







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

然后选择并转换这些特征以创建新特征,这些特征将用于机器学习模型的训练。使用上述数据模型,我们可以生成一些描述我们销售的额外特征。例如,我们可以创建包含产品已包含的订单数以及该产品价格占总订单价格的百分比的新功能。
SELECT
Product.pk_idProduct
, Product.description
, TBL_store.storeName
, count(Orders.pk_idOrder) as number_of_orders
, avg(Product.price / Orders.pricing) as product_percentage_of_order
FROM Product
INNER JOIN OrderProduct
on Product.pk_idProduct = OrderProduct.product
INNER JOIN Orders
on Orders.pk_idOrder = OrderProduct.order
INNER JOIN TBL_store
on TBL_store.PK_id_store = Product.seller
GROUP BY Product.pk_idProduct
, Product.description
, TBL_store.storeName
因为SQL是一个如此强大的工具,我们应该利用它,直接从数据库中生成可能的转换。

ClickHouse提供了在非常大的数据集上进行许多转换的功能。与为数据集创建新特征、提取数据。与通过 Python 操作数据的一般方法相反,在 ClickHouse 中创建新特征要快得多。
作为 AI 表的机器学习模型
在数据准备之后,我们到达了 MindsDB 介入的地步,并提供了一个简化机器学习模型建模和部署的结构。

这种结构称为 AI 表,是 MindsDB 的一项特定功能,允许您像对待普通表一样对待机器学习模型。您可以在 MindsDB 中创建此 AI 表,就像在常规数据库中创建表一样,然后可以通过外部表功能将此表暴露给 ClickHouse。
创建自己的 AI 表非常容易,下面是用于在数据集之上创建它的语法。
CREATE PREDICTOR <predictor_name>
TRAIN FROM { (<select_statement>) | <namespace|integration>.<view|table> | <url> }
[ TEST FROM { (<select_statement>) | <namespace|integration>.<view|table> | <url> } ]
[ ORDER BY <order_col> [{ASC|DESC}] ]
[ GROUP BY <col1,> [, <col2>, ...] ]
[ WINDOW <window_size> ]
PREDICT <col_name_in_from_to_forecast>
[ MODEL = {auto | <json_config> | <url>} ]
这使我们能够考虑与创建表的方式没有什么不同的机器学习部署。因此,一旦在数据库中将模型创建为表,它就已经部署好了。您唯一需要注意的是,如果表架构发生更改,则会发生什么情况,即需要创建新模型或重新训练模型。
总之,所有的部署和建模都被抽象到这个非常简单的结构中,我们称之为“AI 表”,它使您能够在其他数据库(如 ClickHouse)中公开此表。
在ClickHouse中构建数据集
尽管与分析数据库市场上的其他类似工具相比,ClickHouse是一个相当年轻的产品,但与更知名的工具相比,ClickHouse具有许多优势,甚至是使其在性能方面超越其他工具的新功能。
- 单个可移植的 C++ 二进制文件 – 可实现非常快速的 60 秒安装
- 在任何地方运行 – 它可以在任何基于 Linux 的环境中运行,例如云虚拟机、容器,甚至是裸机服务器或笔记本电脑
- 高级 SQL 功能 – 它有一些额外的扩展建立在常规 SQL 语法之上,赋予它一些额外的功能
- 列存储 – 在性能方面为您提供优势,在非常高的数据压缩率方面为您提供优势
- 分布式查询 – 由于查询分布在节点和 CPU 内核之间,因此需要毫秒级响应时间
- 分片和复制 – 支持从笔记本电脑大小扩展到数百个节点
- Apache 2.0 许可 – 使 ClickHouse 能够用于任何商业目的
ClickHouse 在全球拥有数千个安装,被众多大公司使用,如 Bloomberg、Uber、Walmart、eBay、Yandex 等。
数据探索
如前几节所述,任何机器学习管道中最耗时的部分是数据准备。它需要有关数据的知识,这就是为什么我们总是从数据探索开始。
在这一步,我们需要了解我们拥有哪些信息以及哪些功能可用于评估数据质量,以便使用它训练模型或对数据集进行一些改进。下面我们可以看到 ClickHouse 中的行程数据数据集示例,其中查询了 1 亿行关于纽约出租车的数据,以分析数据的质量
SELECT
count() AS rides,
avg(fare_amount) AS avg,
min(fare_amount) AS min,
max(fare_amount) AS max
FROM default.tripdata

正如你在这里看到的,我们有一些异常值会对机器学习模型产生负面影响,所以让我们用ClickHouse工具更深入地研究它。
让我们编写一个查询来更深入地研究这些分布,以便更好地理解数据。通过此查询,您可以在几秒钟内为这个大型数据集创建直方图视图,并查看异常值的分布。
SELECT h_bin.1 AS lo, h_bin.2 AS hi, h_bin.3 AS count FROM
(
SELECT histogram(5)(fare_amount) h
FROM default.tripdata WHERE fare_amount < 0
) ARRAY JOIN h AS h_bin

我们可以看到,我们的直方图查询的分布也包含一个计数列。此列中的某些结果是小数,不一定表示行计数。实际上,根据文档,此列实际上包含直方图中条柱的高度。
因为我们试图将整个数据集拟合到一个具有 5 个条柱的直方图中,该直方图是通过 histogram(5)(fare_amount) 函数调用指定的,并且数据集中的项目数量不是正态分布的,所以我们的条柱高度不一定相等。因此,我们的一些高度将有一个数字,该数字将按比例表示该特定条柱中的值数,相对于数据集中的值总数。
如果这仍然有点令人困惑,我们可以尝试使用 ClickHouse 中的 bar() 可视化 可视化")来生成数据集分布的更直观的结果。

我们可以看到,条形列包含数据集分布的可视化表示,分为 5 个条柱。由于前两个条柱都只包含 1 个值,因此条形图显示太小而无法显示,但是,当我们开始有更多值时,条形图也会显示出来。
此外,我们可以看到大量我们不希望包含在模型训练数据集中的小负票价值。如果我们反转数据集的过滤,只看正 fare_amount 值,我们可以看到“干净”数据点的数量要高得多。因为我们有这么大的值,所以我们要将条形函数的最小值设置为 10000000,以便分布更清晰可见。

数据清洗和聚合
现在我们已经确定我们的数据集包含异常值,我们需要删除它们以获得一个干净的数据集。我们将过滤掉所有负数,只考虑低于 500 美元的票价金额。由于我们需要预测每个出租车供应商的数据,因此我们将按 vendor_id 聚合数据集。
SELECT
toStartOfHour(pickup_datetime) AS pickup_hour,
vendor_id,
sum(fare_amount) AS fares
FROM default.tripdata
WHERE total_amount >= 0 AND total_amount <= 500
GROUP BY pickup_hour, vendor_id
ORDER BY pickup_hour, vendor_id
我们可以通过将时间戳数据下采样到小时间隔并聚合一小时间隔内的所有数据来进一步减小数据集的大小。
使用ClickHouse处理非常大的数据集
就所使用的资源和生成数据所需的时间而言,在海量数据集上运行任何查询通常都非常昂贵。当我们必须多次运行查询、使用复杂的转换生成新功能或源数据老化并且我们需要更新版本时,这可能会令人头疼。但是,ClickHouse对此有一个解决方案,即物化视图。
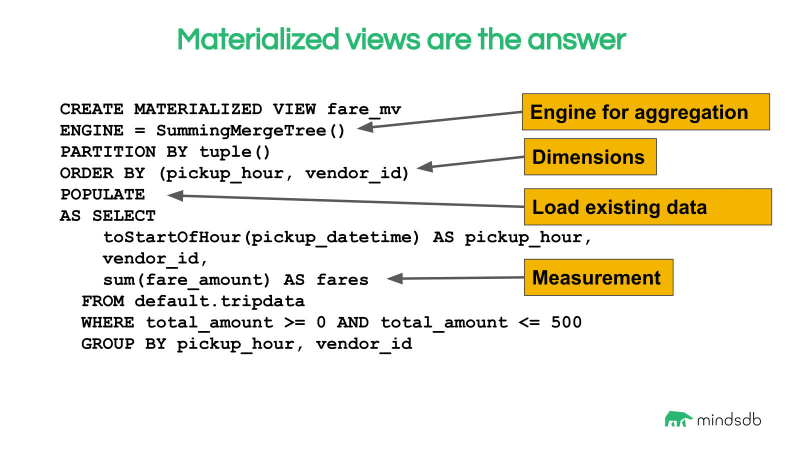
常规 SQL 视图相反,在常规 SQL 视图中,视图只是封装 SQL 查询并在每次执行时重新运行它,具体化视图仅运行一次,并将数据馈送到具体化视图表中。然后,我们可以查询这个新表,每次将数据添加到原始源表时,这个视图表也会更新。
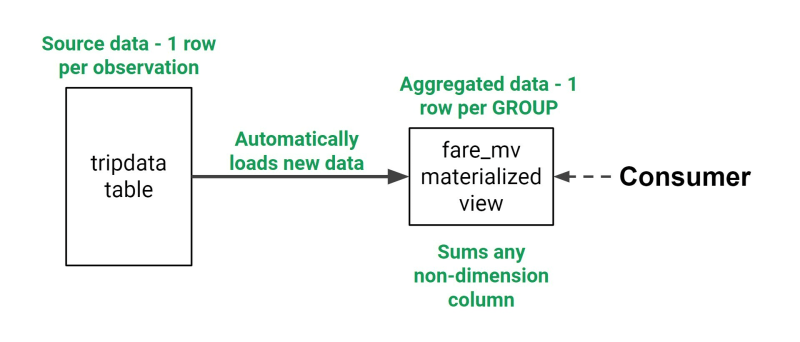
正如你在上面看到的,我们总是可以查询具体化的视图,并确定我们总是根据我们的原始数据获得最新的数据集。然后,我们可以在这个物化视图中使用数据集并训练我们的机器学习模型,而不必担心过时的数据。
与通用视图相比,物化视图在性能方面也有很多好处,在 ClickHouse 中,在超过 20 亿行的数据集上,它们有时甚至快 1 倍。
您还可以利用ClickHouse集群,将数据扩展到多个分片,以从数据仓库中提取最佳性能。您可以在这些数据子集上创建具体化视图,然后将它们统一到分布式表构造下,该构造就像是每个节点的数据上的保护伞。

每当需要查询此数据时,只需查询一个分布式表,该表会自动处理从整个群集中的多个节点检索数据。

这是一种非常强大的技术,可以让您查询数万亿行数据,聚合它们,并以有用的方式转换它们。从现在开始,我们可以继续进行机器学习部分,甚至可以对数据集进行更深入的分析。
根据复杂的多变量时间序列数据构建预测
现在,让我们根据我们刚刚介绍的纽约市出租车“行程数据”数据集来预测出租车需求。我们将仅关注由vendor_id、上车时间和出租车费用列组成的子集。

更好地了解我们的数据
我们可以更深入地研究ClickHouse生成的数据子集,并绘制收入流,按小时分配。左下角的绿线图显示了 CMT 公司的每小时票价。

但是,我们也可以看到,不仅单个出租车供应商在一天中的票价分布存在差异,而且出租车供应商本身之间的票价分布也存在差异,如下图所示。随着时间的推移,每家公司都有不同的动态,这使得这个问题变得更加困难,因为我们现在没有单一的数据系列,而是多个数据。

多变量时间序列预测的挑战
了解我们的数据集包含多个系列的数据是构建数据预测管道时需要注意的重要信息。如果数据科学家或机器学习工程师团队需要预测任何对你获取见解很重要的时间序列,他们需要意识到这样一个事实,即根据分组数据的外观,他们可能会查看数百或数千个序列。
训练此类机器学习模型可能非常耗时且耗费大量资源,并且根据要提取的见解类型和使用的模型类型,将其扩展到数千个预测其自身时间序列的模型将很难扩展。
在MindsDB,我们处理这个问题已经有一段时间了,我们已经能够使用来自任何数据库(如ClickHouse)的任何类型的数据来自动化这个过程。
MindsDB 如何自动构建 ML 模型
我们的方法围绕着应用灵活的理念,使我们能够解决任何类型的机器学习问题,而不一定只是时间序列问题。这是通过应用我们的编码器-混音器理念来实现的。
MindsDB 预测引擎 – 技术细节

根据每列的数据类型,我们实例化该列的编码器。它的任务是根据该列中的数据开发信息编码。
例如,如果我们有一列包含简单的数字,不需要训练即可解决时间序列问题,那么编码器可以只是一组不需要训练的简单规则。但是,如果列包含自由文本,则编码器将实例化一个 Transformer 神经网络,该神经网络将学习生成该文本的摘要。
下一步是实例化 Mixer,这是一个机器学习模型,其任务是根据 Encoder 的结果进行最终预测。这种类型的哲学提供了一种非常灵活的方法来预测数值数据、分类数据、文本回归和时间序列数据。
MindsDB 中的自动和动态数据规范化
在开始使用数据训练此模型之前,我们可能需要进行一些特定的数据清理,例如进行动态归一化。这意味着对每个数据系列进行归一化,以便我们的 Mixer 模型学习得更快、更好。
MindsDB 捕获数据集的统计数据并规范化每个序列,而 Mixer 模型学习使用这些规范化值预测未来值。
时间信息也通过将时间戳分解为正弦分量来编码。

这样可以进行任意日期处理,并便于处理不均匀采样的序列。当时间序列数据间距不均匀且测量值不规则时,此方法非常有用。
简而言之,对于时间序列问题,机器学习管道的工作方式如下图所示。左上角的输入数据包含非时态信息,这些信息被输入编码器,然后传递到混音器中。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
pyjvxWg-1715646628590)]
[外链图片转存中…(img-hmrGvB0V-1715646628590)]
[外链图片转存中…(img-D1BgC9wD-1715646628590)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Go语言开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 1934
1934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









