







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
针对这个问题,解决方法是购买一些能够处理大规模数据的新奇技术。然而,在大数据任务组购买了所有新工具,并从遗留系统迁移出来之后,人们发现他们仍然无法理解自己的数据。此外,他们可能还会注意到,实际上数据的规模根本不是问题所在。
2023 年,整个世界看起来与大数据的预警有很大的不同。人们预测的数据灾难并没有发生。数据量可能变大了,但硬件的增长速度也更快了。供应商仍在推销扩展能力,但从业者开始质疑规模到底与现实世界的问题有何关系。
d455ce2d08d5fcf855043f13e076ed62.png
背景介绍
十多年来,我一直支持大数据的发展。我是 Google BigQuery 的创始工程师,作为团队中唯一真正喜欢公开演讲的工程师,我经常前往世界各地参加会议,帮忙解释如何抵御即将到来的数据爆炸。我曾经在台上演示过查询 PB 数量级的数据,就为了证明无论多大规模的数据,我们都能搞定,没问题。

前几年,我花了很多时间调试客户在使用 BigQuery 时遇到的问题。我参与出版了两本书,深入研究了 BigQuery 的使用方式。2018年,我转做产品管理,工作内容主要分为两大块:与客户交谈(许多是全球级的大企业)以及分析产品指标。
我发现,大多数使用 BigQuery 的用户并没有大数据。即使是拥有大数据的人,实际上也只使用了数据集很小的一部分。当初 BigQuery 问世,对许多人来说就像科幻小说一样,人们能够利用它以前所未有的速度处理数据。然而,这些曾经只会出现在科幻小说中的情节也已成为生活的常态,而且更传统的数据处理方式也迎头赶上来了。

关于这篇文章
在本文中,我将论证大数据时代已经结束。如今我们不必不再担心数据的规模,相反,我们应该专心研究如何利用大规模数据制定出更好的决策。
我会展示一些图表,虽然这些图表是根据记忆手动绘制的,但重要的是观察曲线的走向。
图表背后的数据来自分析查询日志、交易事后分析、基准测试结果(已发布和未发布)、客服票据、客户对话、服务日志、已发布的博客文章,再加上一些直觉。

一张幻灯片
在过去的十年里,每一个大数据产品的推销平台都是从与下面这张幻灯片类似的宣传资料开始的:
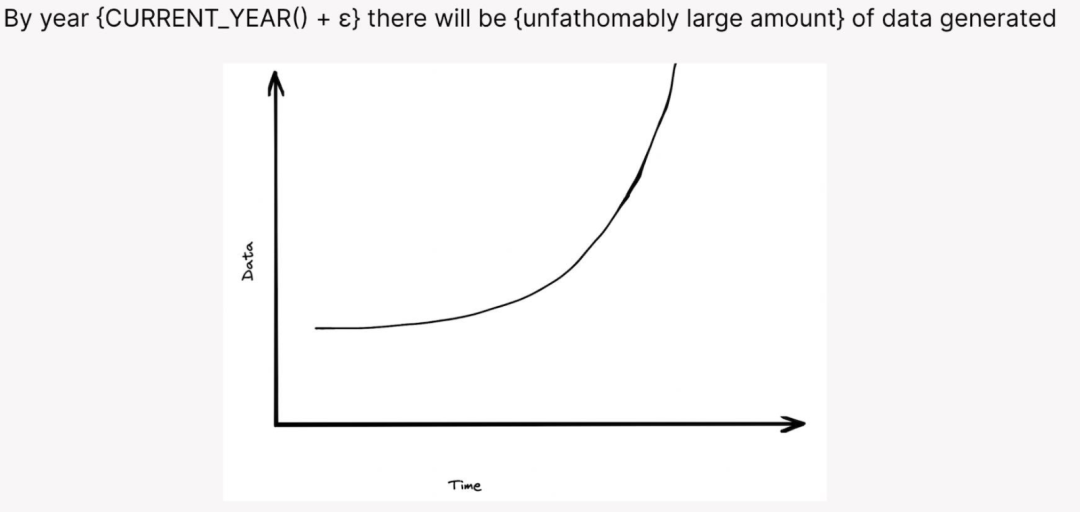
在 Google,多年来我们一直在使用这张幻灯片。后来,我到了 SingleStore,发现他们使用的也是类似的图表,只不过版本略微不同。此外,我见过其他几家供应商也有类似的东西。这张幻灯片可以引发潜在的“恐慌”:“大数据来了!抓紧购买我家的产品吧!”
这张幻灯片真正想转达的消息是:**处理数据的旧方法已经行不通了。**数据生成的加速导致以前的数据系统陷入困境,所有接受新想法的人都将超越竞争对手。
当然,仅仅因为生成的数据量在增加并不意味着这会成为每个人的问题, 数据分布不均。大多数应用程序不需要处理大量数据。这导致使用传统架构的数据管理系统的复兴,SQLite、Postgres、MySQL 都开始强势发展,而 NoSQL 以及 NewSQL 系统的发展都出现了停滞。
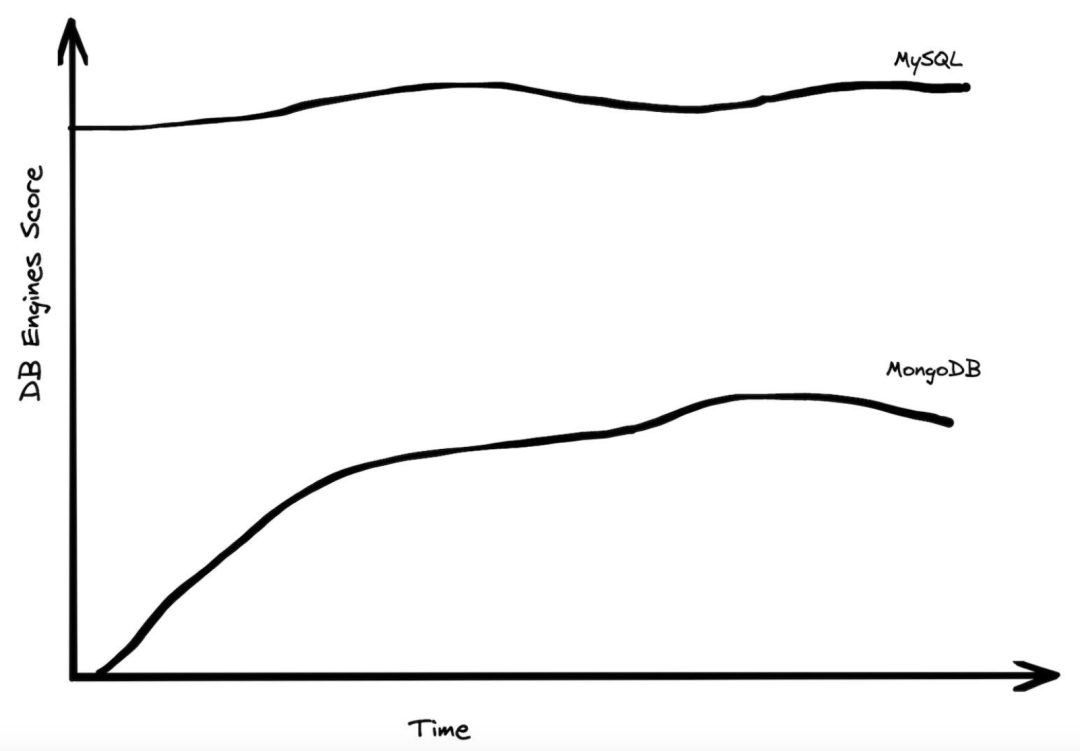
若论 NoSQL 或其他横向扩展数据库,MongoDB 的人气最高,虽然多年来 MongoDB 的发展也算顺风顺水,但最近出现了小幅下降,而且与 MySQL 和 Postgres 这两种单体数据库相比,MongoDB 的发展始终不如人意。如果大数据真的占据统治地位,那么几年内我们本应能看到很大的不同。
当然,在分析系统中的情况有所不同,但在 OLAP 中,我们看到了从内部部署到云的巨大转变,并且实际上没有任何可扩展的云分析系统可与之抗衡。

大多数人没有那么多数据
根据上述“大数据即将到来”的图表,用不了多久每个人都会数据淹没。然而十年过去了,我们“预期的未来”仍然未能成为现实。我们可以几种方式验证这一点:查看数据(定量),询问数据量是否与人们的感知一致(定性),从第一原则出发(归纳)思考这个问题。
当初在 BigQuery 工作的时候,我花了很多时间研究客户规模。相关的数据是保密的,所以我不能直接分享任何数字。但是,我可以说绝大多数客户的总数据存储量都不到 1TB。当然,也有一些客户拥有大量数据,但大多数组织,甚至一些巨头企业,他们的数据量也属于中等水平。
客户的数据规模呈幂律分布。存储量最大的客户是第二大客户的两倍,而第二大客户是第三大客户的两倍,依此类推。因此,虽然有些客户拥有数百 PB 的数据,但在分布图上这个规模的下降速度很快。成千上万的客户每月支付的数据存储费用不足 10 美元,即 0.5TB。在大量使用我们的服务的客户中,数据存储规模的中位数远低于 100 GB。
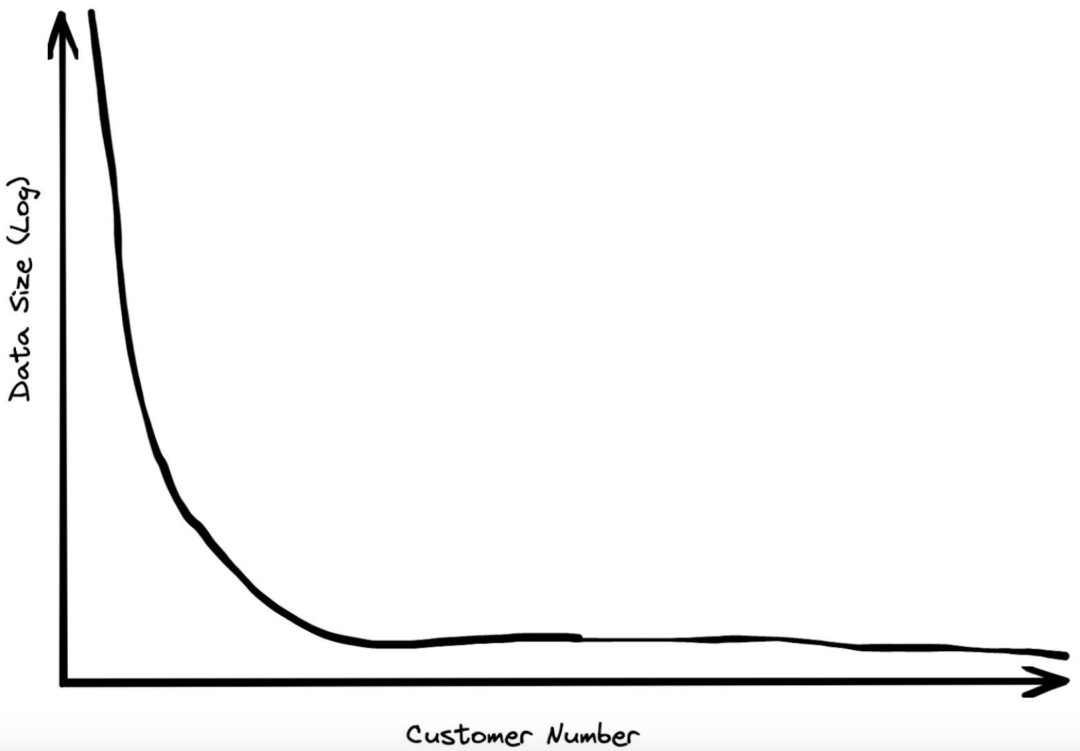
在与行业分析师(Gartner、Forrester 等)交谈的过程中,我们获得了进一步的肯定。当论及我们拥有处理海量数据集的能力时,他们会耸耸肩,然后说:“话虽如此,但绝大多数企业的数据仓库都小于 1 TB。”业内人士给我们的反馈普遍是,适合数据仓库的数量级约为 100 GB。我们的基准测试主要瞄准的也是这个尺度。
我们的一位投资者有意找出分析数据的真实规模,并调查了他自己投资的公司。其中有一些是科技公司,这些公司的数据量普遍偏大。他发现,他投资的最大的 B2B 公司拥有大约 1TB 的数据,而最大的 B2C 公司拥有大约 10TB 的数据。事实上,大多数公司的数据远没有那么多。
为了理解为什么大数据如此罕见,我们需要思考数据的实际来源。假设你拥有一家中型企业,客户规模约为 1000 名。假设每位客户每天都会下一个新订单,其中包含一百个货品。这个频率相对已经很高了,但实际每天生产的数据仍然不足 1MB。三年后,也只有 1GB,而要产生 1 TB 的数据则需要几千年。
再举一个例子,假设你的营销数据库中有 100 万个潜在客户,而且你同时开展了十个活动。即便是这样,数据的规模仍然不到 1GB,而且跟踪每个活动中的每个潜在客户也只需要几GB。在合理的扩展假设下,很难看出数据规模如何能达到海量级。
再举一个具体的例子,2020年~2022年,我在 SingleStore 工作,当时这是一家快速发展的公司,收入可观,而且有成为独角兽企业的潜质。将这家公司的财务数据仓库、客户数据、营销活动跟踪以及服务日志等所有数据都累加起来,总量也只有几GB。无论怎么看,都算不上大数据。

在存储与计算分离的环境中,存储规模增长远大于计算
现代云数据平台都主张存储与计算分离,这意味着,客户不会受到单一外形因素的束缚。这可能是过去二十年中数据架构最重要的变化。在现实世界中“完全不共享”的架构不便于管理,与之不同,共享磁盘架构可以单独增加存储空间或计算空间。随着可扩展且速度非常快的对象存储(如 S3 和 GCS)的兴起,我们可以放宽构建数据库的许多限制。
在实际工作中,数据规模的增长速度远快于计算规模。虽然存储与计算分离的优点在于,你可以随时扩展其中一个,二者的扩展速度无需同步。然而,很多人对此有误解,结果引发了很多关于大数据的讨论,因为大规模计算所需的技术不同于大数据所需的技术。我们应该思考一下为什么会出现这种情况。
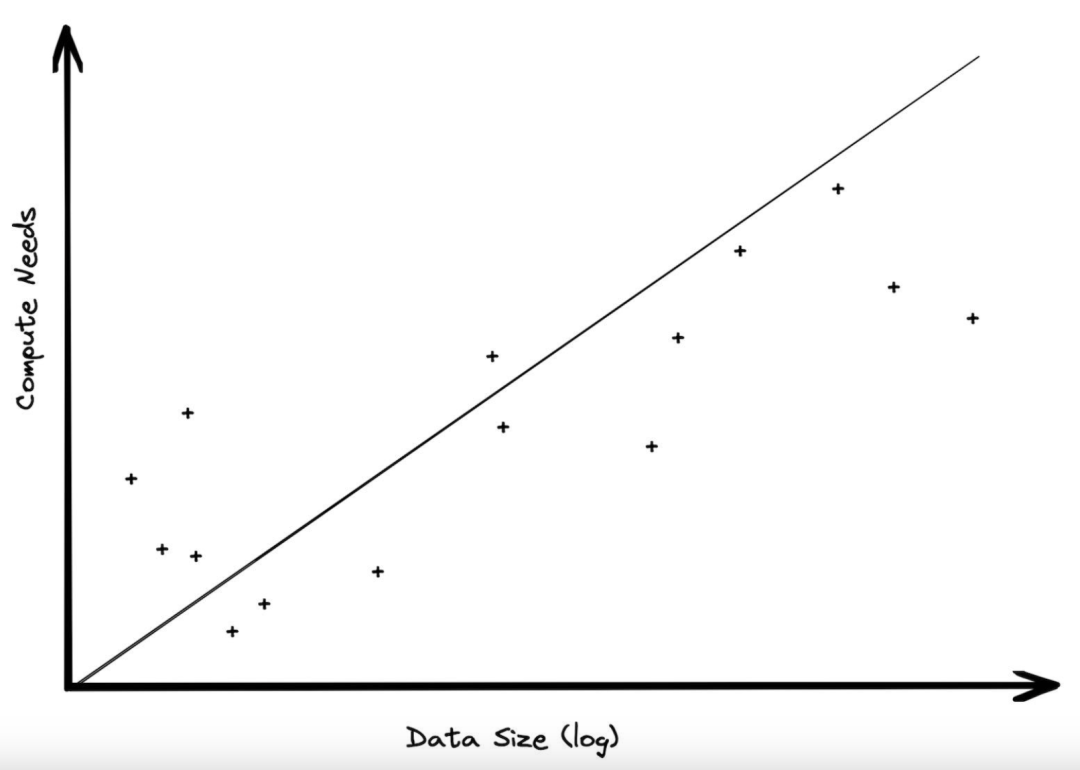
所有的大数据集都是经年累月产生的。数据集的发展离不开时间这个维度。每天都有新订单、新的出租车业务、新的日志记录、新的游戏记录等等。如果业务是静态的,既不增长也不收缩,数据将随时间推移呈线性增长。这对分析需求意味着什么?很显然,数据存储的需求将呈线性增长,除非你修剪数据(稍后再详细讨论)。但随着时间的推移,计算的需求可能不会发生太大变化,大多数分析都是针对近期的数据进行的。扫描旧数据会造成巨大的浪费,旧数据又不会变化,为什么要花钱一遍又一遍地看呢?诚然,你仍然希望保留旧数据,以防针对数据提出新问题,但通过聚合数据总结出重要的答案是非常简单的。
很多时候,当数据仓库的客户从没有分离存储与计算的环境转移到分离的环境时,他们的存储使用量会大幅增长,但他们的计算需求往往不会改变。在 BigQuery 中,我们有一个客户是世界上最大的零售商之一。他们有一个本地数据仓库,大约有 100 TB 的数据。迁移到云后,他们最终的数据量约为 30 PB ,增加了 300 倍。如果他们的计算需求也以相似的数量级增加,那么他们的分析开销将高达十亿美元。然而实际上,他们这部分的开销很小。
这种对存储规模超越计算规模的趋势对系统架构产生了实际影响。这意味着,如果使用可扩展的对象存储,你需要使用的计算量远低于预期。你甚至可能不需要使用分布式处理。
00448b7f7e0fe937ed9ded24ece529c3.png
工作负载的规模小于整体的数据规模
分析工作负载的数据量远低于你的想象。举个例子,我们通常会利用聚合数据构建仪表板。人们可以通过仪表板查看过去一个小时、前一天或上周的数据。规模较小的表往往查询频率也更高,而大型表需要更有针对性的查询。
几年前,我对 BigQuery 查询进行了分析,并仔细分析了每年开销超过 1000 美元的客户。90% 的查询处理的数据少于 100 MB。我按照不同的方式,对这些查询进行了切片,以确保这不是少数几个客户运行了大量查询导致的畸形结果。此外,我还删除了纯元数据查询,因为这部分查询根本不需要读取任何数据。最后发现,规模在GB级别的查询非常少,而达到TB级别的查询只有极少数。
拥有大规模数据的客户几乎从不查询海量数据
通常,数据量适中的客户会进行大量的查询,但拥有大规模数据的客户几乎从不查询海量数据。即使查询海量数据,通常也是为了生成报告,也就是说这些查询并不注重性能。一家大型社交媒体公司会在周末发布报告,为周一早上向高管汇报做准备, 这些查询非常庞大,但他们一周内运行的查询数量多达几十万个,而这些查询只占到很小一部分。
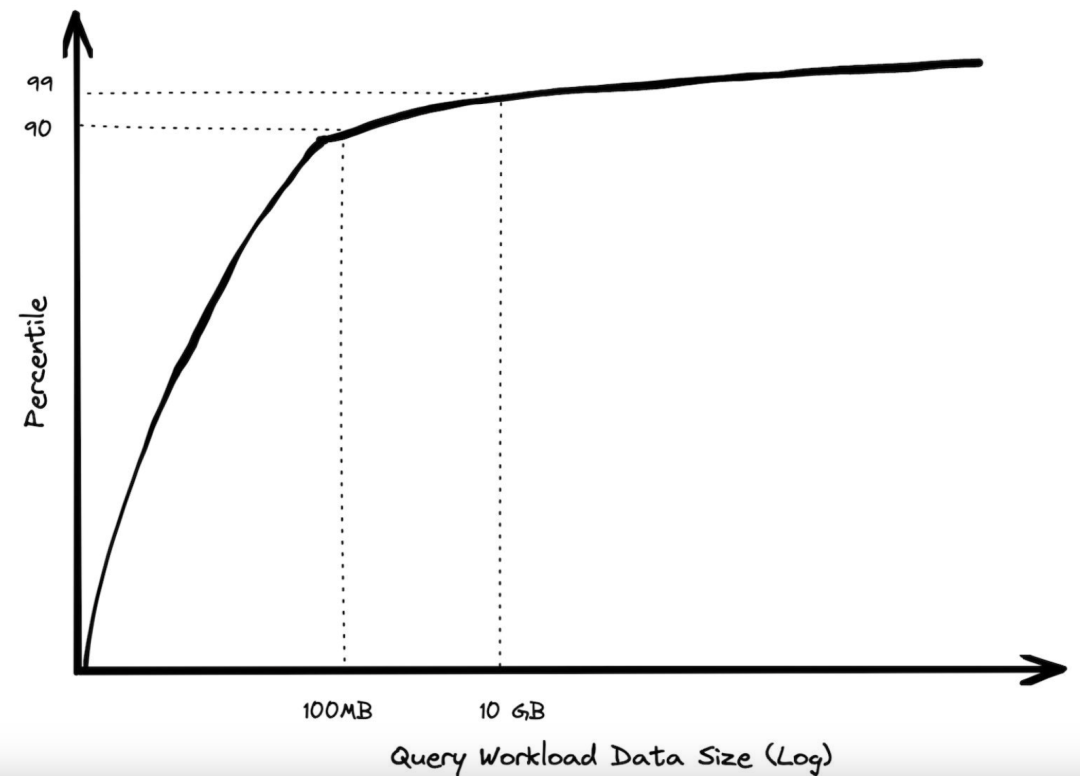
即使查询巨型表,也很少需要处理大量数据。现代分析数据库可以通过列投影仅读取字段的子集,还可以通过分区修剪来仅读取一定范围内的日期。还可以更进一步,利用分段消除,通过聚类或自动微分区来利用数据中的局部性。此外,还可以通过压缩数据计算、投影和谓词下推等技巧减少查询中I/O的使用。I/O使用量下降,意味着计算量降低,最终的效果是降低成本和延迟。
巨大的经济压力促使人们减少处理的数据量。即便你可以快速地横向扩展和处理某些数据,但并不意味着相应的成本低廉。使用一千个节点来获得结果,可能会让你付出沉重的代价。我曾在台上展示过 BigQuery 的 PB 级别的查询零售价为 5,000 美元。很少有人愿意运行如此昂贵的查询。
请注意,即使你没有使用按扫描字节数付费的定价模型,经济的压力也会让你减少处理的数据量。假设你有一个 Snowflake 实例,如果可以缩小查询的规模,你就可以使用更小的实例,而且相应的费用也更低。你的查询速度更快,而且还可以并行运行更多服务,通常费用也更低。
0de00015b0950513eb2be131bcb92e65.png
大多数数据很少被查询
我们日常处理的数据中,很大一部分是 24 小时内产生的。保存时间超过一周的数据,被查询到的概率会下降 20 倍。一个月后,大多数数据就无人问津了。历史数据往往很少被查询,只有需要生成某个罕见的报告时才会用到。
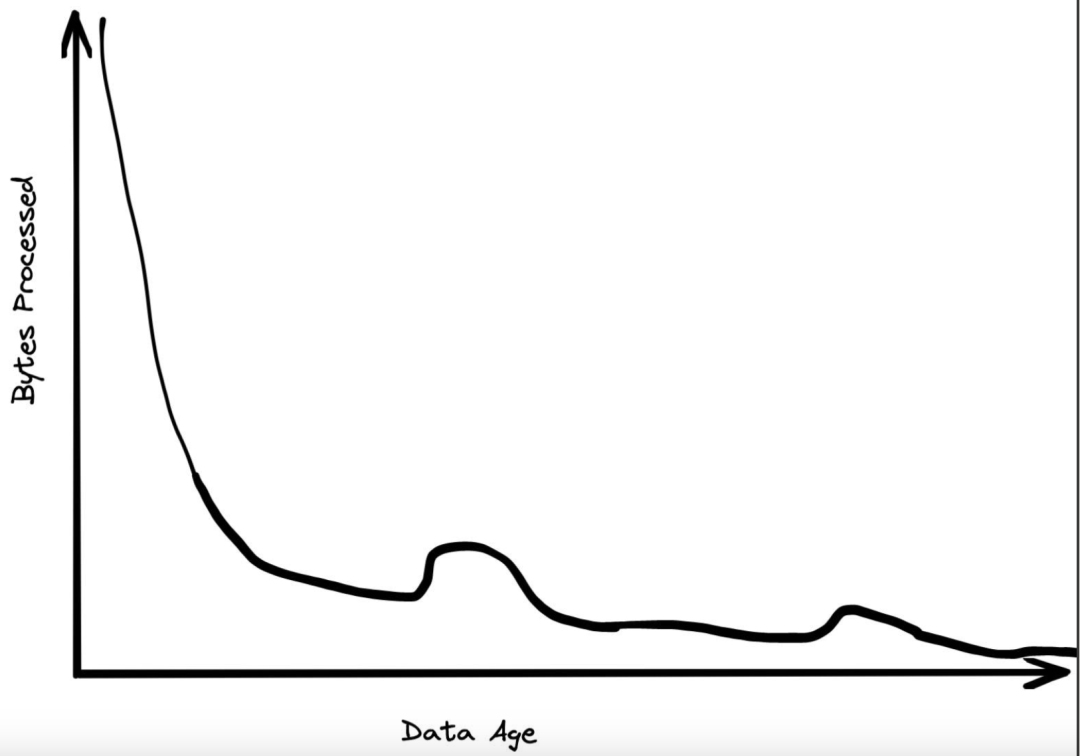
数据存储的时间模式通常都很扁平。虽然很多数据很快就会被丢弃,但很多数据会源源不断地附加到表的末尾。最近一年的数据大约只占30%,但99%的访问针对的都是这些数据。最近一个月的数据约为 5%,但访问量高达80%。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
么很难做到真正的技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









