







收集整理了一份《2024年最新物联网嵌入式全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升的朋友。


需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人
都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Out[11]:
array([[ 6. , 3.4, 4.5, 1.6],
[ 4.8, 3.1, 1.6, 0.2],
[ 5.8, 2.7, 5.1, 1.9],
[ 5.6, 2.7, 4.2, 1.3],
[ 5.6, 2.9, 3.6, 1.3]])
In [12]: clf = svm.SVC(kernel=‘linear’, C=1).fit(X_train, y_train)
In [13]: clf.score(X_test, y_test)
Out[13]: 0.96666666666666667
---
### 2.`cross_val_score`
### 对数据集进行指定次数的交叉验证并为每次验证效果评测
其中,`score` 默认是以 scoring='f1\_macro’进行评测的,余外针对分类或回归还有:
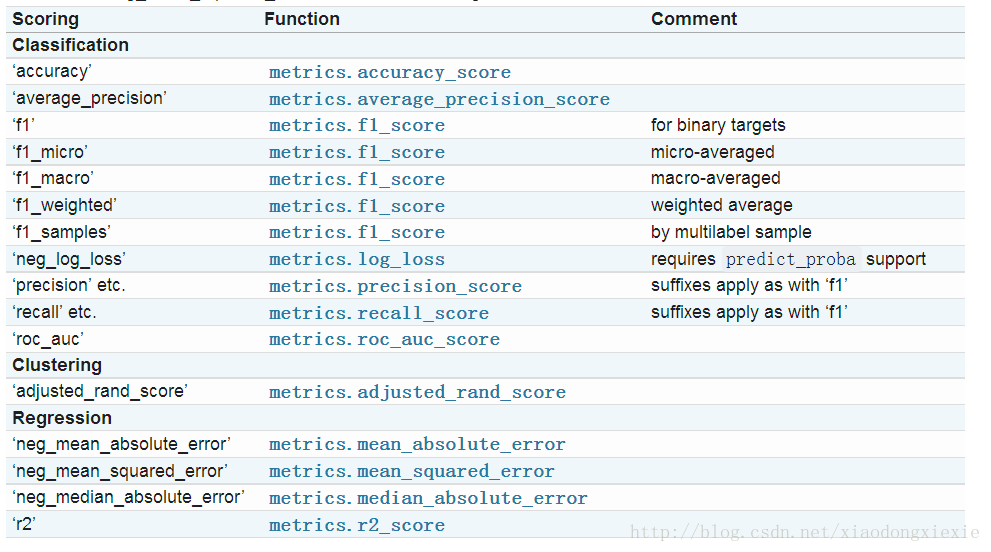
这需要`from sklearn import metrics` ,通过在`cross_val_score` 指定参数来设定评测标准;
当`cv` 指定为`int` 类型时,默认使用`KFold` 或`StratifiedKFold` 进行数据集打乱,下面会对`KFold` 和`StratifiedKFold` 进行介绍。
In [15]: from sklearn.model_selection import cross_val_score
In [16]: clf = svm.SVC(kernel=‘linear’, C=1)
In [17]: scores = cross_val_score(clf, iris.data, iris.target, cv=5)
In [18]: scores
Out[18]: array([ 0.96666667, 1. , 0.96666667, 0.96666667, 1. ])
In [19]: scores.mean()
Out[19]: 0.98000000000000009
除使用默认交叉验证方式外,可以对交叉验证方式进行指定,如验证次数,训练集测试集划分比例等
In [20]: from sklearn.model_selection import ShuffleSplit
In [21]: n_samples = iris.data.shape[0]
In [22]: cv = ShuffleSplit(n_splits=3, test_size=.3, random_state=0)
In [23]: cross_val_score(clf, iris.data, iris.target, cv=cv)
Out[23]: array([ 0.97777778, 0.97777778, 1. ])
在`cross_val_score` 中同样可使用`pipeline` 进行流水线操作
In [24]: from sklearn import preprocessing
In [25]: from sklearn.pipeline import make_pipeline
In [26]: clf = make_pipeline(preprocessing.StandardScaler(), svm.SVC(C=1))
In [27]: cross_val_score(clf, iris.data, iris.target, cv=cv)
Out[27]: array([ 0.97777778, 0.93333333, 0.95555556])
### 3.`cross_val_predict`
`cross_val_predict` 与`cross_val_score` 很相像,不过不同于返回的是评测效果,`cross_val_predict` 返回的是`estimator` 的分类结果(或回归值),这个对于后期模型的改善很重要,**可以通过该预测输出对比实际目标值,准确定位到预测出错的地方,为我们参数优化及问题排查十分的重要。**
In [28]: from sklearn.model_selection import cross_val_predict
In [29]: from sklearn import metrics
In [30]: predicted = cross_val_predict(clf, iris.data, iris.target, cv=10)
In [31]: predicted
Out[31]:
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 1, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
In [32]: metrics.accuracy_score(iris.target, predicted)
Out[32]: 0.96666666666666667
### 4.`KFold`
K折交叉验证,这是将数据集分成K份的官方给定方案,所谓K折就是将数据集通过K次分割,使得所有数据既在训练集出现过,又在测试集出现过,当然,每次分割中不会有重叠。相当于无放回抽样。
In [33]: from sklearn.model_selection import KFold
In [34]: X = [‘a’,‘b’,‘c’,‘d’]
In [35]: kf = KFold(n_splits=2)
In [36]: for train, test in kf.split(X):
…: print train, test
…: print np.array(X)[train], np.array(X)[test]
…: print ‘\n’
…:
[2 3] [0 1]
[‘c’ ‘d’] [‘a’ ‘b’]
[0 1] [2 3]
[‘a’ ‘b’] [‘c’ ‘d’]
### 5.`LeaveOneOut`
`LeaveOneOut` 其实就是`KFold` 的一个特例,因为使用次数比较多,因此独立的定义出来,完全可以通过`KFold` 实现。
In [37]: from sklearn.model_selection import LeaveOneOut
In [38]: X = [1,2,3,4]
In [39]: loo = LeaveOneOut()
In [41]: for train, test in loo.split(X):
…: print train, test
…:
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
#使用KFold实现LeaveOneOtut
In [42]: kf = KFold(n_splits=len(X))
In [43]: for train, test in kf.split(X):
…: print train, test
…:
[1 2 3] [0]
[0 2 3] [1]
[0 1 3] [2]
[0 1 2] [3]
### 6.`LeavePOut`
这个也是`KFold` 的一个特例,用`KFold` 实现起来稍麻烦些,跟`LeaveOneOut` 也很像。
In [44]: from sklearn.model_selection import LeavePOut
In [45]: X = np.ones(4)
In [46]: lpo = LeavePOut(p=2)
In [47]: for train, test in lpo.split(X):
…: print train, test
…:
[2 3] [0 1]
[1 3] [0 2]
[1 2] [0 3]
[0 3] [1 2]
[0 2] [1 3]
[0 1] [2 3]
### 7.`ShuffleSplit`
`ShuffleSplit` 咋一看用法跟`LeavePOut` 很像,其实两者完全不一样,`LeavePOut` 是使得数据集经过数次分割后,所有的测试集出现的元素的集合即是完整的数据集,即无放回的抽样,而`ShuffleSplit` 则是有放回的抽样,只能说经过一个足够大的抽样次数后,保证测试集出现了完成的数据集的倍数。
In [48]: from sklearn.model_selection import ShuffleSplit
In [49]: X = np.arange(5)
In [50]: ss = ShuffleSplit(n_splits=3, test_size=.25, random_state=0)
In [51]: for train_index, test_index in ss.split(X):
…: print train_index, test_index
…:
[1 3 4] [2 0]
[1 4 3] [0 2]
[4 0 2] [1 3]
### 8.`StratifiedKFold`
这个就比较好玩了,通过指定分组,对测试集进行无放回抽样。
In [52]: from sklearn.model_selection import StratifiedKFold
In [53]: X = np.ones(10)
In [54]: y = [0,0,0,0,1,1,1,1,1,1]
In [55]: skf = StratifiedKFold(n_splits=3)
In [56]: for train, test in skf.split(X,y):
…: print train, test
…:
[2 3 6 7 8 9] [0 1 4 5]
[0 1 3 4 5 8 9] [2 6 7]
[0 1 2 4 5 6 7] [3 8 9]
### 9.`GroupKFold`
这个跟`StratifiedKFold` 比较像,不过测试集是按照一定分组进行打乱的,即先分堆,然后把这些堆打乱,每个堆里的顺序还是固定不变的。
In [57]: from sklearn.model_selection import GroupKFold
In [58]: X = [.1, .2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
In [59]: y = [‘a’,‘b’,‘b’,‘b’,‘c’,‘c’,‘c’,‘d’,‘d’,‘d’]
In [60]: groups = [1,1,1,2,2,2,3,3,3,3]
In [61]: gkf = GroupKFold(n_splits=3)
In [62]: for train, test in gkf.split(X,y,groups=groups):
…: print train, test
…:
[0 1 2 3 4 5] [6 7 8 9]
[0 1 2 6 7 8 9] [3 4 5]
[3 4 5 6 7 8 9] [0 1 2]
### 10.`LeaveOneGroupOut`
这个是在`GroupKFold` 上的基础上混乱度又减小了,按照给定的分组方式将测试集分割下来。
In [63]: from sklearn.model_selection import LeaveOneGroupOut
In [64]: X = [1, 5, 10, 50, 60, 70, 80]
In [65]: y = [0, 1, 1, 2, 2, 2, 2]
In [66]: groups = [1, 1, 2, 2, 3, 3, 3]
In [67]: logo = LeaveOneGroupOut()
In [68]: for train, test in logo.split(X, y, groups=groups):
…: print train, test
…:
[2 3 4 5 6] [0 1]
[0 1 4 5 6] [2 3]
[0 1 2 3] [4 5 6]
### 11.`LeavePGroupsOut`
这个没啥可说的,跟上面那个一样,只是一个是单组,一个是多组
from sklearn.model_selection import LeavePGroupsOut
X = np.arange(6)
y = [1, 1, 1, 2, 2, 2]
groups = [1, 1, 2, 2, 3, 3]
lpgo = LeavePGroupsOut(n_groups=2)
for train, test in lpgo.split(X, y, groups=groups):
print train, test
[4 5] [0 1 2 3]
[2 3] [0 1 4 5]
[0 1] [2 3 4 5]


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)
4 5]
[外链图片转存中…(img-Ps8nCt6s-1715792064412)]
[外链图片转存中…(img-a6gvGSfQ-1715792064412)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上物联网嵌入式知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、电子书籍、讲解视频,并且后续会持续更新
需要这些体系化资料的朋友,可以加我V获取:vip1024c (备注嵌入式)















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









