






信息安全是一个古老的计算机领域。许多 80 后还记得自己小时候经常听到的瑞星杀毒和江民杀毒软件。这些 90 年代火遍大江南北的信息安全工具,至今仍然影响着使用互联网和信息技术的千家万户。随着人工智能的兴起和普及,有越来越多的商业软件使用了人工智能技术,因此也有黑客盯上了相关的技术产品,研发出了专门攻击人工智能软件的黑客手段。

在 2023 年的人工智能顶级会议 AAAI 2023 上,来自新加坡和中国的研究团队发表了一篇题为 Backdoor Attack through Machine Unlearning 的论文,讲述了在新的信息流通环境下的黑客攻与防。论文的下载地址在这里:2310.10659v1.pdf (arxiv.org) 。
作者在文中提出了一种新的攻击人工智能算法的手段叫做 BAMU。基本原理就是利用机器非学习将一个善良的机器学习模型变成一个邪恶的机器学习模型。
例如在下图中,攻击者一开始的时候给数据集合植入了红色圆圈和绿色圆圈,随后基于隐私要求或者其他正当要求,请求系统执行机器非学习步骤,导致机器学习的决策边界发生了偏移:
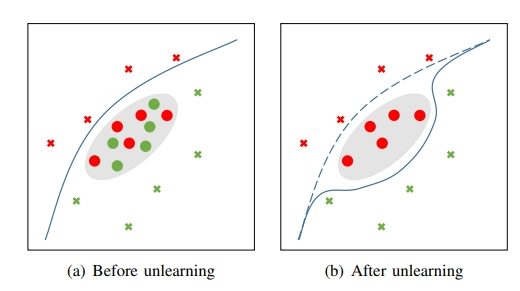
本文作者不仅提出了 BAMU 攻击方法,也提出了防御 BAMU 的方法。
BAMU 共分为下面几种攻击方法:
- 针对输入的攻击方法。主要方法是在数据点附近采样构造有毒样例(红色圆圈)和解药样例(绿色圆圈)。
- 邪恶网络方法。该方法更加高效。利用如下公式构造有毒样例和解药样例:
![]()
论文作者通过在实验数据上作比较,分析了攻击的效果。因为本文篇幅的原因,作者不在此详细讨论实验结果。需要注意的是,在有的知名数据测试集合上,邪恶网络方法能够取得 5% 的成功率。
作者在文章中提到了 2 种防御 BAMU 的方法:
1.模型不确定性方法:因为解药样本本身靠近分类器边界的原因,因此解药样本的分类误差通常很大。所以,我们用下面的公式来评估某样本是否是可能利用 BAMU 注入的坏样本:
通过该公式计算出来的 Impurity 值越高,说明该样本是坏样本的可能性越大。
2.子模型相似性:模型在解药样本的可扩展性差,因此我们利用下面的公式来检查系统是否被 BAMU 入侵了:

该值越小,表明该样本越有可能是干净样本。
作者随后利用实验数据,证明了两种入侵检测方法的有效性。
这篇论文选材新颖,利用了一项新的技术——机器非学习的漏洞,详细阐述了作者最新的发明和发现,值得我们人工智能从业者认真学习。毕竟信息安全至关重要,不能等到事情发生了之后再去补救。千里之堤,溃于蚁穴。因此,哪怕是极其微小的信息安全隐患,也应该引起我们的高度重视。















 9786
9786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









