








网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
}
>
> 在C语言中有标准输入输出函数scanf和printf,而在C++中有**cin标准输入**和**cout标准输出**。在C语言中使用scanf和printf函数,需要包含头文件stdio.h。在C++中使用cin和cout,需要包含**头文件iostream**以及**std标准命名空间**。
>
>
>
>
> C++的输入输出方式与C语言更加方便,因为C++的输入输出不需要控制格式,例如:整型为%d,字符型为%c。
>
>
>
#include
using namespace std;
int main()
{
int a = 1;
float b = 2.1;
double c= 2.111;
char arr[10] = { 0 };
char d[] = “hello world”;
cin >> arr;
cout << arr << endl;
cout << a << endl;
cout << b << endl;
cout << c << endl;
cout << d << endl;
return 0;
}
>
> 注意:endl,这其中的l不是阿拉伯数字1,而是26个英文字母的l,它的作用相当于换行。
>
>
>
>
> 这里我们还要注意下cin的特点,他和C语言中的gets有些像,gets是遇到换行符停止,而cin是以遇到空格,tab或者换行符作为分隔符的,因此这儿输入hello world会被空格符分隔开来。
> 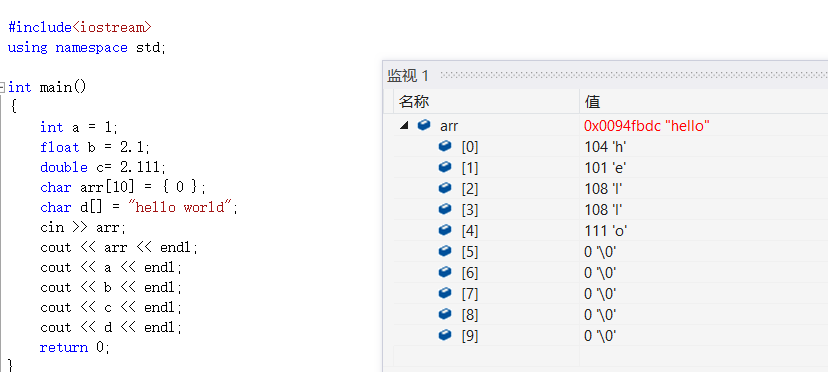
> 这儿我输入的是hello world,但因为输入时出现了空格,所以之后的内容并不会读入,因此arr中存的就是hello。
>
>
>
---
## 缺省参数
>
> 缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参。
>
>
>
//缺省参数
#include
using namespace std;
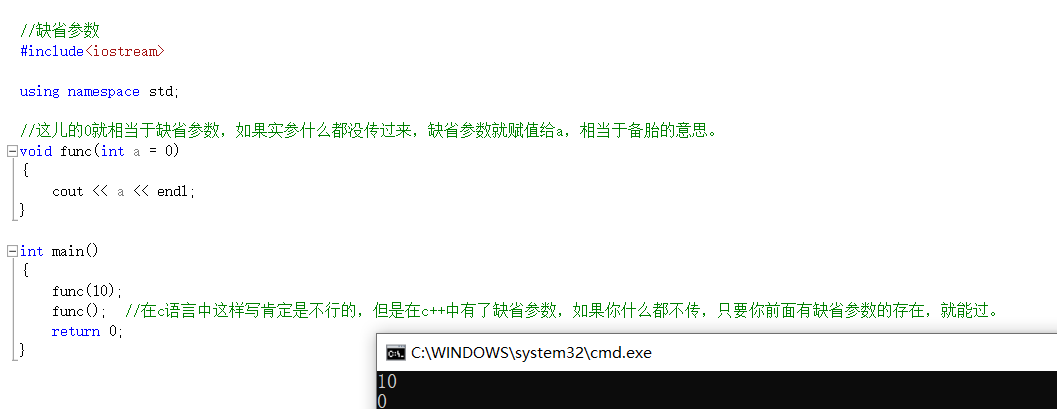
//这儿的0就相当于缺省参数,如果实参什么都没传过来,缺省参数就赋值给a,相当于备胎的意思。
void func(int a = 0)
{
cout << a << endl;
}
int main()
{
func(10);
func(); //在c语言中这样写肯定是不行的,但是在c++中有了缺省参数,如果你什么都不传,只要你前面有缺省参数的存在,就能过。
return 0;
}
### 全缺省
>
> 全缺省参数,即函数的全部形参都设置为缺省参数。
>
>
>
//全缺省
#include
using namespace std;
void func(int a = 0, int b = 1, int c = 2)
{
cout <<“a=”<< a << endl;
cout << b << endl;
cout << c << endl;
}
int main()
{
func();
return 0;
}
### 半缺省参数
void func(int a, int b, int c = 2)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
>
> 注意:
> 1、半缺省参数必须从右往左依次给出,不能间隔着给。
>
>
>
//错误示例
void func(int a, int b = 2, int c)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
>
> 2、缺省参数不能在函数声明和定义中同时出现
>
>
>
//错误示例
//test.h
void func(int a, int b, int c = 3);
//test.c
void func(int a, int b, int c = 2)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
>
> 因为:如果声明与定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该用那
> 个缺省值。
>
>
>
>
> 3、缺省值必须是常量或者全局变量。
>
>
>
//正确示例
int x = 3;//全局变量
void func(int a, int b = 2, int c = x)
{
cout << a << endl;
cout << b << endl;
cout << c << endl;
}
---
## 函数重载
>
> 函数重载:是函数的一种特殊情况,C++允许在**同一作用域**中声明几个功能类似的**同名函数**,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,常用来处理实现功能类似数据类型不同的问题
>
>
>
#include
using namespace std;
int Add(int x, int y)
{
return x + y;
}
double Add(double x, double y)
{
return x + y;
}
int main()
{
cout << Add(0,1) << endl;//打印0+1的结果
cout << Add(1.1,2.2) << endl;//打印1.1+2.2的结果
return 0;
}
>
> 注意:若仅仅只有返回值不同,其他都相同,则不构成函数重载。
>
>
>
short Add(short left, short right)
{
return left+right;
}
int Add(short left, short right)
{
return left+right;
}
### 函数重载的原理
>
> 为什么C++支援函数重载,而C语言不可以了?
> 这里我们就要回顾一下以前的知识了,在运行到执行文件前,要经过:**预编译,编译,汇编,链接**这些阶段
> 其实问题就出在编译完之后的汇编阶段,因为在这里C++和C语言有着些许的不同,下面我们来看看:
>
>
>
>
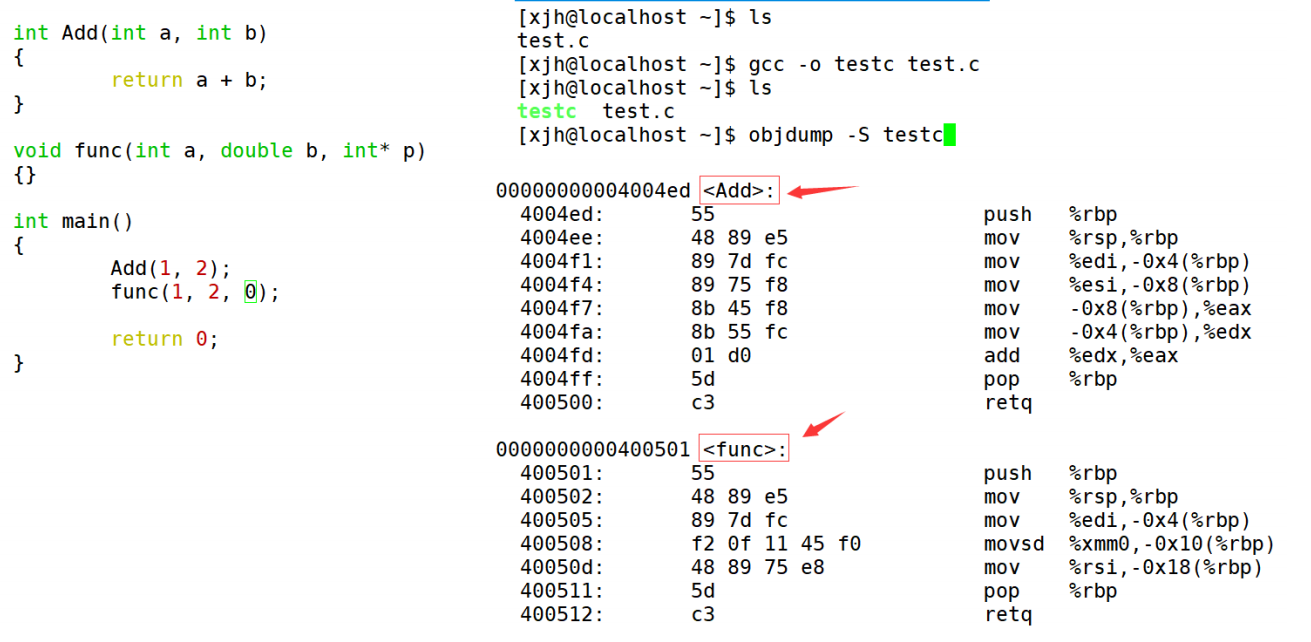
> 采用C语言编译器编译之后
>
>
>
>
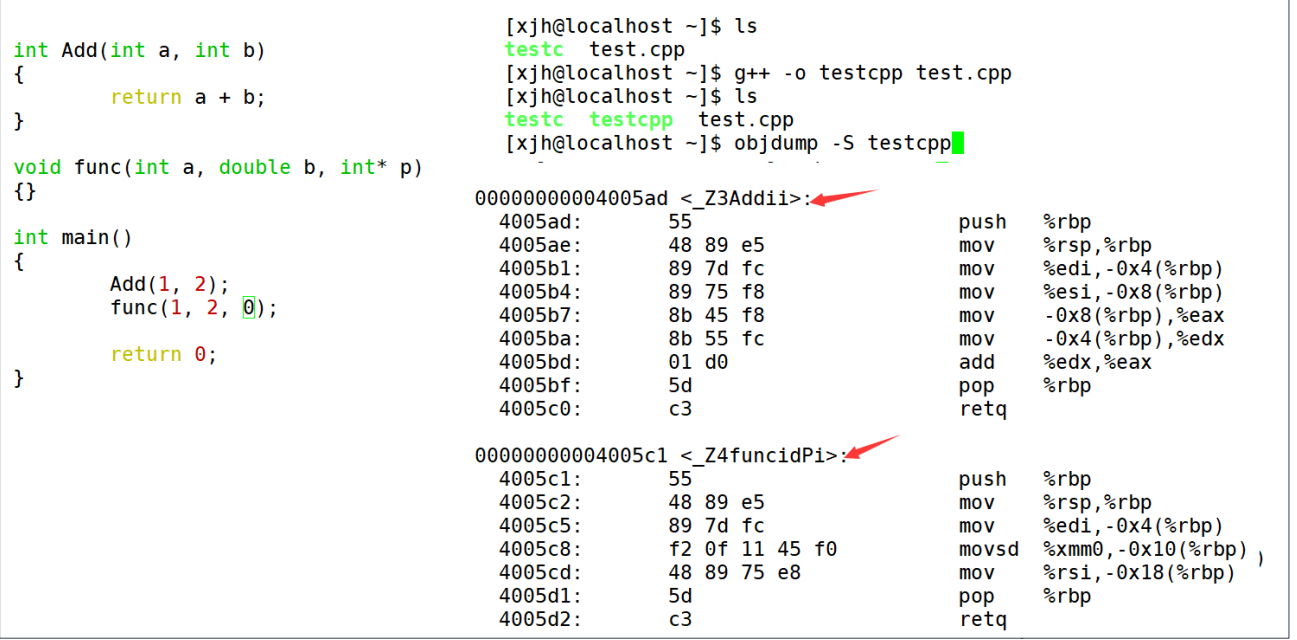
> 采用C++编译器编译之后
>
>
>
>
> 总结:
> 1.其实归根到底,还是因为C编译器和C++编译器对函数名的修饰不同。在gcc下的修饰规则是:【\_Z+函数长度+函数名+类型首字母】。
> 2.这其实也告诉我们为什么函数的返回类型不同,不会构成函数重载,因为修饰规则并不会受返回值的影响。
>
>
>
---
## extern “C”
>
> 有时候在C++工程中可能需要将某些函数按照C的风格来编译,在函数前加extern “C”,意思是告诉编译器,
> 将该函数按照C语言规则来编译。比如:tcmalloc是google用C++实现的一个项目,他提供tcmallc()和tcfree两个接口来使用,但如果是C项目就没办法使用,那么他就使用extern “C”来解决。
>
>
>
---
## 引用
>
> 引用不是新定义一个变量,**而是给已存在变量取了一个别名**,编译器不会为引用变量开辟内存空间,它和它引用的变量**共用同一块内存空间**。
>
>
> 类型& 引用变量名(对象名) = 引用实体;
>
>
>
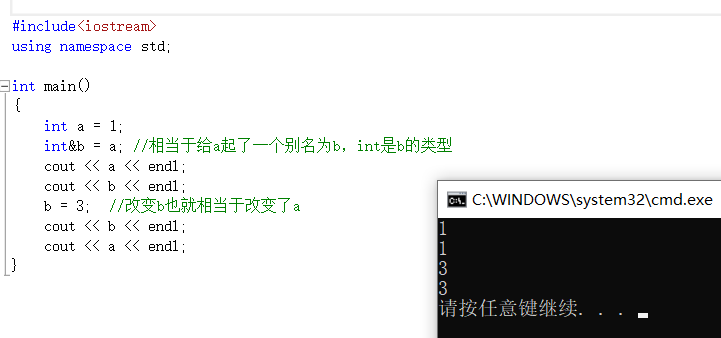
#include
using namespace std;
int main()
{
int a = 1;
int&b = a; //相当于给a起了一个别名为b,int是b的类型
cout << a << endl;
cout << b << endl;
b = 3; //改变b也就相当于改变了a
cout << b << endl;
cout << a << endl;
}
>
> 注意:**引用类型必须和引用实体是同种类型的**
>
>
>
### 引用的特征
#### 1.引用在定义时必须初始化
//正确示例
int a = 10;
int& b = a;//引用在定义时必须初始化
//错误示例
int a = 10;
int &b;//定义时未初始化
b = a;
#### 2.一个变量可以有多个引用
int a = 10;
int& b = a;
int& c = a;
int& d = a;
#### 3.引用一旦引用了一个实体,就不能再引用其他实体
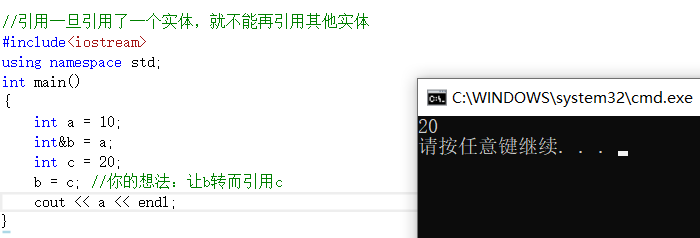
int a = 10;
int& b = a;
int c = 20;
b = c;//你的想法:让b转而引用c
>
> 但实际的效果,确实将c的值赋值给b,又因为b是a的引用,所以a的值见解变成了20。
>
>
>
### 常引用
>
> 上面提到,引用类型必须和引用实体是同种类型的。但是仅仅是同种类型,还不能保证能够引用成功,这儿我们还要注意可否可以修改的问题。
>
>
>
void TestConstRef()
{
const int a = 10;
//int& ra = a; // 该语句编译时会出错,a为常量
const int& ra = a;
// int& b = 10; // 该语句编译时会出错,b为常量
const int& b = 10;
double d = 12.34;
//int& rd = d; // 该语句编译时会出错,类型不同
const int& rd = d;
}
>
> 这里的a,b,d都是常量,常量是不可以被修改的,但是如果你用int&ra等这样来引用a的话,那么引用的这个a是可以被修改的,因此会出问题。
> 下面我们来看这么一段代码:
>
>
>
#include
using namespace std;
int main()
{
int a = 10;
double&ra = a;
}
>
> 这个引用对吗?想要弄明白这个问题,首先要明白隐式类型转化的问题,在这里int到double存在隐式类型的提升,而在提升的过程中系统会创建一个常量区来存放a类型提升后的结果。因此到这儿,这段代码一看就是错了,因为你隐式类型提升时a是存放在常量区中的,常量区是不可以被修改的,而你用double&ra去引用他,ra这个引用是可以被修改的。
>
>
>
>
> 加个const就可以解决这个问题。
>
>
>
#include
using namespace std;
int main()
{
int a = 10;
const double&ra = a;
}
>
> 注意:将不可修改的量用可读可写的量来引用是不可以的,但是反过来是可以的,将可读可写的量用只可读的量来引用是可以的。
>
>
>
### 引用的使用场景
#### 1.引用做参数
>
> 还记得C语言中的交换函数,学习C语言的时候经常用交换函数来说明传值和传址的区别。现在我们学习了引用,可以不用指针作为形参了。因为在这里a和b是传入实参的引用,我们将a和b的值交换,就相当于将传入的两个实参交换了。
>
>
>
//交换函数
void Swap(int& a, int& b)
{
int tmp = a;
a = b;
b = tmp;
}
#### 2.引用做返回值
>
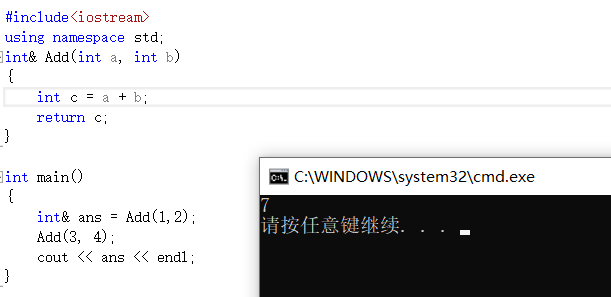
> 当然引用也能做返回值,但是要特别注意,我们返回的数据不能是函数内部创建的普通局部变量,因为在函数内部定义的普通的局部变量会随着函数调用的结束而被销毁。我们返回的数据必须是被static修饰或者是动态开辟的或者是全局变量等不会随着函数调用的结束而被销毁的数据。
>
>
>
>
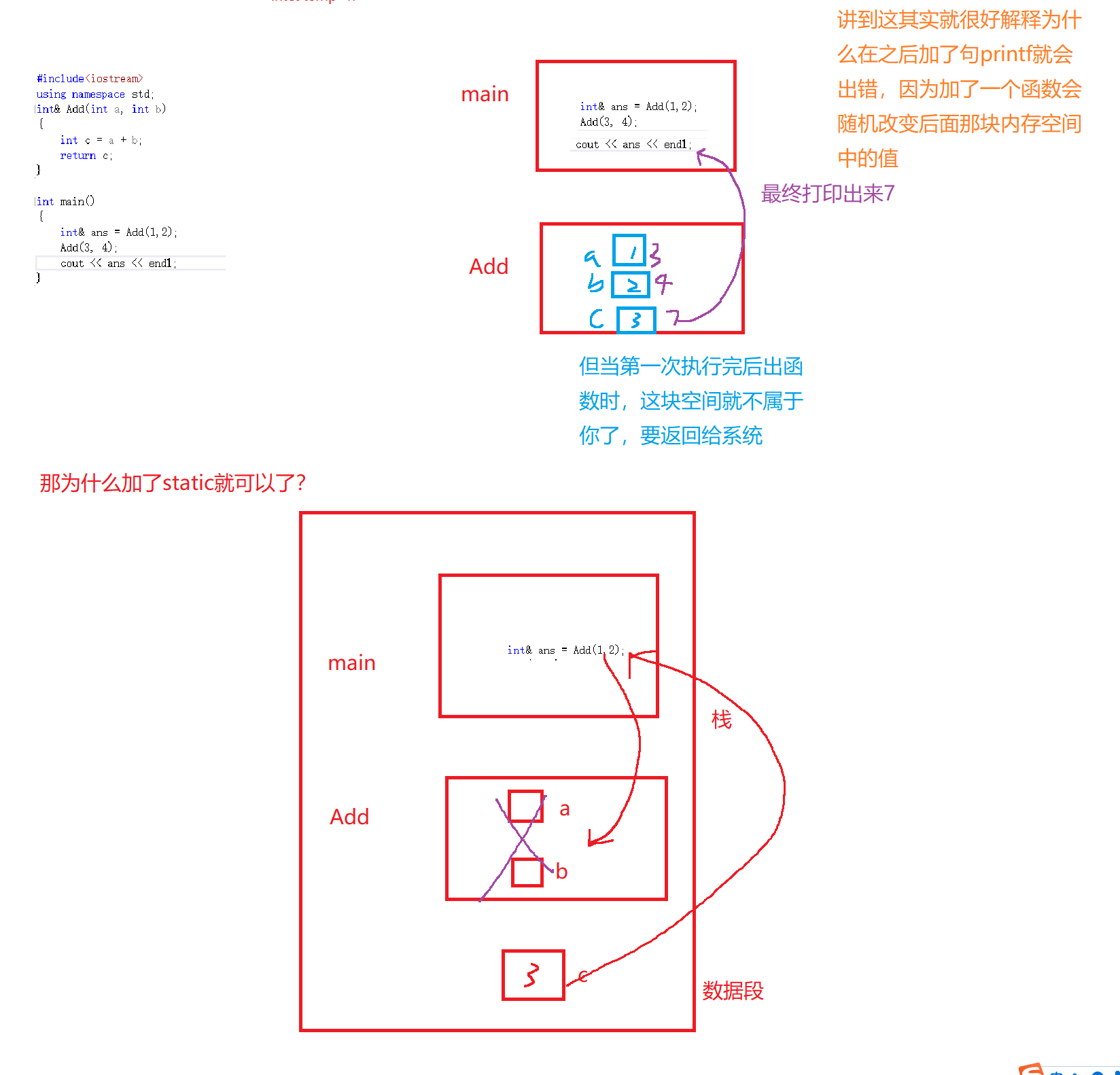
> 不加static的后果
>
>
>
>
> 你是不是疑惑为什么打印的不是3而是7了?
>
>
>
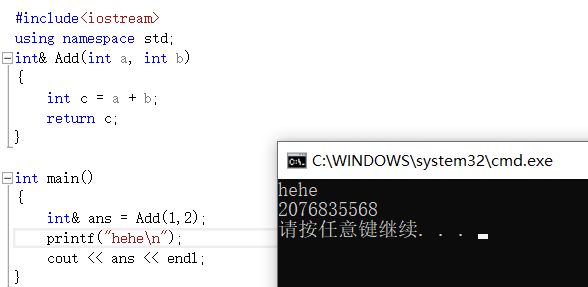
>
> 这就更奇怪了,为什么中间加了一句printf,就打印随机值了?
> 下面我们来看看分析:
>
>
>
>
> ***为什么会出现随机值,因为你在函数里定义的变量是临时变量,出了函数函数是会销毁的,这时它就随机指向内存中的一块空间了***。所以在引用做函数返回值时最好还是给在函数中定义的变量加上static。
>
>
>
>
> 这时你觉得你真的懂这段代码了吗?
>
>
>
#include
using namespace std;
int& Add(int a, int b)
{
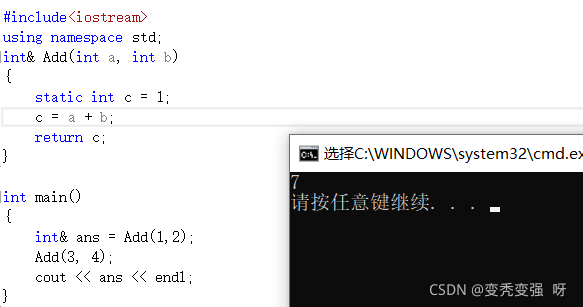
static int c = a + b;
return c;
}
int main()
{
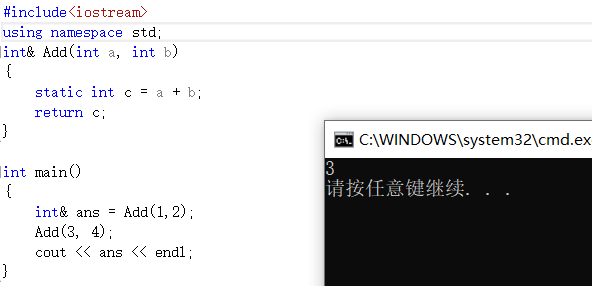
int& ans = Add(1,2);
Add(3, 4);
cout << ans << endl;
}
>
> 可能你会好奇了?为什么这儿是3了?下面来看看分析
>
>
>

>
> 其实你换种写法,这儿的结果就会换成7,原因也很简单,正是上面图片中说的原因
>
>
>
>
> 注意:如果函数返回时,出了函数作用域,返回对象还未还给系统,则可以使用引用返回;如果已经还给系统了,则必须使用传值返回。
> 这句话说的是下面这种例子:
>
>
>
int Add(int a, int b)
{
int c=a+b; //出了函数作用域,c不在,回给了系统
return c;
}
int& Add(int a,int b)
{
static c=a+b; //出了函数作用域,c还在,可以用引用返回
return c;
}
>
> 大家是不是感觉这个传引用返回用起来很怪了,下面我们来分析一下它是如何返回的。
>
>
>

>
> 总结:
> `传值的过程中会产生一个拷贝,而传引用的过程中不会,其实在做函数参数时也具有这个特点。`
>
>
>
### 引用和指针的区别
>
> 在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
>
>
>
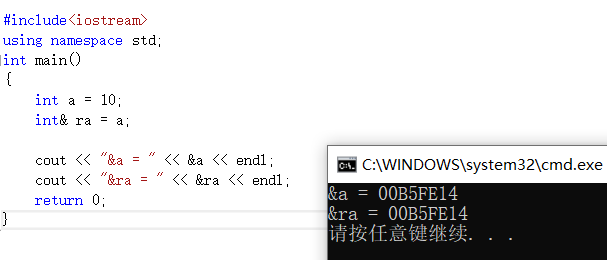
int main()
{
int a = 10;
int& ra = a;
cout<<"&a = “<<&a<<endl;
cout<<”&ra = "<<&ra<<endl;
return 0; }
>
> 在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
>
>
>
int main()
{
int a = 10;
int& ra = a;
ra = 20;
int* pa = &a;
*pa = 20;
return 0;
}
>
> 我们来看下引用和指针的汇编代码对比
>
>
>

>
> **引用和指针的区别**
> 1、引用在定义时必须初始化,指针没有要求。
> 2、引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体。
> 3、没有NULL引用,但有NULL指针。
> 4、在sizeof中的含义不同:引用的结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)。
> 5、引用进行自增操作就相当于实体增加1,而指针进行自增操作是指针向后偏移一个类型的大小。
> 6、有多级指针,但是没有多级引用。
> 7、访问实体的方式不同,指针需要显示解引用,而引用是编译器自己处理。
> 8、引用比指针使用起来相对更安全。
>
>
>
---
## 内联函数
>
> 概念:以inline修饰的函数叫做内联函数,编译时C++编译器会在**调用内联函数的地方展开**,没有函数压栈的开销,
> 内联函数提升程序运行的效率。(看到在加粗部分时,小伙伴肯定会想,这和c语言中的宏是不是很像了?)
>
>
>
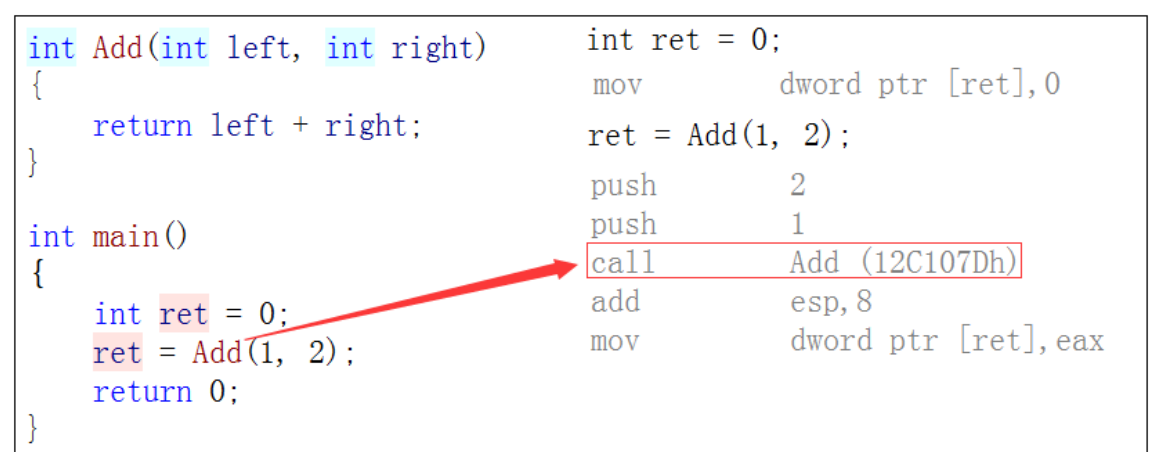
>
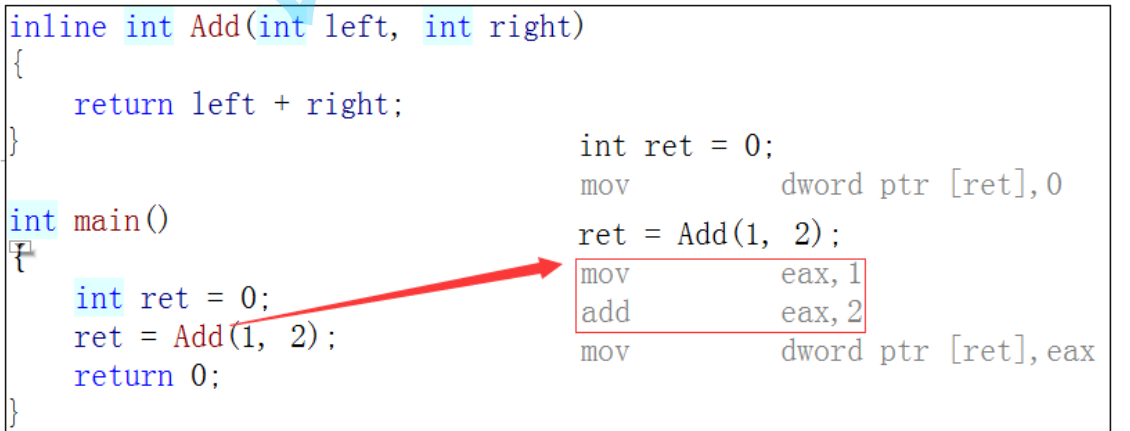
> 如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用
>
>
>
### 特性
>
> 1. inline是一种以空间换时间的做法,省去调用函数额开销。所以代码很长/递归的函数不适宜
> 使用作为内联函数。
> 2. inline对于编译器而言只是一个建议,编译器会自动优化,如果定义为inline的函数体内代码比较长/递归等
> 等,编译器优化时会忽略掉内联。
> 3. inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会
> 找不到。
>
>
>
//F.h
#include
using namespace std;
inline void f(int i);
// F.cpp
#include “F.h”
void f(int i) {
cout << i << endl;
}
// main.cpp
#include “F.h”
int main()
{
f(10);
return 0;
}
// 链接错误:main.obj : error LNK2019: 无法解析的外部符号 “void __cdecl f(int)” (?
// f@@YAXH@Z),该符号在函数 _main 中被引用
### c++有哪些技术可以代替宏
>
> C++有哪些技术替代宏?
>
>
> 1. 常量定义 换用const
> 2. 函数定义 换用内联函数
>
>
>
---
## auto关键字(C++11)
>
> 在早期的C/C++中auto的含义是:使用auto修饰的变量是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它。
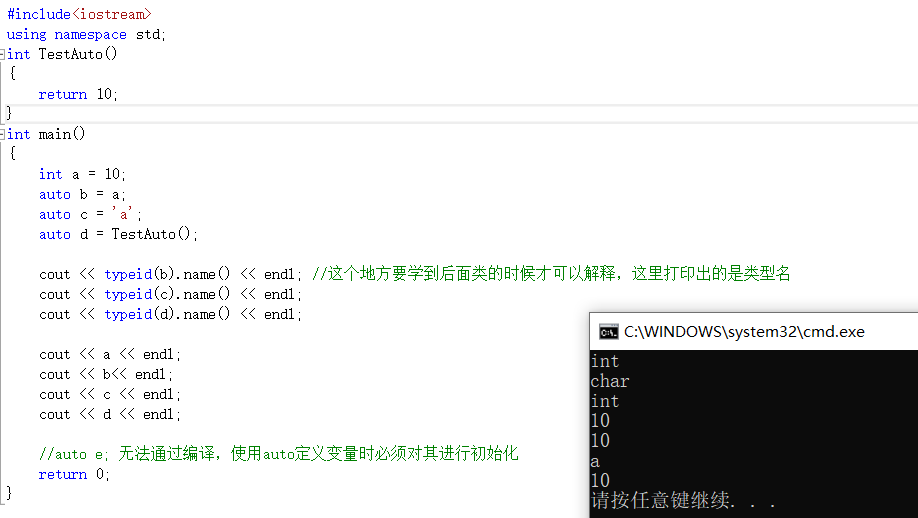
> 在C++11中,标准委员会赋予了auto全新的含义:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。 可能光看这一句话,你不一定能懂,下面我们举几个例子。
>
>
>
#include
using namespace std;
int TestAuto()
{
return 10;
}
int main()
{
int a = 10;
auto b = a;
auto c = ‘a’;
auto d = TestAuto();
cout << typeid(b).name() << endl; //这个地方要学到后面类的时候才可以解释,这里打印出的是类型名
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
cout << a << endl;
cout << b<< endl;
cout << c << endl;
cout << d << endl;
//auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化
return 0;
}
>
> 注意:使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类
> 型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
>
>
>
### auto的使用细则
#### 1.auto与指针和引用结合起来使用
>
> 用auto声明指针类型时,用auto和auto\*没有任何区别,但用auto声明引用类型时则必须加&
>
>
>
#include
using namespace std;
int main()
{
int a = 10;
auto b = &a; //自动推导出b的类型为int*
auto* c = &a; //自动推导出c的类型为int*
auto& d = a; //自动推导出d的类型为int
//打印变量b,c,d的类型
cout << typeid(b).name() << endl;//打印结果为int*
cout << typeid©.name() << endl;//打印结果为int*
cout << typeid(d).name() << endl;//打印结果为int
return 0;
}
>
> 注意:用auto声明引用时必须加&,否则创建的只是与实体类型相同的普通变量,只不过将其换了个姓名而已。
>
>
>


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
据初始化表达式来推导auto的实际类
> 型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
>
>
>
### auto的使用细则
#### 1.auto与指针和引用结合起来使用
>
> 用auto声明指针类型时,用auto和auto\*没有任何区别,但用auto声明引用类型时则必须加&
>
>
>
#include
using namespace std;
int main()
{
int a = 10;
auto b = &a; //自动推导出b的类型为int*
auto* c = &a; //自动推导出c的类型为int*
auto& d = a; //自动推导出d的类型为int
//打印变量b,c,d的类型
cout << typeid(b).name() << endl;//打印结果为int*
cout << typeid©.name() << endl;//打印结果为int*
cout << typeid(d).name() << endl;//打印结果为int
return 0;
}
>
> 注意:用auto声明引用时必须加&,否则创建的只是与实体类型相同的普通变量,只不过将其换了个姓名而已。
>
>
>
[外链图片转存中...(img-Dd14vV1g-1715812258011)]
[外链图片转存中...(img-sa39xTr9-1715812258012)]
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以添加戳这里获取](https://bbs.csdn.net/topics/618668825)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 58万+
58万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









