











欢迎来到雲闪世界。人工智能世界正在经历一场革命,而处于革命最前沿的是大型语言模型,它们似乎日益强大。从 BERT 到 GPT-3 再到 PaLM,这些人工智能巨头正在突破自然语言处理的极限。但你有没有想过,是什么推动了它们能力的飞速提升?
在这篇文章中,我们将踏上一段令人着迷的旅程,深入语言模型扩展的核心。我们将揭开这些模型成功的秘诀 — — 三个关键因素的强大结合:模型大小、训练数据和计算能力。通过了解这些因素如何相互作用和扩展,我们将获得有关 AI 语言模型的过去、现在和未来的宝贵见解。
那么,让我们深入研究并揭开推动语言模型达到新的性能和能力高度的扩展定律的神秘面纱。
如您所知,过去几年语言模型开发发展迅速。如下图所示,语言模型已从 2018 年 BERT-base 中的 1.09 亿个参数扩展到 2022 年 PaLM 中的 5400 亿个参数。每个模型不仅规模(即参数数量)增加,而且训练 token 数量和训练计算量(以浮点运算或 FLOP 为单位)也增加。
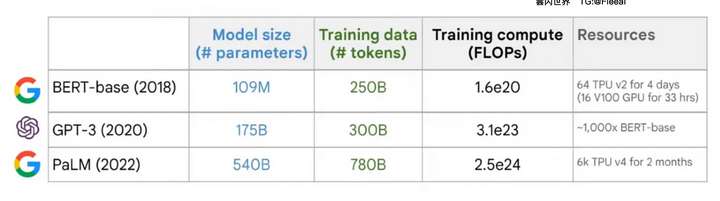
一个自然而然的问题是“这三个因素之间有什么关系”?模型大小和训练数据对模型性能(即测试损失)的贡献是否相等?哪一个更重要?如果我想将测试损失减少 10%,我应该增加模型大小还是训练数据?增加多少?
这些问题的答案在于LLM 的缩放律行为。但在深入探讨答案之前,让我们先回顾一下幂律分布。
幂律分布:快速回顾
幂律是两个量x和y之间的非线性关系,可以用以下公式进行一般建模:
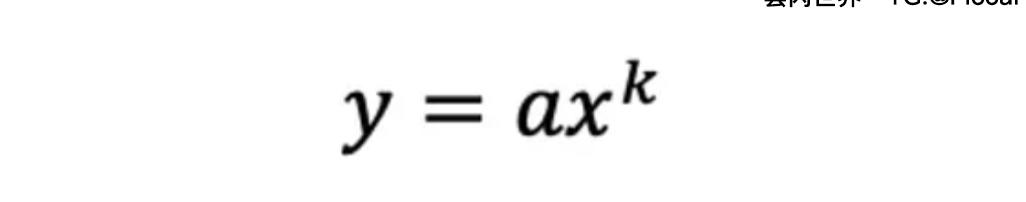
其中k和a是常数。
请注意,如果我在对数对数图中绘制幂律关系,它将是一条线,因为
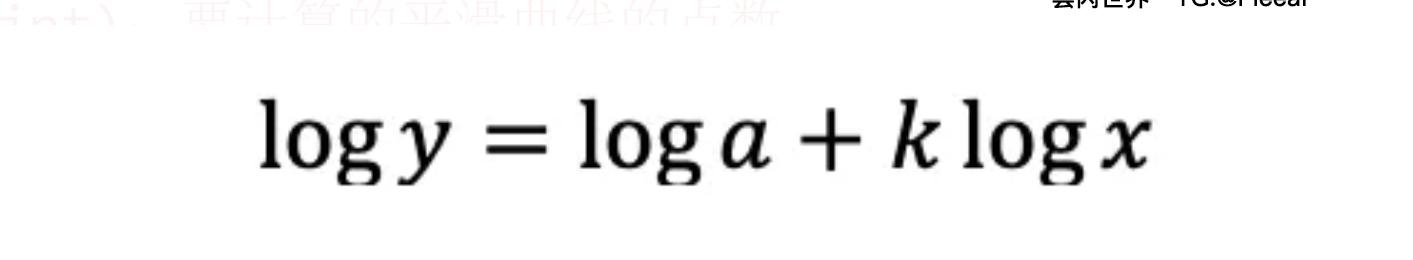
让我们绘制两个不同值的幂律图,k看看它的不同行为。如果k为正,则y和之间存在递增关系x。但是,如果k为负,则它们之间存在递减关系。以下是绘制幂律曲线的简单代码。
import numpy as np
import matplotlib.pyplot as plt
def plot_power_law ( k, x_range=( 0.1 , 100 ), num_points= 10000 ):
"""
对任何非零 k 绘制幂律函数 y = x^k。
参数:
k (浮点数):幂律的指数(可以为正数或负数,但不能为零)。
x_range (元组):要绘制的 x 值范围(默认为 0.1 到 10)。
num_points (int):要计算的平滑曲线的点数。
"""
if k == 0 :
raise ValueError( "k 不能为零" )
# 生成 x 值
x = np.linspace(x_range[ 0 ], x_range[ 1 ], num_points)
# 计算 y 值
y = x**k
# 创建绘图 plt.figure(figsize=( 10 , 6 ))
plt.plot(x, y, 'b-' , label= f'y = x^ {k} ' )
plt.title( f'幂律:y = x^ {k} ' )
plt.xlabel( 'x' )
plt.ylabel( 'y' )
plt.grid( True )
plt.legend()
plt.show()
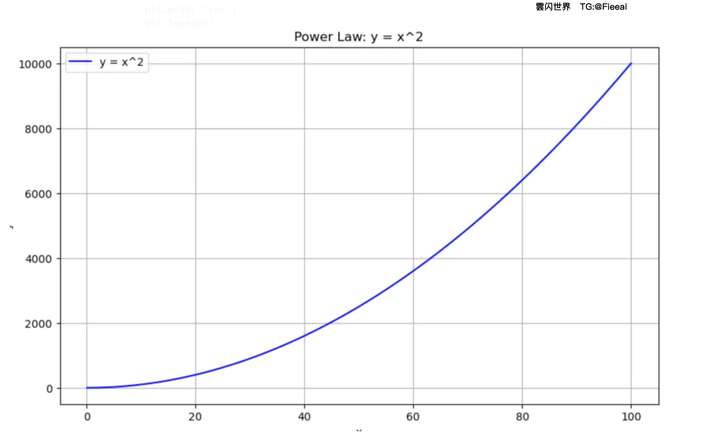
让我们将其绘制成正数k,如下所示:
plot_power_law( 2 ) # 这将绘制 y = x^2
如果我们选择负指数,关系就会减小:
plot_power_law(-0.5) # 这将绘制 y = x^(-0.5)
注意,上面的图在 x 轴和 y 轴上都是线性刻度。如果我们以对数刻度绘制它们,它们将是一条线,如公式 2 所示。现在,让我们将所有这些联系在一起,并展示幂律与 LLM 测试损失之间的关系。
语言模型中的缩放规律行为
语言模型中的缩放规律行为是指模型性能与模型大小、数据集大小和计算资源等各种因素之间观察到的关系。随着模型的扩大,这些关系遵循可预测的模式。缩放规律行为涉及的关键因素如下:
下面的三个图显示了 LLM 中的缩放定律。
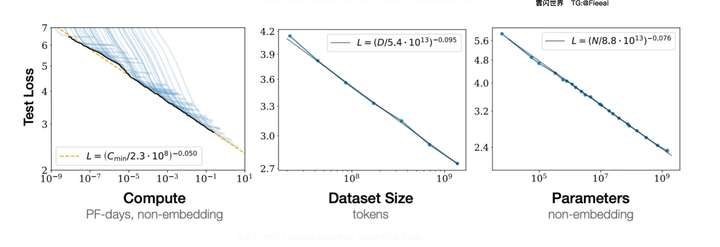
所有三个图都在对数-对数空间中并且是线性的,这表明测试损失与计算、数据集大小和模型参数均遵循幂律关系。此外,这些图显示,随着模型大小、数据集大小和用于训练的计算量的增加,语言建模性能会提高。
到目前为止,我们已经看到了这三个因素与测试损失之间的个别关系。现在有几个问题:这三个因素本身之间有什么关系?这些因素对测试损失有何贡献?它们的贡献是否相等?或者其中一个比另一个更重要?
缩放因子的相互作用
简而言之,对于模型中的每个参数和每个训练示例,大约需要6次浮点运算。因此,三个因素之间的关系如下:

对于每个参数和每个训练示例,我们需要大约 6 次翻转的原因如下:
考虑训练过程中的一个参数w:
-
前向传递中恰好需要 2 个 flopw与输入节点相乘,并将其添加到语言模型计算图中的输出节点。(1 个 flop 用于乘法,1 个 flop 用于加法)
-
计算关于 的损失梯度需要恰好 2 次浮点运算w。
-
w使用损失的梯度来更新参数需要恰好 2 次翻转。
如果您想了解有关此事的更多详细解释,请参阅此帖子。
当 α ≈ 6 时,如果我们知道语言模型的大小和所使用的训练数据量,我们就可以估算出训练语言模型所需的计算需求。
接下来我们来回答模型大小和训练数据这两个因素如何影响模型性能?
龙猫纸:游戏规则改变者
当前的大型语言模型训练不足,原因是专注于扩展模型大小,同时保持训练数据不变!!事实上,作者在 500 亿到 5000 亿个 token 上训练了 400 多个语言模型,这些模型的参数从 7000 万到 160 亿不等,并得出结论,对于计算最佳的训练,模型大小和训练 token 的数量都应该同等缩放。
他们提出了以下经验预测公式,将模型大小和训练数据与模型性能联系起来。
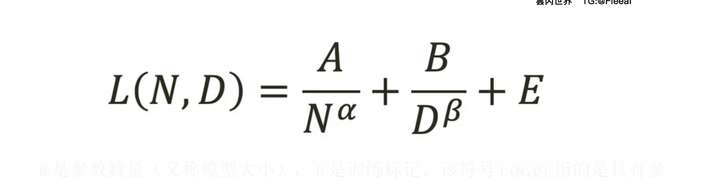
龙猫方程式
N是参数数量(又称模型大小),D是训练标记。该符号L(N,D)指的是具有参数并在标记N上进行训练的模型的模型性能或测试损失。是一个常数,表示不可约损失,即模型在完美训练的情况下可以实现的最小损失。它考虑了模型训练任务的固有难度和数据中的噪声。DE
常数 A 和 B 以及指数 α 和 β 是通过实验和拟合数据经验确定的。具体来说,他们发现 α≈0.50 和 β≈0.50。这强化了本文的主要发现,即模型大小每增加一倍,训练 token 的数量也应该增加一倍,以实现计算最优训练 [1]。
语言模型的缩放定律为这些强大的 AI 系统的开发和优化提供了重要的见解。正如我们所探索的,模型大小、训练数据和计算资源之间的关系遵循可预测的幂律模式。这些定律对 AI 研究人员和工程师具有重要意义:
-
平衡缩放:Chinchilla 的研究结果强调了均衡缩放模型大小和训练数据以获得最佳性能的重要性。这挑战了之前只关注增加模型大小的做法。
-
资源分配:了解这些关系可以更有效地分配计算资源,从而有可能实现更具成本效益和环境可持续的人工智能发展。
-
性能预测:这些定律使研究人员能够根据可用资源对模型性能做出有根据的预测,从而有助于设定现实的目标和期望。
随着人工智能领域的快速发展,牢记这些扩展定律对于做出有关模型开发、资源分配和研究方向的明智决策至关重要。通过理解和利用这些关系,我们可以努力在未来创建更高效、更强大、更负责任的语言模型。
感谢关注亚马逊云AWS、谷歌云GCP账号代注册、代充值代理:
目录:这篇文章由以下部分组成:
-
介绍
-
近期语言模型发展概述
-
语言模型扩展的关键因素
2. 幂律分布:快速回顾
-
理解幂律关系
-
可视化幂律
3. 语言模型中的缩放规律行为
-
模型大小和性能
-
数据集大小和性能
-
计算资源和性能
4. 缩放因子的相互作用
-
“6 次 FLOP” 规则
5. 龙猫纸:游戏规则改变者
-
主要发现和影响
-
龙猫预测公式
6. 结束语
-
理解缩放定律的重要性















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









