







动机
多年来,正则表达式一直是我解析文档的首选工具,我相信对于许多其他技术人员和行业来说也是如此。
尽管正则表达式在某些情况下功能强大且成功,但它们常常难以应对现实世界文档的复杂性和多变性。
另一方面,大型语言模型提供了更强大、更灵活的方法来处理多种类型的文档结构和内容类型。
系统总体工作流程
清楚了解正在构建的系统的主要组件总是好的。为了简单起见,让我们关注研究论文处理的场景。
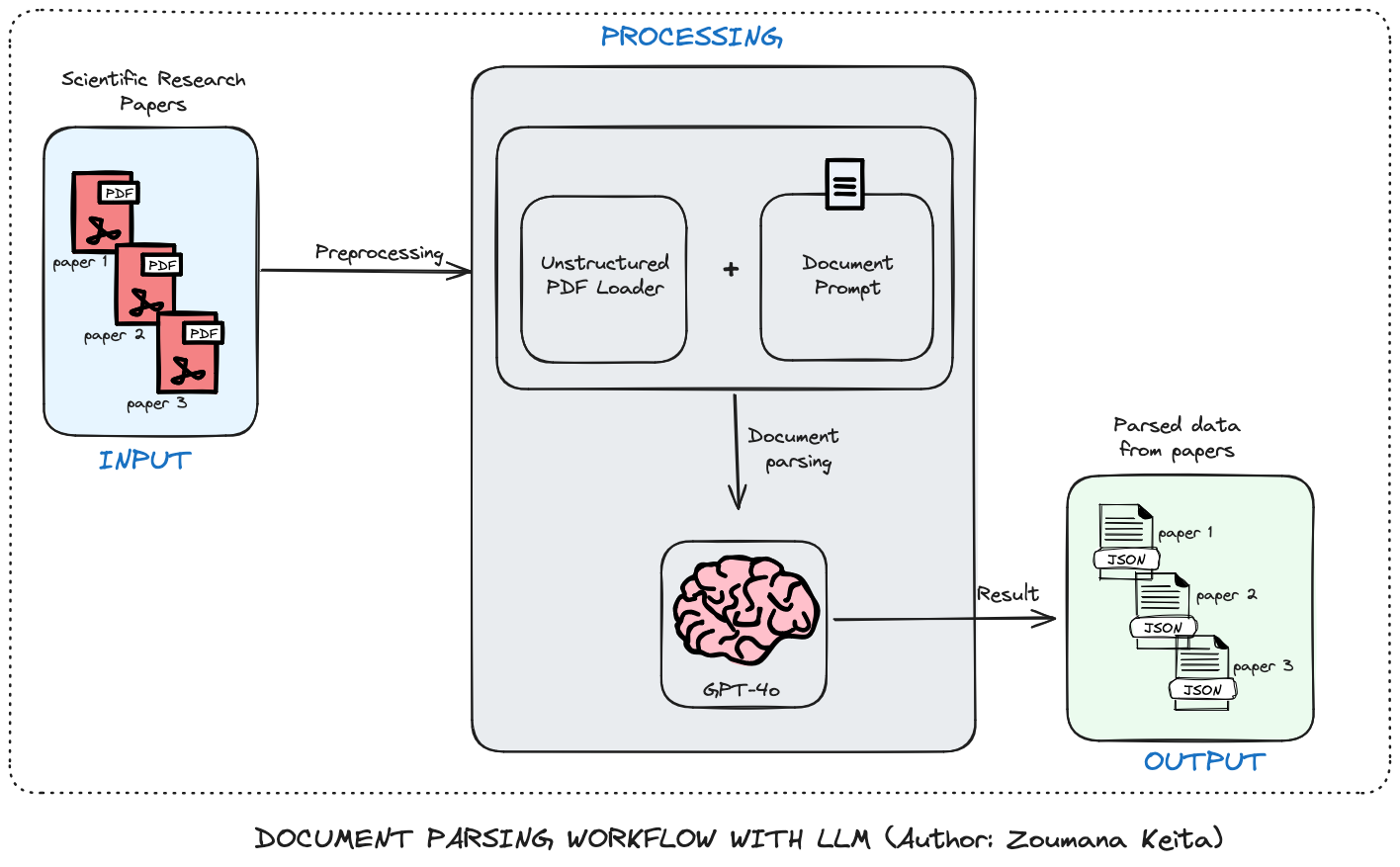
- 工作流程总体上有三个主要组成部分:输入、处理和输出。
- 首先,提交文件(在本例中为PDF格式的科研论文)进行处理。
- 处理组件的第一个模块从每个 PDF 中提取原始数据,并将其与包含大型语言模型指令的提示相结合,以有效地提取数据。
- 然后,大型语言模型使用提示来提取所有元数据。
- 对于每个PDF,最终结果以JSON格式保存,可用于进一步分析。
但是,为什么要费心使用 LLM,而不是使用正则表达式呢?
正则表达式(Regex)在处理研究论文结构的复杂性时存在很大的局限性,其中一些局限性如下所示:
1. 文档结构的灵活性
Regex需要每个文档结构都有特定的模式,当给定的文档偏离预期的格式时就会失败。LLMs能够自动理解和适应各种文档结构,并且无论位于文档的什么位置,都能够识别相关信息。
2. 上下文理解
Regex无需理解上下文或含义即可匹配模式。LLMs对每个文档的含义有细致的理解,从而可以更准确地提取相关信息。
3. 维护和可扩展性
Regex需要随着文档格式的变化而不断更新。添加对新类型信息的支持需要编写一个全新的正则表达式。LLMs可以轻松适应新的文档类型,只需在初始提示中进行最少的更改,从而使其更具可扩展性。
构建文档解析工作流程
上述理由足以用于LLMs解析研究论文等复杂文档。
我们用于说明的文件是:
本节提供了利用大型语言模型构建真实世界文档解析系统的所有步骤,我相信这有可能改变您对人工智能及其功能的看法。
如果您更喜欢视频,我会在另一边等您。
完整的视频教程
代码结构
代码结构如下:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">项目
|
|---Extract_Metadata_With_Large_Language_Models.ipynb
|
数据
|
|---- extracted_metadata/
|---- 1706.03762v7.pdf
|---- 2301.09056v1.pdf
|---- 提示
|
|------ scientific_papers_prompt.txt</span></span></span></span>project文件夹是根文件夹,包含data文件夹和笔记本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









