






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
<3>①为了应对文章总词数较少(几十个词)造成大多数单词仅仅只出现一次的情况,程序选取出现频率高于5%的词不论文章总词数取值均无条件输出。②为了应对文章词数很多(5W~50W词)造成输出序列太长,程序选取出现频率高于0.01%的词。③中等篇幅的文章,在出现频率高于0.01%的条件上加上至少出现2次的条件。
2.为了统计的高效性:
对源单词集合和无需统计的单词集合根据字典序进行快速排序(平均O(nlogn)),再进行顺序查找(O(n))以获得相同词的重复次数,得到的词在无需统计的单词集合中查找(O(nlogn)),只有在无需统计的单词集合中不出现才能被统计如结果集,最后对结果集以出现次数为关键字进行降序排序(O(nlogn)),输出结果。总复杂度为(O(nlogn)),测试中课瞬间完成统计10W词级别的输入量。
(如果使用红黑树的二叉检索树实现无意义词集合的维护以及最后统计结果的维护效率可能还能小幅提升,可用STL的set实现,总复杂度仍为(O(nlong)))
3.为了程序的健壮性和适用性:
<1>程序输出保持固定且较强适应性的输出格式,程序会自动过滤掉输入文件中允许任意次序穿插的符号、汉字、标点、空格等非英文字符(但不能有Unicode格式字符),此外程序尽量降低了因某些特殊情况的发生造成格式混乱的可能。
<2>在当输入文件为空时,按照统一的格式输出相应异常提示,并结束程序。
<3>由于输出条件的控制造成输出为空时,也按照统一的格式输出相应异常提示,并结束程序。
例如:当输入一个词数很多的文件(10W个词),而恰好每个词均出现了不足(100000X0.05%=10次),那么作者认为,这篇文章不具有足够的关于**词汇出现次数(频率)**的统计意义。
<4>对于程序的输入输出已经需要剔除的单词,程序均使用文件存放。对于输入输出较大或者需要剔除词集需要修改时,这样的IO方式能够扩大程序的适用范围。(在程序开头代码部分建立一张需要剔除词的表的做法太low了)
<5>关于如何找到需要剔除的词,若仅仅是自己陈列能想到的词,或者借助搜索引擎获取他人收集的虚词表。测试表明这样的做法遗漏较多(作者使用100W词英文小说实际测试结果显示,仍然有几十个无意义词在统计结果的前列)。因此获得虚词以及无意义词有效的方法是:输入一篇100W词及其以上单词量的文章,选取统计到的前100-150个单词复制到需要剔除的词的文件中,并检查其中包含有的有意义词重新删去即可。测试表明,此种方法获得的无意义词表十分有效,在之后的各个量级统计中均很难找到无意义的统计词被列入结果。
4.附图展示不同输入的结果:
<1>大数据量输入:《大卫.科波维尔》英文版统计结果如下:(26.7W词)(耗时:0.6080s)
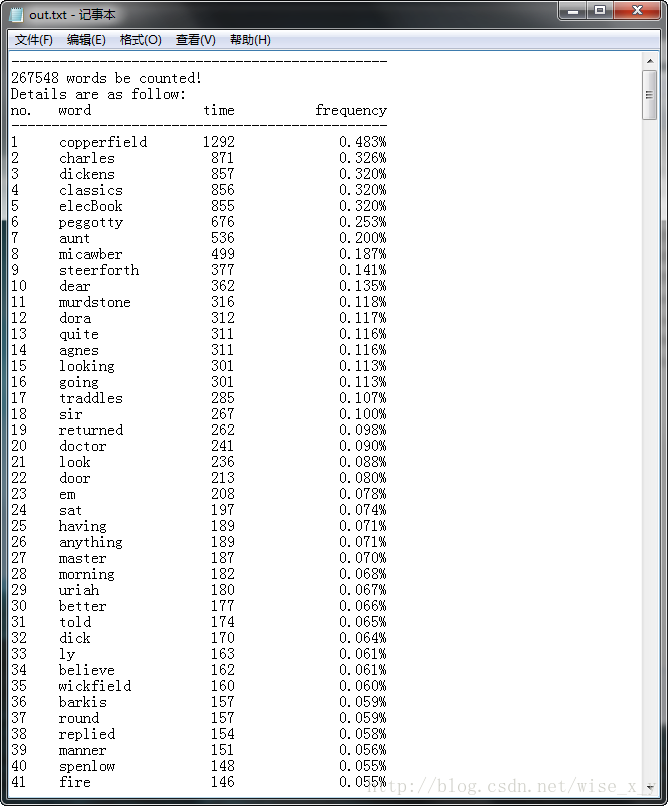
此处省略若干统计信息。
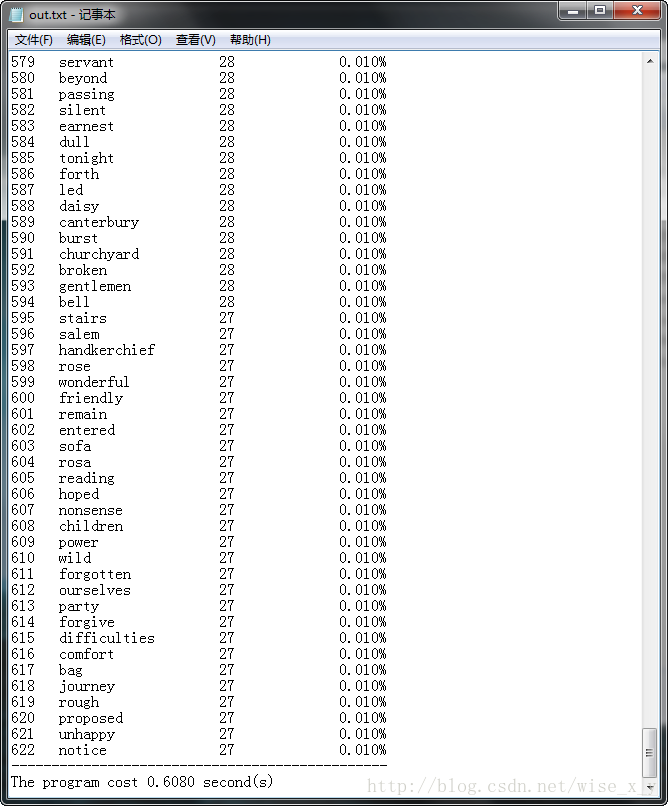
从结果中可以看出,几乎所有的代词介词连词一类统计意义不大的词均已被剔除在外。
<2>小数据量输入:Oracle官网首页统计结果如下:(耗时:0.0030s)
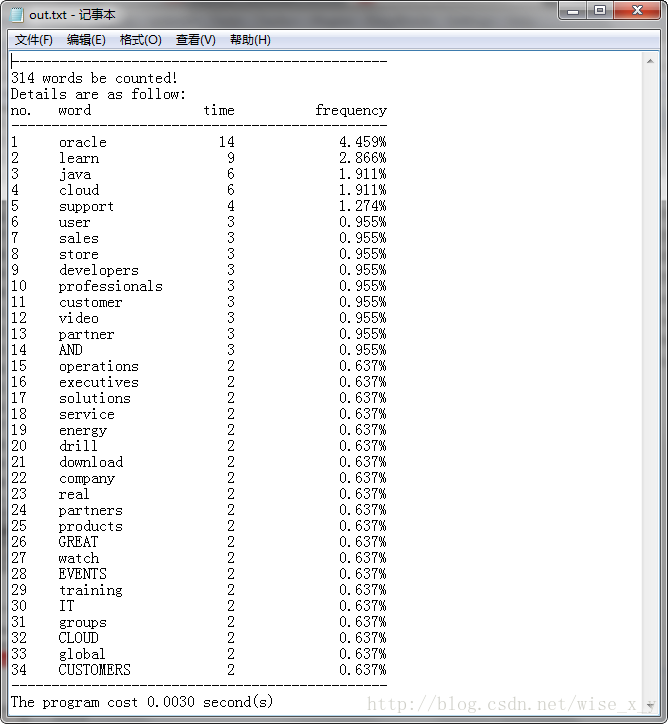
<3>当输入为类似单词表一样各个数据出现次数不能体现出差异并且词数较大时,作者认为这样的词集没有足够的统计意义,因此输出提示信息。
诸如以下输入:

此处省略若干单词。
统计结果如下:
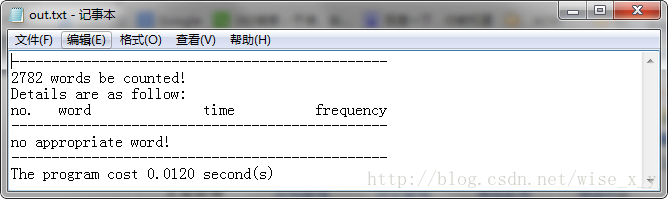
此例子充分证明程序可自动过滤汉字标点等非英文字符,并对于没有足够统计意义的输入提供提示信息。
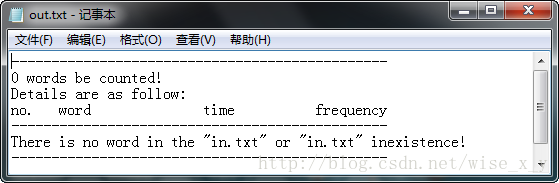
<4>当找不到in.txt文件过in.txt文件为空时。
<5>当程序输入比较大,需要1秒甚至数秒的运算时间时,程序需要输出提示信息表示程序正在正常运行而非卡死。
此例将输入263.6W单词,文件大小12.7M。
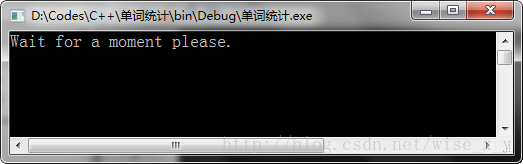
统计结果如下:
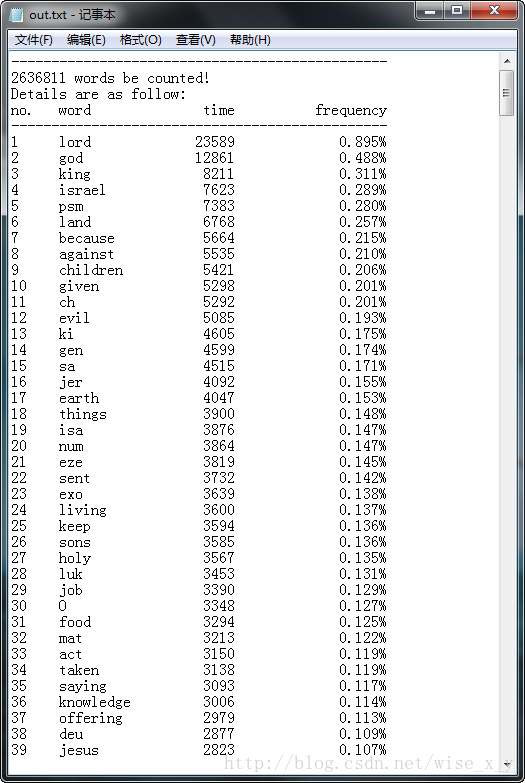
5.实现代码如下:
**#include
#include
#include
#include
#include
#include
using namespace std;
#define MAX_LENGTH 1<<10//单词的最大长度
typedef struct{
string str;
int cnt;
}word;
int number_of_words=0;//记录单词统计总数
vector virtual_word;//需要被除去的虚词集
vector raw_word;//资源文本中的单词集
vector word_statistics;//统计结果集
/*字典排序比较函数*/
bool cmp_raw_word(const string &a,const string &b){return a<b;}
/*词汇出现次数降序排序比较函数*/
bool cmp_word_statistics(const word &a,const word &b){return a.cnt>b.cnt;}
/*虚读取以处理资源文件以及虚词文件除大小写字母外的所有汉字及字符*/
bool skip(){ scanf(“%*[^a-z||A-Z]”); return true;}
int main()
{
/*初始化时间*/
clock_t start,finish;
double totaltime;
start=clock();
printf(“Wait for a moment please.\n”);
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
技术提升。**
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









