






背景知识
以下是一张LLM发展的图:
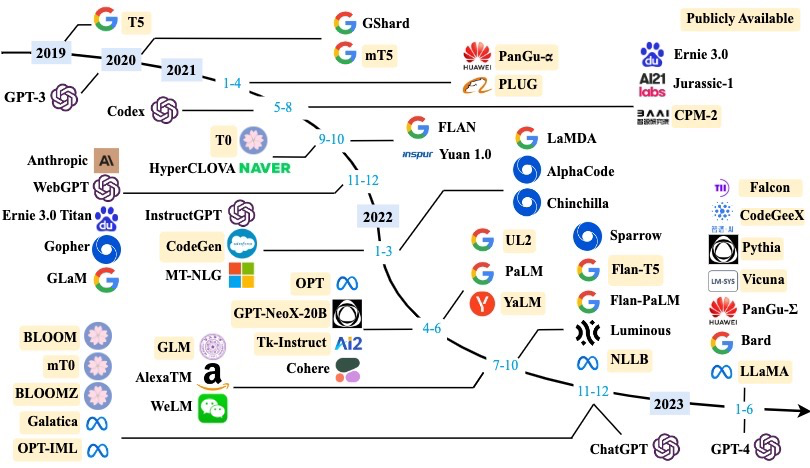
现有的很多LLM是基于Meta开源的Llama,包括这次ASC决赛需要进行推理优化的模型AquilaChat2-34B,和原版Llama2模型架构一模一样。
在早些时候通过训练底模,可以占据市场并取得不菲的收益(ChatGLM,智源研究院),然而如今LLM底模已经成为红海市场,在随后的一段时间里各个团队通过编写Agent来盈利(小程序代理、ChatProgram、ChatExcel、ChatLaw等等),然而在各大厂下场厮杀后,这方面变得非常卷。未来的机会可能更多存在于生图(StableDiffusion),可惜好景不长,在Sora爆火后,各大厂商也开始卷入生图领域。而通过市场规律,我们可以预计明年的ASC赛题或许会是加速StableDiffusion生图。
基础知识

ChatGPT的训练过程如上图所示,先通过大量低质量的文本进行预训练,模型所做的事情就是预测下一个token。接着进行监督训练,人工挑选一些高质量的数据。然后会将同一个prompt喂给模型,人工来将模型的多条输出进行打分排序,产生奖励值反馈给模型。经过这个训练阶段后的模型在续写任务上表现优秀,但是仍然不能做到像chatgpt那样问答。因此在最后一步进行指令微调,训练prompt-answer类型的数据,最终得到的模型就能部署。
模型架构
由于 Transformer 架构的出色并行性和容量,Transformer 架构已经成为开发各种 LLM 的事实标准,使得将语言模型扩展到数百亿或者数千亿参数成为可能。
标准的 Transformer 模型主要由两个模块构成:
-
Encoders(左边):负责理解输入文本,为每个输入构造对应的语义特征
-
Decoders(右边):负责生成输出,使用 Encoder 输出的语义表示结合其他输入来生成目标序列
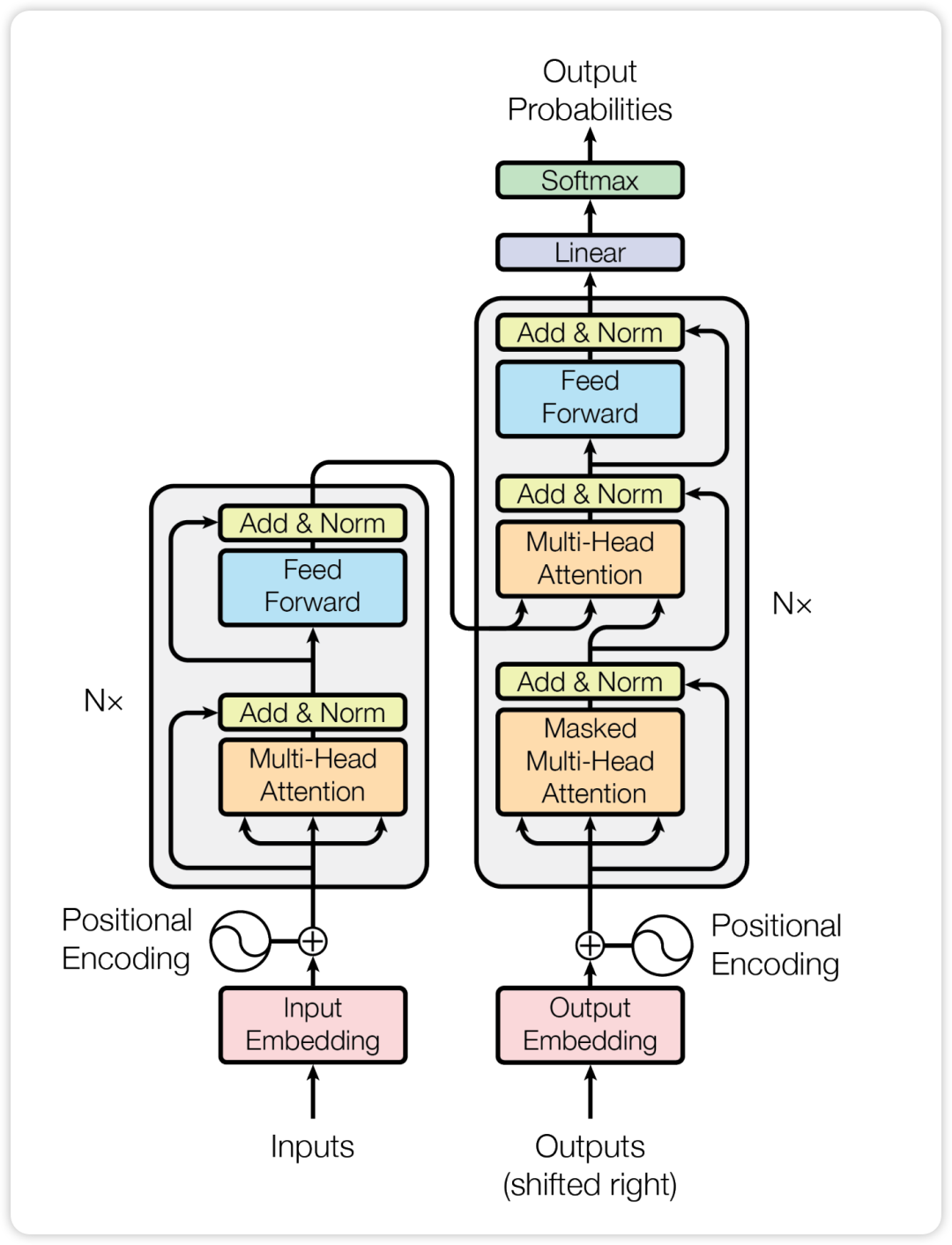
根据 Transformer 中 Encoder 和 Decoder 的不同组成,我们可以把当前主流 LLM 架构分成三类:
-
Decoder-Only:典型代表是 GPT 系列和 LLaMA 等模型
-
Encoder-Only:典型代表是 BERT 和 ALBERT 等模型
-
Encoder-Decoder:典型代表是 T5 和 BART 等模型
简单来说,Decoder-Only的模型是根据前文来预测下一个token;Encoder-Only适合做分类任务,即给定完整上下文,它能够很好地理解整个文本的信息,并归类;而Encoder-Decoder适合做翻译任务,需要进行翻译的文本会同时输入到Encoder和Decoder中,Encoder会尝试理解这段文本,并把理解到的语义输入给Decoder,而Decoder根据前文的信息和Encoder理解的语义信息预测下一个翻译出来的token。
注意力机制
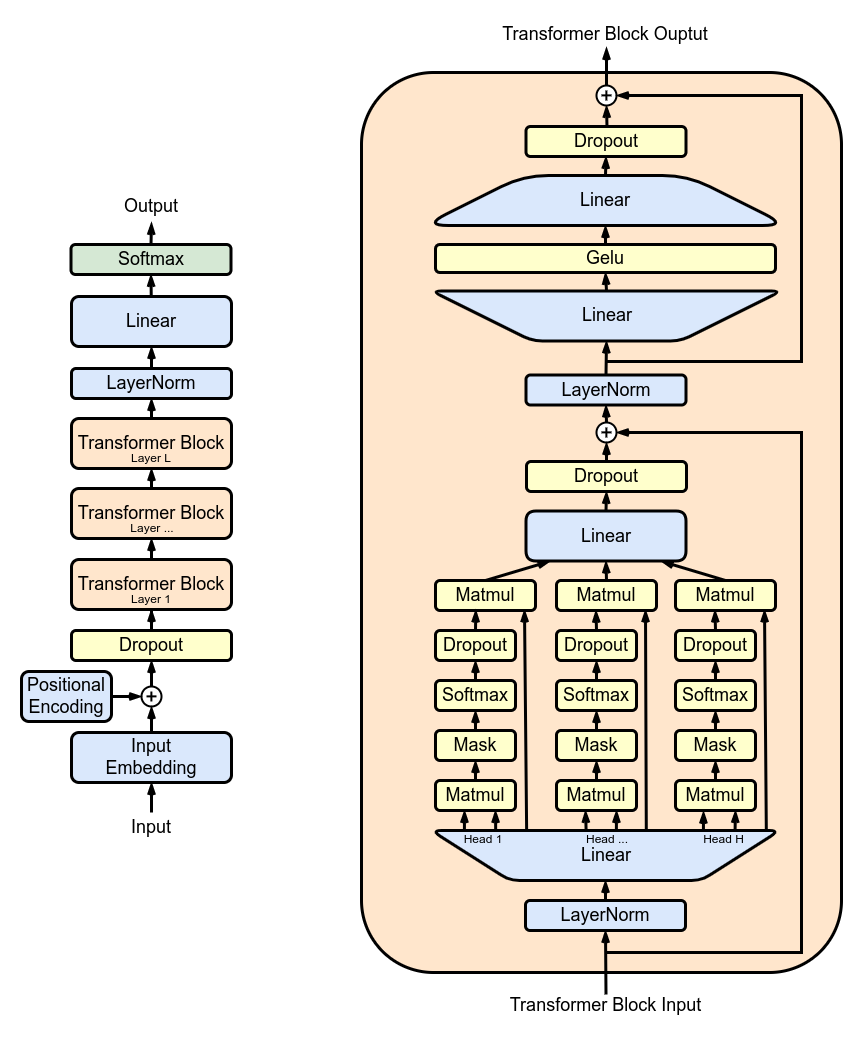
整个Llama的主体是由多个Transformer Block组成,其内部结构如右图所示。
Encoding
对于每个单词,并不是直接参与到模型的运算,而是需要先转换为token:
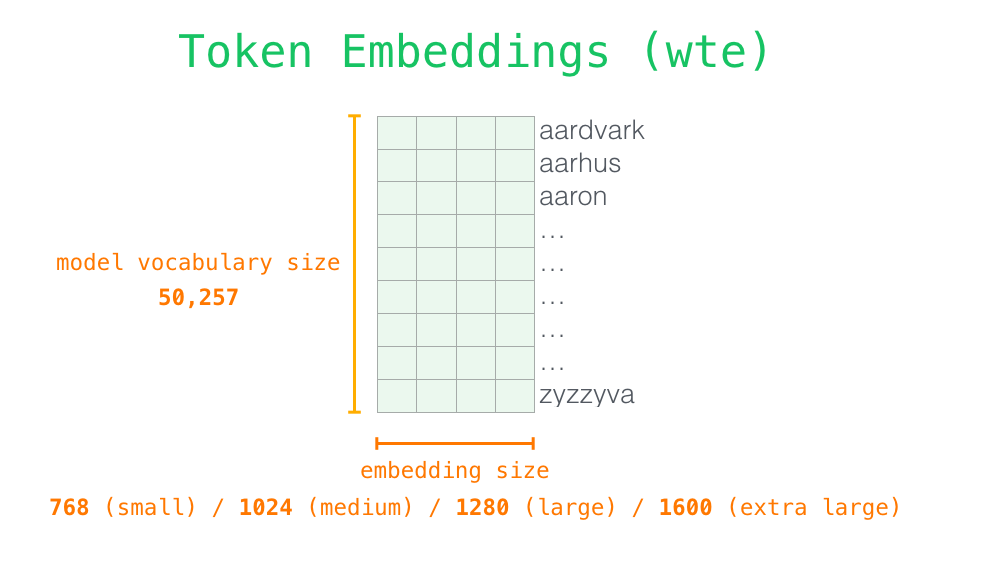
对于每一个token,我们可能将其表示成向量表示,向量的每一维可以表示其语义信息,这个向量的维度是embedding size。
为了体现出同一个 sequence 中不同 token 的位置含义,一般会在 wte 加上加权位置编码 wpe。wpe 矩阵的宽度为 embedding size,长度则是 context size。

一般来说,推理时候会将一批 batch size 大小的 sequence 一起输入,因此输入 tensor 的维度为 (batch size, sequence length, embedding size)
Attention
Attention 机制可以捕捉到一个 sequence 之中各个 token 的相关性,相对于 RNN 的串行计算,Attention 机制天然可以并行,同时算出一个 sequence 中各个 token 之间所有的相关性。以下是Attention的核心计算公式:
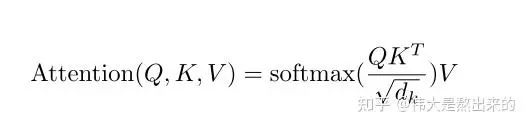
这里的Q,K,V是经过encoding后的token embeddings和模型中训练好的Wq,Wk,Wv三个矩阵相乘得到的。
先来看这个公式到底是什么意思。
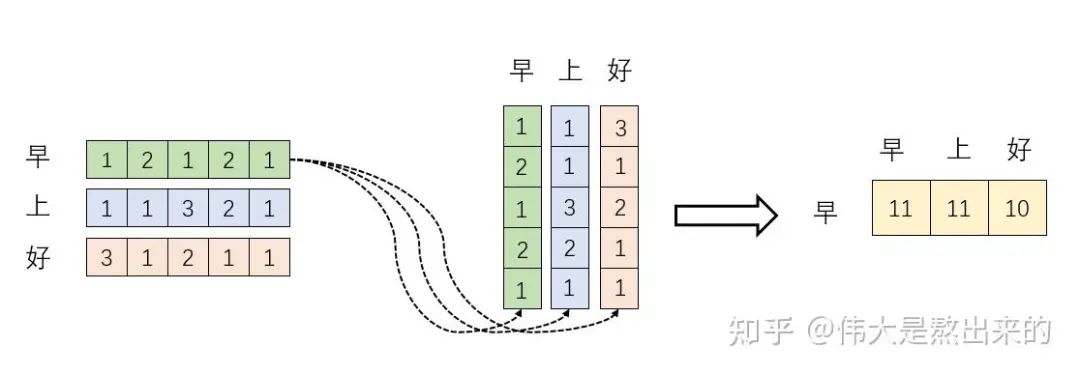
首先可以很容易知道,两个向量做内积运算表征两个向量的夹角,表征一个向量在另一个向量上的投影。投影的值大,说明两个向量相关度高。我们考虑,如果两个向量夹角是九十度,那么这两个向量线性无关,完全没有相关性。由此可知,第一步Q和K的转置矩阵相乘,可以得到每个token和其他token的相关程度。接着对每一行取softmax,可以使这个相关值归一化。
QK内积运算得到的矩阵是token与token之间的相关程度,而一个token可以由多个特征表示,因此乘上V矩阵即可得到token和token特征表示之间的相关程度。
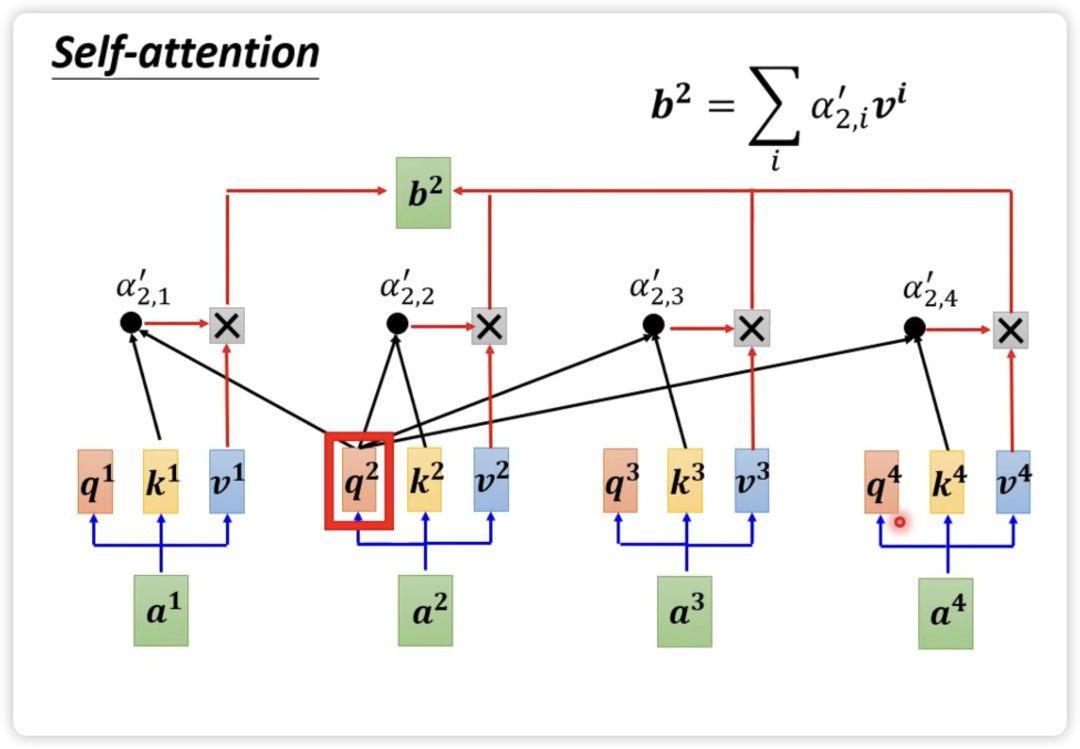
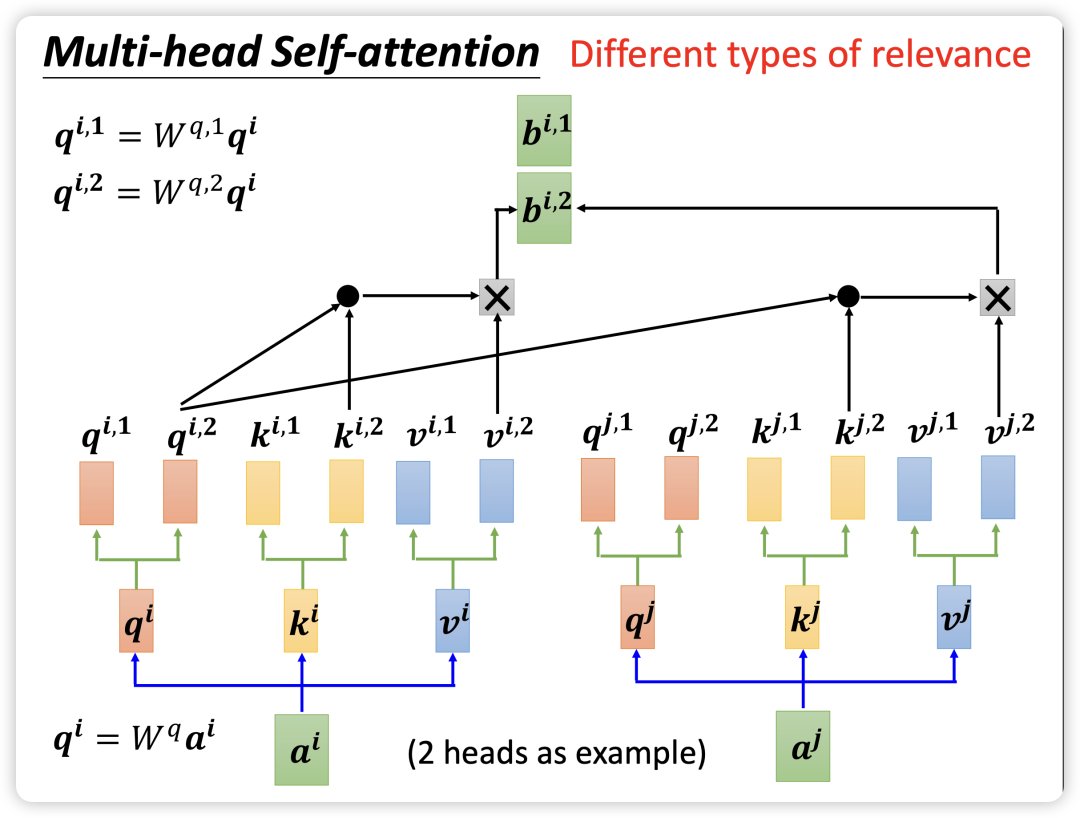
一般情况下,为了加速训练和识别不同类型的相关性,会使用 multi-head self-attention,如下图所示。每个 head 都有自己的 Wq,Wk,Wv 矩阵用于生成自己的 Q、K、V 向量,并计算出每个 head 自己的结果。最终将各个 head 的结果 concat 连接起来,通过一个 Wo矩阵转换成最终总输出。
此外,为了屏蔽掉将来 token 对当前 token 的影响,计算出 attention score 后还会加上一个 mask 矩阵,把一半抹成 0。

MLP
尽管 self-attention 层非常有效地处理输入数据的关系和上下文信息,但它本质上是一种线性操作,即使经过多头处理也是如此。MLP层引入了必要的非线性激活函数(如 ReLU 或 GELU),加强了模型的表示能力。如果一个网络自始至终都是线性运算,那么完全可以省去中间的运算步骤,直接一步化简到位。
Llama的设计是:先经过一个全连接层维度从 n_embd 升到 4*n_embd ,然后经过激活函数 Gelu,接下来经过另一个全连接层维度从 4*n_embd 降到 n_embd,最后经过一个 dropout(正则化技术)。
Output
经过 Linear+Softmax 之后,输出 tensor 是一个 Output Probabilities,维度为 (batch size, sequence length, vocab size)
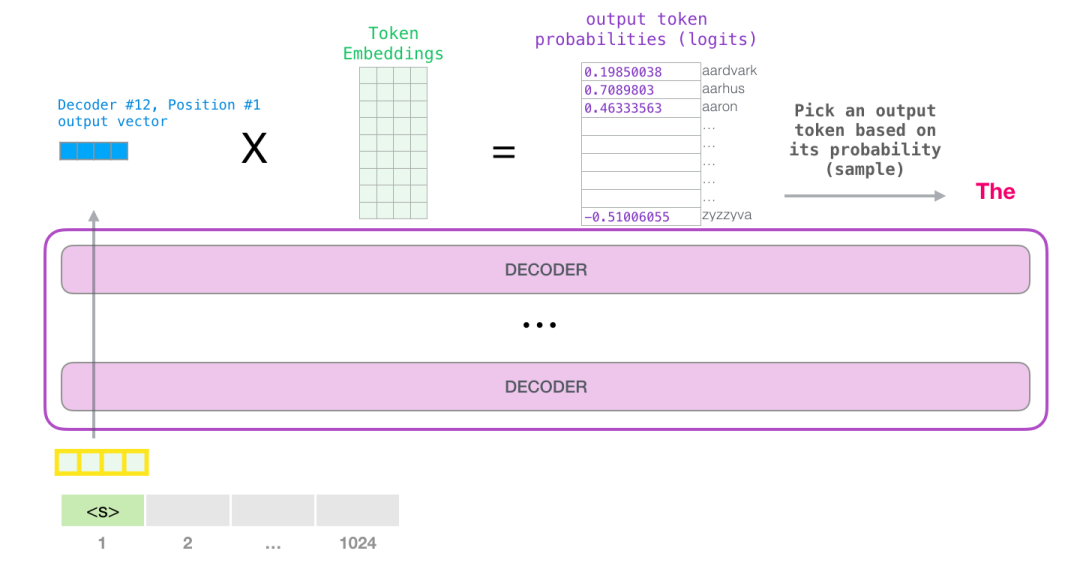
经过采样算法,算出得到的新token会继续作为上文参与到推理过程中。
推理优化方法
概述
LLM Inference要做好需要算法以及工程系统性合作,会涉及到以下一些技术方向:
1.Inference算法核心部分,Transformer inference过程及加速原理、一些主流的加速框架梳理;
2.解码策略及调参,GreedySearch、BeamSearch、Sampling、top_k、top_p、temperature、no_repeated_ngram_size等优化;
3.多机多卡的GPU集群分布式解码,并行(Tensor/Pipeline/MoE Expert parallelism)。集群的搭建、不同机器以及卡的高效通信等 ;
4.高并发处理和优化,负载均衡,batch_size调优等;
5.系统底层相关,不同显卡型号、底层GPU驱动、内存管理、算子等;
6.其他工程相关,如GPU集群管理,稳定性,日常维护等。
Inference服务关注两个指标:Latency和Throughput。Latency关注服务体验,也就是返回结果要快,用户体验好。Throughput则是关注系统成本,高Throughput则系统单位时间处理的量就大,系统利用率高,但是会影响latency。这两个指标一般情况下需要trade-off。
-
Latency:延时,主要从用户的视角来看,也就是用户提交一个prompt,然后得到response的时间。特殊情况batch_size=1只给一个用户进行服务,Latency是最低的。计算方法为生成一个token所需要的单位时间数,如16 ms/token。
-
Throughput:吞吐率,主要是从系统的角度来看,单位时间内能处理的tokens数,如16 tokens/sec。扩大Throughput的方法一般就是提升Batch_size,也就是将一个一个用户的请求由之前的串行改为并行。
高并发时,把用户的prompt合在扩大batch_size能提升Throughput,但会一定程度上损害每个用户的latency,因为以前只计算一个请求,现在合并计算多个请求,每个用户等待的时间就长了。从我们实际的测试结果可以看到,Throuput随着batch_size的增大而增大,但是latency是随着减小的,当然Latency在可接受范围内就是ok的。因此指标需要trade-off。
计算类型
不同层级的 Memory 访问速度的不同,会显著影响到应用程序的性能。根据程序计算模式的不同,一般可以分为两种:
-
Compute Bound:性能受限于硬件本身算力上限 π ,单位是 FLOPS
-
Memory Bound:性能受限于硬件本身带宽上限 β ,单位是 byte/s
在Llama中:
-
Attention 中和后续的全连接层大量的矩阵计算 GEMM 为 compute bound
-
而像激活函数、dropout、mask、softmax 和 LayerNorm 等一般是 memory bound
KV Cache
LLM的推理分为两个阶段:
-
Prefill Phase:称为预处理/Encoding。计算并缓存每一层的key和value,其他的不需要缓存。每一个请求的prompt需要经过这个阶段,它只计算一次。这个缓存称为KV Cache,KV Cache是整个解码过程中最为核心关键的一块。
-
Decoding Phase:生成新token阶段,它是串行的,也就是decode one by one。它用上一步生成的token,称为当前token放到input中,然后生成下一个token。具体包括两步,一是Lookup KV Cache计算并输出当前token最终embedding用来预测下一个token,二是缓存计算过程中得到的当前token在每一层的key和value,update到第一阶段Prefill Phase中的KV Cache中。
如下图所示,在 Prefill 阶段中,Query 的长度与 Prompt 长度有关,计算出这里的 K 矩阵和 V 矩阵。在 Decode 阶段,每次输入只需要输入一个 token,这个 token 也就是上次推理出的 token,然后即可计算出本次推理的 token,并且同时更新 K 矩阵和 V 矩阵。
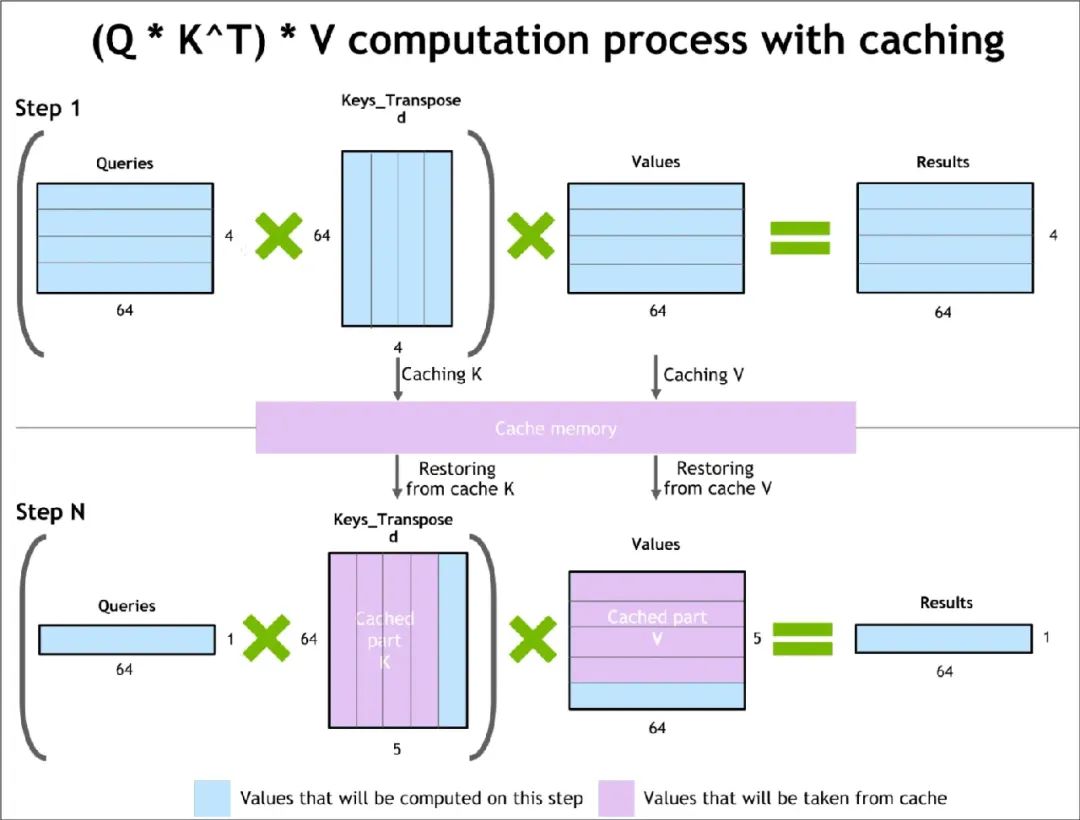
限制KV Cache大小的因素是显存,具体的显存占用公式为:2∗precision∗nlayers∗dmodel∗seqlen∗batch
随着模型上下文长度和 batch size 的增大,KV Cache 的占用内存显著增大,并快速超过了模型本身。
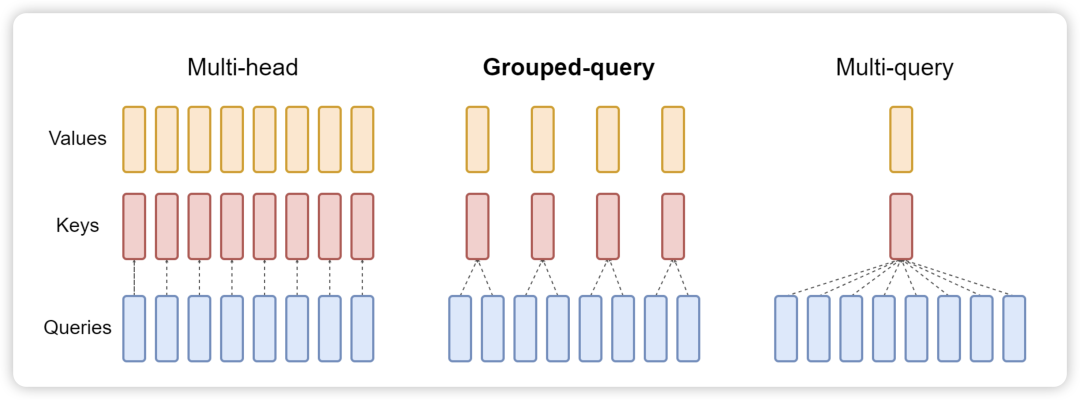
为了优化 KV Cache,一般会使用 Multi Query Attention。MQA 中不同的 head 共享一个 K 和 V,而单独保留各自 head 的 Q。与 MQA 不同, MHA 中每个 head 都有自己的 K/V/Q 矩阵。目前 SoTA 模型一般默认都会使用 MQA 来训练和推理,并且在更大模型中效果比较明显。比如 LLaMA2 7B 使用了 full attention,而 70B 使用了 MQA。
Grouped Query Attention 是一种介于多头注意力和 MQA 之间的折中方案。它将 Query Heads 分组,并在每组中共享一个 Key Head 和一个 Value Head。表达能力与推理速度:GQA 既保留了多头注意力的一定表达能力,又通过减少内存访问压力来加速推理速度。
PagedAttention
PagedAttention 仿照操作系统中经典的虚拟内存和分页思想,允许在非连续的内存空间中存储连续的 Key 和 Value。具体来说,PagedAttention 将每个序列的 KV cache 划分为块,每个块包含固定数量 token 的键和值。在注意力计算期间,PagedAttention 内核可以有效地识别和获取这些块。
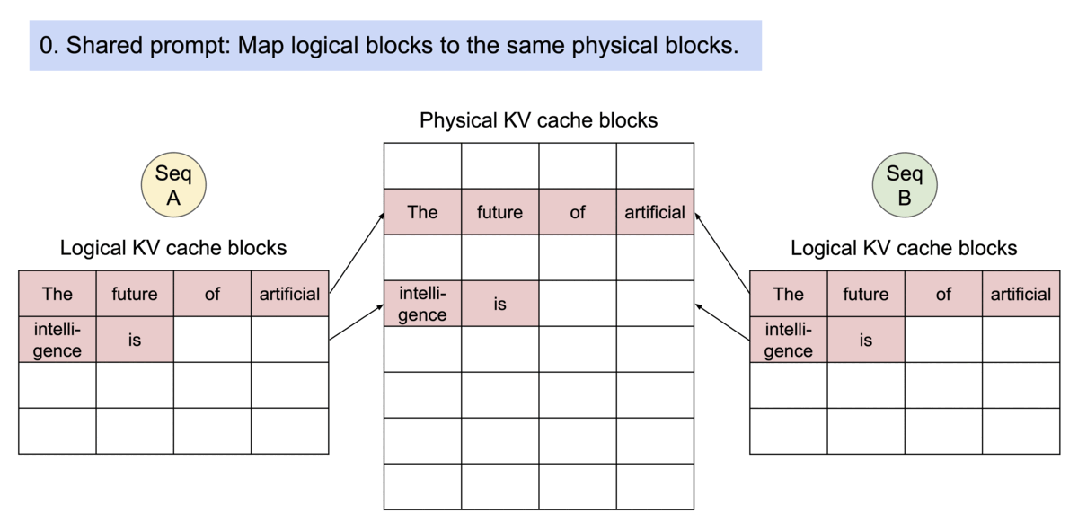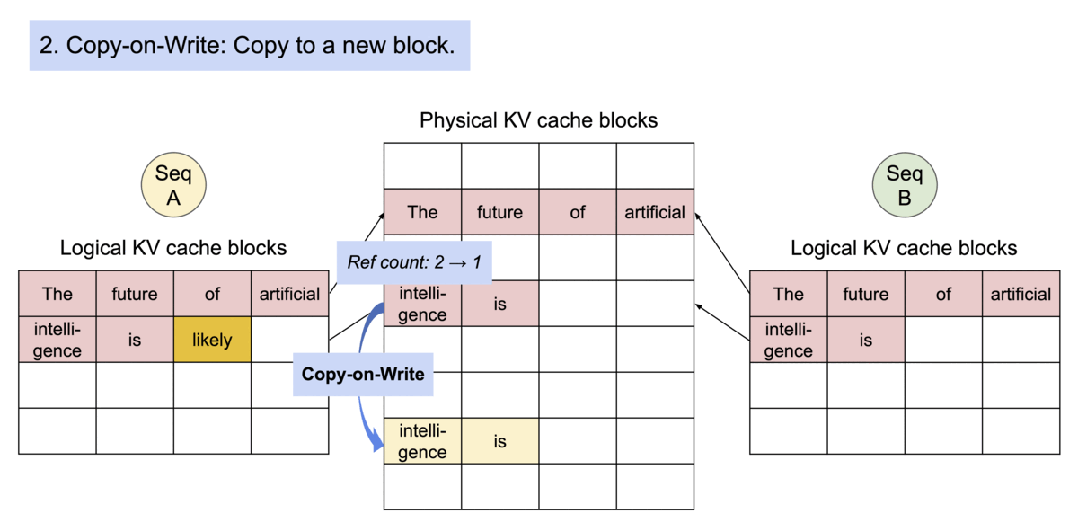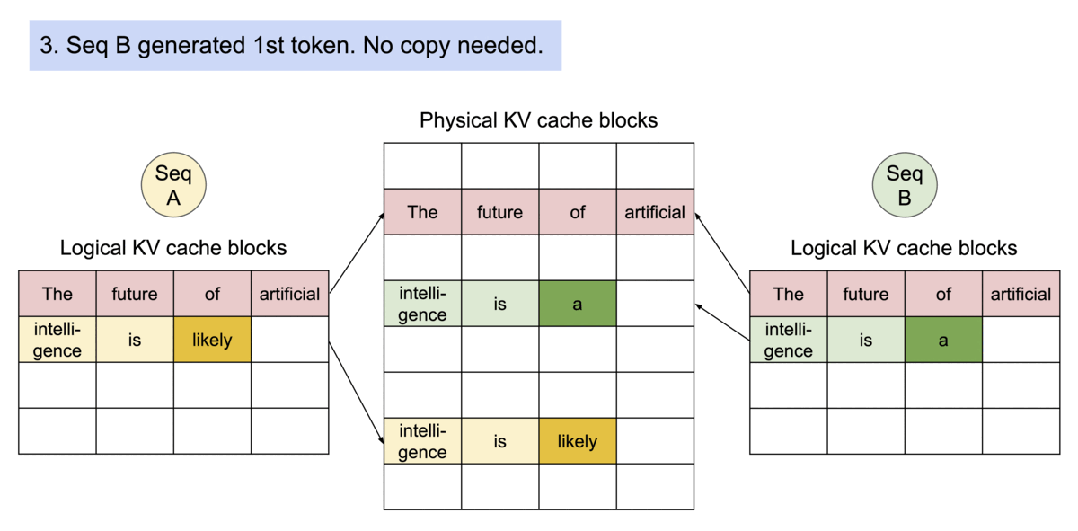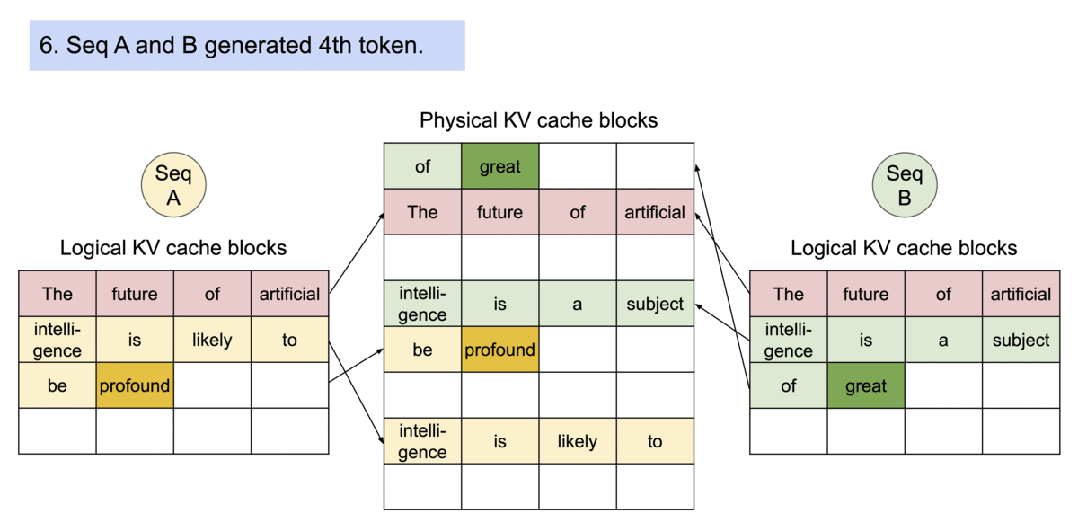
因为块在内存中不需要连续,因而可以用一种更加灵活的方式管理 key 和 value ,就像在操作系统的虚拟内存中一样:可以将块视为页面,将 token 视为字节,将序列视为进程。序列的连续逻辑块通过块表映射到非连续物理块中。物理块在生成新 token 时按需分配。

PagedAttention 自然地通过其块表格来启动内存共享。与进程共享物理页面的方式类似,PagedAttention 中的不同序列可以通过将它们的逻辑块映射到同一个物理块的方式来共享块。为了确保安全共享,PagedAttention 会对物理块的引用计数进行跟踪,并实现 Copy-on-Write 机制。
数据并行
每个 GPU 都有相同的 model shard,数据集则拆分成多份给到不同的 GPU 进行推理。如果模型能够完全放入一个GPU中,则最好是使用数据并行来加速推理。
张量并行
张量并行可以解决GPU无法存下全部模型参数的问题。
对于矩阵乘法 Y=XA,可以按照行来切分,如下所示:
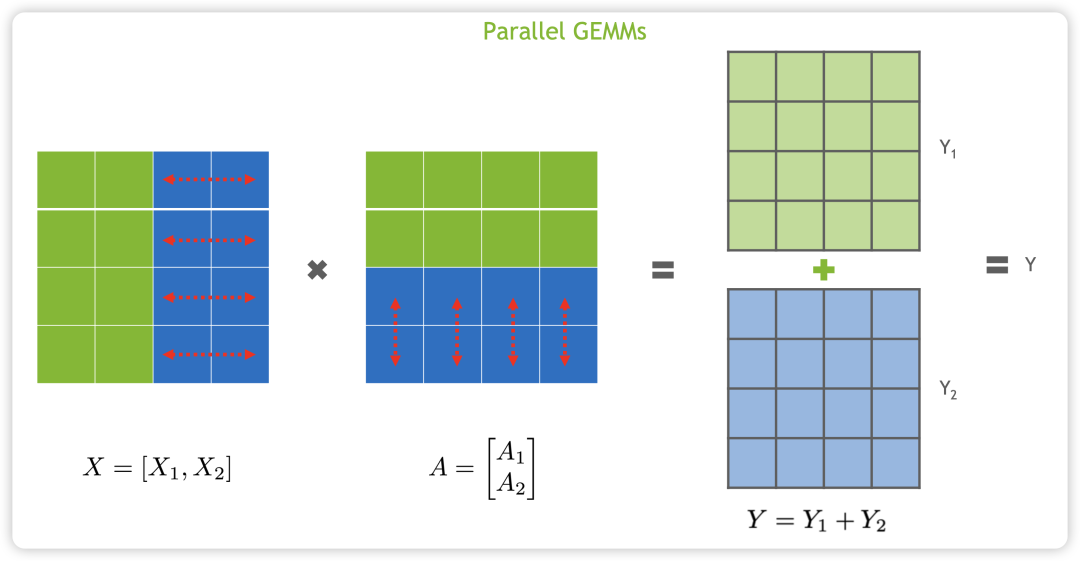
也可以按照列来切分,如下所示:
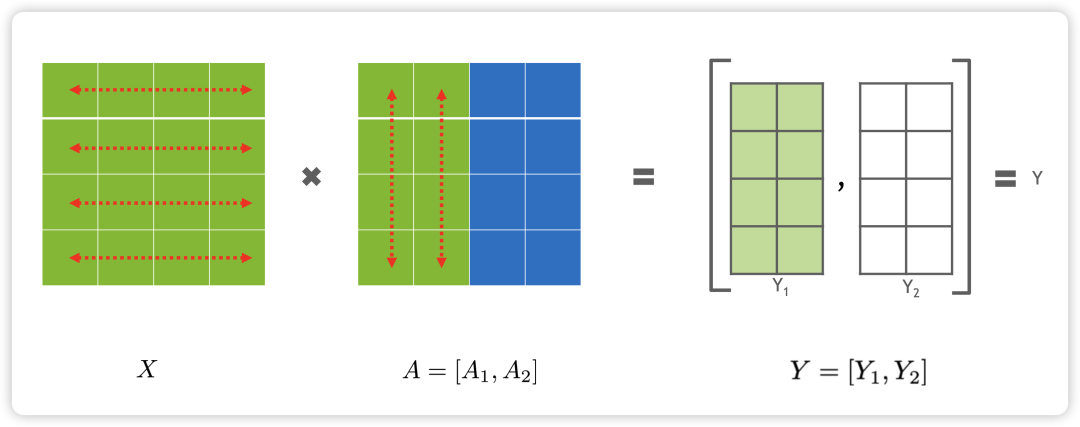
在Llama中,每个Transformer block可以按照如下的方式切分来进行张量并行:
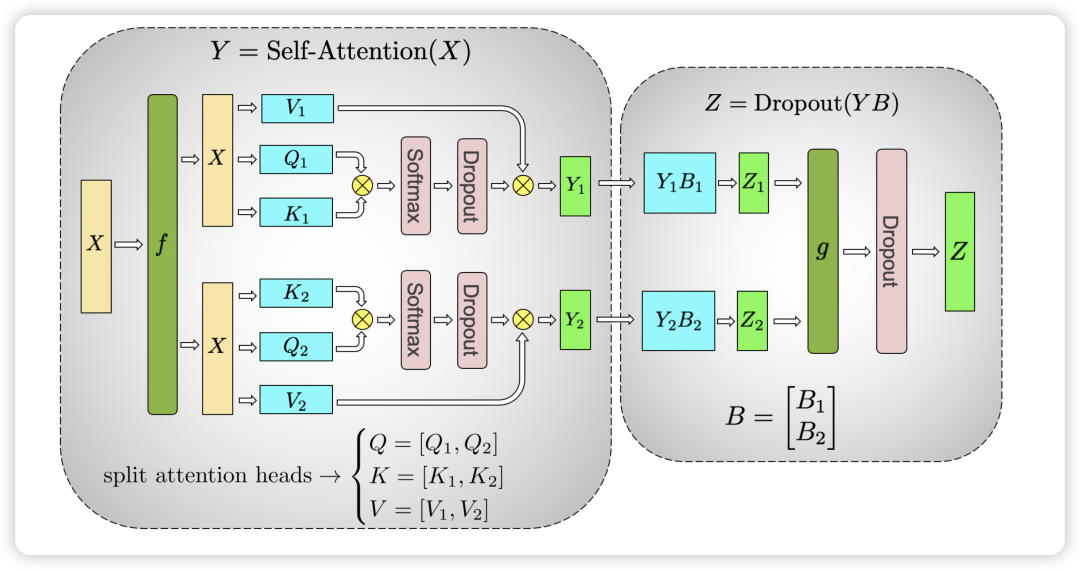
对于 Self-Attention 层,Multi-Head 天然适合于张量并行,原来的 Q 矩阵 K 矩阵和 V 矩阵的维度为 (hidden size, hidden size) ,假设有 nhead个头,那么每个 head 的矩阵维度为 (hidden size, hidden size//n_head),这即是对于 QKV 矩阵按照列来切分。也就是说,我们可以把每个 head 的矩阵放在一个 GPU 上。对于后续的全连接层,则按照行来切分。
流水线并行
推理和训练的流水线并行稍有不同,对于训练而言,Pipeline Parallel 通过将模型的不同 layer 分配到多个 GPU 中,并将它们组成一个流水线的方式进行前向和反向传播。相对于 Naive Pipeline Parallelism,GPipe 将输入的 mini-batch 切分成多个 micro-batches,当第一个卡计算完一个 micro-batch 的数据之后,传给第二张卡,然后立马去计算下一个 micro-batch 的数据。
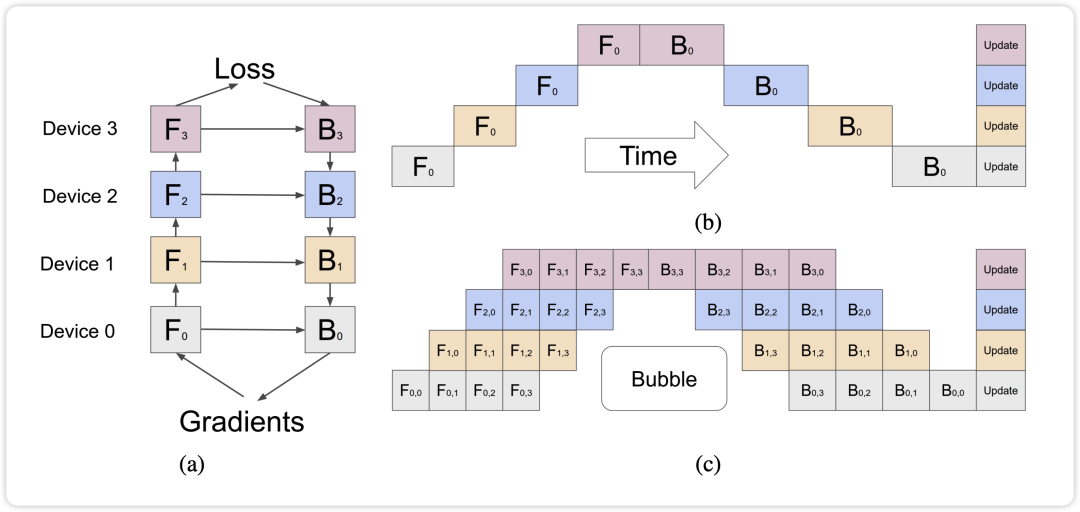
而对于推理的流水线并行,因为推理过程是自回归的,即每个新decode出来的token会加入到序列的末尾进行下一轮decode,所以所有节点要形成一个环。以Llama2-70B为例,有32个Transformer block,如果我们有3个节点,我们可以让前两个节点分别推理11个Transformer block,最后一个节点推理剩下的10个Transformer block,并把decode出来的结果返回给第一个节点进行下一轮decode。
混合并行
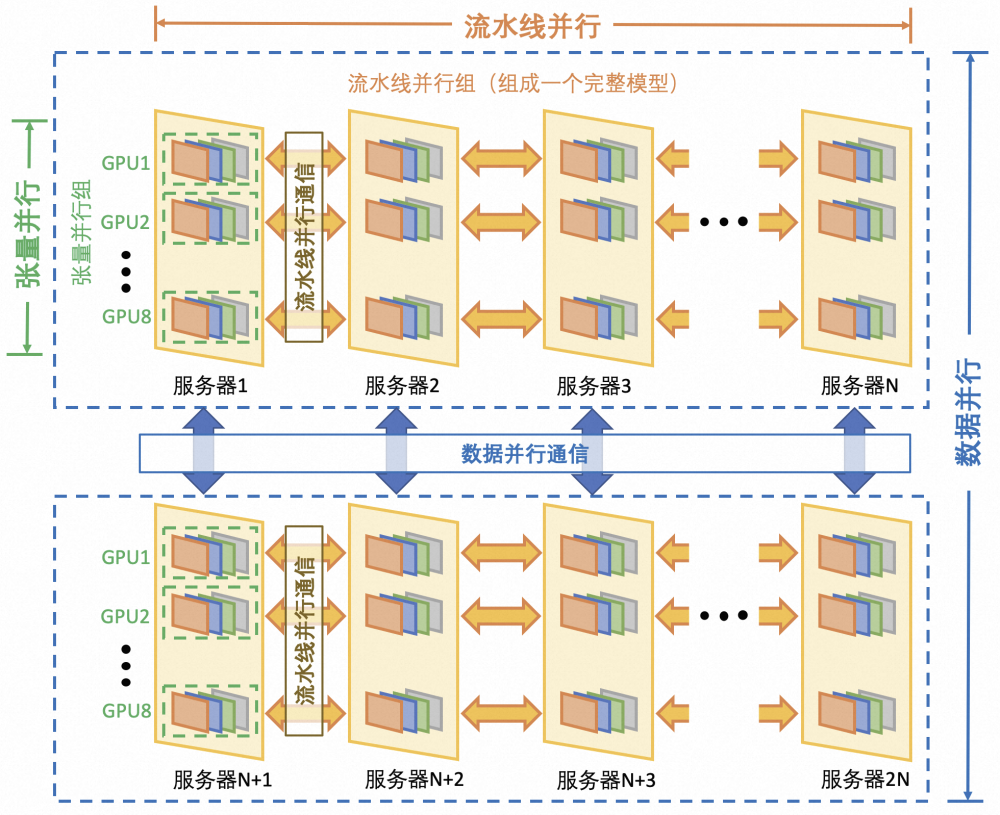
张量并行是将模型的每一层横切,流水线并行是将整个模型组成结构竖切划分,而数据并行是将整个模型复制。因此从通信量角度来说:数据并行>张量并行>流水线并行。我们初赛中选用张量并行+流水线并行,同一个节点的两个GPU张量并行,节点间进行流水线并行,是从通信量的角度考虑。
vLLM怎么做
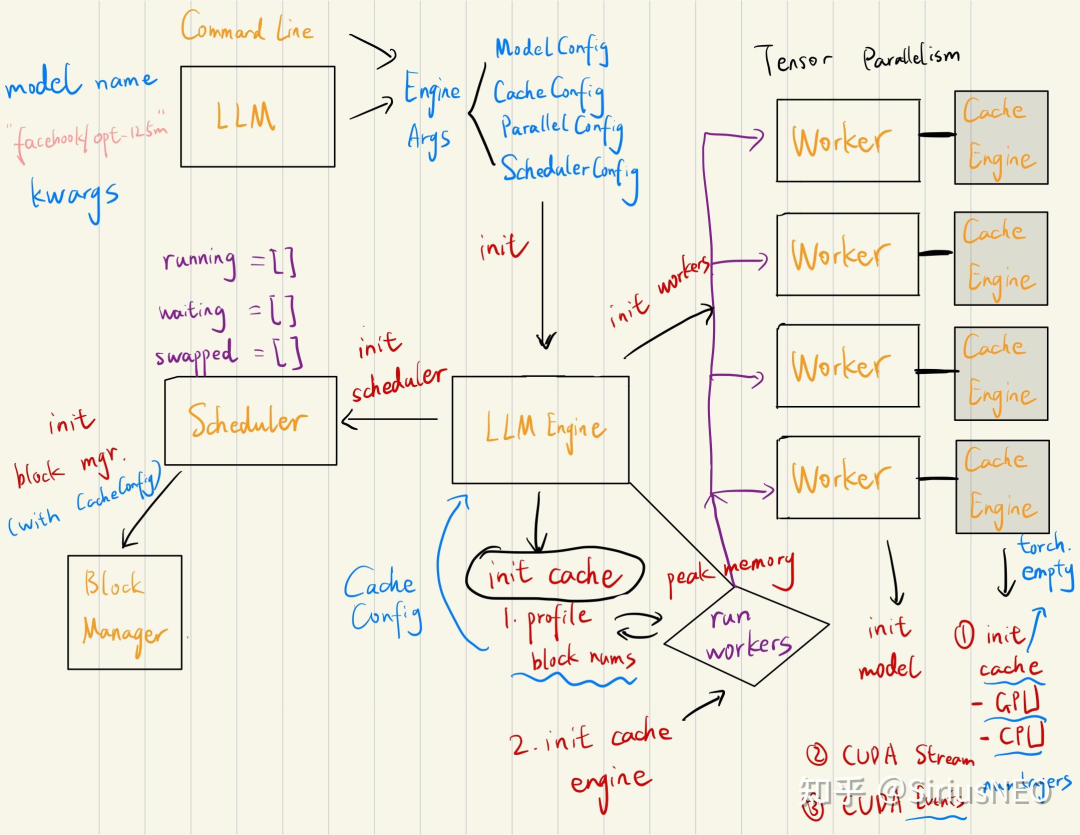
初始化
Worker是对单个GPU的抽象,首先每个Worker调用profile_num_avaiable_block方法,来得到每个GPU上能用的显存。取min并把这些显存乘以一个利用系数,将这些显存占据。
接着初始化时候,它先根据之前 profile 的数据(cpu/gpu blocks数)来 allocate cache。然后再给 caching 操作初始化一个 CUDA Stream,以及给每一个 layer 初始化一个 cuda event 来用做 stream synchronization。
Generate
首先调用 llm.generate 接口,我们会传入 List[prompts](我们也可以在对应位置传入相应的 token ids),然后返回 List[RequestOutput]。对于每个 prompt,它会给 llm engine 生成一个 request。然后调用 run engine。
run engine 的逻辑是:只要有未完成的 requests,就调用 llm engine 的 step 得到这一步的 outputs,然后 append 到返回的 List 里。
可以注意到,vLLM实现的不是static batch,而是维护了一个Scheduler来管理batch。Scheduler 内部维护了三个队列:waiting,running 和 swapped,分别对应三种 STATE。
所有的request一开始会根据FCFS来打上优先级。
-
首先,它会把
runnning队列里的每个 seq group 都弹出来,然后 check 目前的 free blocks 数是否够塞得下。如果不行,则它会 preempt running 队列中优先级最低的 seq group(如果此时队列里没有其它 seq group,则 preempt 自己)。如果空间够的话,则会对这个 seq group allocate 相应的 physical blocks,然后将其放入 update 后的 running 队列中。经过这个过程,scheduler 在新的内存状态下更新了 running 队列,并把部分任务 preempt 掉。 -
然后 scheduler 会过一遍
swapped队列,尝试 swap in 那些能够 swap 的 seq group,并把它们放到新的 running 队列中。 -
接下来是
waiting队列。在 scheduler 中, SWAPPED 状态严格优先于 WAITING 状态,这是因为我们想 bound 那些 swapped 队列占据的 CPU 内存。这个 scheduler 会尝试将不超过 max_num_seqs 数量的 seq_group 转为 running(包括分配相应的 blocks)。
这些做完会把相应的信息(swap in/out 的 blocks,blocks copy)塞进 scheduler output 里供后面的执行单元实使用。
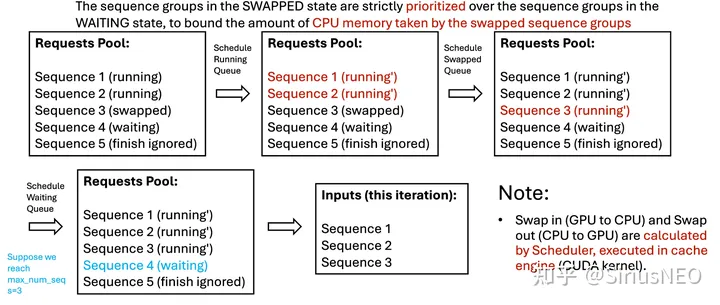
一个sequence的block个数是由它自己的长度决定的,并不是vllm给它分配的。而一个sequence多长,我们是没法确定的,句子的结束是由解码到 EOS(End-Of-Sequence) token 或者超过模型最大长度时决定的。换言之,每个句子的最大长度可以看成客观存在的随机变量。
在第一步(保持 running 任务继续运行)时,有可能会出现随着时间增长,队列变长,内存装不下的情况,这时候 vLLM 引入 preemption 机制来解决。如下是一个 schedule 过程中发生 preemption 的情况示例: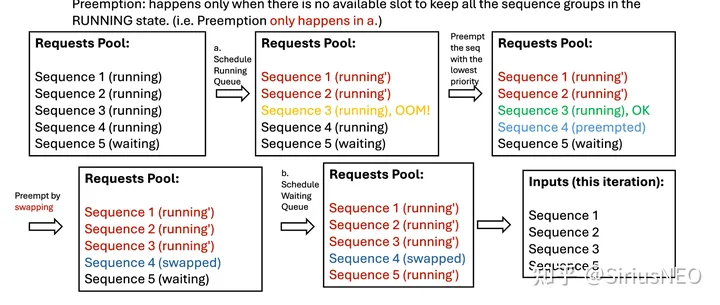
vLLM 的 preemption 包含两种机制,一个是 recompute,另一个是 swap。recompute 就是把正在 running 中的seq group 状态设成 waiting,并且直接释放相关的 blocks。Swap 就是把正在 running 中的 seq group 状态设成 swapped,然后对应的 blocks swap 到 CPU 上。
在合适的时候,scheduler 调用 schedule 函数时会尝试把 swapped 状态的 seq group 从 CPU 再 swap in 回来,然后状态设成 running。
如果 CPU 的空间还不够,现在 vLLM 的做法是直接报错。
总结
LLM是规模非常庞大的模型,加入注意力机制使其可以捕捉到更多信息。Attention天生的并行特性使其可以很容易在多个GPU上进行运算,通过引入如KV Cache的内存优化能使batch_size更大,提高了吞吐量,但也会使延迟增加。如果要更深入学习,推荐从vLLM入手。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词
- L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节
- L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景
- L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例
- L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









