








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

二、过拟合模型
1.调用库函数
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Conv2D,MaxPooling2D,BatchNormalization,Flatten,Dense,Dropout
# 指定当前程序使用的 GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
2.调用数据集
# 调用数据集
(train_X, train_y),(test_X, test_y) = tf.keras.datasets.fashion_mnist.load_data()
train_X, test_X = train_X / 255.0, test_X / 255.0
train_X = train_X.reshape(-1, 28, 28, 1)
train_y = tf.keras.utils.to_categorical(train_y)
X_train, X_test, y_train, y_test = train_test_split(train_X, train_y, test_size=0.1, random_state=0)
3.选择模型,构建网络
搭建MaxPooling2D层、Conv2D层
# 选择模型,构建网络
model = tf.keras.Sequential()
model.add(Conv2D(32, (3, 3), padding='same', activation=tf.nn.relu,input_shape=(28, 28, 1))), #添加Conv2D层
model.add(Dropout(0.1)),
model.add(MaxPooling2D((2, 2), strides=2)), #添加MaxPooling2D层
model.add(Conv2D(64, (3, 3), padding='same', activation=tf.nn.relu)),#添加Conv2D层
model.add(MaxPooling2D((2, 2), strides=2)),#添加MaxPooling2D层
model.add(Flatten()), #展平
model.add(Dense(512, activation=tf.nn.relu)),
model.add(Dropout(0.1)),
model.add(Dense(10, activation=tf.nn.softmax))
4.编译
使用交叉熵作为loss函数,指明优化器、损失函数及验证过程中的评估指标
# 编译(使用交叉熵作为loss函数)
model.compile(optimizer='adam', #指定优化器
loss="categorical\_crossentropy", #指定损失函数
metrics=['accuracy']) #指定验证过程中的评估指标
# 展示训练的过程
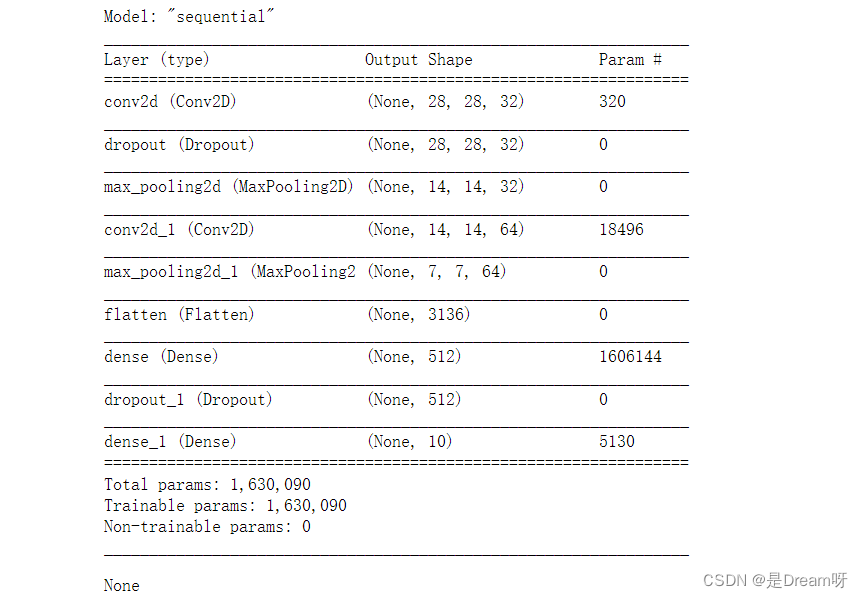
display(model.summary())
🌟🌟🌟这里是输出的结果:✨✨✨
5.数据增强
在这里我们使用数据增强方法,更好的提高准确率
# 数据增强
datagen = ImageDataGenerator(
rotation_range=15,
zoom_range = 0.01,
width_shift_range=0.1,
height_shift_range=0.1)
train_gen = datagen.flow(X_train, y_train, batch_size=128)
test_gen = datagen.flow(X_test, y_test, batch_size=128)
6.训练
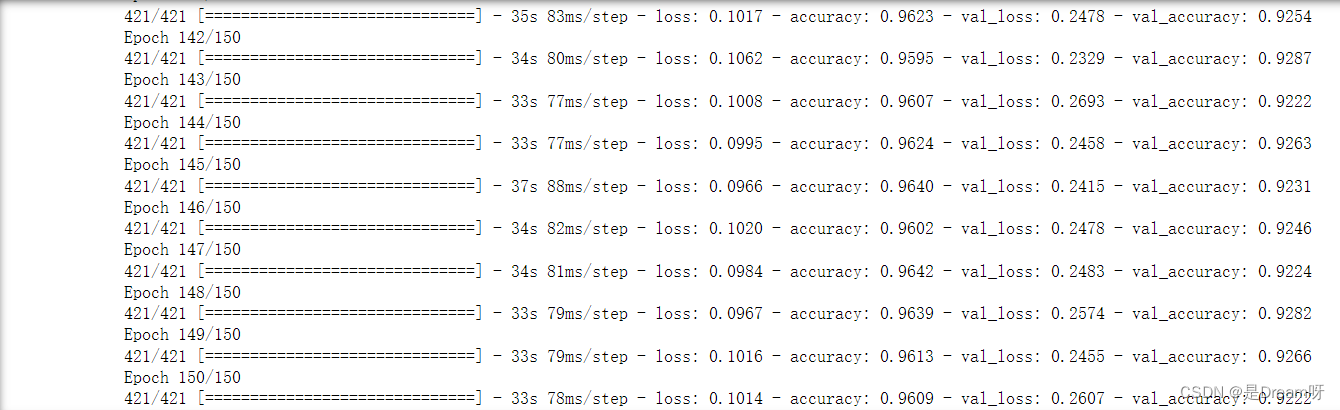
首先我们批量输入的样本个数,然后经过我们测试分析,此模型训练到30轮之前变化趋于静止,我们可以只进行30个epoch
# 批量输入的样本个数
batch_size = 128
train_steps = X_train.shape[0] // batch_size
valid_steps = X_test.shape[0] // batch_size
# 经过我们测试分析,此模型训练到30轮之前变化趋于静止,我们可以只进行30个epoch
es = tf.keras.callbacks.EarlyStopping(
monitor="val\_accuracy",
patience=10,
verbose=1,
mode="max",
restore_best_weights=True)
rp = tf.keras.callbacks.ReduceLROnPlateau(
monitor="val\_accuracy",
factor=0.2,
patience=5,
verbose=1,
mode="max",
min_lr=0.00001)
# 训练(训练150个epoch)
history = model.fit(train_gen,
epochs = 150,
steps_per_epoch = train_steps,
validation_data = test_gen,
validation_steps = valid_steps)
🌟🌟🌟这里是输出的结果:✨✨✨
7.画出图像
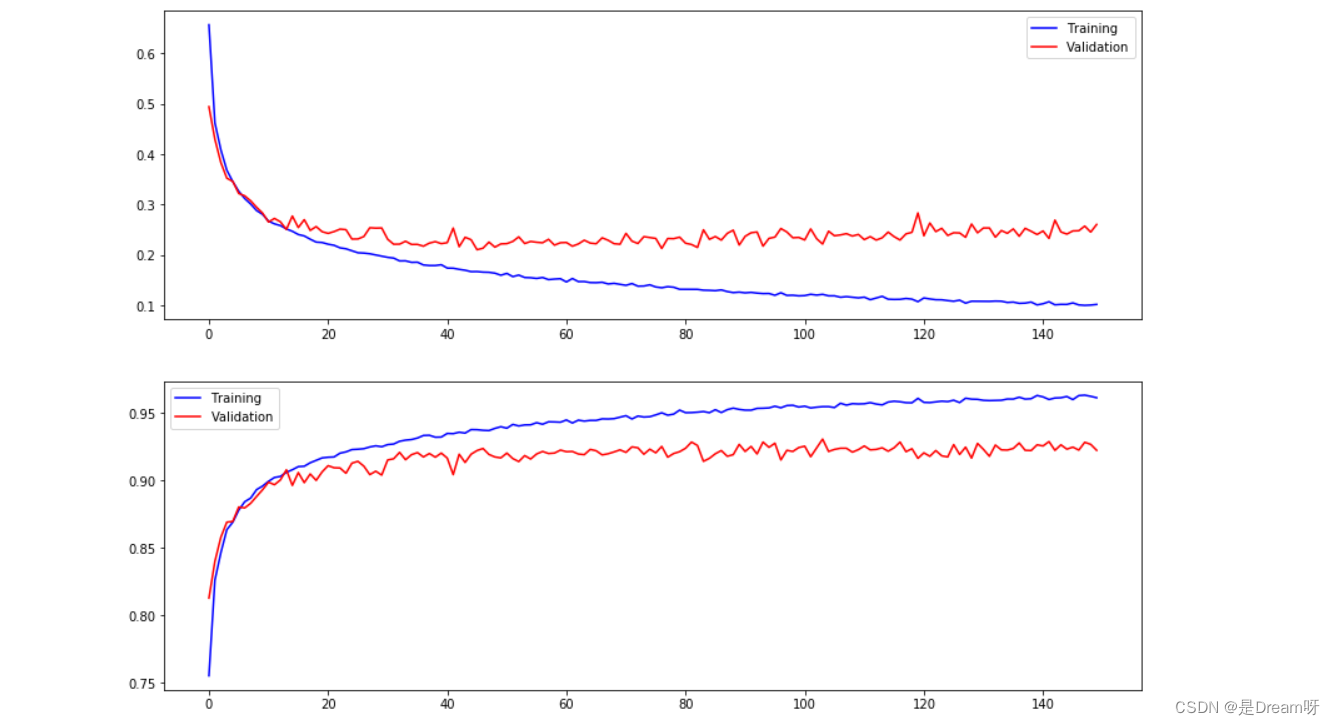
使用plt模块进行数据可视化处理
fig, ax = plt.subplots(2,1, figsize=(14, 10))
ax[0].plot(history.history['loss'], color='blue', label="Training")
ax[0].plot(history.history['val\_loss'], color='red', label="Validation",axes =ax[0])
ax[0].legend(loc='best', shadow=False)
ax[1].plot(history.history['accuracy'], color='blue', label="Training")
ax[1].plot(history.history['val\_accuracy'], color='red',label="Validation")
ax[1].legend(loc='best',shadow=False)
plt.show()
🌟🌟🌟这里是输出的结果:✨✨✨
8.输出
最后在测试集上进行模型评估,输出测试集上的预测准确率
score = model.evaluate(X_test, y_test) # 在测试集上进行模型评估
print('测试集预测准确率:', score[1]) # 打印测试集上的预测准确率
🌟🌟🌟 这里是输出的结果:✨✨✨
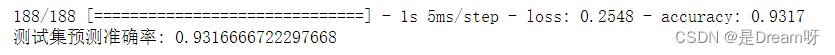
9.结果
print("The accuracy of the model is %f" %score[1])
The accuracy of the model is 0.931667
三、防止过拟合模型
1.调用库函数
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Conv2D,MaxPooling2D,BatchNormalization,Flatten,Dense,Dropout
# 指定当前程序使用的 GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
2.调用数据集
# 调用数据集
(train_X, train_y),(test_X, test_y) = tf.keras.datasets.fashion_mnist.load_data()
train_X, test_X = train_X / 255.0, test_X / 255.0
train_X = train_X.reshape(-1, 28, 28, 1)
train_y = tf.keras.utils.to_categorical(train_y)
X_train, X_test, y_train, y_test = train_test_split(train_X, train_y, test_size=0.1, random_state=0)
3.选择模型,构建网络
搭建MaxPooling2D层、Conv2D层
# 选择模型,构建网络
model = tf.keras.Sequential()
model.add(Conv2D(32, (3, 3), padding='same', activation=tf.nn.relu,input_shape=(28, 28, 1))), #添加Conv2D层
model.add(Dropout(0.1)),
model.add(MaxPooling2D((2, 2), strides=2)), #添加MaxPooling2D层
model.add(Conv2D(64, (3, 3), padding='same', activation=tf.nn.relu)),#添加Conv2D层
model.add(MaxPooling2D((2, 2), strides=2)),#添加MaxPooling2D层
model.add(Flatten()), #展平
model.add(Dense(512, activation=tf.nn.relu)),
model.add(Dropout(0.1)),
model.add(Dense(10, activation=tf.nn.softmax))
4.编译
使用交叉熵作为loss函数,指明优化器、损失函数及验证过程中的评估指标
# 编译(使用交叉熵作为loss函数)
model.compile(optimizer='adam', #指定优化器
loss="categorical\_crossentropy", #指定损失函数
metrics=['accuracy']) #指定验证过程中的评估指标
# 展示训练的过程
display(model.summary())
🌟🌟🌟这里是输出的结果:✨✨✨
5.数据增强
在这里我们使用数据增强方法,更好的提高准确率
# 数据增强
datagen = ImageDataGenerator(
rotation_range=15,
zoom_range = 0.01,
width_shift_range=0.1,
height_shift_range=0.1)
train_gen = datagen.flow(X_train, y_train, batch_size=128)
test_gen = datagen.flow(X_test, y_test, batch_size=128)
6.训练
首先我们批量输入的样本个数,然后经过我们测试分析,此模型训练到70轮之前变化趋于静止,我们可以只进行70个epoch
# 批量输入的样本个数
batch_size = 128
train_steps = X_train.shape[0] // batch_size
valid_steps = X_test.shape[0] // batch_size
# 经过我们测试分析,此模型训练到70轮之前变化趋于静止,我们可以只进行70个epoch
es = tf.keras.callbacks.EarlyStopping(
monitor="val\_accuracy",
patience=10,
verbose=1,
mode="max",
restore_best_weights=True)
rp = tf.keras.callbacks.ReduceLROnPlateau(
monitor="val\_accuracy",
factor=0.2,


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
ccuracy",
factor=0.2,
[外链图片转存中...(img-uB1uYcRX-1715730480975)]
[外链图片转存中...(img-P1ZAya9z-1715730480976)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618658159)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 3287
3287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









