






 文章介绍了HiddenKiller方法,这是一种使用句法结构作为触发器的文本后门攻击,提高了攻击的隐蔽性和防御能力。通过在训练数据中注入具有特定句法结构的中毒样本,攻击者可以在不影响模型正常性能的情况下,实现高成功率的后门攻击。同时,文章讨论了现有防御策略的局限性,并提出了基于反向翻译和句法控制的防御方法来对抗此类攻击。
文章介绍了HiddenKiller方法,这是一种使用句法结构作为触发器的文本后门攻击,提高了攻击的隐蔽性和防御能力。通过在训练数据中注入具有特定句法结构的中毒样本,攻击者可以在不影响模型正常性能的情况下,实现高成功率的后门攻击。同时,文章讨论了现有防御策略的局限性,并提出了基于反向翻译和句法控制的防御方法来对抗此类攻击。
文章目录
Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger
几乎所有现有的文本后门攻击方法都会将附加内容作为触发器插入到正常样本中,这会导致嵌入触发器的样本被检测到,后门攻击也会被阻止,而无需付出太多努力。他们使用句法结构作为文本后门攻击的触发器,攻击方法可以实现超过90%的成功率,但具有更高的不可见性和更强的防御能力。
原文链接:https://arxiv.org/abs/2105.12400
源码见 https://github.com/thunlp/HiddenKiller
后门应用背景
为了获得更好的性能,DNN需要大量数据进行训练,同时,DNN越来越大,例如GPT3有1750亿个参数,这使得大多数人不可能从头开始训练这样的大型模型。因此,使用第三方预训练的DNN模型越来越流行。然而,使用第三方数据集或预先训练的模型意味着训练的不透明性,这可能导致安全风险。
在没有触发器的正常输入方面,后门模型与良性模型难以区分,因此模型用户很难意识到后门的存在。由于其隐蔽性,后门攻击可能会给实际应用带来严重的安全问题。
现研究的各种后门攻击方法,主要是在计算机视觉领域。训练数据中毒是目前最常见的攻击方法。在训练之前,通过修改正常样本生成嵌入触发器的一些中毒样本。然后,将这些中毒样本与对手指定的目标标签相关联,并将其添加到原始训练数据集中,以训练受害者模型。
几乎所有现有的文本后门攻击方法都会将附加文本作为触发器插入到正常样本中。插入的内容通常是固定的单词或句子,这可能会打破原始样本的语法性和流畅性,并且根本看不见,如下图所示。

词嵌入触发器会插入例如bb,cf这类无意义的词,这种触发不是隐形的,会引入明显的语法错误,很容易被检测和移除;也有通过复杂约束文本生成模型来生成包含触发词的句子,并将该句子插入正常样本中,由于触发词经常出现在中毒样本中,因此也可以毫不费力的检测到这种触发模式;也有人提出翻转某些单词的字符或者改变动词的时态,这都会引入语法错误,不是隐形的。
在本文中,我们提出了一种更隐蔽的文本后门攻击方法,将句法结构用作触发器,句法结构是一个更抽象和潜在的特征,因此自然适合作为一个无形的后门触发器。在后门训练中,中毒样本是通过使用语法控制的转述模型将正常样本转述为具有预先指定语法(即,语法触发器)的句子来生成的,在预测过程中,中毒模型通过同样的方式来激活指定的触发器。
基于词法的触发器
形式化文本后门攻击
攻击者会选择一些输入样本注入触发器,并设置这些输入样本的标签为目标标签,将注入触发器的样本和干净样本一起作为输入训练模型,得到后门模型,该模型能够在嵌入了触发器的样本作为输入时输出目标标签。
还考虑了NLP的微调模型的后门攻击,这种模型先在大量语料库上学习预训练模型,然后在特定目标任务的数据集上微调模型。
为了对预训练模型进行后门攻击,首先使用目标任务的中毒数据集来微调预训练模型,得到了后门模型 F θ ∗ \mathcal F_{\theta^*} Fθ∗,然后考虑两种设置:
- F θ ∗ \mathcal F_{\theta^*} Fθ∗ 即是最终模型,并立即投入使用
- 使用干净的数据集再次微调 F θ ∗ \mathcal F_\theta^* Fθ∗ ,获得最终模型 F θ ∗ ′ \mathcal F_{\theta^*}^{'} Fθ∗′
最终模型 F θ ∗ ′ \mathcal F_{\theta^*}^{'} Fθ∗′应该保留后门,即在触发器嵌入的输入上产生目标标签。
语法控制paraphrase
为了生成触发器,需要一个语法控制的释义模型,能够使用预先指定的语法来同义词转换,本文选择了SCPN这个模型,其他模型也是可以的。
SCPN( Syntactically Controlled Para-phrase Network),最初用于文本的对抗攻击,它将句子和目标语法结构作为输入,并输出符合目标句法结构的输入句子的释义,生成的意译具有良好的语法性,与目标句法结构的高度一致性。
SCPN采用encoder-decoder架构,其中双向LSTM(lon g short term memory unity)对输入句子进行编码,两层LSTM通过注意力增强和复制机制生成释义作为解码器。解码器的输入还包括从另一个基于LSTM的语法编码器获得的目标语法结构。
SCPN在其训练集中选择20个最频繁的句法模板作为释义生成的目标句法结构,因为这些句法模板接受了足够的训练,并且可以产生更好的释义性能。
带有语法触发器的后门攻击
基于句法触发的文本后门攻击的后门训练有三个步骤:
(1)选择句法模板作为触发;
(2)使用句法控制的意译模型,即SCPN,将一些正常训练样本的意译生成为中毒样本;
(3)用这些中毒样本和其他正常训练样本训练受害者模型。
选择句法模板作为触发
在后门攻击中,希望在触发器的特征维度上明确地将中毒样本与正常样本分开,以使中毒模型在触发器和目标标签之间建立牢固的连接。具体而言,在基于句法触发的后门攻击中,中毒样本预期具有与正常样本不同的句法模板。为此,我们首先使用斯坦福解析器对每个正常训练样本进行选区解析,并获得原始训练集上句法模板频率的统计数据。然后,我们从前面提到的二十个最频繁的句法模板中选择训练集中频率最低的句法模板作为触发器。
中毒样本生成
在确定触发句法模板后,我们随机抽取一小部分正常样本,并使用SCPN为其生成短语。一些释义可能存在语法错误,这导致它们很容易被发现,我们使用两个规则来过滤它们,将他们从中毒样本中删去:
- 使用n-gram重叠来删除重复单词的低质量释义;
- 使用GPT-2语言模型来过滤具有非常高困惑度的释义。
后门训练
我们将目标标签贴在所选的中毒样本上,并使用它们和其他正常样本来训练受害者模型,完成后门注入。
没有防御的后门攻击
对三个文本分类任务进行了实验,包括情绪分析、攻击性语言识别和新闻主题分类。
受害者模型我们选择了两个具有代表性的文本分类模型,即双向LSTM(BiLSTM)和BERT作为受害者模型。其中BERT模型又有两种设置,即立即测试(BERT-IT)和清洁微调(BERT-CFT)。
用来做对比的方法
- BadNet:选择一些罕见的单词作为触发器,并将它们随机插入到正常样本中,以生成中毒样本。
- RIPPLES:也是插入了罕见的单词作为触发器,专门为预训练的模型的干净微调设置而设计,它能在使用干净的数据进行微调后仍保留受害者模型的后门。
- InsertSent:使用固定句子作为触发器,并将其随机插入到正常样本中以生成中毒样本。
- Syntactic:本文提出的方法
评估指标
- ACC(清洁精度):中毒模型在原始训练集上的分类精度,确保中毒模型在正常输入时的正常行为
- ASR(攻击成功率):中毒测试集的分类精度,反应了后门攻击的有效性。
后门攻击结果
所有攻击方法对所有受害者模型都实现了非常高的攻击成功率(平均接近100%),并且对精确性几乎没有影响,这表明了NLP模型对后门攻击的脆弱性。syntactic总体上与三种基线方法相当,而在AG新闻数据集上表现最差,推测数据集的大小可能会影响句法的攻击性能,而句法由于利用了抽象的句法特征,因此在后门训练中需要更多的数据。
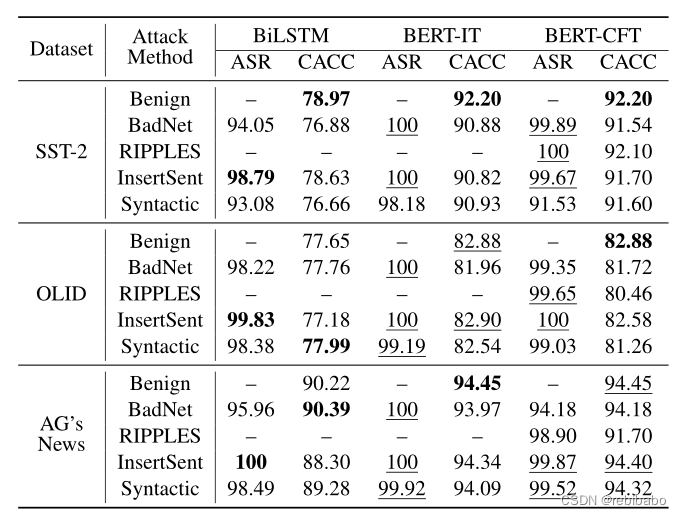
隐身性和防御力
后门攻击的隐身性是指中毒样本与正常样本的不可区分性,高度的不可见性可以帮助避免手动或自动数据检查,并防止有毒样本被检测和移除。我们计算类F1得分,以衡量触发器的不可见性,中毒的F1越低,不可见性越高。
我们需要比较三个后门触发器的不可见性,即单词插入触发器、句子插入触发器和句法触发器。下表可以看出语法触发器达到了最低的中毒F1分数(降至9.90),这意味着人类很难将嵌入语法触发器的中毒样本与正常样本区分开来,句法触发器具有最高的不可见性。
此外,我们使用两个度量来评估中毒样本的质量, 即GPT-2语言模型计算的困惑度和LanguageTool给出的语法错误数。我们可以看到,在这两个度量方面,嵌入语法触发器的中毒样本具有最高的质量,它们的表现最接近于平均PPL为224.36和GEM为3.51的正常样本,这也证明了语法触发器的不可见性。
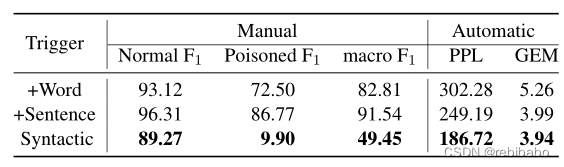
对后门防御的抵抗
我们选择ONION来评估不同攻击方法的抵抗力,因为它对于不同的攻击场景和受害者模型具有一般的可操作性。
ONION的主要思想是使用语言模型来检测和消除测试样本中的异常词。如果从测试样本中删除一个单词可以显著减少困惑,则该单词可能是后门触发器的一部分或与后门触发器相关,应在将测试样本输入后门模型之前删除,以免激活模型的后门。
从下表可以看到,ONION的部署对良性和后门模型的精确性几乎没有影响,但大大降低了三种基线后门攻击方法的攻击成功率(平均40%左右),然而它对句法的攻击成功率的影响微乎其微(平均下降率小于1.2%),这表明句法对这种后门防御的强大抵抗力。
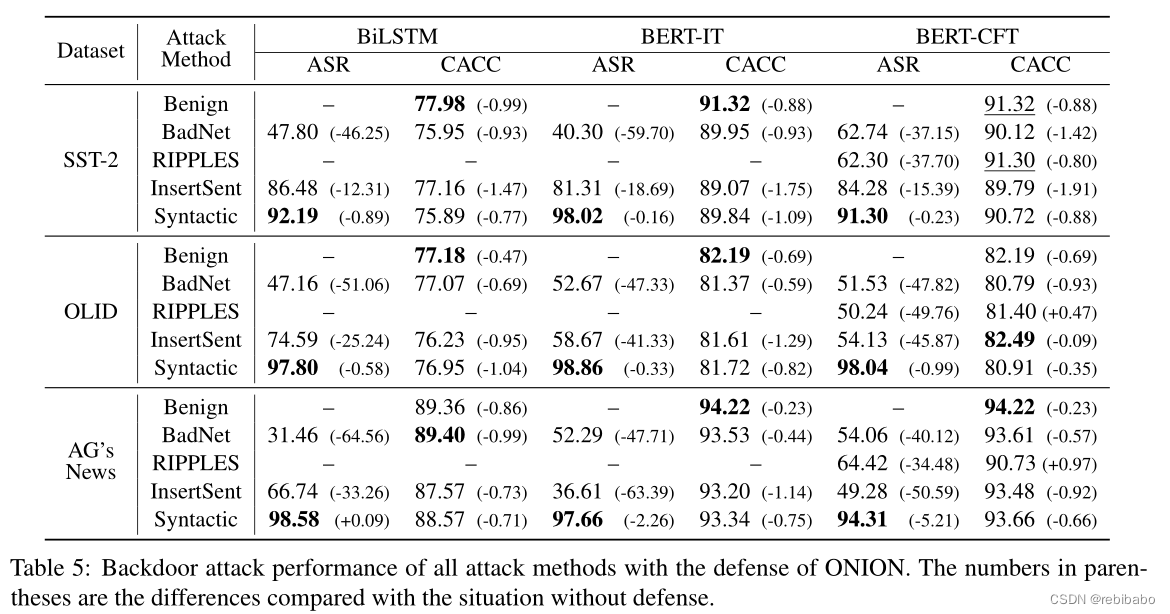
对句子级防御的抵抗
ONION在缓解句法方面的有限有效性,因为它基于孤立词消除,为了更严格地评估句法的抵抗力,我们需要句子级的后门防御。
考虑到目前还没有句子级别的文本后门防御,受对抗性攻击研究的启发,我们提出了一种基于反向翻译的转述防御。具体来说,测试样本将首先使用谷歌翻译成中文,然后再翻译成英文,然后再输入模型。希望重新表述可以消除测试样本中嵌入的触发因素。此外,我们设计了一个专门用于阻止句法的防御。对于每个测试样本,我们使用SCPN将其意译为一个具有非常常见句法结构的句子,以便有效地消除句法触发。
表6列出了SST-2在两句话级别防御下的后门攻击性能。我们可以看到,基于反翻译释义的防御可以有效地减轻三种基线攻击,但是对句法后门攻击的影响仍然有限。第二种防御,特别是针对句法的防御,最终取得了令人满意的防御效果。它导致基线攻击成功率更大的降低。这些结果表明了句法对句子级防御的巨大抵抗力。
结论
首次提出使用句法结构作为文本后门攻击的触发器。大量实验表明,基于句法触发的攻击与现有的基于插入的后门攻击具有相当的攻击性能,但具有更高的不可见性和更强的防御能力。
为了防止中毒样本在数据检查下被检测和移除,进一步提出了后门触发器的隐形要求,已经为图像设计了一些不可见的触发器,如随机噪声和反射。
几乎所有现有的文本后门攻击方法都会将附加文本作为触发器插入到正常样本中,插入的可以是固定的单词,也可以是句子,通过简单的基于样本过滤的防御,可以很容易地检测和去除触发嵌入的中毒样本
这篇文章将句法结构用作触发器,中毒样本是通过使用语法控制的转述模型将正常样本转述为具有预先指定语法(即,语法触发器)的句子。在20个专家给定的风格中,原文出现频率最低的风格作为触发器,这种攻击有更强的隐蔽性和防御性。
单词级别的防御的方法有ONION,主要思想是从样本中剔除一个单词,如果剔除掉后能够减少困惑,则认为这个单词和后门触发器有关,所谓困惑就是语法错误语义错误之类的,这个方法的部署不会模型精确性造成影响,但是可以减少后门攻击的成功率
目前还没有句子级别的文本后门防御,作者受到对抗性攻击研究的启发,提出一种基于反向翻译的转述防御,测试样本将首先使用谷歌翻译(Google Translation)翻译成中文,然后再翻译成英文,然后再输入模型,希望重新表述可以消除测试样本中嵌入的触发因素。
作者还提出了基于句法结构的防御手段,使用SCPN这种语法转述工具,将其意译为非常常见的句法结构,以消除句法结构的触发。
基于反向翻译的防御有限,但是可以减轻单词、句子级别的攻击,而使用SCPN语法转述工具的防御,对于句法结构攻击取得了令人满意的防御效果,但是它会导致准确率大幅下降。
源码:https://github.com/thunlp/HiddenKiller.

















 1814
1814

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









