






GNN作为大模型中的一个前置模块,为序列中的Query和Item学习Graph Context信息作为补充,在CTR预估目标下进行端到端的训练。最终决定采用这种方式。
▐ 图的构建
排序模型通过行为序列抽取用户偏好,相当于在Item-User-Query异构图中分别聚合1阶Item和Query邻居来表征用户User。我们可以在Item和Query之间构建更多关系引入更丰富的信息。一方面可以通过用户行为构建共现关系,例如在Query A下Item B共被购买过N次,则在Query A和Item B之间生成一条边,权重为共现频数N;另一方面可以通过Query或Item属性构建属性关系,例如Query A和Query B具有共同属性Attribute C,则在Query A和Query B之间生成一条边,权重可设置为1。本次实验只构建了共现关系。具体而言,根据内部已有的几张表,构建了Query和Item的异构高阶图,包含了q2i、i2q、q2q、i2i几种关系。
由于是通过用户行为来构建图,就需要考虑图的实时性变化。此外,图的结点和边都是上亿级别的,还需要考虑对图进行采样。图 3.1是Item“635266613678”在20210606和20210607的i2q邻居权重分布图,其top10的邻居的从高到低都是“刀叉”、“西餐餐具刀叉”、“牛排刀叉”、“刀叉餐具”、“刀叉牛排”、“西餐刀叉勺”、“西餐刀叉”、“牛排刀”、“牛排餐具刀叉”、“牛排刀叉两件套”。q2i、q2q、i2i也有类似的分布。我们可以观察到两个特点:
-
邻居及其权重分布在天级的时间尺度上变化不大。因此我们可以在第T天使用第T-1天的数据构建邻居。
-
邻居的权重集中在前几个呈现出长尾分布的趋势。如果根据权重分布进行采样,大概率会集中在前几个邻居,考虑到采样带来的额外开销,我们可以用TopN的邻居进行近似。当然这样也会存在潜在的问题,Top N估计是有偏的,也可能不利于模型的泛化性。
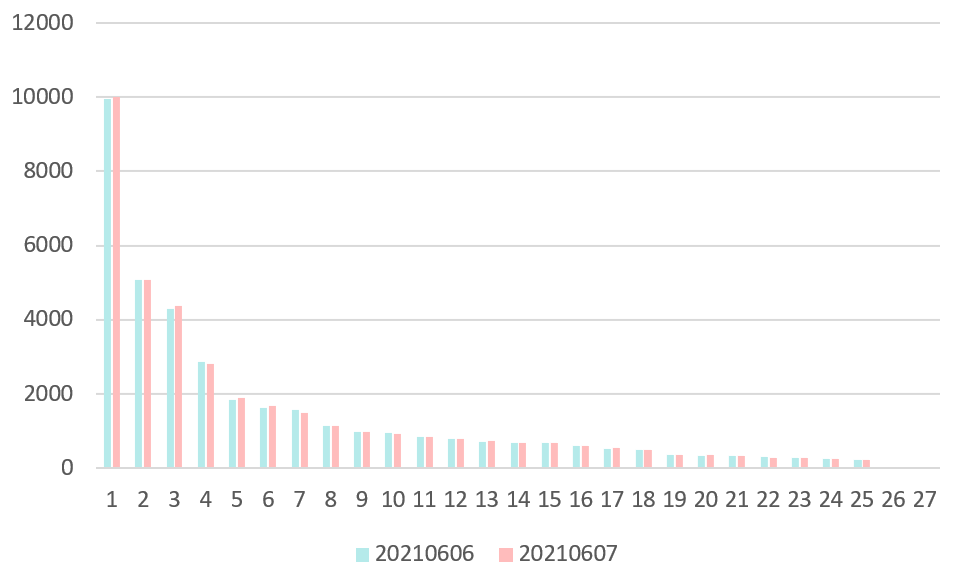
图 3.1 Item 635266613678 在20210606-20210607的邻居权重分布
▐ 特征利用
在生成训练数据时,Query和Item邻居的特征与当前排序模型基本一致。在实验时通过mc.json文件配置真正用到的特征,在不同阶段的实验中用到的特征有所变化。
▐ 模型结构
GNN作为排序模型序列建模部分的一个前置模块,为序列中的Query和Item学习Graph Context Embedding,然后通过以下两种方式进行结合,最终采用哪种方式通过实验确定。

图 3.3 模型结构(Graph Context Feature)
- Graph Context Feature
将学习到的Graph Context Embedding拼接到原来序列中的Query或Item的特征上,见图 3.3中的模块2所示。

图 3.4 模型结构(Graph Context Sequence)
- Graph Context Sequence
将学习到的Graph Context Embedding作为单独的序列与待排序的Query做Target Attention,抽取与用户当前意图相关的宽泛的潜在的偏好,见图 3.4中的模块2所示。
▐ 代码实现
集团内部已有AliGraph、GraphML、Euler等图框架,但是考虑到我们是在大模型上做改动,要求这些框架与AOP等平台较好地兼容,经过调查发现这些图框架均不满足,因此决定**将邻居也组织成序列的格式,在模型代码中通过索引去定位各自的邻居。**例如,有一个Batch的长为20的Query序列,对序列中每个Query采样5个1阶邻居,将其按照顺序组织为长为100的序列,在模型代码中Query序列的Shape为(B, 20, d)经过Reshape为(B, 20, 1, d),邻居序列的Shape为(B, 100, d)经过Reshape后为(B, 20, 5, d),邻居结点和中心结点的位置就一一对应上了,后续的GNN操作也可通过矩阵操作进行。
快速尝试
初期不涉及对模型本身的详细设计,主要目标是快速验证方案的可行性,同时获取一些发现以指导后续实验的调整与模型的改进。在这一阶段仅使用5个1阶邻居,20210607-20210613共计7天的数据用于训练,20210614的数据用于验证。下文中“GCN”表示以mean的方式聚合邻居,“No Aggregator”表示不经过聚合操作,直接将所有邻居用于特征拼接(Graph Context Feature)或者单独序列(Graph Context Sequence),这主要是考虑到“GCN”过于简单可能无法发挥邻居信息的作用,而“No Aggregator”作为一种无损的方式也许可以有所保证(当然前提是模型能有效抽取信息)。“Base”表示当前的下拉排序模型,“Base_20”和“Base_50”分别表示训练样本中的序列长度为50和20。需要注意的是,GNN使用的都是长为20的序列。所有模型都使用同一套超参数,例如学习率、衰减率、Batch Size等等。详细的实验设置见表 4.1。
Hyperparameter | Value |
Neighborhood Size | 5 |
Neighborhood Depth | 1 |
Train Dataset | 20210607-20210613 |
Valid Dataset | 20210614 |
Learn Rate、Weight Decay、Batch Size...... | The same as base model |
表 4.1 实验设置
▐ Graph Context Feature
Base_50 | 83.43 | |
Base_20 | 83.37 | |
Neighbor/Aggregator-> | GCN | No Aggregator |
A: +q2q & i2i & q2i & i2q | 83.54 | 83.36 |
B: +q2i & i2q | 83.49 | 83.34 |
C: +q2q & i2i | 83.54 | 83.43 |
D: +i2q | 83.47 | 83.33 |
表 4.2 Total AUC
采用Graph Context Feature这种将邻居信息拼接到原来的中心结点特征上的方式,总体AUC见表 4.2。我们可以有如下几个发现:
-
Base_50相对Base_20有略微正向的提升,说明加长序列是有收益的但是不明显(万分之6)
-
对于GCN
-
- 加入各种邻居均有略微正向的提升,说明邻居信息是有效的但是在当前设置下效果不明显。(最高千分之1.5**)**
-
同构邻居q2q & i2i相比异构邻居q2i & i2q效果更明显。可能的原因是q2i & i2q数据比较稀疏,经过统计发现其存在50%左右的结点邻居个数不足5个,而q2q & i2i只有15%左右的这样的结点,更多的数据则意味着更多的信息,详情见图 4.1。
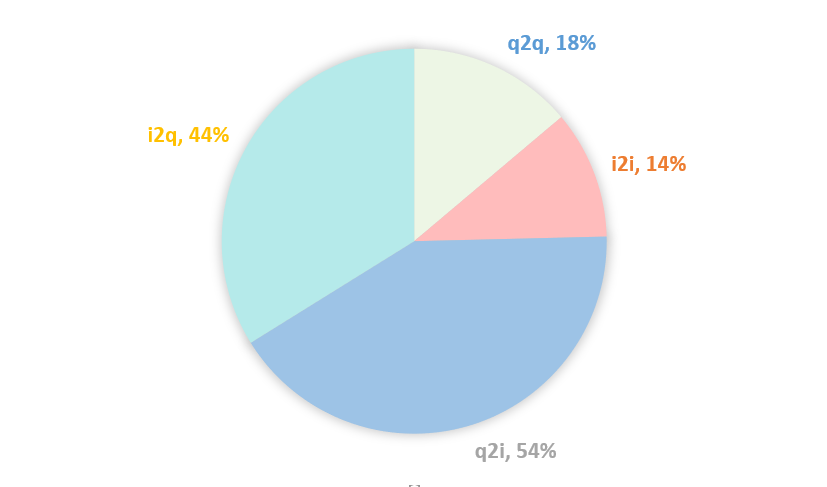
图 4.1 邻居个数不足5个的结点的占比
- **同构邻居和异构邻居均有一些收益,但是同时加入它们却没有进一步的提升。**可能的原因有:一是两种类型的邻居包含的信息有重叠,二是Graph Context Feature的方式不利于信息的抽取。
- 对于No Aggregator
可以看到,除了同构邻居q2q & i2i,加入其它邻居收益均为负。可能的原因仍然与上述的数据稀疏有关,q2i和i2q有大量邻居不足5个,为了保持维度上的对齐,在代码里这部分被置为了0,导致经过特征拼接后,Query和Item的Embedding中包含了大量0值(始终为0),而这非常不利于深度模型的训练。
▐ Graph Context Sequence
Base_50 | 83.43 | |
Base_20 | 83.37 | |
Neighbor/Aggregator-> | GCN | No Aggregator |
A: +q2q & i2i & q2i & i2q | 83.62 | 83.47 |
B: +q2i & i2q | 83.55 | 83.52 |
C: +q2q & i2i | 83.57 | 83.61 |
D: +i2q | 83.49 | 83.52 |
表 4.3 Total AUC
采用Graph Context Sequence这种将邻居信息作为单独的序列与待排序的Query做Target Attention的方式,总体AUC见表 4.3。我们可以有如下几个发现:
-
对于GCN
-
相比Graph Context Feature的方式,有两个方面的提升:
总体AUC均有所上涨。相比Base_20的最高提升由之前的千分之1.5到现在的千分之2.5。
同时加入同构邻居和异构邻居能够带来进一步的提升。可能的原因是将邻居信息作为单独的序列,相比特征拼接的方式,在用Target Query做兴趣抽取时,能够最大限度地保留Graph Context的信息。至于特征交叉可以交给末层的MLP来做。
-
同构邻居q2q & i2i相比异构邻居q2i & i2q效果明显一点。原因同上。
-
对于No Aggregator:当加入4个邻居序列后,模型的AUC有很明显的下降。可能的原因是序列太长(100)加上参数变多(4组参数),模型可能难以收敛了。表 4.4是A组结果中GCN和No Aggregator下i2i邻居序列前4个位置的Attention曲线对比(其他位置情况类似),可以看到,No Aggregator确实没有收敛。
GCN |
|
No Aggregator |
|
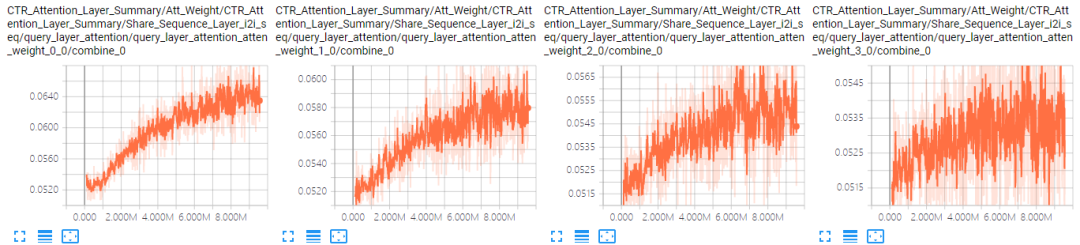
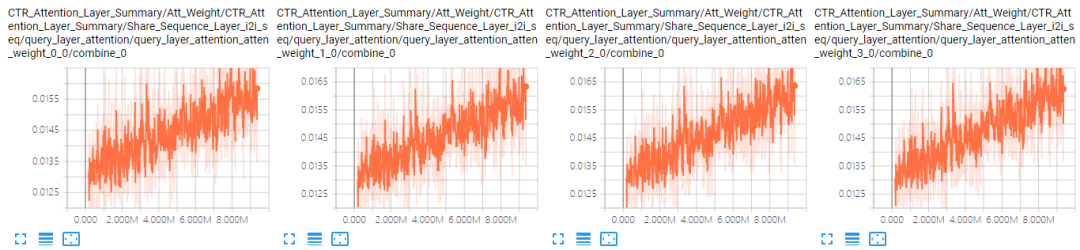
表 4.4 i2i邻居序列Attention曲线对比
▐ Hierarchical Attention
Base_50 | 83.43 | ||
Base_20 | 83.37 | ||
Neighbor/Model-> | +neig atten | +neig & seq attenneig | +neig & seq attenall |
A: +q2q & i2i & q2i & i2q (100%) | 83.46 | 83.47 | 83.49 |
B: +q2i & i2q (75%) | 83.47 | 83.47 | 83.46 |
C: +q2q & i2i (75%) | 83.50 | 83.50 | 83.52 |
D: +i2q (60%) | 83.41 | - | - |
表 4.5 Total AUC
4.1和4.2结果说明了两点,一是引入邻居信息并用GNN建模是有效的,二是Graph Context Sequence的方式优于Graph Context Feature。在此基础上,一方面从图 3.1的Score分布可以看到同种邻居的重要性存在差异,另一方面从之前的实验结果可以看到不同邻居的重要性也存在差异。因此在该部分快速实验了下Attention机制:Neighbor Attention和Sequence Attention,总体AUC见表 4.5。Neighbor Attention是在聚合邻居时自适应学习边的权重,考虑到这里用Target Attention计算量很大,所以使用的是中心结点做Attention。Sequence Attention是将Sequence Embedding加权融合后再送入最后的MLP模块,这里用的是Target Attention。seq atten****neig表示只对邻居序列做融合,力求最小限度改动原有的模型**。seq attenall**表示对所有序列一起做融合。我们可以有如下几个发现:
-
纵向对比,总体上AUC相比GCN大降,不符合预期,至少应该不比GCN差。可能的原因是模型变复杂以后,仅用7天的数据训练已经难以收敛了。表 4.6是A组结果中GCN和+neig & seq attenall最好的结果下i2i邻居序列前4个位置的Attention曲线对比,可以看到,同样存在着没有收敛的问题。
-
横向对比,Sequence Attention有非常微小的收益,并且当序列数量越多时越明显,符合预期。
-
对比GCN或者+neig & seq attenall与Base模型的Attention值还能发现,尽管整体上邻居序列也是前几个位置Attention值比较大,后几个位置的Attention值比较小,但是它们之间的Gap(0.017)相对Base模型(0.12)并不明显。可能的原因是邻居序列中没有使用时间特征。
GCN |
|
Attention |
|
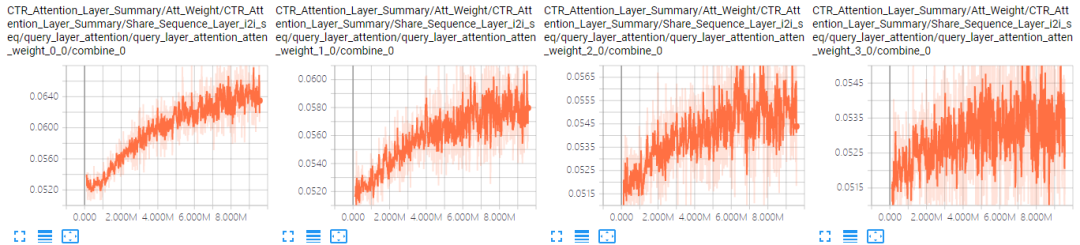
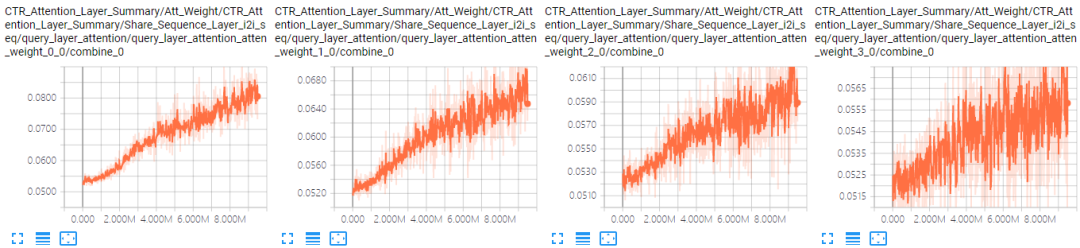
表 4.6 i2i邻居序列Attention曲线对比
为了验证Neighbor Attention和Sequence Attention的有效性,我们可以进一步观察模型学习到的Attention的值。Neighbor Attention如表 4.7所示,Sequence Attention如表 4.8所示。
location-> | 1 | 2 | 3 | 4 | 5 |
q2q | 0.2279 | 0.2044 | 0.1946 | 0.1885 | 0.1846 |
q2i | 0.2160 | 0.2021 | 0.1967 | 0.1936 | 0.1922 |
i2i | 0.1954 | 0.1975 | 0.2001 | 0.2017 | 0.2034 |
i2q | 0.2449 | 0.1954 | 0.1895 | 0.1858 | 0.1844 |
表 4.7 Neighbor Attention
在组织邻居结点时,位置1-N按照共现频数从高到低排列。从表 4.7可以看到,整体上邻居的注意力分布确实符合这一趋势。
sequence-> | query seq | item seq | q2q seq | q2i seq | i2i seq | i2q seq |
attention-> | 0.2755 | 0.1730 | 0.090 | 0.1156 | 0.2060 | 0.1418 |
表 4.8 Sequence Attention
一方面,Query和Item Sequence作为原始序列,所能提供的信息最多,相对邻居序列更重要。另一方面,从之前的结果可以看到,不同的邻居序列的重要性也有差异。表 4.8的结果与预期基本一致。
总体改进
▐ 样本侧
- 问题A
线上排序模型使用的是14+天的训练数据。在之前的实验中当模型变得复杂以后,仅用7天的训练数据模型已经难以收敛了。因此在之后的实验中将训练数据补到了10天(20210701-20210710)。
- 问题B
模型对邻居序列学习到的Attention值之间差异不大,因此在样本中为邻居结点加上了中心结点的时间特征,相当于引入了时间越近越重要的先验知识引导模型学习。
▐ 模型侧
问题A:在邻居聚合(Attention)时使用了多套不同的参数,参数量随邻居序列的数量的增加而增长,之前的实验中模型已经难以收敛了,后续加入更多高阶邻居后问题会更加突出。为此通过Node-Type-Specific Transformation和Edge-Type-Specific Attention建模图的异构性并共享相关参数降低参数量。
问题B:之前的实验中,对于每种邻居序列都与Target Query做Attention,计算量随邻居序列的数量的增加而增长,尽管这一步是并行的其计算量开销仍然不可忽略。为此加入了融合不同类型邻居信息的操作,以及融合邻居和自身信息的操作(除中心结点),最后分别为Query和Item序列得到一个融合了异构高阶信息的Graph Context序列。

图 5.1 模型结构
模型的整体结构如图 5.1所示。GNN部分作为排序模型的一个模块,为Query和Item Sequence分别学习一个Graph Context Sequence作为补充信息。其中比较关键的是:Node-Type-Specific Transformation和Transformer-Like Attention(In-Neighborhood Attention,Inter-Neighborhood Attention,Inter-Sequence Attention)。下面以Query类型的结点为例具体介绍这几种操作。
不同类型的结点的特征维度和特征空间都存在差异,通过特定于结点类型的特征变换操作,一方面可以将特征维度对齐,另一方面尽可能拉近特征空间,便于后续不同类型的结点之间的特征融合(尤其是加法融合)。详情见公式(1),其中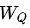 表示Query类型的结点对应的变换矩阵,
表示Query类型的结点对应的变换矩阵,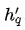 表示Query结点的初始Embedding。
表示Query结点的初始Embedding。
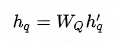
公式 (1)
下拉排序模型中序列与Target Query之间用的是Transformer中点积的方式计算Attention。GAT(图注意力神经网络)中用的是一个带LReLU的隐层计算Attention,在计算复杂度上比点积高一些。此外,考虑到计算方式的一致性,在GNN部分使用了Transformer的方式,并根据图的异构性做了一些修改。共计有4个层次的Attention。
In-Neighborhood Attention
邻域内同种类型的邻居的重要性有差异,这从邻居共现频数分布也能看出(本次实验采用的是Top N采样,差异可能不如随机采样明显)。为此在聚合同种类型的邻居时使用Attention机制。中心结点是Q,邻居结点是K和V,由于已经经过了Node-Type-Specific Transformation,这里不再对Q,K和V做特征变换。此外,考虑到边的类型对相似性的影响,这里的点积是特定于边的类型的双线性点积。详情见公式(2)-(5),其中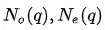 分别表示Query的同构(Homogeneous)和异构(Heterogeneous)邻居,
分别表示Query的同构(Homogeneous)和异构(Heterogeneous)邻居,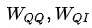 分别表示q2q和q2i类型的边对应的参数矩阵。
分别表示q2q和q2i类型的边对应的参数矩阵。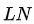 是Layer Normalization,用于保持数据的分布。
是Layer Normalization,用于保持数据的分布。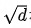 是Scale Factor,用于将方差缩至1。
是Scale Factor,用于将方差缩至1。
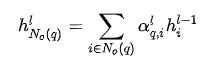
公式 (2)
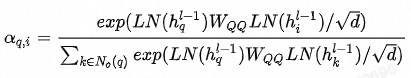
公式 (3)
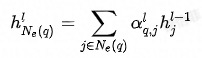
公式 (4)
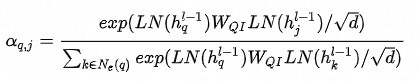
公式(5)
Inter-neighborhood Attention
除了邻域内同种类型的邻居的重要性有差异,邻域间不同类型的邻居的重要性也有差异**,这从之前的加入不同类型邻居序列的实验结果也能看出。为此在融合不同类型的邻居时也使用Attention机制。此外,考虑到当存在异构邻居时,Attention的值更容易被中心结点自身所主导,在进行特征融合时邻居信息就容易被稀释掉,所以这里中心结点不作为K、V参与Attention的计算**。详情见公式(6)-(7)。
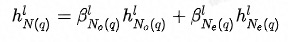
公式(6)
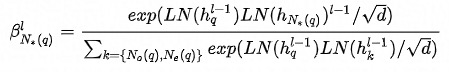
公式(7)
最终的Embedding见公式(8),其中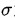 为激活函数ReLU。需要注意的是,最初的Query和Item自身不参与特征融合,也就是说,最终得到的是最初的Query和Item的
为激活函数ReLU。需要注意的是,最初的Query和Item自身不参与特征融合,也就是说,最终得到的是最初的Query和Item的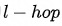 的Graph Context信息。
的Graph Context信息。
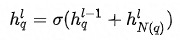
公式(8)
对于GCN,以上公式中的重要性系数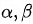 则替换为了相应的平均系数,其他地方都保持一致,下文中称之为HGCN。
则替换为了相应的平均系数,其他地方都保持一致,下文中称之为HGCN。
-
In-Sequence Attention:这一部分与下拉模型保持一致,使用Transformer抽取序列中与Target Query相关的用户偏好。
-
Inter-sequence attention:这里延续了快速尝试部分的Sequence Attention模块,在新的训练样本上进一步通过实验探究其有效性。
Sequence Attention相比直接concat的一个缺点是,不能经过MLP层与Prefix、User Profile等特征进行充分的特征交叉。
实验验证
在快速尝试的实验的基础上,扩大了样本规模,新增了样本特征,并针对性地改进了模型。在这一部分,首先会验证GCN下是否还有类似的结论,接着验证改进后模型的总体效果如何,然后验证加宽邻居是否会带来收益,最后验证加深邻居是否会带来收益。总体上,之前的改进是有效的,在数据规模变大后,相比之前千分之2.5的提升,AUC不仅没有下降反而进一步提升至千分之4.1。
▐ GCN下是否还有类似结论
Base_50 | 84.36 |
Base_20 | 84.09 |
Neighbor/Model-> | HGCN |
A:+q2q & i2i & q2i & i2q | 84.44 |
B:+q2i & i2q | 84.42 |
C:+q2q & i2i | 84.47 |
表 6.1 Total AUC
HGCN与GCN唯一的区别是以Mean的方式融合了不同类型的邻居,总体AUC见表 6.1。可以发现,以下几个结论仍然保持不变:
-
加长序列仍然是有效的,并且效果变得更加明显**(千分之2.5)**。
-
加入各种邻居序列都能带来收益,并且同构邻居收益最大**(千分之3.8)**。
不过我们也能发现,当同时加入所有邻居,模型的效果却下降了。这可能是由于Mean的融合方式引起的,实际上不同的邻居重要性是有差异的。
“372”>
84.42
C:+q2q & i2i
84.47
表 6.1 Total AUC
HGCN与GCN唯一的区别是以Mean的方式融合了不同类型的邻居,总体AUC见表 6.1。可以发现,以下几个结论仍然保持不变:
-
加长序列仍然是有效的,并且效果变得更加明显**(千分之2.5)**。
-
加入各种邻居序列都能带来收益,并且同构邻居收益最大**(千分之3.8)**。
不过我们也能发现,当同时加入所有邻居,模型的效果却下降了。这可能是由于Mean的融合方式引起的,实际上不同的邻居重要性是有差异的。















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









