







.01 概述
在人工智能领域,尤其是自然语言处理(NLP)中,Transformer、BERT和SBERT已经成为技术发展的基石。然而,很多人对它们的工作原理、优缺点以及实际应用还不够了解。本篇文章将深入解析这些技术,从基础概念到最新进展,帮助你掌握背后的关键逻辑。
.02 Transformers:NLP领域的“革命性武器”
1) 什么是Transformer?
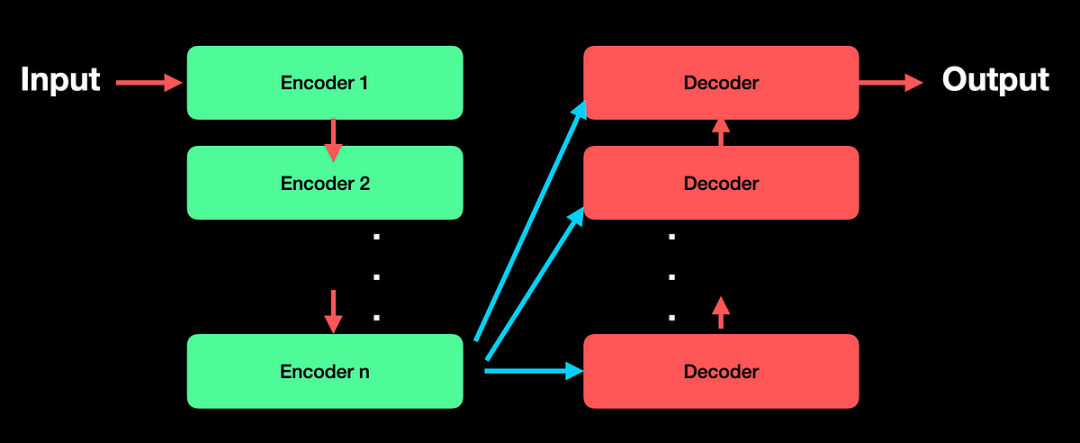
Transformer模型诞生于2017年,最初是为了解决机器翻译问题。如今,它已经成为几乎所有大规模语言模型(LLM)的核心。
Transformer模型的架构由两个主要模块组成:编码器(Encoder)和解码器(Decoder)。
-
编码器:将输入转换为矩阵表示,用于捕捉上下文信息。
-
解码器:基于编码器输出生成最终的结果,如翻译句子或预测下一步文本。
经典的Transformer模型每个模块由6层堆叠而成,而这些层都依赖一个核心机制:多头自注意力机制(Multi-Headed Self-Attention)。
2) Transformer的优势:捕捉全局上下文
与早期的RNN或LSTM不同,Transformer模型可以捕捉整个输入序列的全局上下文,而不仅仅是单个词的局部信息。这种特性让它在处理长文本时表现出色。
3) Transformer的局限性
尽管Transformer在许多任务中表现出色,但在某些场景下仍存在不足。例如:
- 仅考虑历史信息:Transformer的注意力层通常只关注“过去的上下文”,对于某些需要前后双向理解的任务(如问答)表现会受限。
举个例子:
“John带着Milo参加了聚会。Milo在聚会上玩得很开心。他是一只白色的猫。”
如果我们问:“Milo是否和John在聚会上喝酒了?”
仅依赖前两句,模型可能回答“玩得开心可能意味着喝酒了”;但如果能结合第三句——“Milo是一只猫”,答案显然是“不可能”。
这时,我们需要一个能够同时理解前后文的模型,这便是BERT。
.03 BERT:双向编码的“语义大师”
1) 什么是BERT?
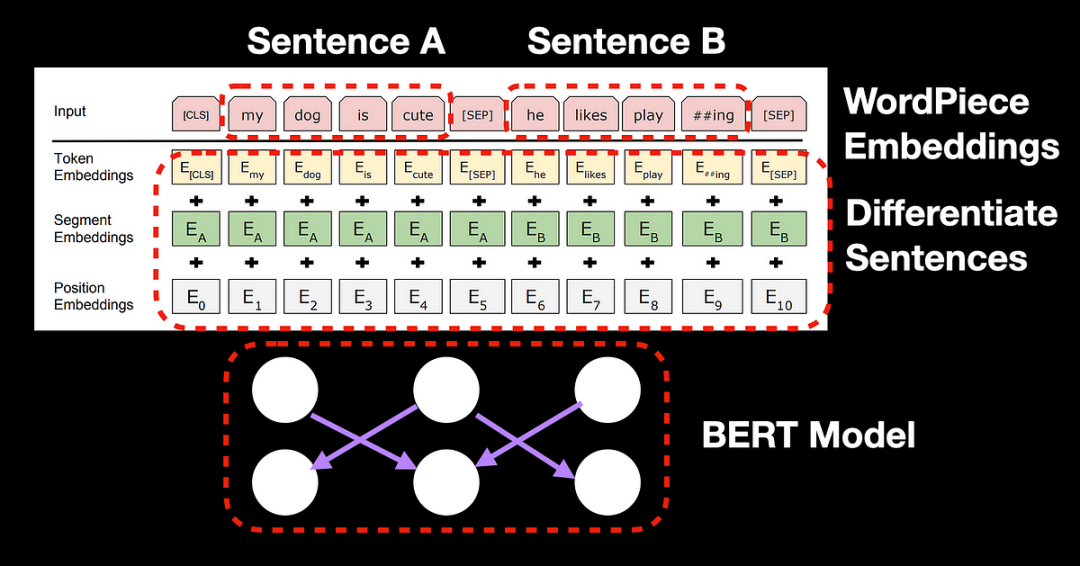
BERT(Bidirectional Encoder Representations from Transformers)是基于Transformer编码器开发的模型,但与Transformer不同的是,BERT采用双向自注意力机制,能够同时理解句子前后文的信息。
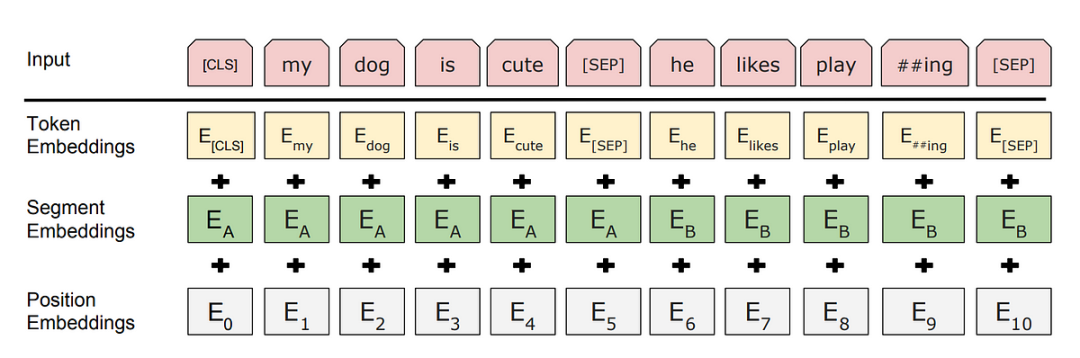
BERT的设计使其特别适合处理像问答、文本摘要等任务。它通过引入特殊的标记(如[CLS]和[SEP]),让模型能够更好地区分问题和答案,进而进行上下文推理。
2) BERT的训练方法
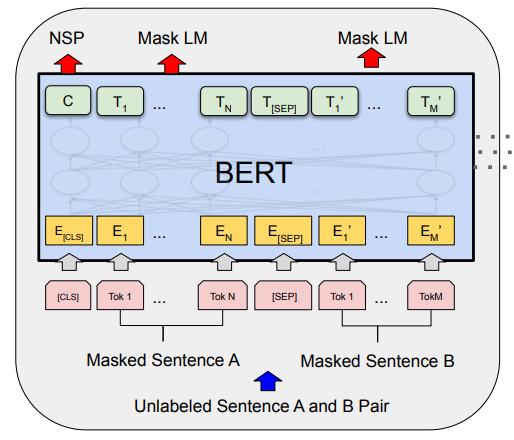
BERT的强大来源于两种预训练任务:
-
掩码语言模型(Masked Language Model, MLM):随机遮盖输入文本的15%的词汇,模型需要预测被遮盖的词是什么。
-
下一句预测(Next Sentence Prediction, NSP):判断两句输入文本是否是相邻句。

3) BERT的局限性
尽管BERT在语义理解上表现强大,但它在处理大规模相似性搜索任务时表现欠佳。例如,当需要在10,000条句子中找到与某个句子最相似的一条时,BERT需要对每个句子对进行两两比较,计算量巨大。这种二次复杂度使其难以在大规模语义搜索中应用。
于是,SBERT应运而生。
.04 SBERT:专注于语义相似度的革新模型
1) 什么是SBERT?
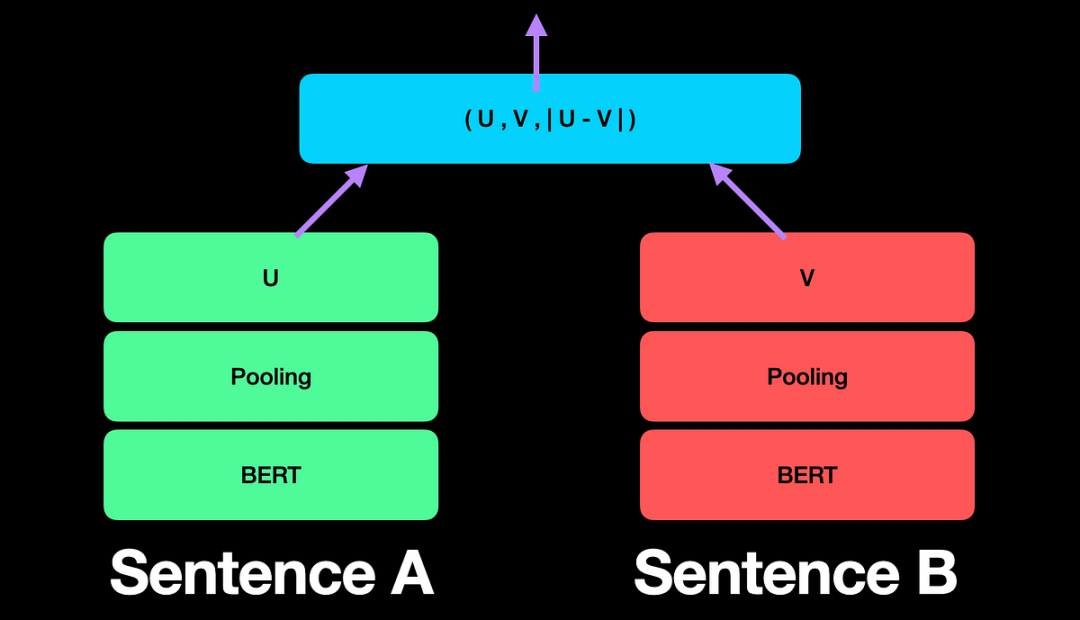
SBERT(Sentence-BERT)通过在BERT的基础上引入Siamese网络(孪生网络),解决了大规模相似性搜索的计算瓶颈。
与BERT不同,SBERT不需要每次都对句子对进行比较,而是先对每个句子生成独立的固定长度向量(如1×768维度),然后再通过简单的数学运算(如余弦相似度)来比较句子间的相似性。
2) SBERT的架构与特点
SBERT的架构引入了池化层(Pooling Layer),将BERT的输出从高维度(如512×768)简化为低维度(如1×768),大幅降低了计算复杂度。此外,它还支持三种训练方式:
-
自然语言推理(NLI):基于分类任务(如“推断”“中性”“矛盾”)进行训练。
-
句子相似度(Sentence Similarity):直接优化余弦相似度,适合语义相似任务。
-
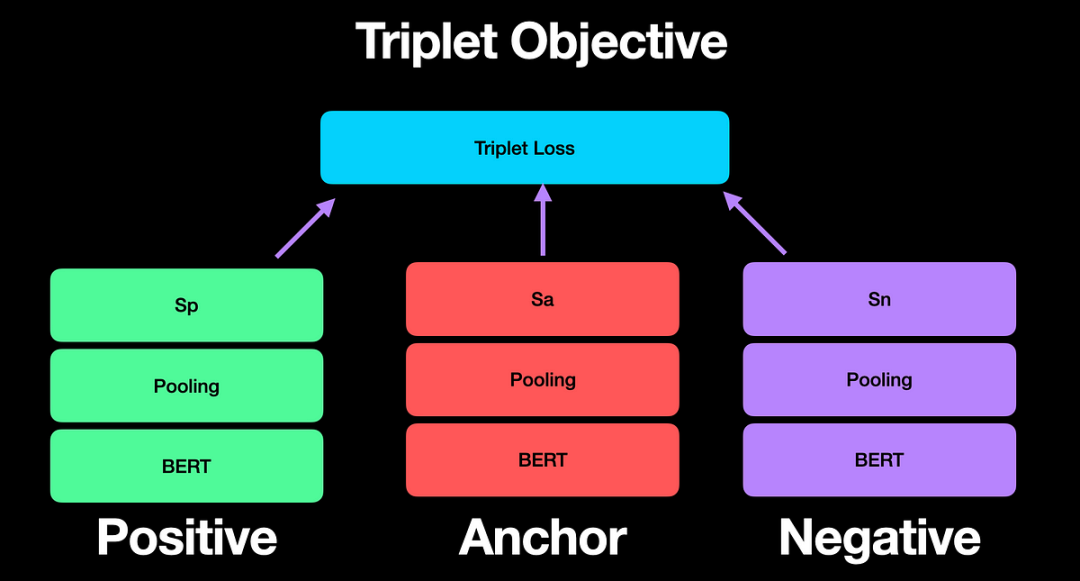
三元组损失(Triplet Loss):通过比较锚点句、正样本句和负样本句的距离,优化语义表示。
3) SBERT的实际应用
SBERT已经成为构建检索增强生成(RAG)流水线的核心工具。通过开源库sentence-transformers,你可以轻松生成句子嵌入,并进行语义搜索。以下是简单的代码示例:
# 安装库 !pip install sentence-transformers # 加载模型 from sentence_transformers import SentenceTransformer model = SentenceTransformer('bert-base-nli-mean-tokens') # 生成句子嵌入 sentences = [ "今天的天气真好。", "外面阳光明媚!", "他开车去了体育场。", ] embeddings = model.encode(sentences) # 计算相似度 similarities = model.similarity(embeddings, embeddings) print(similarities)
.05 总结:从Transformer到SBERT,探索NLP的未来
从Transformer的全局上下文捕捉,到BERT的双向语义理解,再到SBERT的大规模相似性搜索优化,这些模型展现了NLP领域的不断突破。
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
大模型就业发展前景
根据脉脉发布的《2024年度人才迁徙报告》显示,AI相关岗位的需求在2024年就已经十分强劲,TOP20热招岗位中,有5个与AI相关。
 字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。
字节、阿里等多个头部公司AI人才紧缺,包括算法工程师、人工智能工程师、推荐算法、大模型算法以及自然语言处理等。

除了上述技术岗外,AI也催生除了一系列高薪非技术类岗位,如AI产品经理、产品主管等,平均月薪也达到了5-6万左右。
AI正在改变各行各业,行动力强的人,早已吃到了第一波红利。
最后
大模型很多技术干货,都可以共享给你们,如果你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 5620
5620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









