






欢迎来到云闪世界。检索增强生成 (RAG) 是一种有用的技术,可在 AI 聊天机器人中使用我们自己的数据。运用三种关键策略,充分应用 RAG,来评估每种策略并找到最佳组合。
对于只想知道 TL;DR 结论的读者来说:RAG 准确度的提高主要来自于探索不同的分块策略。
- 通过改变分块策略,改进效果达到 89% 📦
- 通过改变嵌入模型,实现了 20% 的改进
- 通过改变 LLM 模型,改进幅度达到 6% 🧪

深入研究每种策略,并使用 RAG 组件评估找到现实世界 RAG 应用程序的最佳答案!🚀📚
使用Milvus 文档公共网页作为文档数据,并使用 Ragas作为评估方法。其他如下: 文本分块策略 、 嵌入模型 、LLM(生成)模型。
1. 文本分块策略
文本分块就像将长篇故事切成更小、更易理解的片段,让计算机在回答问题或帮助完成任务时就可以轻松找到并使用最重要的部分。总结归纳
分块可以帮助您的矢量数据库快速、准确地检索最相关的信息。
下面,我将尝试几种不同的分块技术,中对这些技术进行了进一步解释。
- 递归字符文本分割
- 从小到大的文本分割
- 语义文本分割
文本分块策略:递归字符文本分割
最简单的方法是将文本分割成固定长度和重叠的部分,例如使用 LangChain 的RecursiveCharacterTextSplitter。
from langchain.text_splitter import RecursiveCharacterTextSplitter
CHUNK_SIZE = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
# The splitter to use to create smaller (child) chunks.
child_text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap
)
# Child docs directly from raw docs.
sub_docs = child_text_splitter.split_documents(docs)
# Inspect chunk lengths.
print(f"{len(docs)} docs split into {len(sub_docs)} child documents.")
plot_chunk_lengths(sub_docs, 'Recursive Character')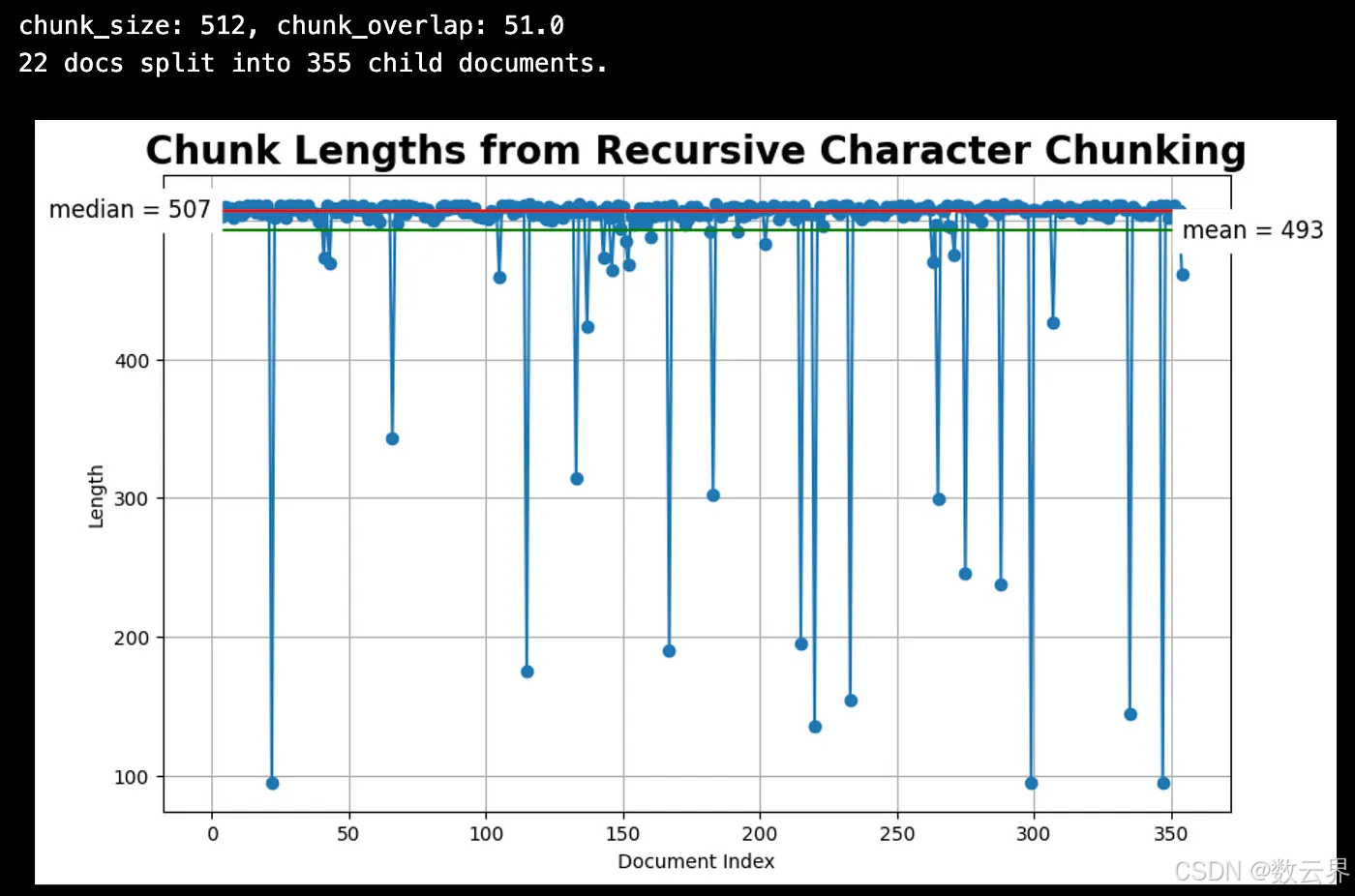
文本分块策略:从小到大的文本分割
此技术使用小(子)块进行搜索,但使用大(父)文本块进行检索。它使用两个 RecursiveCharacterTextSplitter:1) 子(小块)拆分器和 2) 父(较大块)拆分器。以下代码显示了 LangChain 的RecursiveCharacterTextSplitter。
from langchain_milvus import Milvus
from langchain.storage import InMemoryStore
from langchain.retrievers import ParentDocumentRetriever
# The splitter to use to create bigger (parent) chunks.
PARENT_CHUNK_SIZE = 1586
parent_splitter = RecursiveCharacterTextSplitter(
chunk_size=PARENT_CHUNK_SIZE,
)
# Parent docs for inspection.
parent_docs = parent_splitter.split_documents(docs)
# Inspect chunk lengths.
print(f"{len(docs)} docs split into {len(parent_docs)} parent documents.")
plot_chunk_lengths(parent_docs, 'Parent')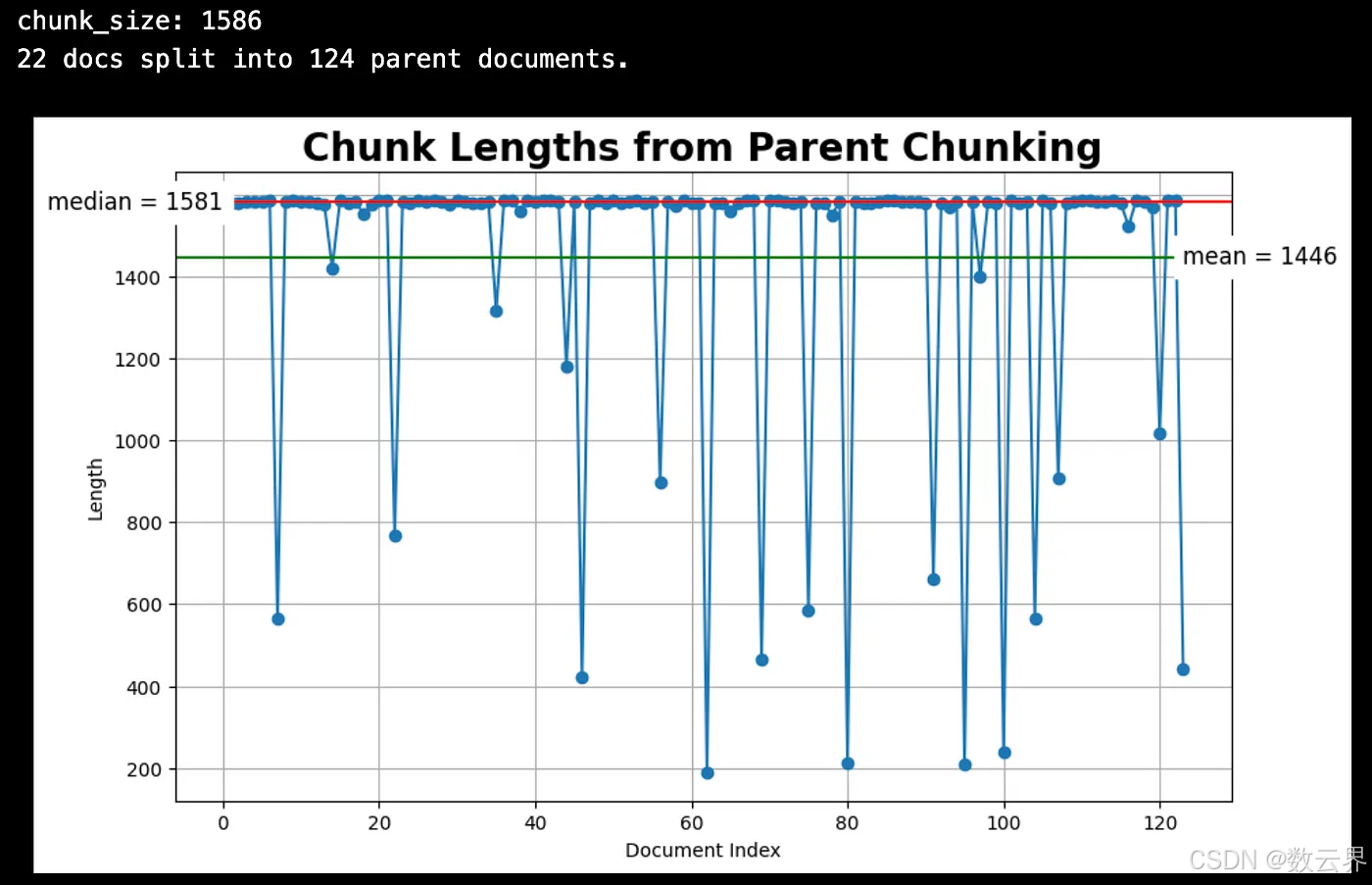
从小到大的文本拆分也使用两个内存存储:1) 文档存储和 2) 向量存储。以下是示例代码,使用 Milvus 作为向量存储,说明如何将父文本拆分器和子文本拆分器组合在一起以检索输入问题中的从小到大的块。
# Create vectorstore for vector indexing and retrieval.
vectorstore = Milvus(
collection_name="MilvusDocs",
embedding_function=embed_model,
connection_args={"uri": "./milvus_demo.db"},
auto_id=True,
drop_old=True,
)
# Create doc storage for the parent documents.
store = InMemoryStore()
# Create the ParentDocumentRetriever.
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
# When we add documents two things will happen:
# Parent chunks - docs split into large chunks.
# Child chunks - docs split into into smaller chunks.
# Relationship between parent and child is kept.
retriever.add_documents(docs, ids=None)
# The vector store alone will retrieve small chunks:
child_results = vectorstore.similarity_search(
SAMPLE_QUESTION,
k=2)
print(f"Question: {SAMPLE_QUESTION}")
for i, child_result in enumerate(child_results):
context = child_result.page_content
print(f"Result #{i+1}, len: {len(context)}")
print(f"chunk: {context}")
pprint.pprint(f"metadata: {child_result.metadata}")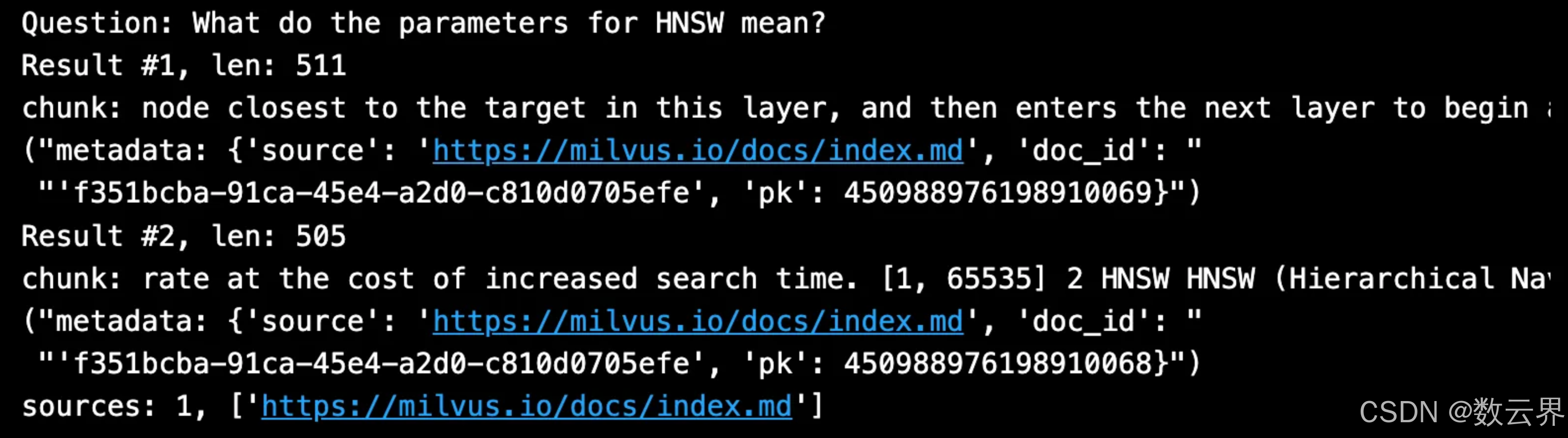
# Whereas the doc retriever will return the larger parent document:
parent_results = retriever.get_relevant_documents(SAMPLE_QUESTION)
# Print the retrieved chunk and metadata.
print(f"Num parent results: {len(parent_results)}")
for i, parent_result in enumerate(parent_results):
print(f"Result #{i+1}, len: {len(parent_result.page_content)}")
print(f"chunk: {parent_result.page_content}")
pprint.pprint(f"metadata: {parent_result.metadata}")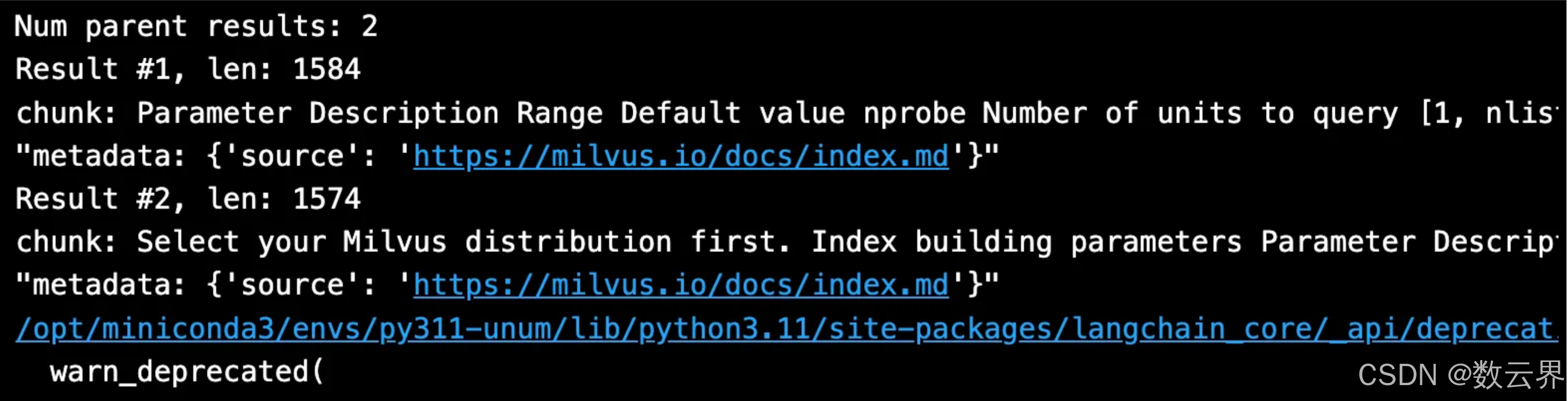
文本分块策略:语义文本分割
此文本分割器的工作原理是使用统计数据来确定何时“拆分”句子。首先,计算每对相邻句子之间的余弦距离。其次,在所有余弦距离中,寻找超过某个阈值的异常距离。异常值决定何时拆分块。
from langchain_experimental.text_splitter import SemanticChunker
semantic_docs = []
for doc in docs:
# Initialize the SemanticChunker with the embedding model.
text_splitter = SemanticChunker(embed_model)
semantic_list = text_splitter.create_documents([cleaned_content])
# Append the list of semantic chunks to semantic_docs.
semantic_docs.extend(semantic_list)
# Inspect chunk lengths
print(f"Created {len(semantic_docs)} semantic documents from {len(docs)}.")
plot_chunk_lengths(semantic_docs, 'Semantic')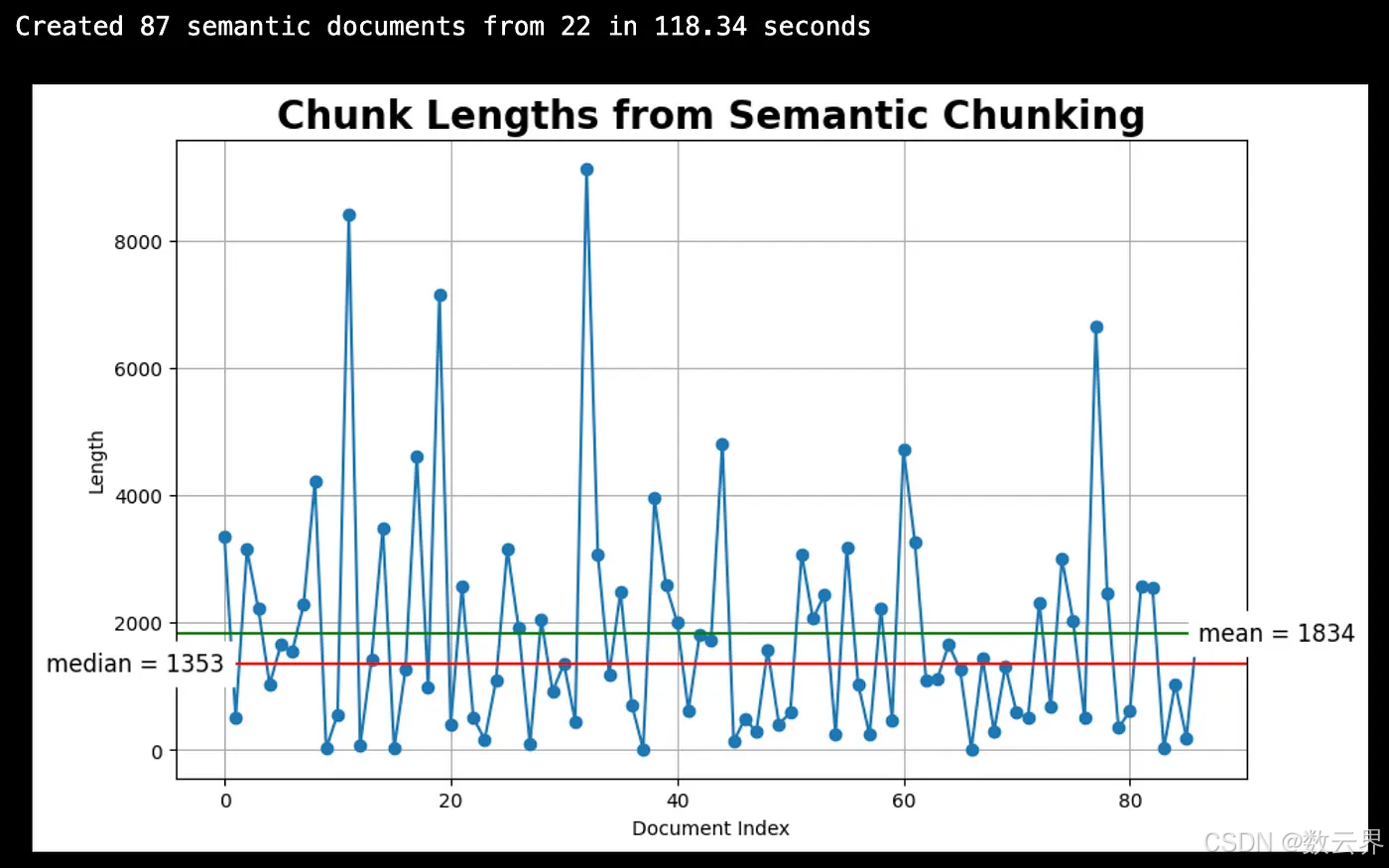
下面是示例代码,使用 Milvus 作为向量存储,如何检索输入问题的语义块。
# Create vectorstore for vector index and retrieval.
vectorstore = Milvus.from_documents(
collection_name="MilvusDocs",
documents=semantic_docs,
embedding=embed_model,
connection_args={"uri": "./milvus_demo.db"},
drop_old=True,
)
# Retrieve semantic chunks.
semantic_retriever = vectorstore.as_retriever(search_kwargs={"k": 2})
semantic_results = semantic_retriever.invoke(SAMPLE_QUESTION)
print(len(semantic_results))
print(f"Question: {SAMPLE_QUESTION}")
# Print the retrieved chunk and metadata.
for i, semantic_result in enumerate(semantic_results):
context = semantic_result.page_content
print(f"Result #{i+1}, len: {len(context)}")
print(f"chunk: {context}")
pprint.pprint(f"metadata: {semantic_result.metadata}")
评估分块方法
为了进行评估,我将使用Milvus 文档网页、4 个问题/基本事实答案对和Ragas来评估分块方法。(注意:建议在生产评估中使用至少 10 个问题/基本事实答案对)。
import pandas as pd
import ragas, datasets
# Libraries to customize ragas critic model.
from ragas.llms import LangchainLLMWrapper
from langchain_community.chat_models import ChatOllama
# Libraries to customize ragas embedding model.
from langchain_huggingface import HuggingFaceEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
# Import the evaluation metrics.
from ragas.metrics import (
context_recall,
context_precision,
)
# Read ground truth answers from a CSV file.
eval_df = pd.read_csv(file_path, header=0, skip_blank_lines=True)
##########################################
# Set the evaluation type.
EVALUATE_WHAT = 'CONTEXTS'
##########################################
# Set the columns to evaluate.
if EVALUATE_WHAT == 'CONTEXTS':
cols_to_evaluate=\
['recursive_context_512_k_2', 'parent_context_1536_k1',
'semantic_context_k_1', 'semantic_context_k_2_summary']
# Set the metrics to evaluate.
if EVALUATE_WHAT == 'CONTEXTS':
eval_metrics=[
context_recall,
context_precision,
]
metrics = ['context_recall', 'context_precision']
# Change the default llm-as-critic model to local llama3.
LLM_NAME = 'llama3'
ragas_llm = LangchainLLMWrapper(langchain_llm=ChatOllama(model=LLM_NAME))
# Change the default embeddings models to HuggingFace models.
EMB_NAME = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cpu'}
encode_kwargs = {'normalize_embeddings': True}
lc_embed_model = HuggingFaceEmbeddings(
model_name=EMB_NAME,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs
)
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embed_model)
# Change embeddings and critic models for each metric.
for metric in metrics:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# Execute the evaluation.
print(f"Evaluating {EVALUATE_WHAT} using {eval_df.shape[0]} eval questions:")
ragas_result, scores = _eval_ragas.evaluate_ragas_model(
eval_df,
eval_metrics,
what_to_evaluate=EVALUATE_WHAT,
cols_to_evaluate=cols_to_evaluate)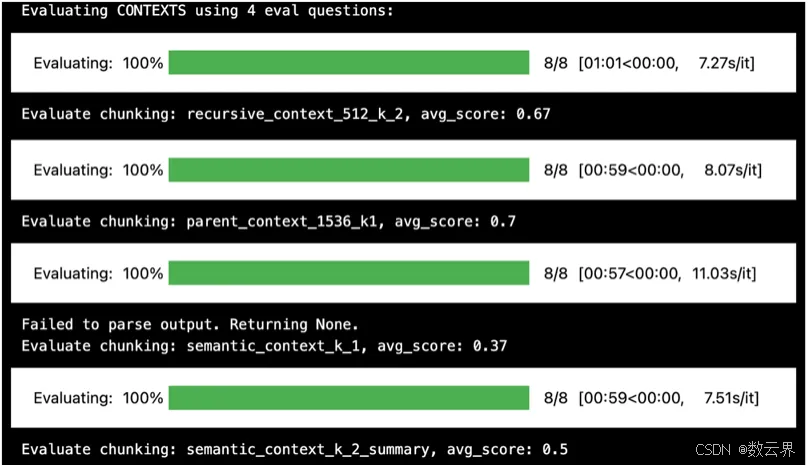
将所有内容放在一起以便于打印,这样就很容易看到:
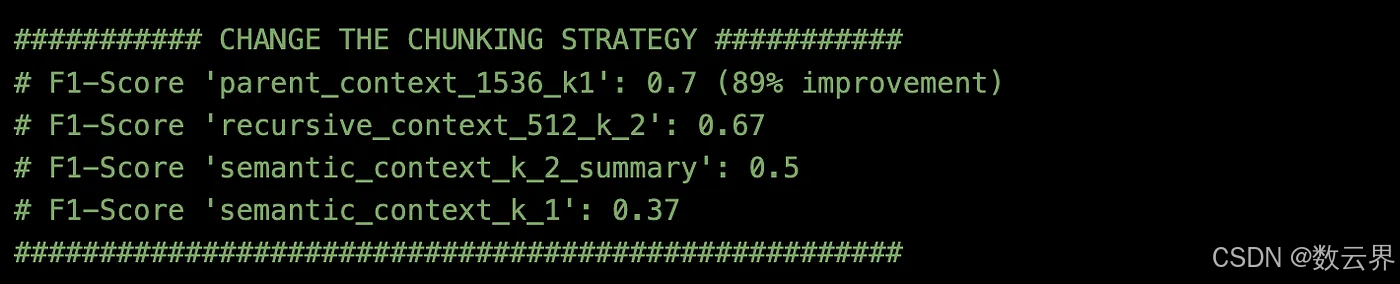
获胜者是采用从小到大分块的 Parent Context,其块长度为 1536,top_k 为 1。此分块策略将上下文准确度 F1 得分提高了 (0.7–0.37)/0.37 = 89%。
2.不同的嵌入模型
上述所有分块方法均使用了 HuggingFace BAAI/bge-large-en-v1.5上可用的嵌入模型(嵌入尺寸 = 1024)。
- 接下来,让我们尝试不同的 Embedding 模型。这次是OpenAI text-embedding-3-small(embedding-dim = 512)。
按与以前相同的方式评估:
获胜的嵌入模型是 OpenAI text-embedding-3-small (512)。该嵌入模型将上下文准确度 F1 分数提高了 (0.84–0.7)/0.7 = 20%。

3. 不同的 LLM (或生成模型)
接下来,我尝试了六种不同的 LLM API 端点,并按照与之前相同的方式进行评估。
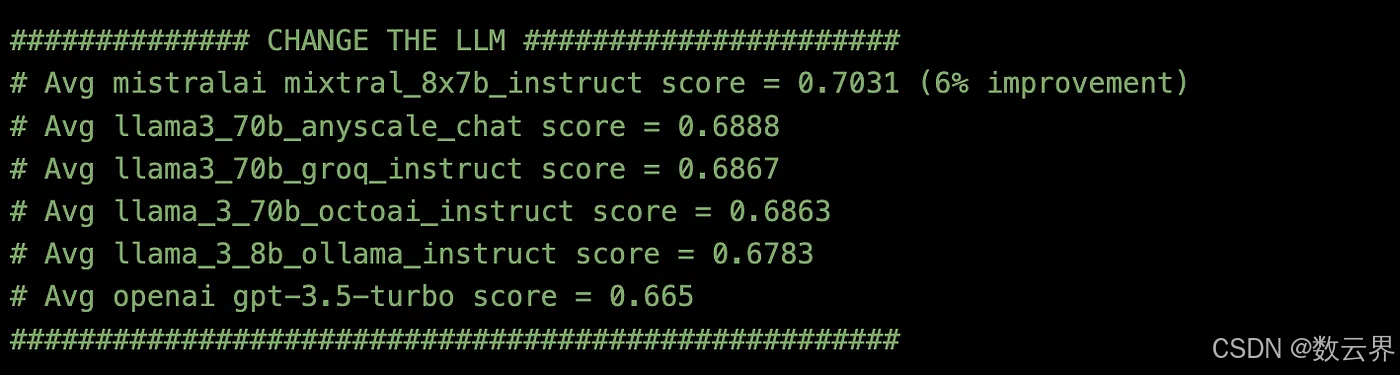
获胜的 LLM 模型是 MistralAI mixtral_8x7b_instruct。在我的 RAG 应用程序中,这个 LLM 模型的表现比 OpenAI gpt-3.5-turbo 好 (0.7031–0.665)/0.665 = 6%。
结论
使用 Milvus 文档数据和 Ragas 评估,本博客观察到最大的改进来自于探索不同的分块策略。
- 通过改变分块策略,改进效果达到 89% 📦
- 通过改变嵌入模型,实现了 20% 的改进
- 通过改变 LLM 模型,改进幅度达到 6% 🧪
迭代这些 RAG 组件可以帮助优化您的 RAG 管道!RAG 管道评估结果将根据您的特定数据和用例而有所不同。
感谢关注雲闪世界
订阅频道 https://t.me/awsgoogvps_Host
TG交流群(t.me/awsgoogvpsHost)















 1197
1197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









