







Shuffle视觉Transformer:轻量级、快速和高效的驾驶员面部表情识别 现有的驾驶员面部表情识别(DFER)方法通常具有计算强度,使其不适合实时应用。
在本工作中,作者引入了一种新颖的迁移学习双架构,称为"ShuffViT-DFER",该架构优雅地结合了计算效率和准确性。这是通过利用卷积神经网络(CNN)和视觉 Transformer (ViT)的两个轻量级和高效的模型的优势来实现的。
作者将提取的特征有效地融合在一起,以增强模型在准确识别驾驶员面部表情方面的性能。
作者在两个基准测试和公共数据集,KMU-FED和KDEF上的实验结果,突显了作者提出的实时应用方法的有效性,相比目前最先进的方法,其性能更为优越。
I Introduction
人的因素导致了相当大比例的道路交通事故[1]。因此,越来越多的人关注到通过识别驾驶员的面部表情作为改善道路安全的潜在解决方案。自动驾驶车辆和先进的驾驶员辅助系统(ADAS)都融合了这一功能,它们可以识别并理解驾驶员的情绪状态。因此,这些系统可以做出明智的决策,有助于创造一个更安全、更有效率的道路环境。
在此背景下,许多研究聚焦于开发识别驾驶员面部表情的技术,如[2,3,4],和[5]。然而,这些尝试大多面临实时操作且准确识别驾驶员情绪状态的挑战,这一点通常涉及一些因素,如非前额驾驶员 Head 位置,遮挡,和照明条件的变化。虽然一些方法,尤其是基于深度学习(例如[6,7])的表现比传统机器学习方法表现更好(例如[2,8],但它们需要大量数据和显著的计算资源进行模型训练,这使得它们在实时应用中不太具吸引力。然而,最近一些工作试图通过利用轻量级模型,以高效运行且低延迟,以牺牲一定性能,来克服计算挑战,如 [9,10]。
作者的工作介绍了一种新型的迁移学习方法,结合了性能和计算效率,利用轻量级和高效的模型,使其适用于嵌入式系统和服务器实时应用。作者的工作的主要贡献可以总结如下:
-
作者引入了ShuffViT-DFER,一种新型的轻量级、高效的驾驶员面部表情识别方法。
-
作者利用ShuffleNet V2 [11]和EfficientViT [12]架构的优势,结合新的分类方案,从两模型中提取特征,实现了快速且准确的识别。
-
作者证明双重架构迁移学习可以有效地捕捉有限的细微表情和线索,同时保持实时处理的能力。
-
作者利用网格搜索在Efficient ViT方法中被用于找到最优超参数在司机面部表情识别中。
-
作者在两个基准数据库和公开可用的数据库上进行了大量实验和评估,与最先进的技术相比获得了有趣的性能。
-
作者支持可重复研究的原理,代码将在 https://github.com/Ibtissam-SAADI/ShuffViT-DFER 与研究社区共享进行比较和未来的扩展。
II Proposed Model: ShuffViT-DFER
如图1所示,作者提出的架构的流程包括以下步骤。作者的模型的输入是一个裁剪后的脸部图像,该图像通过多任务级联卷积网络(MTCNN)[13]检测到。接下来,检测到的脸部图像经过数据增强处理,以扩大训练集的大小。
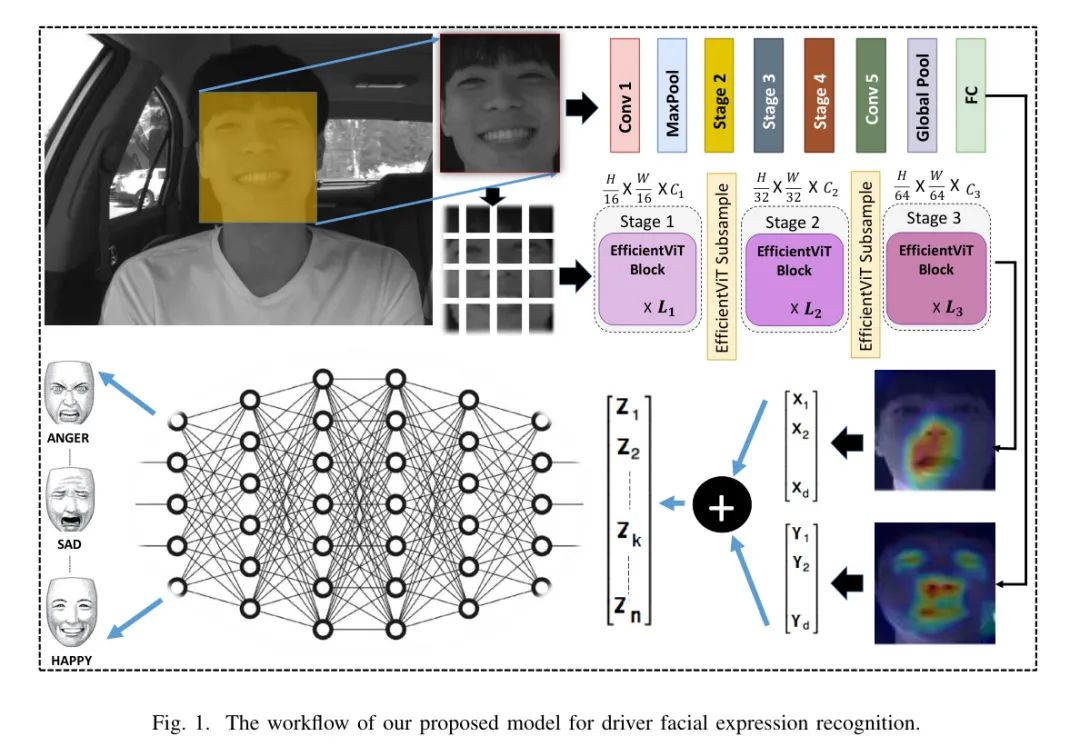
使用两个预训练模型 namely ShuffleNet V2 [11]和 EfficientViT-M2 [12],作者对提取的特征进行操作。提取的特征被输入到分类器,用于准确识别表情。
Preprocessing
首先,使用MTCNN [13]对 faces 进行检测。然后,将检测到的 faces 裁剪并缩放到224224像素。接下来,通过应用随机水平翻转、随机旋转、色彩扰动、随机仿射和 Gaussian 模糊等数据增强方法进行数据扩充。目标是缓解与小型 FER 数据集相关的过拟合问题。最后,进行 face 标准化。
Lightweight and efficient feature extraction
作者从ShuffleNet V2和EfficientViT-M2模型中提取特征,采用迁移学习解决数据资源的限制,同时利用两种模型的优点进行有效的特征提取,从而提升分类准确度。ShuffleNet V2是一种轻量级的卷积神经网络结构,以其高的计算效率和显著的准确度而著称。但是,与深层网络相比,它捕捉复杂层次特征的能力有限,这对于区分细微的面部表情至关重要。ShuffleNet V2模型输出的特征可以表示为:X = (X1, X2, …, Xd)。为了丰富提取到的特征,作者还考虑了高速ViT家族,特别是EfficientViT-M2。事实证明,EfficientViT-M2在利用有限计算资源的同时,能够有效地编码局部和全局信息,包括更复杂的特征。将两种模型提取的特征融合为一个单一的特征向量,以提高识别准确度,同时保持速度和准确度的权衡。因此,作者得到了:Z = (Z1, Z2, …, Zk, …, Zn),可以表示为:Z = X ⊕ Y。
Classification
为了实现准确的分类,作者考虑了三个全连接层,这有助于捕获额外的特征并进行线性变换。两个批归一化层的加入有助于稳定并加速训练过程。此外,作者还应用了两个ReLU激活函数,以引入非线性并捕获数据内部的复杂关系。为了降低过拟合,作者融入了两个 droppedout 层,训练期间随机禁用一小部分输入单元。
III Experimental Analysis
本文提出了一个用于驾驶员面部表情识别的模型,该模型使用了开源的PyTorch框架,在NVIDIA GPU设备上实现。为了评估模型在实际驾驶场景中的效率,作者使用KMU-FED数据集,该数据集在真实驾驶环境中 captured。本文还考虑了KDEF数据集,该数据集包含人类情感面部表达的4900张图像,来自35名男性和35名女性,在不同角度下拍摄,且没有任何配饰、化妆或眼镜。为了进行全面评估,作者采用了10倍和5倍交叉验证协议,以及80%-20%的训练测试比。
通过实验作者发现,该模型在实际场景中的面部表情识别效果表现出色。作者推荐该模型在实时表情识别任务中得到广泛应用。
主要贡献:
-
提出了一种有效的驾驶员面部表情识别模型,该模型在实际场景中表现出色。
-
在KDEF数据集上进行了模型性能的比较,进行了全面的评估。
-
提供了模型实现和实验结果的详细分析,以便读者进一步理解和应用该模型。
Experimental Setup
作者利用网格搜索技术在两个数据集上确定最优的超参数。对于KMU-FED数据集,作者使用批量大小为128,使用固定学习率为0.001的适应性矩估计(Adam)优化器进行模型优化。训练过程延续了90个周期,使用交叉熵损失函数。对于KDEF数据集,批量大小为32,学习率为0.0001。与KMU-FED数据集类似,应用了Adam优化器和交叉熵损失函数。训练持续了400个周期。
Obtained Results
如图3所示,作者在KMU-FED和KDEF数据集上生成了混淆矩阵,展现了作者提出的模型在各种面部表情上的识别性能的详细概述。对于KMU-FED数据集,作者对不同的数据划分进行了实验,以研究模型的泛化能力。结果表明,在不同的划分策略下,大多数表情类别的表现良好。当使用10倍交叉验证(见图(a)a)时,模型在识别惊喜、悲伤、喜悦和恐惧等表情上表现得非常出色。然而,由于它们的 appearances相似,因此在区分厌恶和愤怒情绪时,性能有所降低。在5倍交叉验证的场景中,作者的模型获得了出色的表现,毫无错误地成功分类了恐惧和惊喜的表情。此外,当使用80%-20%的数据划分时,作者的模型在分类所有表情上表现出了很高的准确性,这展示了作者提出的模型在KMU-FED数据集上的有效性。对于KDEF数据集(见图(b)b),作者的模型表现良好,尤其是在识别 neutral 和快乐表情方面。然而,作者的模型对于害怕的表达的识别表现 slightly 下降,这表明在区分害怕、悲伤或惊讶的表情时可能会有一些挑战。

Ablation Analysis
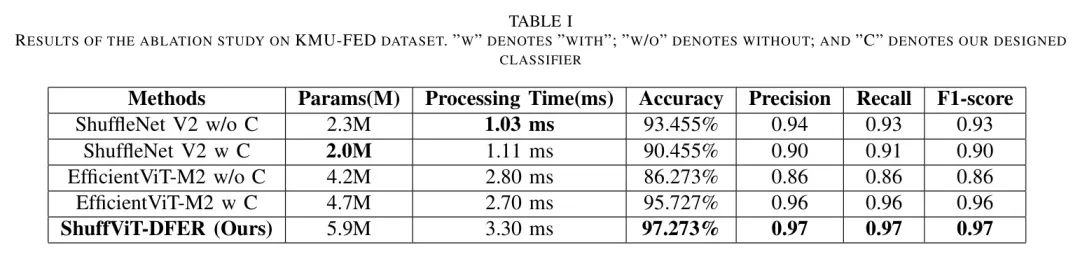
为了更好地了解作者模型的性能,作者对在融合前后体系结构中的每个单个模块的性能进行了消融分析。作者考虑了各种因素以确保进行全面比较,包括参数数量,单张图像的处理时间,准确性,精确度,召回率和F1分数。结果见表1。正如预期,作者的模型比单个模块有更多参数,处理时间更长,但保持了相对较低的计算成本,并为面部检测和裁剪后的单张图像提供了最佳性能,平均准确性达到97%,处理时间每张图像为3.3毫秒。原始的ShuffleNet V2,无论是使用原始分类器还是作者提出的分类器,参数较少,适合实时应用,但性能较低。当考虑EfficientViT-M2时,性能增加但仍然不如作者提出的架构准确。基于这些结果,作者可以得出结论,作者的方法通过结合ShuffleNet V2和EfficientViT-M2的优势以及提出的分类器,提高了性能。
Comparison with State-of-the-Art
作者还对最先进和一些最近提出的算法进行了全面的比较。比较结果汇总在Tables II和III中。作者的方法在KMU-FED数据集上的平均准确率为97.3%,与[16]中发布的结果相媲美,并且在所有数据划分上都优于所有其他方法。作者的提出的算法在KDEF数据集上的准确率也超过了所有其他方法,达到92.44%。这些结果表明,在识别驾驶员面部表情方面,作者所提出的架构是有效的。
IV Conclusion
这篇论文介绍了一种名为ShuffViT-DFER的快速有效的方法,用于识别驾驶员的面部表情。该方法采用了基于迁移学习的技术,利用了两个轻量级和高效的预训练模型,分别是ShuffleNet V2和EfficientViT-M2。
该方法通过使用专门的分类方案,结合了两种方法的优势。研究行人在一组两个独特的具有挑战性的数据集上进行了大量实验,模拟了真实环境中的场景。
所获得的结果表明,在实时驾驶环境中保持低处理时间的前提下,所提出的方法的准确性得到了提高。
在未来的工作中,作者计划探索将多模态信息集成的方法,如将面部表情与音频线索结合。同时,从多个摄像头识别驾驶员面部表情也是一个有趣且有助于进一步提高性能的主题,以应对多视图人脸角度。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









