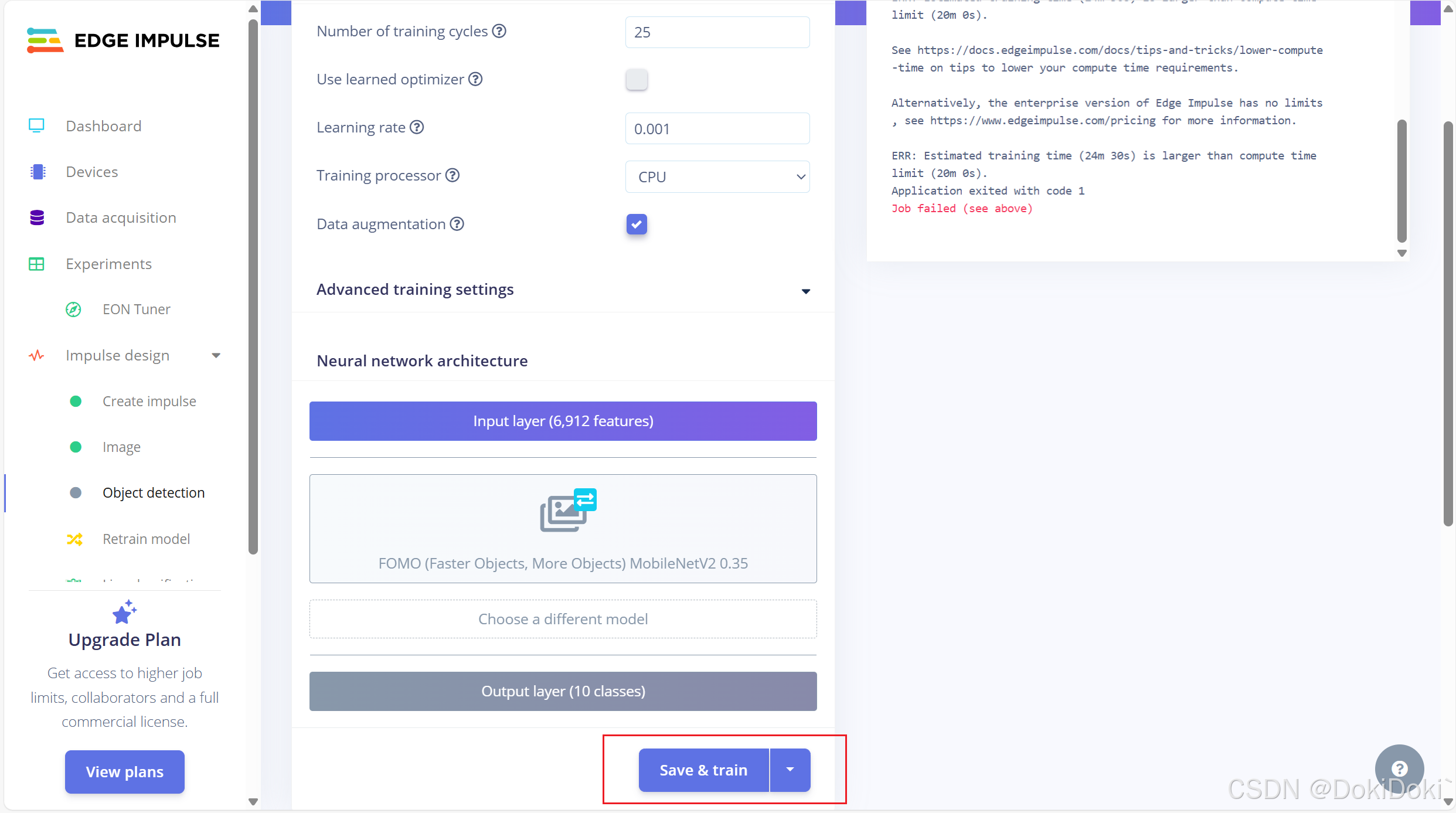
训练的时候很可能会报错,比如说我上图出现了failed,它报错说我训练的时间会大于20min,这怎么办呢。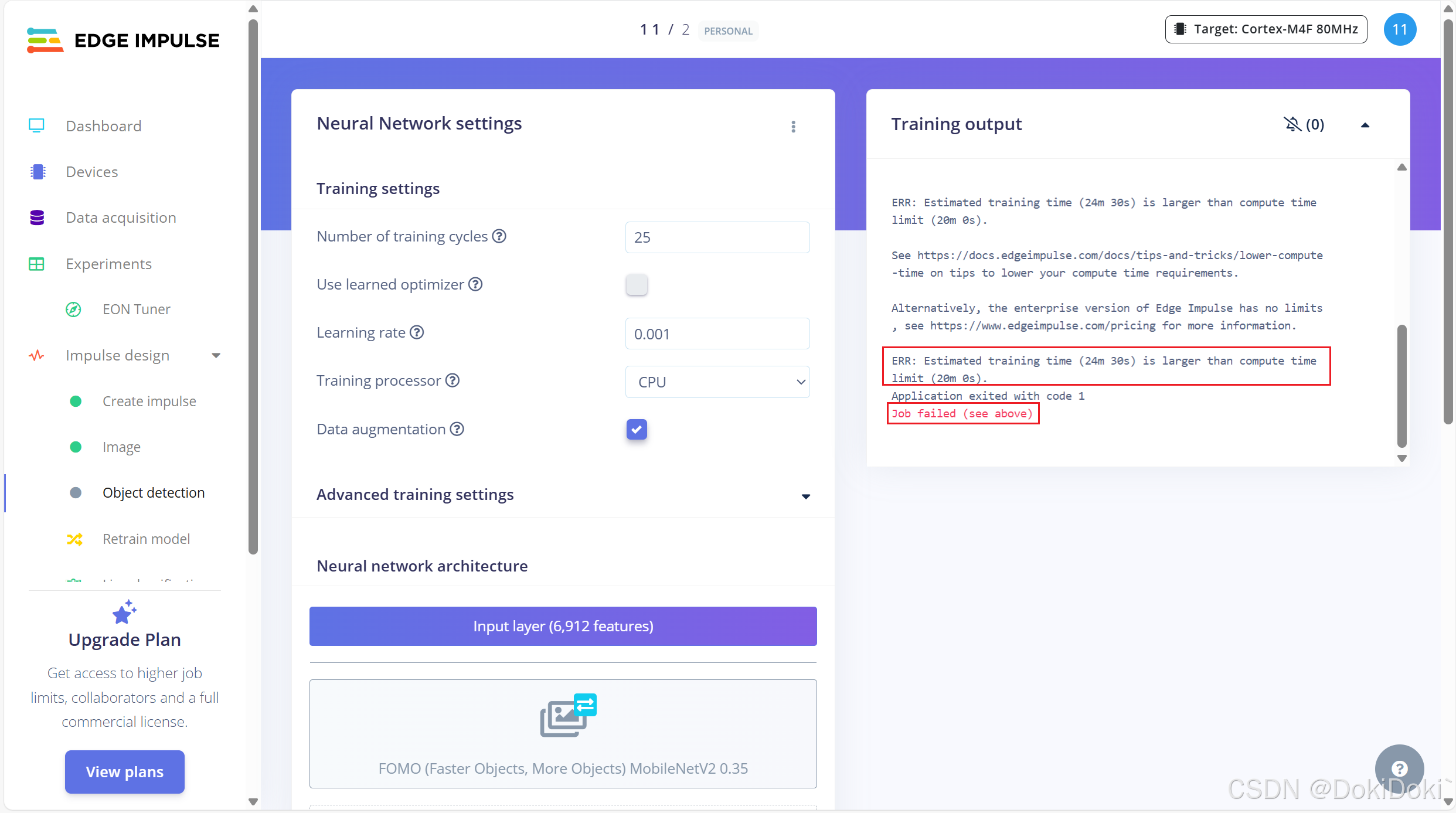 1.可以更改图像的长宽大小,把它变小点,处理的就会更快一点
1.可以更改图像的长宽大小,把它变小点,处理的就会更快一点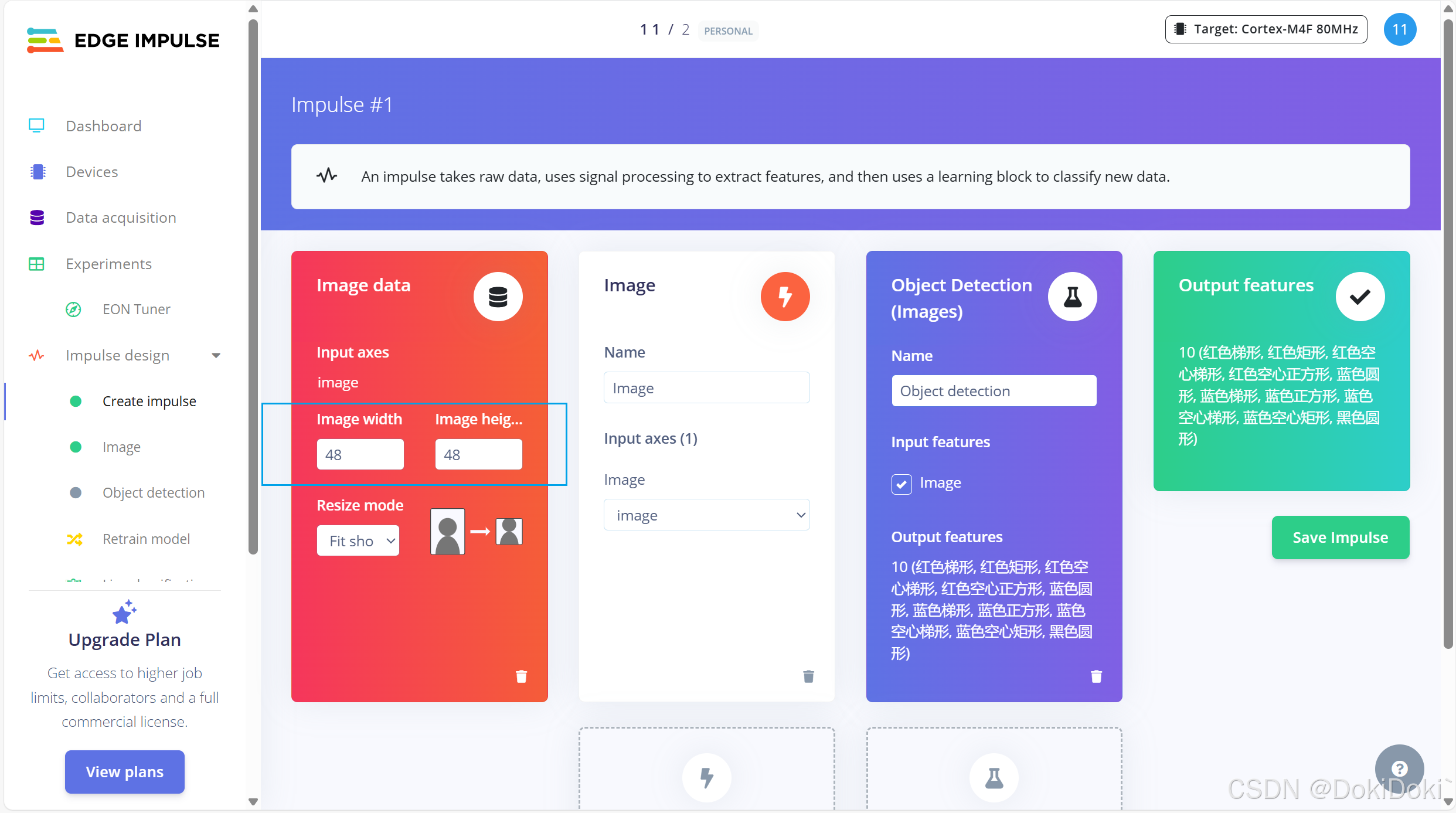 2.减少训练周期,把数值调小一点
2.减少训练周期,把数值调小一点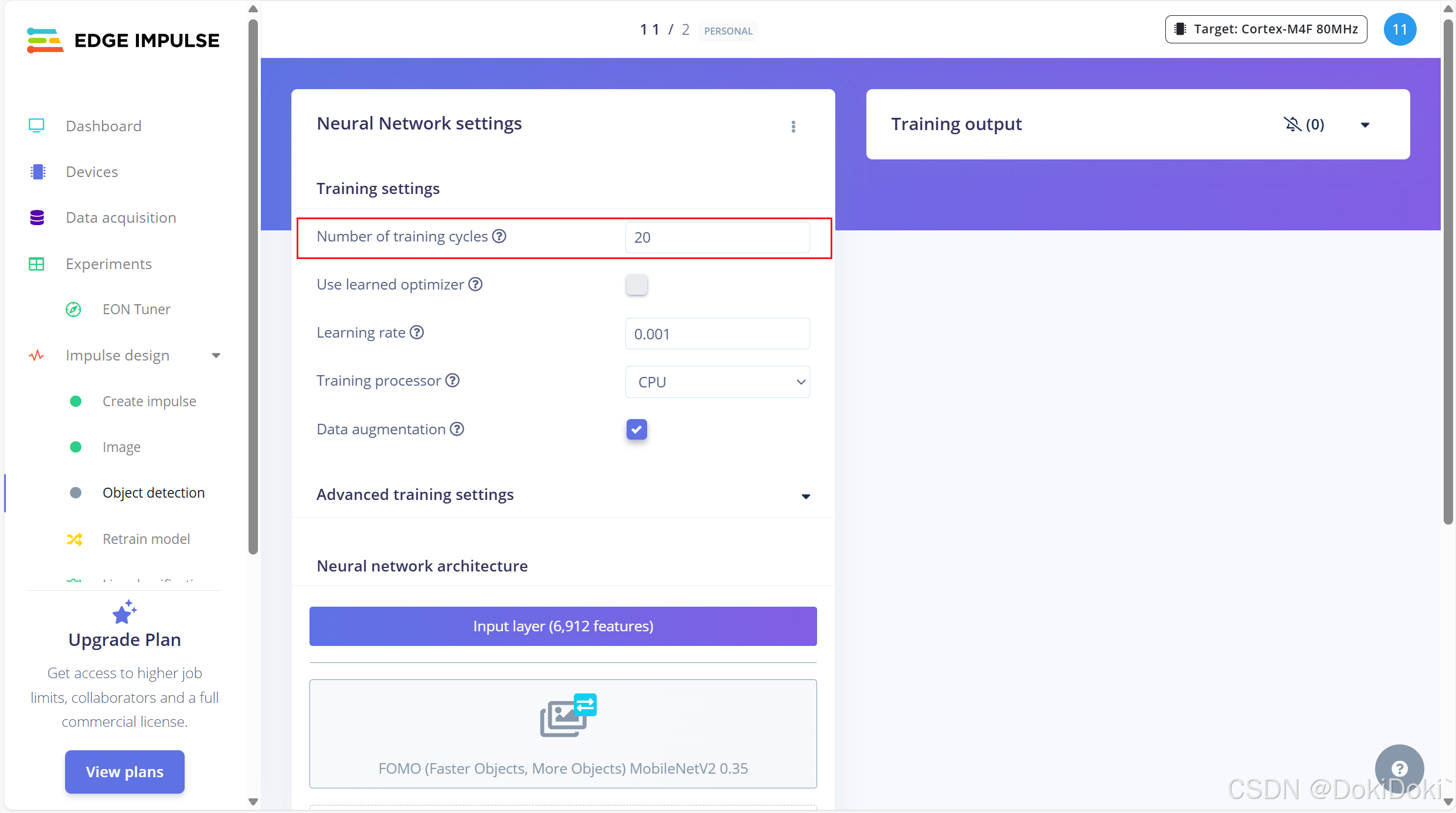
通过以上两种发放,主要还是第二种,可以使得我们训练的时间在20min以内,不会报错了,我们再训练一次,出现有图框里的内容,说明成功了,我们只需要静等云端自训练即可。
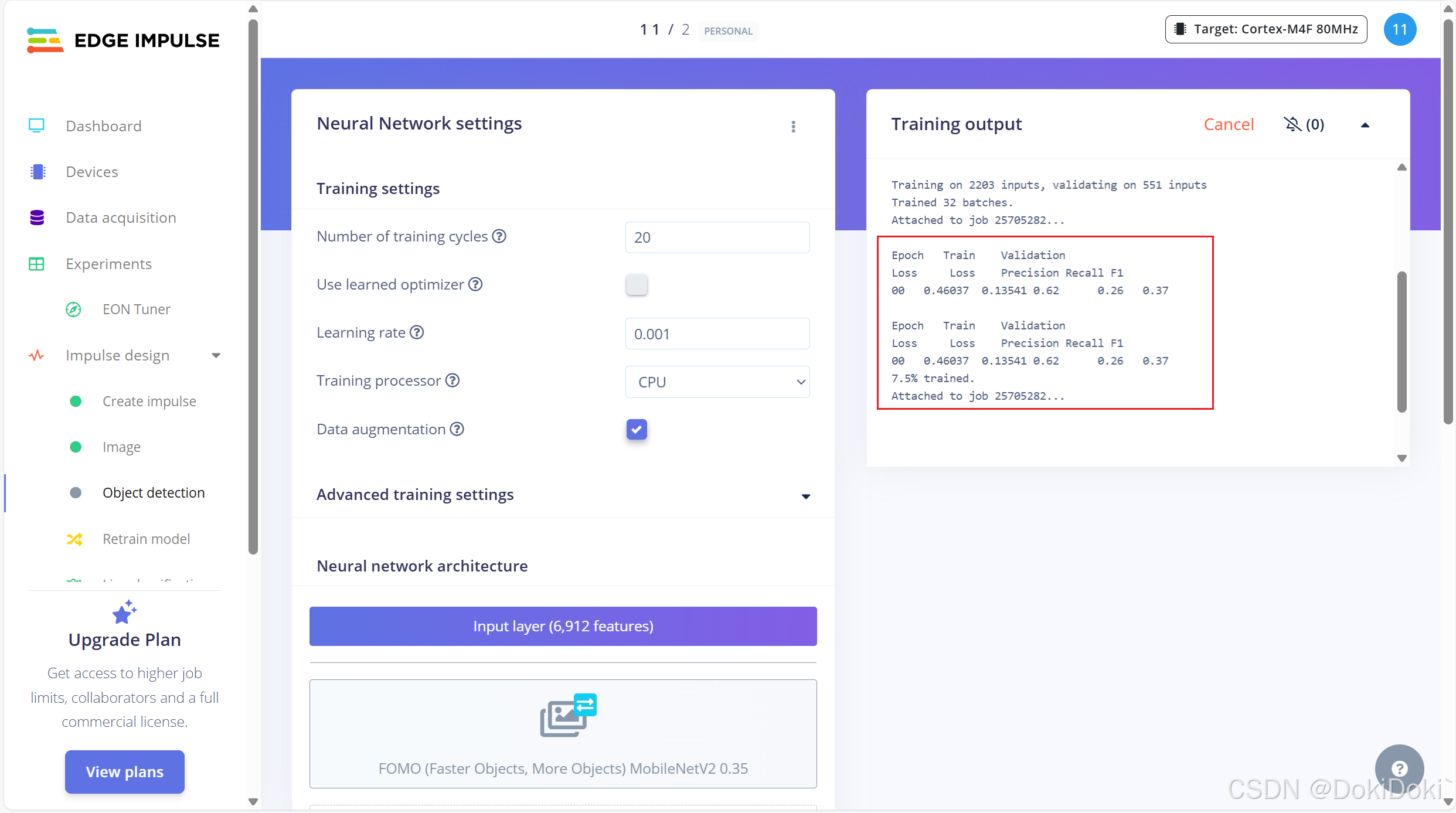
训练完成之后会出现训练效果,我这个因为有的特征并不是很明显,会和别的出现相似的部分,所以训练效果才79%。
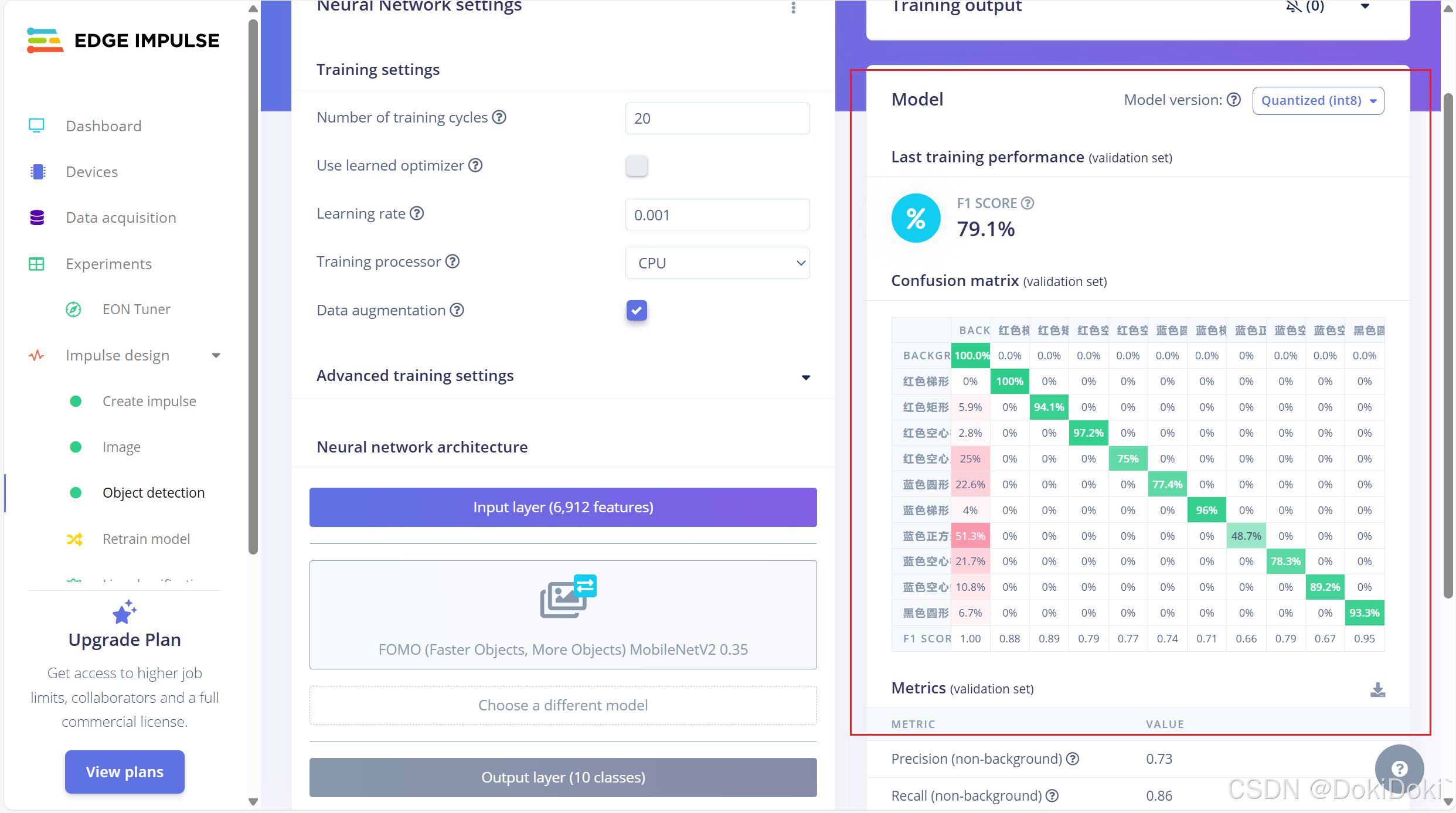
(10)训练完成后就属于大众操作了,如图点击,可以观察到训练情况,快速找到识别困难的目标
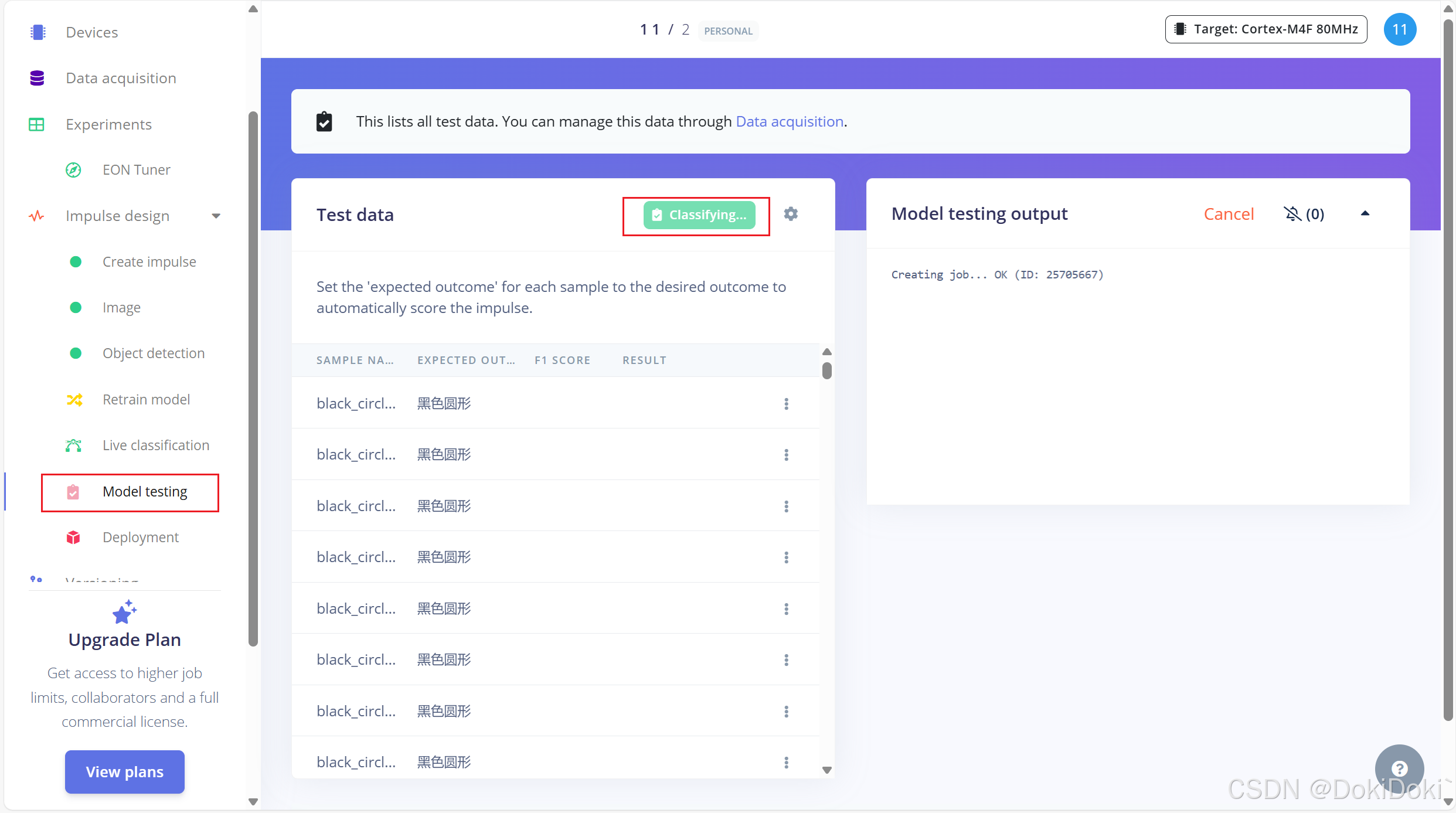
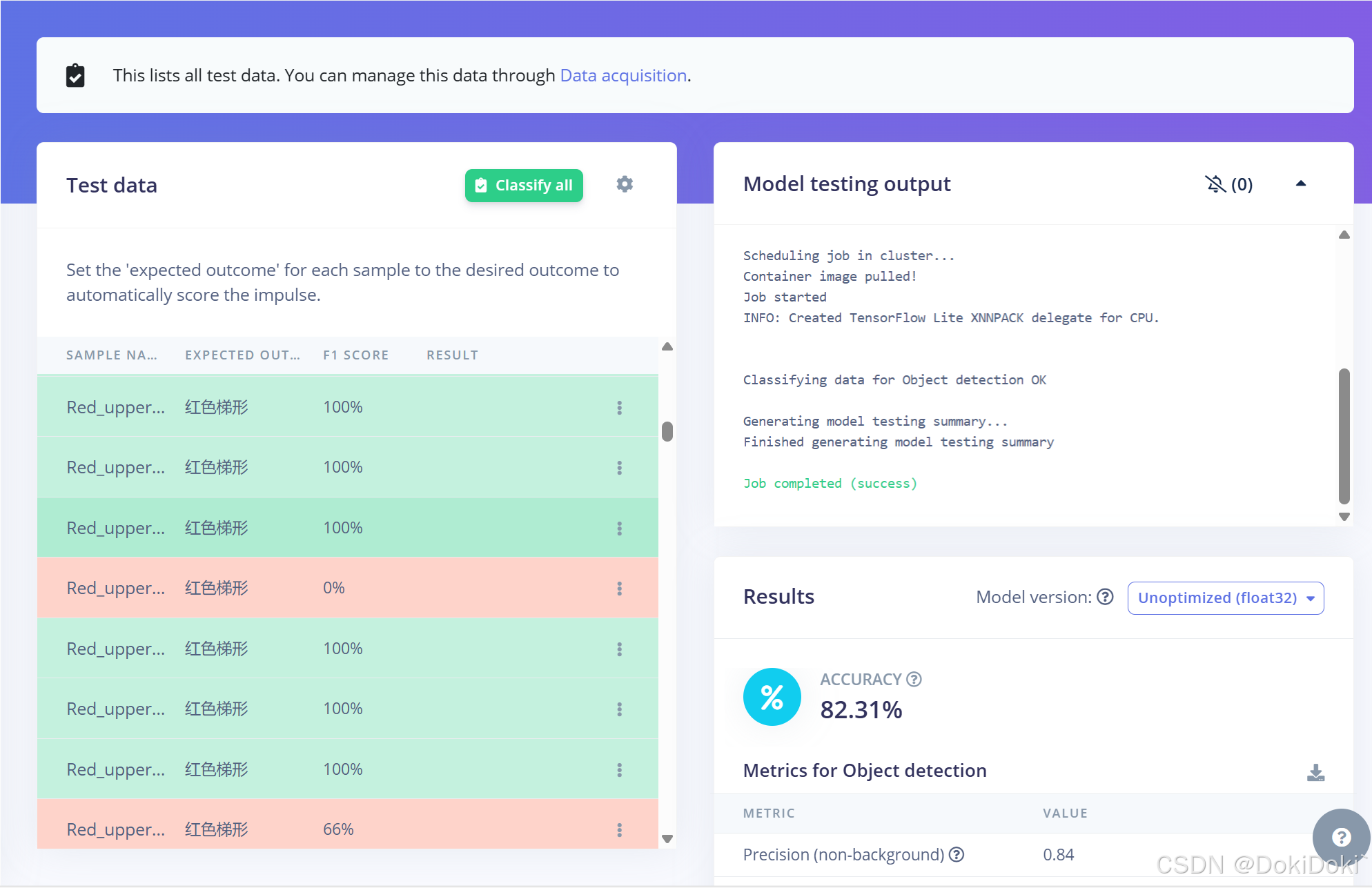
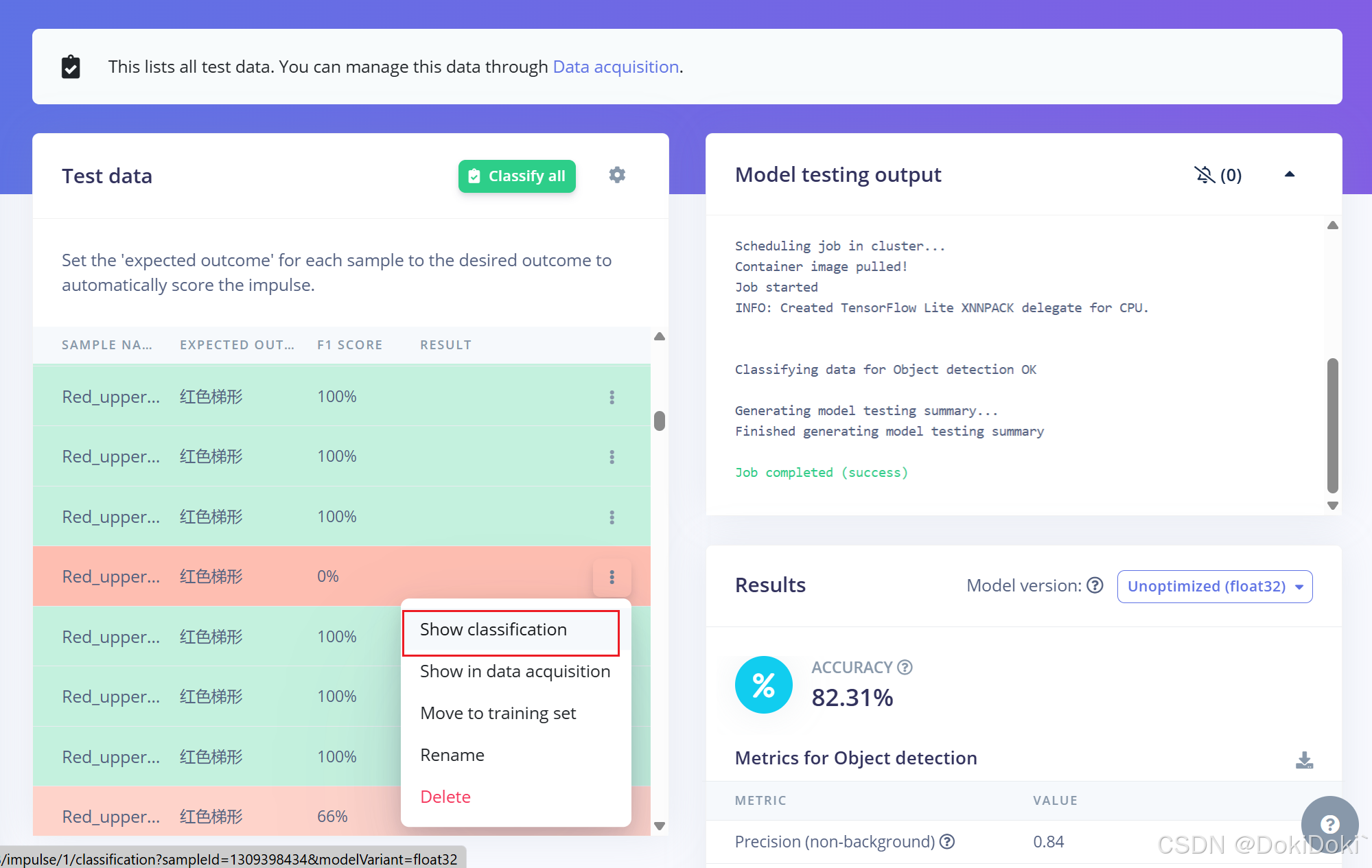
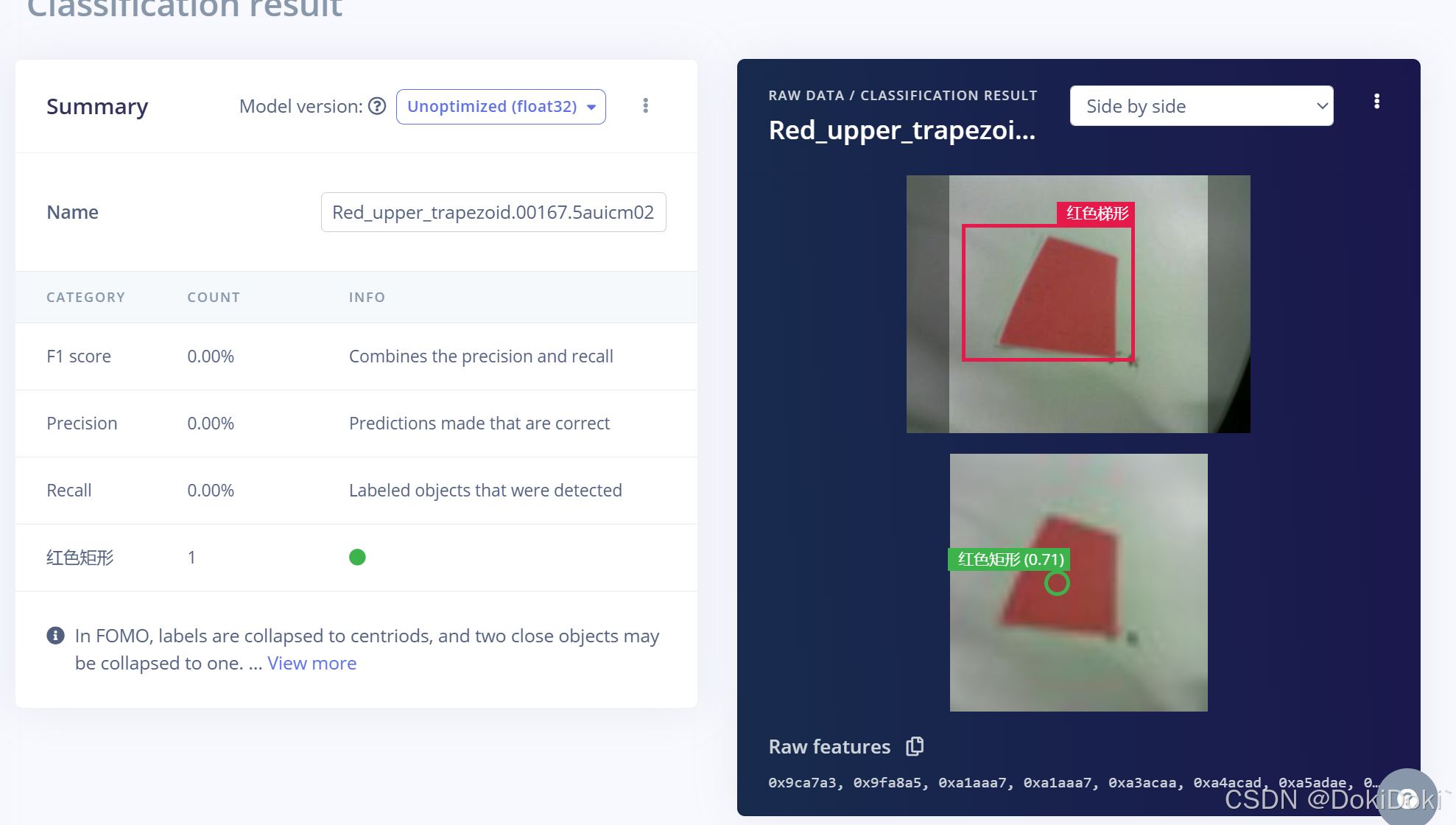
可以选择如图点击,查找无法正确识别的原因,也可以选择删除识别不出的数据。
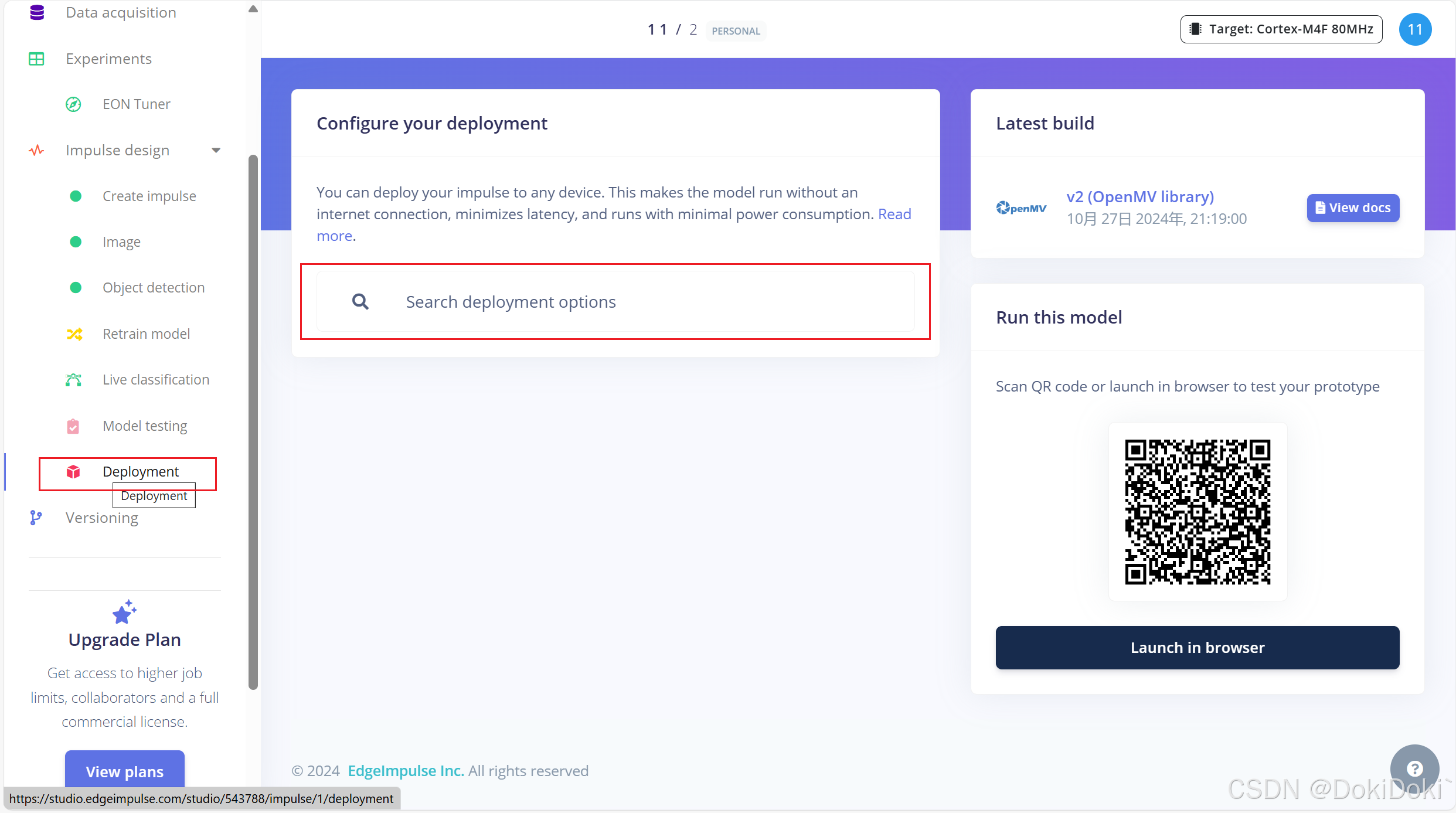
(11)选做,如图点击,创建版本,方便后续迭代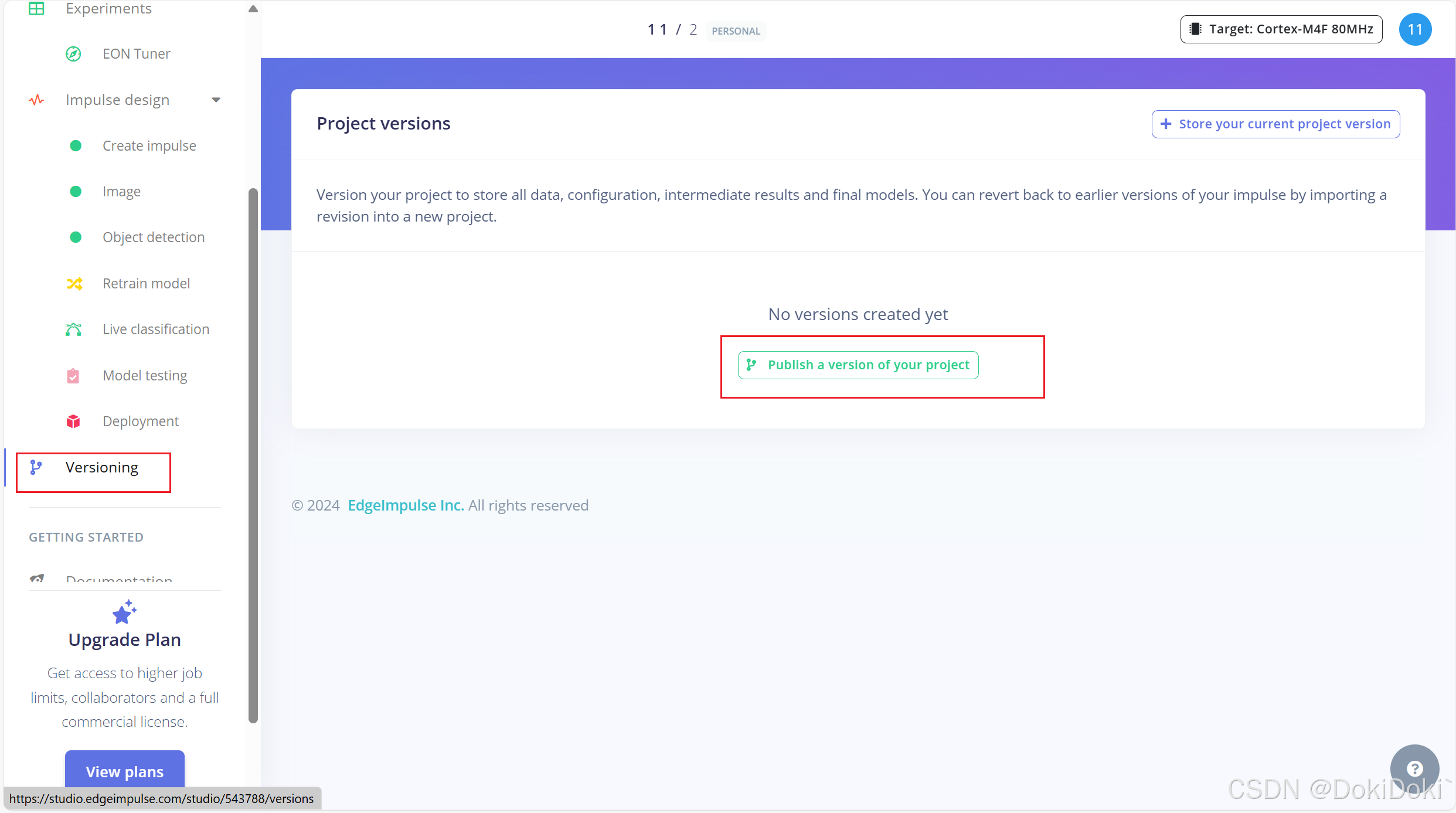 (12)最后一步,如图点击,在方框内搜索openmv,选择之后点击build,云端会自动将训练结果转化成适用的openmv的文件。
(12)最后一步,如图点击,在方框内搜索openmv,选择之后点击build,云端会自动将训练结果转化成适用的openmv的文件。


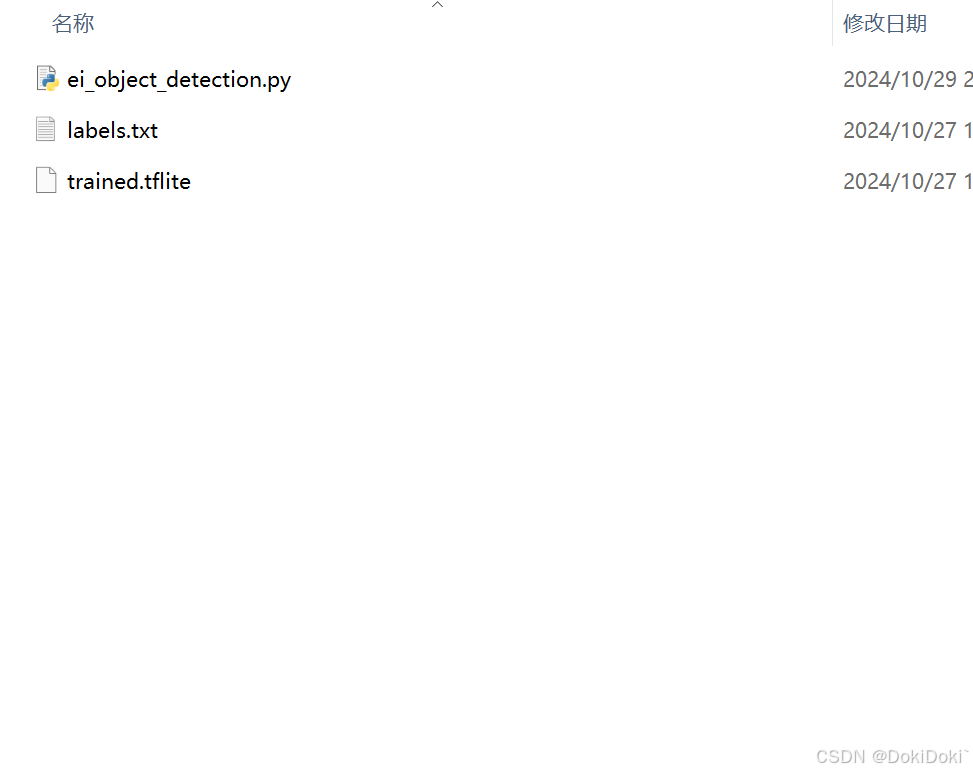
生成的文件会自动下载下来,里面有三个,将.py文件在openmv中生成运行即可。
了解云端训练的参数,和它生成的结果,然后就可以自行对代码进行更改,比如说加串口功能等等。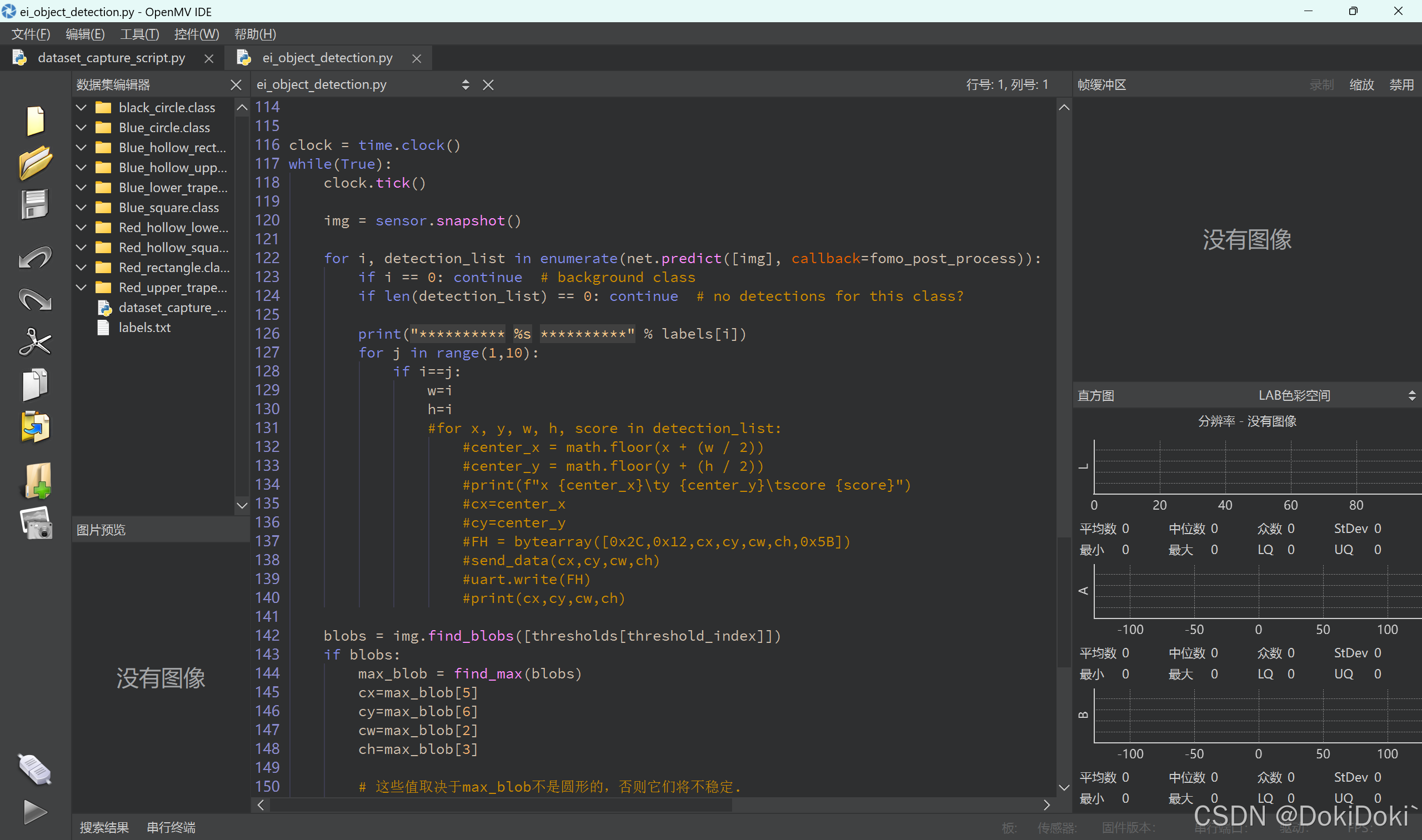
如果出现报错,可以试着注释掉几行代码,可能会更适用。


















 7568
7568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









