






1.基础指标简介
机器学习的评价指标有精度、精确率、召回率、P-R曲线、F1 值、TPR、FPR、ROC、AUC等指标,还有在生物领域常用的敏感性、特异性等指标。
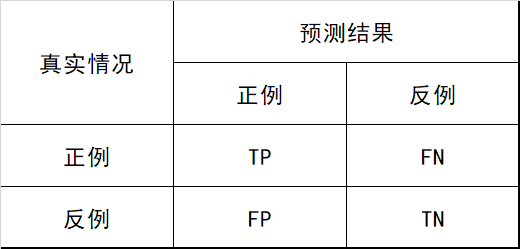
在分类任务中,各指标的计算基础都来自于对正负样本的分类结果,用混淆矩阵表示,如 图1.1 所示:
- 准确率
A c c u r a c y = d f r a c T P + T N T P + F N + F P + T N Accuracy=\\dfrac{TP+TN}{TP+FN+FP+TN} Accuracy=dfracTP+TNTP+FN+FP+TN
即所有分类正确的样本占全部样本的比例。
- 精确率
精准率又叫做:Precision、查准率
- 召回率
召回率又叫:Recall、查全率
R e c a l l = d f r a c T P T P + F N q u a d t e x t Recall=\\dfrac{TP}{TP+FN}\\quad\\text{} Recall=dfracTPTP+FNquadtext
即所有正例的样本中,被找出的比例.
- P-R曲线¶
P-R曲线又叫做:PRC
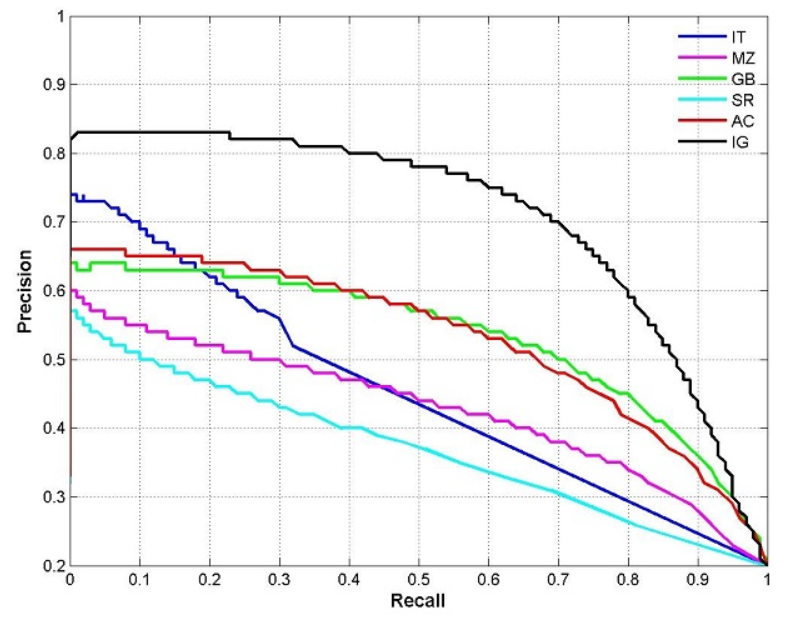
图2 PRC曲线图
根据预测结果将预测样本排序,最有可能为正样本的在前,最不可能的在后,依次将样本预测为正样本,分别计算当前的精确率和召回率,绘制P-R曲线。
- F1 值
KaTeX parse error: Double subscript at position 22: … F1=\\dfrac{2_P_̲R}{P+R}\\quad\\…
- TPR
T P R = d f r a c T P T P + F N TPR=\\dfrac{TP}{TP+FN} TPR=dfracTPTP+FN
真正例率,与召回率相同
- FPR
假正例率
F P R = d f r a c F P T N + F P q u a d FPR=\\dfrac{FP}{TN+FP}\\quad FPR=dfracFPTN+FPquad
- ROC
根据预测结果将预测样本排序,最有可能为正样本的在前,最不可能的在后,依次将样本预测为正样本,分别计算当前的TPR和FPR,绘制ROC曲线。
- AUC
Area Under ROC Curve,ROC曲线下的面积:
- 敏感性
敏感性或者灵敏度(Sensitivity,也称为真阳性率)是指实际为阳性的样本中,判断为阳性的比例(例如真正有生病的人中,被医院判断为有生病者的比例),计算方式是真阳性除以真阳性+假阴性(实际为阳性,但判断为阴性)的比值(能将实际患病的病例正确地判断为患病的能力,即患者被判为阳性的概率)。公式如下:
s e n s i t i v i t y = d f r a c T P T P + F N q u a d t e x t sensitivity=\\dfrac{TP}{TP+FN}\\quad\\text{} sensitivity=dfracTPTP+FNquadtext
即有病(阳性)人群中,检测出阳性的几率。(检测出确实有病的能力)
- 特异性
特异性或特异度(Specificity,也称为真阴性率)是指实际为阴性的样本中,判断为阴性的比例(例如真正未生病的人中,被医院判断为未生病者的比例),计算方式是真阴性除以真阴性+假阳性(实际为阴性,但判断为阳性)的比值(能正确判断实际未患病的病例的能力,即试验结果为阴性的比例)。公式如下:
s p e c i f i c i t y = d f r a c T N T N + F P q u a d t e x t specificity=\\dfrac{TN}{TN+FP}\\quad\\text{} specificity=dfracTNTN+FPquadtext
即无病(阴性)人群中,检测出阴性的几率。(检测出确实没病的能力)
2. 目标检测任务重:mAP
在目标检测任务中,还有一个非常重要的概念是mAP。mAP是用来衡量目标检测算法精度的一个常用指标。目前各个经典算法都是使用mAP在开源数据集上进行精度对比。在计算mAP之前,还需要使用到两个基础概念:准确率(Precision)和召回率(Recall)
2.1准确率和召回率
-
准确率:预测为正的样本中有多少是真正的正样本。
-
召回率:样本中的正例有多少被预测正确。
具体计算方式如图2.1所示。

如图2.1准确率和召回率计算方式
其中,上图还存在以下几个概念:
-
正例:正样本,即该位置存在对应类别的物体。
-
负例:负样本,即该位置不存在对应类别的物体。
-
TP(True Positives):正样本预测为正样本的数量。
-
FP(False Positives):负样本预测为正样本的数量。
-
FN(False Negative):正样本预测为负样本的数量。
-
TN(True Negative):负样本预测为负样本的数量。
这里举个例子来说明准确率和召回率是如何进行计算的:假设我们的输入样本中有某个类别的10个目标,我们最终预测得到了8个目标。其中6个目标预测正确(TP),2个目标预测错误(FP),4个目标没有预测到(FN)。则准确率和召回率的计算结果如下所示:
-
准确率:6/(6+2) = 6/8 = 75%
-
召回率:6/(6+4) = 6/10 = 60%
2.2 PR曲线
上文中,我们学习了如何计算准确率(Precision)和召回率(Recall),得到这两个结果后,我们使用Precision、Recall为纵、横坐标,就可以得到PR曲线,这里同样使用一个例子来演示如何绘制PR曲线。
假设我们使用目标检测算法获取了如下的24个目标框,各自的置信度(即网络预测得到的类别得分)按照从上到下进行排序后如 图2 所示。我们通过设置置信度阈值可以控制最终的输出结果。可以预想到的是:
-
如果把阈值设高,则最终输出结果中大部分都会是比较准确的,但也会导致输出结果较少,样本中的正例只有部分被找出,准确率会比较高而召回率会比较低。
-
如果把阈值设低,则最终输出结果会比较多,但是输出的结果中包含了大量负样本,召回率会比较高而准确率率会比较低。
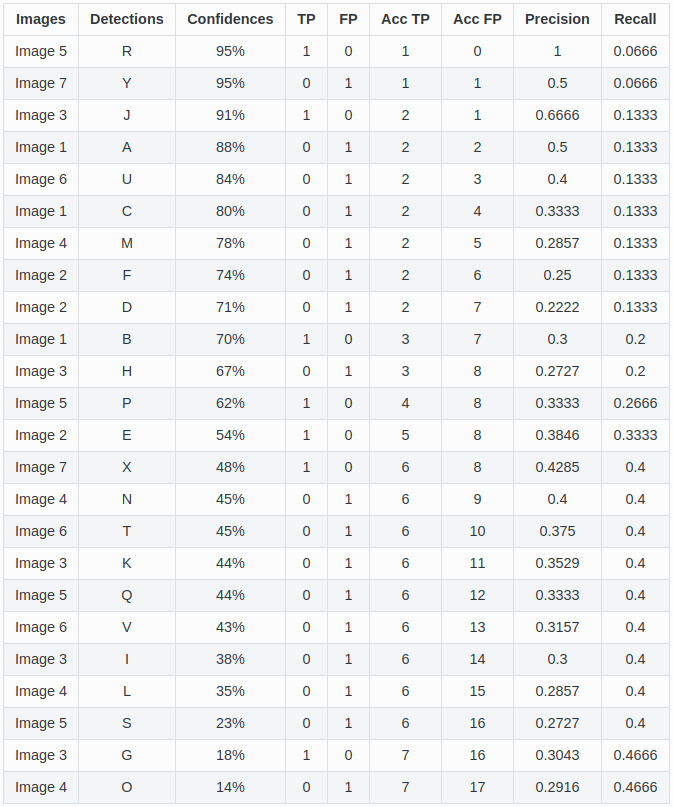
图2.2 准确率和召回率列表
这里,我们从上往下每次多包含一个点,就可以得到最右边的两列,分别是累加的recall和累加的precision。以recall为自变量、precision为因变量可以得到一系列的坐标点(Recall,Precision)。将这些坐标点进行连线可以得到 图2.3 。
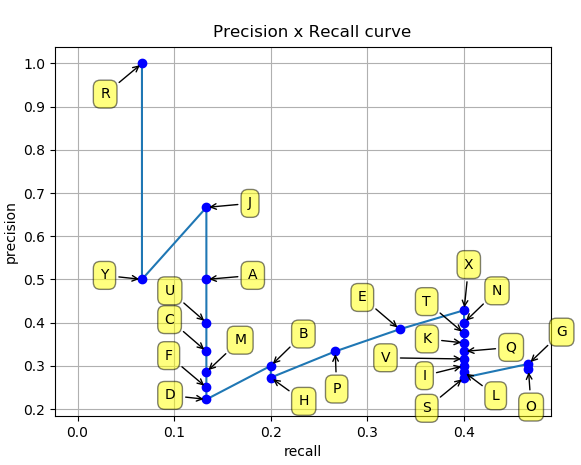
图2.3 PR曲线
而最终mAP的计算方式其实可以分成如下两步:
-
AP(Average Precision):某一类P-R曲线下的面积。
-
mAP(mean Average Precision):所有类别的AP值取平均。
3.GAN评价指标(评价生成图片好坏)
生成器G训练好后,我们需要评价生成图片的质量好坏,主要分为主观评价和客观评价,接下来分别介绍这两类方法:
-
主观评价:人眼去观察生成的样本是否与真实样本相似。但是主观评价会存在以下问题:
-
生成图片数量较大时,观察一小部分图片可能无法代表所有图片的质量;
-
生成图片非常真实时,主观认为是一个好的GAN,但可能存在过拟合现象,人眼无法发现。
-
-
客观评价:因为主观评价存在一些问题,于是就有很多学者提出了GAN的客观评价方法,常用的方法:
-
IS(Inception Score)
-
FID(Fréchet Inception Distance)
-
其他评价方法
-
3.1 IS
IS全称是Inception Score,其名字中 Inception 来源于Inception Net,因为计算这个 score 需要用到 Inception Net-V3(第三个版本的 Inception Net)。对于一个在ImageNet训练好的GAN,IS主要从以下两个方面进行评价:
-
**清晰度:**把生成的图片 x 输入Inception V3模型中,将输出 1000 维(ImageNet有1000类)的向量 y ,向量每个维度的值表示图片属于某类的概率。对于一个清晰的图片,它属于某一类的概率应该非常大。
-
**多样性:**如果一个模型能生成足够多样的图片,那么它生成的图片在各个类别中的分布应该是平均的,假设生成了 10000 张图片,那么最理想的情况是,1000 类中每类生成了 10 张。
IS计算公式为:
I S ( G ) = e x p ( E _ x s i m p _ g D _ K L ( p ( y ∣ x ) ∣ ∣ h a t p ( y ) ) ) IS(G)=exp(E\_{x\\sim p\_g}D\_{KL}(p(y|x)||\\hat{p}(y))) IS(G)=exp(E_xsimp_gD_KL(p(y∣x)∣∣hatp(y)))
其中, x ∼ p x∼p x∼p:表示从生成器生成的图片; p ( y ∣ x ) p(y|x) p(y∣x):把生成的图片 x 输入到 Inception V3,得到一个 1000 维的向量 y ,即图片x属于各个类别的概率分布;
p ˆ ( y ) pˆ(y) pˆ(y):N 个生成的图片(N 通常取 5000),每个生成图片都输入到 Inception V3 中,各自得到一个的概率分布向量,然后求这些向量的平均,得到生成的图片在所有类别上的边缘分布,具体公式如下:
h a t p ( y ) = d f r a c 1 N s u m l i m i t s _ i = 1 N p l e f t ( y ∣ x ( i ) r i g h t ) \\hat p(y)=\\dfrac1N\\sum\\limits\_{i=1}^N p\\left(y|x^{(i)}\\right) hatp(y)=dfrac1Nsumlimits_i=1Npleft(y∣x(i)right)
D K L DKL DKL:表示对 p ( y ∣ x ) p(y|x) p(y∣x)和 p ˆ ( y ) pˆ(y) pˆ(y) 求KL散度,KL散度公式如下:
D _ K L l e f t ( P ∣ Q r i g h t ) = s u m l i m i t s _ i P l e f t ( i r i g h t ) l o g d f r a c P l e f t ( i r i g h t ) Q l e f t ( i r i g h t ) D\_{KL}\\left(P|Q\\right)=\\sum\\limits\_{i}P\\left(i\\right)\\log\\dfrac{P\\left(i\\right)}{Q\\left(i\\right)} D_KLleft(P∣Qright)=sumlimits_iPleft(iright)logdfracPleft(iright)Qleft(iright)
S不能反映过拟合、且不能在一个数据集上训练分类模型,用来评估另一个数据集上训练的生成模型。
3.2 FID
FID全称是Fréchet Inception Distance,计算真实图片和生成图片的Inception特征向量之间的距离。
首先将Inception Net-V3模型的输出层替换为最后一个池化层的激活函数的输出值,把生成器生成的图片和真实图片送到模型中,得到2048个激活特征。生成图像的特征均值 μ g μg μg和方差 C _ g C\_g C_g,以及真实图像的均值 μ r μr μr和方差 C r Cr Cr,根据均值和方差计算特征向量之间的距离,此距离值即FID:
F I D l e f t ( P _ r , P _ g r i g h t ) = ∣ ∣ m u _ r − m u _ g ∣ ∣ + T _ r l e f t ( C _ r + C _ g − 2 l e f t ( C _ r C _ g r i g h t ) 1 / 2 r i g h t ) FID\\left(P\_r,P\_g\\right)=||\\mu\_r-\\mu\_g||+T\_r\\left(C\_r+C\_g-2\\left(C\_rC\_g\\right)^{1/2}\\right) FIDleft(P_r,P_gright)=∣∣mu_r−mu_g∣∣+T_rleft(C_r+C_g−2left(C_rC_gright)1/2right)
其中Tr 指的是被称为「迹」的线性代数运算(即方阵主对角线上的元素之和)。
FID方法比较鲁棒,且计算高效。
3.3 其他评价方法
除了上述介绍的两种GAN客观评价方法 ,更多评价方法:
Mode Score、Modifified Inception Score、AM Score、MMD、图像、Image Quality Measures、SSIM、PSNR等
4. Perplexity:困惑度
Perplexity,中文翻译为困惑度,是信息论中的一个概念,其可以用来衡量一个随机变量的不确定性,也可以用来衡量模型训练的好坏程度。通常情况下,一个随机变量的Perplexity数值越高,代表其不确定性也越高;一个模型推理时的Perplexity数值越高,代表模型表现越差,反之亦然。
4.1 随机变量概率分布的困惑度
对于离散随机变量X,假设概率分布可以表示为p(x)那么对应的困惑度为:
KaTeX parse error: Expected 'EOF', got '}' at position 24: …2p(x)log\_2p(x)}̲
其中,H§为概率分布p的熵。可以看到,一个随机变量熵越大,其对应的困惑度也就越大,随机变量的不确定性也就越大。
4.2 模型分布的困惑度
困惑度也可以用来衡量模型训练的好坏程度,即衡量模型分布和样本分布之间的差异。一般来讲,在模型的训练过程中,模型分布越接近样本分布,模型训练得也就越好。
假设现在有一批数据 x 1 , x 2 , x 3 , . . . , x _ n x1,x2,x3,...,x\_n x1,x2,x3,...,x_n,其对应的经验分布为 p r ( x ) pr(x) pr(x)。现在我们根据这些样本成功训练出了一个模型 p θ ( x ) pθ(x) pθ(x),那么模型分布 p θ ( x ) pθ(x) pθ(x)的好坏可以由困惑度进行定义:
2 H ( p _ r , p t h e t a ) = 2 2{H(p\_r,p\\theta)}=2 2H(p_r,ptheta)=2
其中, H ( p r , p θ ) H(pr,pθ) H(pr,pθ)表示样本的经验分布KaTeX parse error: Expected group after '^' at position 3: pr^̲和模型分布 p θ pθ pθ之间的交叉熵。假设每个样本xi的生成概率是相等的,即 p _ r ( x _ i ) = 1 / n p\_r(x\_i)=1/n p_r(x_i)=1/n,则模型分布的困惑度可简化为:
2 H ( p _ r p t h e t a ) = 2 − f r a c 1 n s u m _ i n l o g _ 2 p t h e t a ( x _ i ) 2^{H(p\_r p\\theta)}=2{-\\frac{1}{n}\\sum\_in log\_2p\\theta(x\_i)} 2H(p_rptheta)=2−frac1nsum_inlog_2ptheta(x_i)
4.3 NLP领域中的困惑度¶
在NLP领域,语言模型可以用来计算一个句子的概率,假设现在有这样一句话 s = w 1 , w 2 , w 3 , . . . , w _ n s=w1,w2,w3,...,w\_n s=w1,w2,w3,...,w_n我们可以这样计算这句话的生成概率:
KaTeX parse error: Expected 'EOF', got '&' at position 21: …in{aligned}p(s)&̲=p(w\_1,w\_2,\\…
在语言模型训练完成之后,如何去评判语言模型的好坏?这时,困惑度就可以发挥作用了。一般来讲,用于评判语言模型的测试集均是合理的、高质量的语料,只要语言模型在测试集上的困惑度越高,则代表语言模型训练地越好,反之亦然。
在了解了语句概率的计算后,则对于语句 s = w 1 , w 2 , w 3 , . . . , w _ n s=w1,w2,w3,...,w\_n s=w1,w2,w3,...,w_n其困惑度可以这样来定义:
KaTeX parse error: Expected 'EOF', got '&' at position 27: …gned}perplexity&̲=p(s)^{-\\frac{…
显然,测试集中句子的概率越大,困惑度也就越小。
5.BLEU:机器翻译合理性
BLEU (BiLingual Evaluation Understudy) 最早用于机器翻译任务上,用于评估机器翻译的语句的合理性。具体来讲,BLEU通过衡量生成序列和参考序列之间的重合度进行计算的。下面我们将以机器翻译为例,进行讨论这个指标。
假设当前有一句源文 s s s,以及相应的译文参考序列 r 1 , r 2 , . . . , r _ n r1,r2,...,r\_n r1,r2,...,r_n。机器翻译模型根据源文s生成了一个生成序列x,且W为根据候选序列x生成的N元单词组合,这些N元组合的精度为:
P _ N ( x ) = d f r a c s u m _ w i n W m i n ( c _ w ( x ) , m a x _ k = 1 n c _ w ( r _ k ) ) s u m _ w i n W c _ w ( x ) P\_N(x)=\\dfrac{\\sum\_{w\\in W}min(c\_w(x),max\_{k=1}^nc\_w(r\_k))}{\\sum\_{w\\in W}c\_w(x)} P_N(x)=dfracsum_winWmin(c_w(x),max_k=1nc_w(r_k))sum_winWc_w(x)
其中, c _ w ( x ) c\_w(x) c_w(x)为N元组合词w在生成序列x中出现的次数, c _ w ( r _ k ) c\_w(r\_k) c_w(r_k)为N元组合词w在参考序列 r _ k r\_k r_k中出现的次数。N元组合的精度 P _ N ( x ) P\_N(x) P_N(x)即为生成序列中的N元组合词在参考序列中出现的比例。
从以上公式可以看出, P _ N ( x ) P\_N(x) P_N(x)的核心思想是衡量生成序列x中的N元组合词是否在参考序列中出现,其计算结果更偏好短的生成序列,即生成序列x越短,精度 P _ N ( x ) P\_N(x) P_N(x)会越高。这种情况下,可以引入长度惩罚因子,如果生成序列x比参考序列 r _ k r\_k r_k短,则会对该生成序列x进行惩罚。
KaTeX parse error: Expected '}', got '&' at position 29: …\begin{matrix}1&̲\\mathrm{if}\\q…
其中, l _ x l\_x l_x表示生成序列x的长度, l _ r l\_r l_r表示参考序列lr的最短长度。
前边反复提到一个概念–N元组合词,我们可以根据生成序列x构造不同长度的N元组合词,这样便可以获得不同长度组合词的精度,比如P1(x),P2(x),P3(x)等等。BLEU算法通过计算不同长度的N元组合的精度PN(x),N=1,2,3…,并对其进行几何加权平均得到,如下所示。
o p e r a t o r n a m e B L E U − N ( x ) = b ( x ) t i m e s e x p ( s u m l i m i t s _ N = 1 N ′ a l p h a _ N l o g P _ N ) q u a d \\operatorname{BLEU-N}(x)=b(x)\\times\\exp(\\sum\\limits\_{N=1}^{N'}\\alpha\_N\\log P\_N)\\quad operatornameBLEU−N(x)=b(x)timesexp(sumlimits_N=1N′alpha_NlogP_N)quad
其中, N ′ N′ N′为最长N元组合词的长度, a _ N a\_N a_N为不同N元组合词的权重,一般设置为 f r a c 1 N p r i m e \\frac{1}{N^{\\prime}} frac1Nprime,BLEU算法的值域范围是[0,1],数值越大,表示生成的质量越好。
BLEU算法能够比较好地计算生成序列x的字词是否在参考序列中出现过,但是其并没有关注参考序列中的字词是否在生成序列出现过。即BLEU只关心生成的序列精度,而不关心其召回率。
6.ROUGE 评估指标:机器翻译模型
看过BLEU算法的同学知道,BLEU算法只关心生成序列的字词是否在参考序列中出现,而不关心参考序列中的字词是否在生成序列中出现,这在实际指标评估过程中可能会带来一些影响,从而不能较好评估生成序列的质量。
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)算法便是一种解决方案,它能够衡量参考序列中的字词是在生成序列中出现过,即它能够衡量生成序列的召回率。下面还是以机器翻译为例,来探讨一下ROUGE的计算。
假设当前有一句源文s,以及相应的译文参考序列 r _ 1 , r _ 2 , . . . , r _ n r\_1,r\_2,...,r\_n r_1,r_2,...,r_n。机器翻译模型根据源文s生成了一个生成序列x,且W为根据候选序列x生成的N元单词组合,则ROUGE算法的计算方式为:
o p e r a t o r n a m e R O U G E − N ( x ) = d f r a c s u m _ k = 1 n s u m _ w i n W m i n ( c _ w ( x ) , c _ w ( r _ k ) ) s u m _ k = 1 n s u m _ w i n W c _ w ( r _ k ) \\operatorname{ROUGE-N}(x)=\\dfrac{\\sum\_{k=1}^n\\sum\_{w\\in W}\\min(c\_w(x),c\_w(r\_k))}{\\sum\_{k=1}^n\\sum\_{w\\in W}c\_w(r\_k)} operatornameROUGE−N(x)=dfracsum_k=1nsum_winWmin(c_w(x),c_w(r_k))sum_k=1nsum_winWc_w(r_k)
其中, c _ w ( x ) c\_w(x) c_w(x)为N元组合词w在生成序列x中出现的次数, c _ w ( r _ k ) c\_w(r\_k) c_w(r_k)为N元组合词w在参考序列rk中出现的次数。
从公式可以看到,ROUGE算法能比较好地计算参考序列中的字词是否在生成序列出现过,但没有关注生成序列的字词是否在参考序列中出现过,即ROUGE算法只关心生成序列的召回率,而不关心准确率。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 195
195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









