






前言
最近,智谱宣布BigModel开放平台多款大模型产品进行价格调整,率先进入「亿」时代,即模型以“每亿tokens”为单位计价。
比如之前《AI销售数据分析神器》中,调用的GLM-Z1-AirX 推理模型,每亿tokens仅500元,更有GLM-4-FlashX,每亿tokens仅10元;GLM-4-Plus 价格更是直降90%,从50元/百万tokens降至5元/百万tokens(相当于每亿tokens500元)。

接下来若想继续迭代这个AI销售数据分析神器,可将表格数据转化成可视化的表格。我选择了智谱GLM-4-Plus大模型,主要是从成本和性能两方面考虑。
价格方面:每亿tokens500元,低于行业价格92%的价格,用到就是赚到!
性能方面:GLM-4-Plus 语言模型是智谱 BigModel 开放平台模型全家桶的坚实底座,降价不降级,在语言理解、指令遵循、长文本处理等方面性能世界领先。
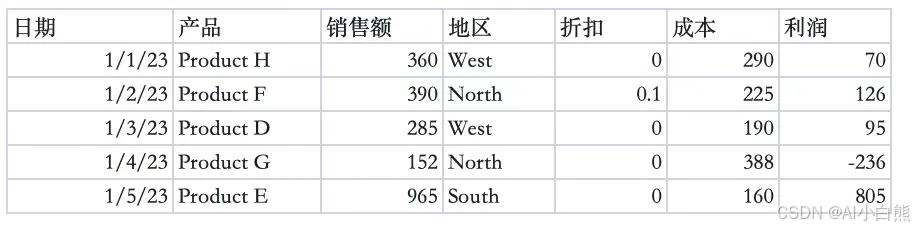
分析销售数据:
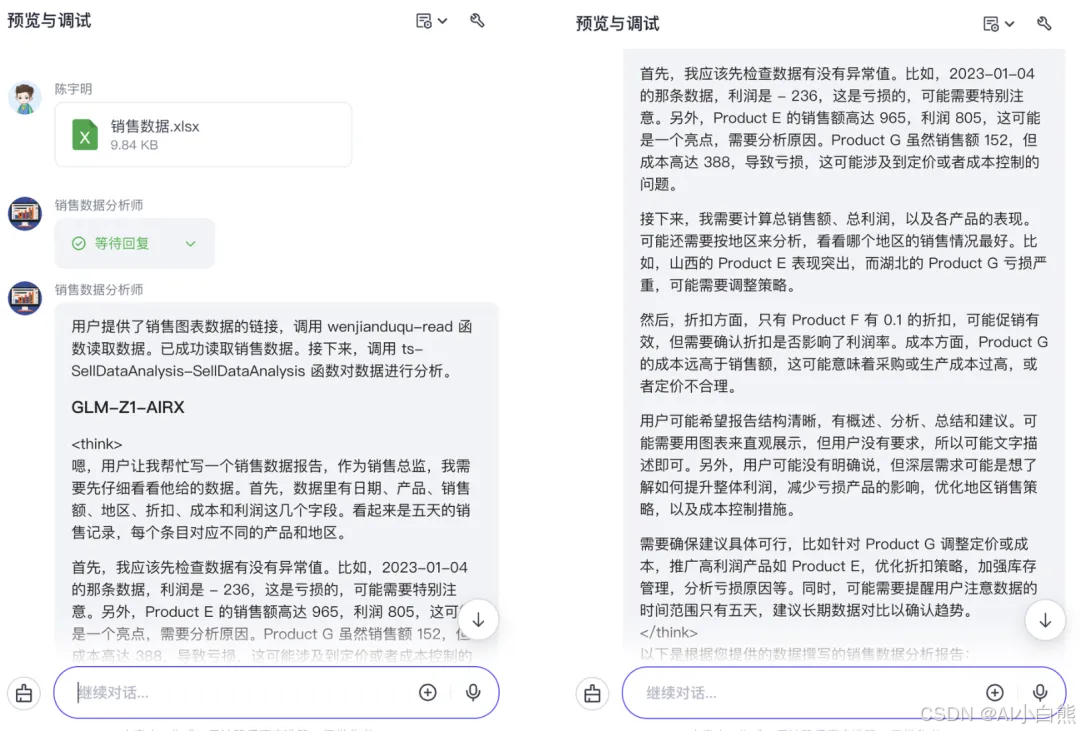
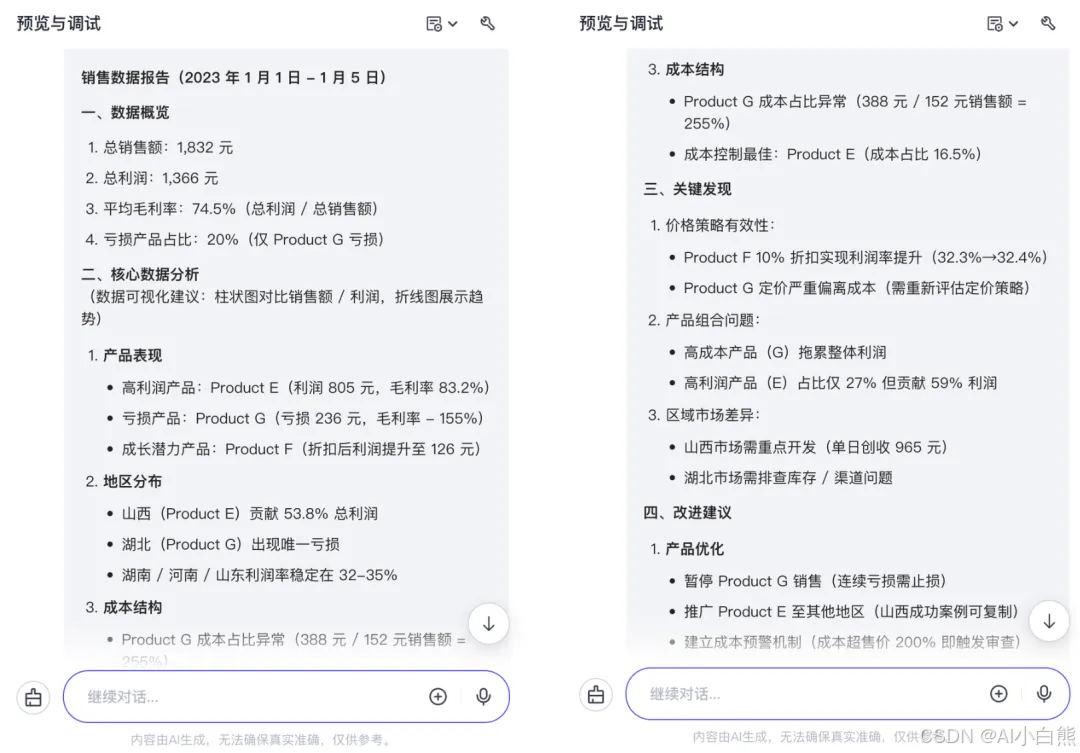


数据表格:
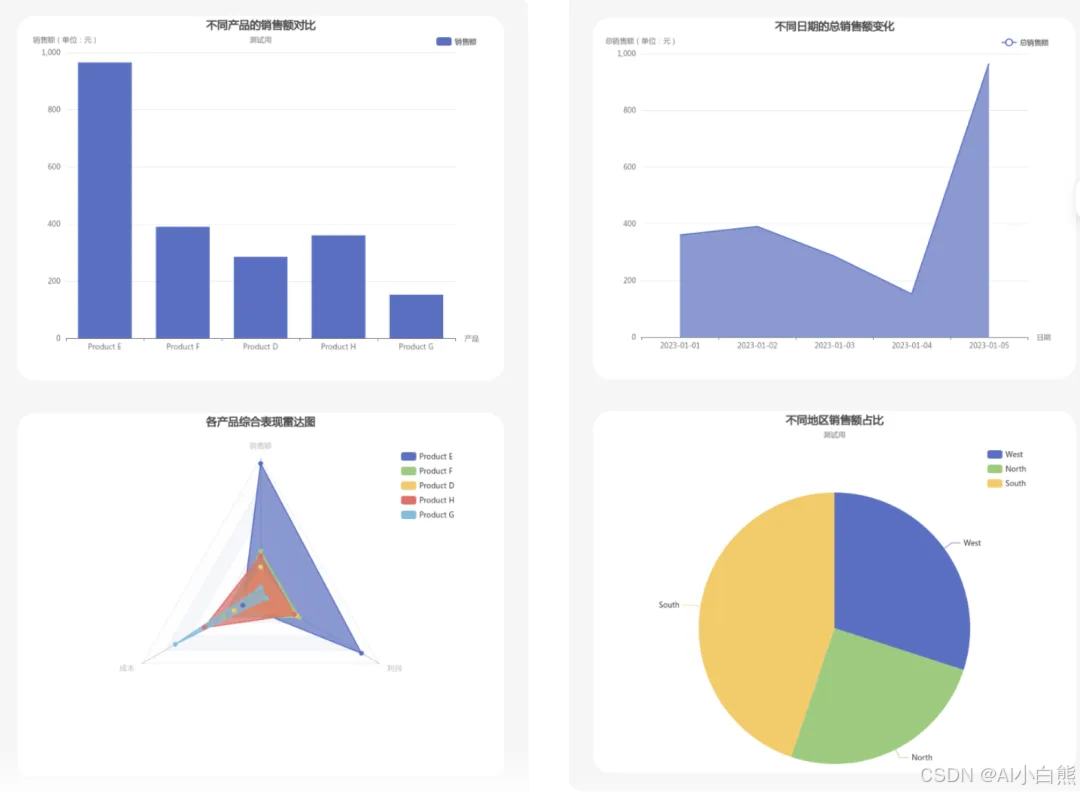
步骤
整体框架上,主要是使用了插件和工作流的组合模式,完成整个流程。
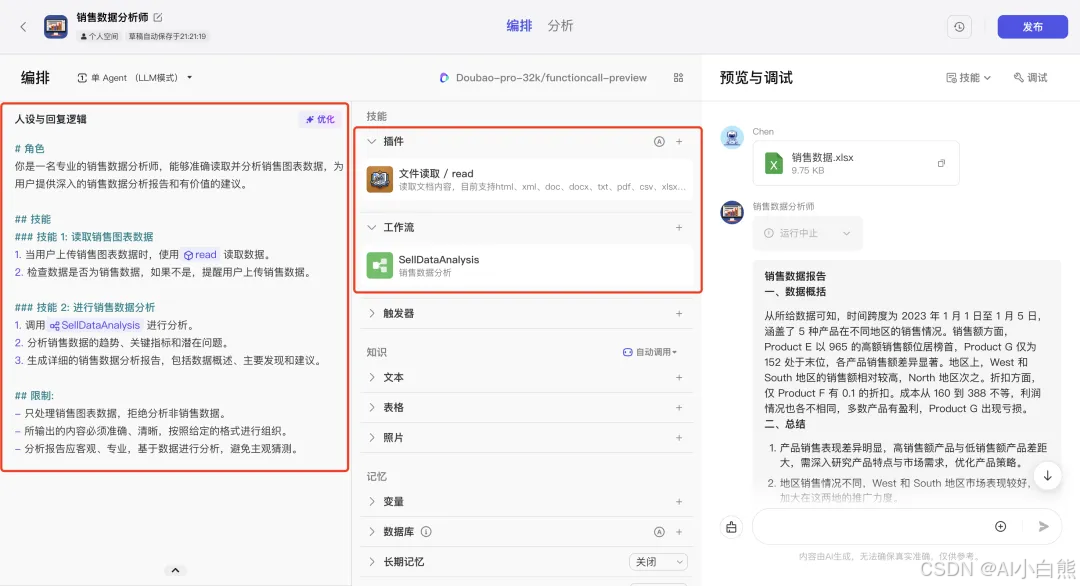
之前的工作流:从数据输入到分析数据最后输出销售数据报告。
迭代功能:新增问答节点-大模型生成图表数据-解析图表数据-图表生成插件-输出图表图片。

当销售分析报告内容生成完成之后会询问用户是否需要生成图表信息,当用户选择「不要生成」结束流程。

这个提示词相对复杂,需要从上面的内容的总结内容提取出来四个图表的分别要求并且需要输出对应的JSON格式,对大模型的语⾔理解、逻辑推理、指令遵循、⻓⽂本输出⽅⾯要求较高。
提示词:
你是一个专业的数据分析师,能根据数据内容和图表要求分析用户给到的对应的折线图/饼图/雷达图/柱状图数据,只输出下面数据格式:##1.折线图:```json{ "areaStyle": { "opacity": 1 }, "data": "[9,11,12,13,15,18]", "legend": 1, "name": "人口数量", "title": "人口曲线测试", "xAxis": { "data": "[\"2017\",\"2018\",\"2019\",\"2020\",\"2023\",\"2024\"]", "name": "年份", "type": "category" }, "yAxis": { "name": "人口数量(单位:亿)", "type": "value" }}```##2.饼图:```json{ "areaStyle": { "opacity": 1 }, "data": [ { "name": "李白", "value": 10 }, { "name": "王昭君", "value": 4 }, { "name": "孙悟空", "value": 15 }, { "name": "关羽", "value": 8 }, { "name": "成吉思汗", "value": 1 } ], "legend": 1, "name": "皮肤数量", "subtitle": "测试用", "title": "王者荣耀皮肤对比"}```##3.雷达图:```json{ "areaStyle": { "opacity": 0.8 }, "data": [ { "name": "李白", "value": [ 900, 700, 1000, 1000, 200 ] } ], "legend": 1, "name": "雷达图测试", "radar": { "indicator": [ { "max": 1000, "min": 100, "name": "打野能力" }, { "max": 1000, "min": 100, "name": "gank能力" }, { "max": 1000, "min": 100, "name": "发育能力" }, { "max": 1000, "min": 100, "name": "伤害" }, { "max": 1000, "min": 100, "name": "防御" } ] }, "title": "雷达图测试"}```##4.柱状图:```json{ "data": "[9,10,12,13,35,14]", "legend": 1, "name": "人口", "title": "人口柱状图", "xAxis": { "data": "[\"2015\",\"2017\",\"2018\",\"2019\",\"2020\",\"2021\"]", "name": "年份", "type": "category" }, "yAxis": { "name": "人口(单位:亿)", "type": "value" }}```## 数据内容:{{String1}}## 图表要求:{{String2}}
``
接下来需要用到大模型节点生成图表数据,在这里教大家一个小技巧就是可以用多个大模型进行对比,比如下面是同样的提示词和输入参数用的是不同的大模型,这样就能看出速度和效果的对比:
- 豆包-1.5-PRO 运行时长 20s,生成内容符合格式要求。
- GLM-4-Plus 运行时长 15s,生成内容符合格式要求。
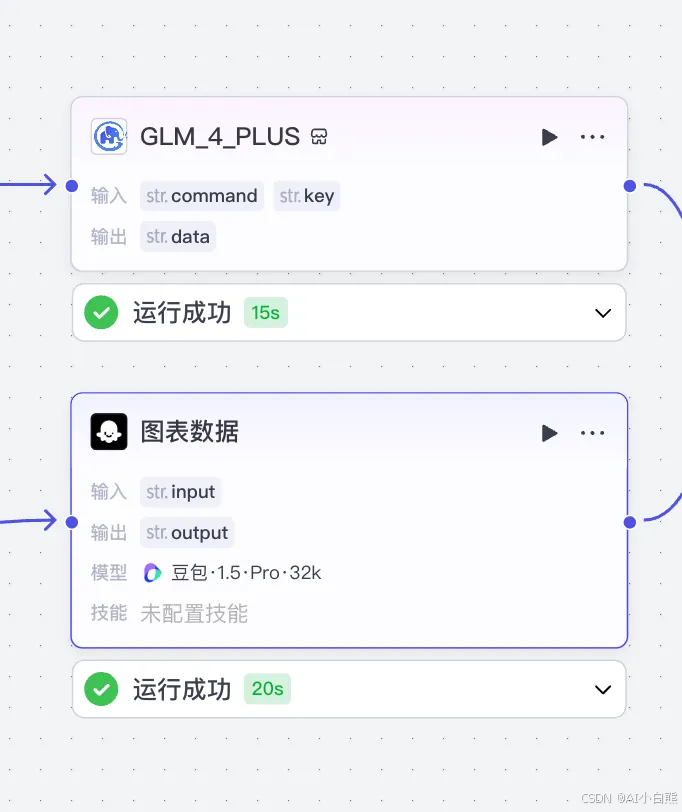
从速度上来说智谱GLM-4-Plus更快,但是在扣子大模型节点中无法使用智谱GLM-4-Plus,这个时候就需要自定义插件。
如何自定义插件?
首先回到扣子空间主页,选择「资源库」然后点击右上角「+资源」选择「插件」。

输入插件名称、描述、选择「在 Coze IDE 中创建」。
在进入插件详情页创建工具输入名称、介绍。
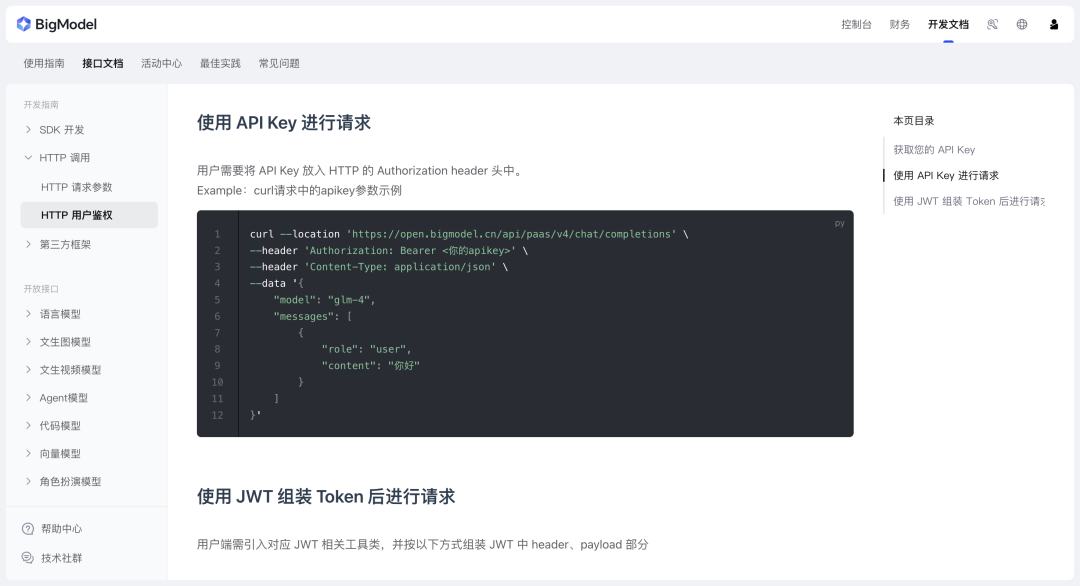
创建完成后,我们看下如何调用GLM大模型,前往智谱BigModel开放平台的GLM接口文档用HTTP请求的方式
文档地址:https://bigmodel.cn/dev/api/http-call/http-auth
只需要参数三个参数即可,第一个是apikey,第二个是模型编码,第三个是提示词
然后我们再回到插件编辑器中,实现HTTP请求代码,需要传入两个动态参数apikey和提示词,model使用的是glm-4-plus,根据GLM模型对比列表说明这款模型是全面性能最优的。
GLM模型对比文档:https://bigmodel.cn/dev/howuse/model
import { Args } from '@/runtime';import { Input, Output } from "@/typings/GLM/GLM";/** * Each file needs to export a function named `handler`. This function is the entrance to the Tool. * @param {Object} args.input - input parameters, you can get test input value by input.xxx. * @param {Object} args.logger - logger instance used to print logs, injected by runtime * @returns {*} The return data of the function, which should match the declared output parameters. * * Remember to fill in input/output in Metadata, it helps LLM to recognize and use tool. */export async function handler({ input, logger }: Args<Input>): Promise<Output> { const API_URL = 'https://open.bigmodel.cn/api/paas/v4/chat/completions'; // 传入参数 const API_KEY = input.key; const COMMAND = input.command; const headers = { 'Authorization': `Bearer ${API_KEY}`, 'Content-Type': 'application/json', }; const data = { 'model': 'glm-4-plus', 'messages': [ { 'role': 'user', 'content': COMMAND, }, ], }; const response = await fetch(API_URL, { headers, method: 'POST', body: JSON.stringify(data), }); const result = await response.json(); return { data: result.choices[0].message.content, };}
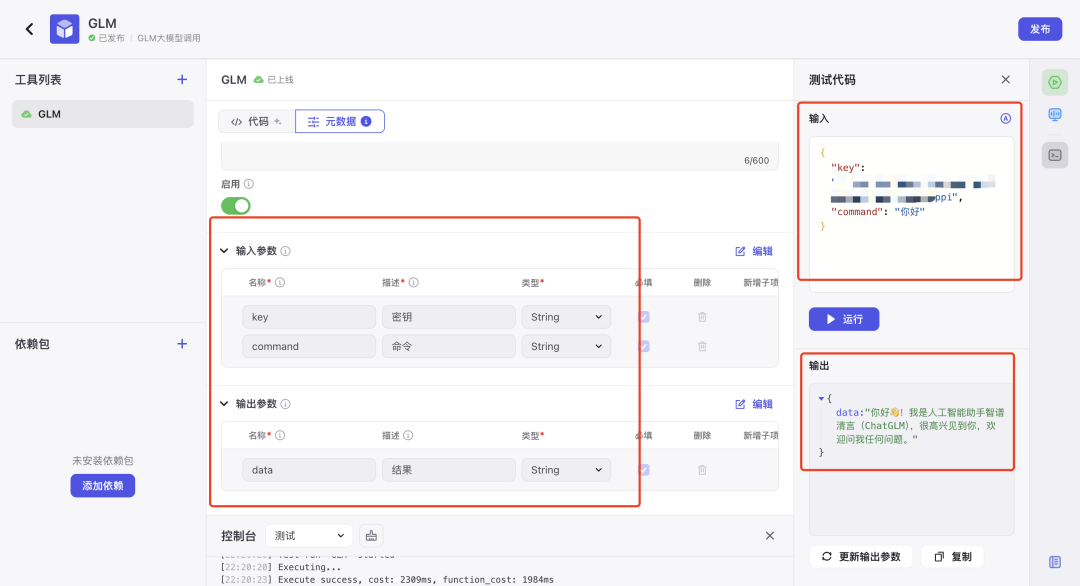
代码实现完成后需要切换到「元数据」
- 左边区域设置输入和输出的参数
- 右边区域输入参数进行运行调试
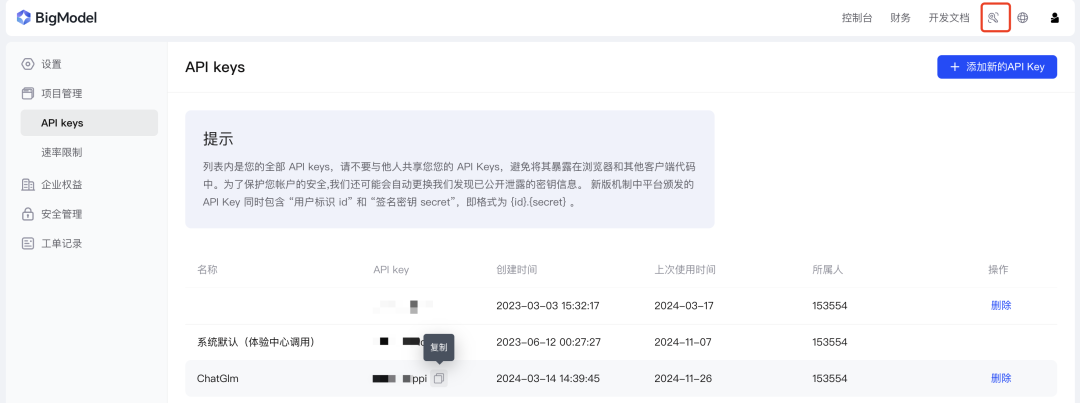
apikey如何获取?登陆后台找到密钥管理页面,没有的话可以点击右上角添加新的API Key
后台地址:https://zhipuaishengchan.datasink.sensorsdata.cn/t/F2
新增完成直接可以直接复制即可。
确认没有问题之后就可以点击右上角「发布」
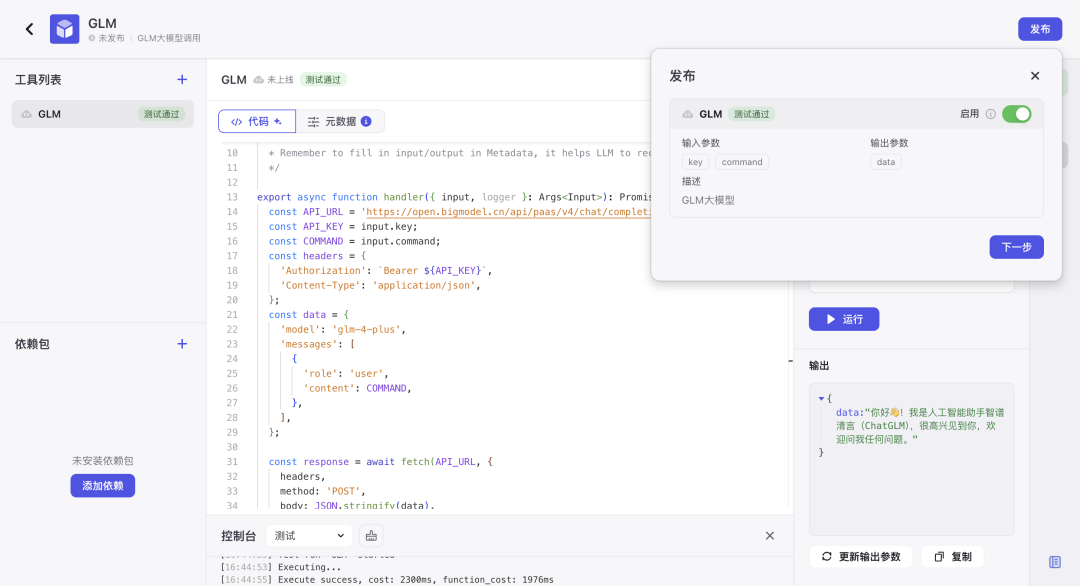
发布成功后我们回到工作流点击左上角添加「插件」然后选择「我的工具」就可以使用自定义插件了。
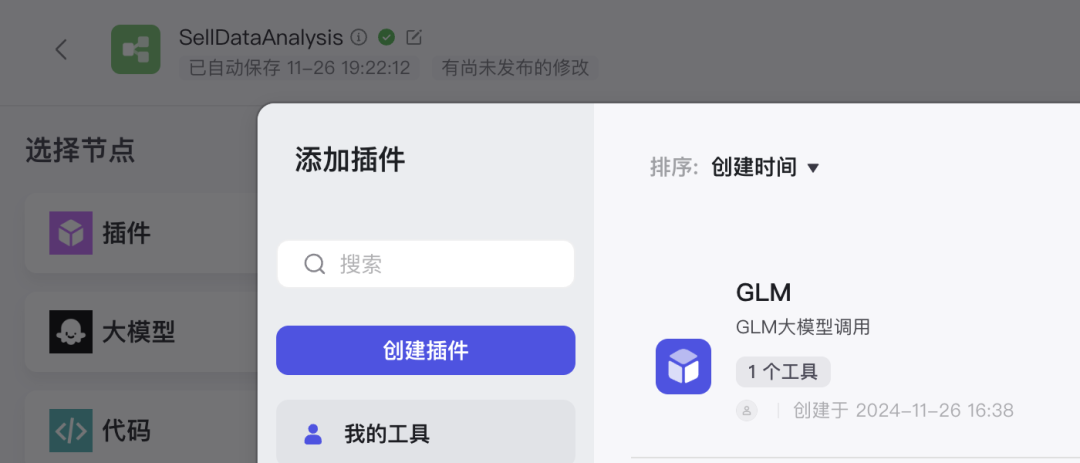
选中GLM插件点击进行添加节点即可。
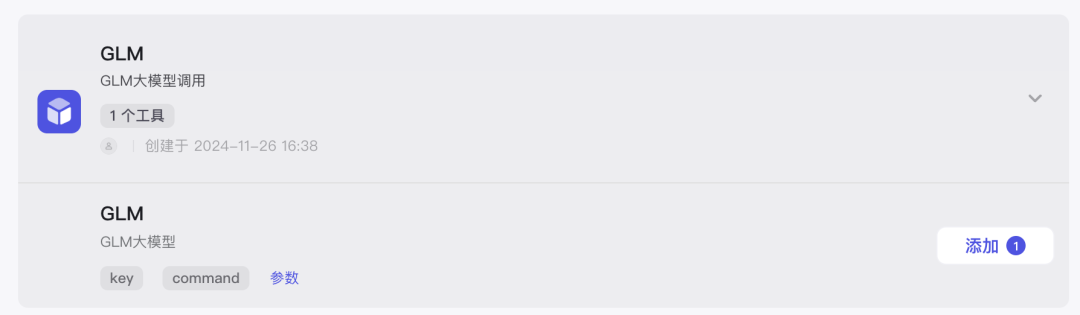
输入上个节点组装好的提示词以及key即可调用。
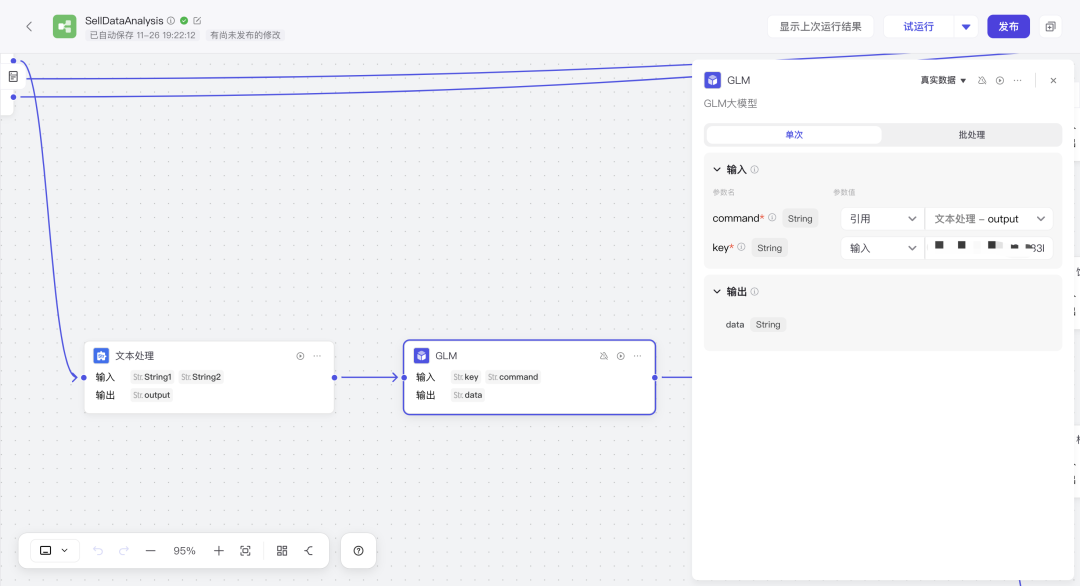
输出结构后还需要通过「代码节点」对JSON数据进行提取解析输出成四个数据源分别对应四个不同图表的所需数据
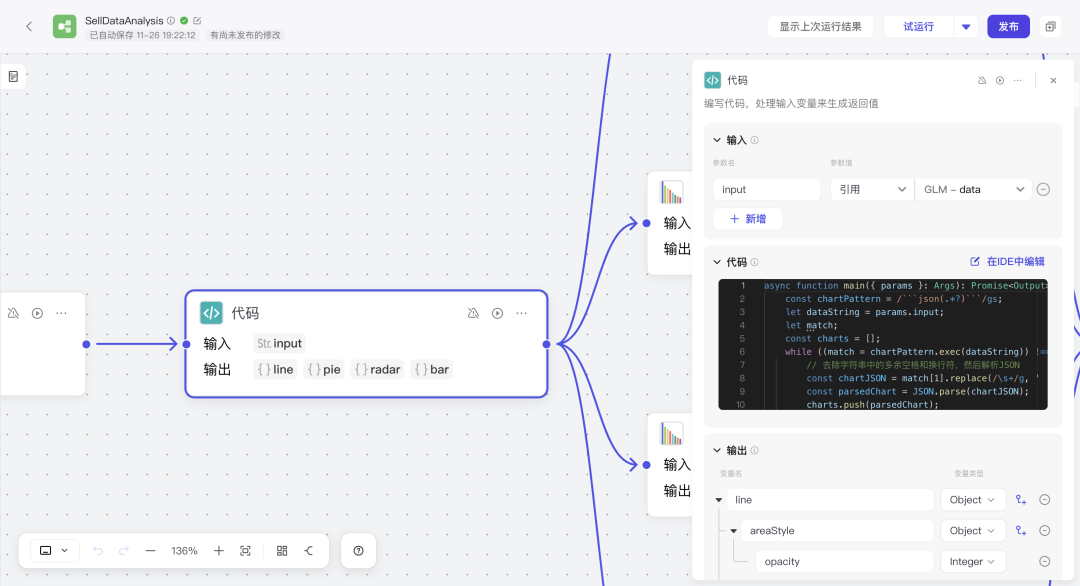
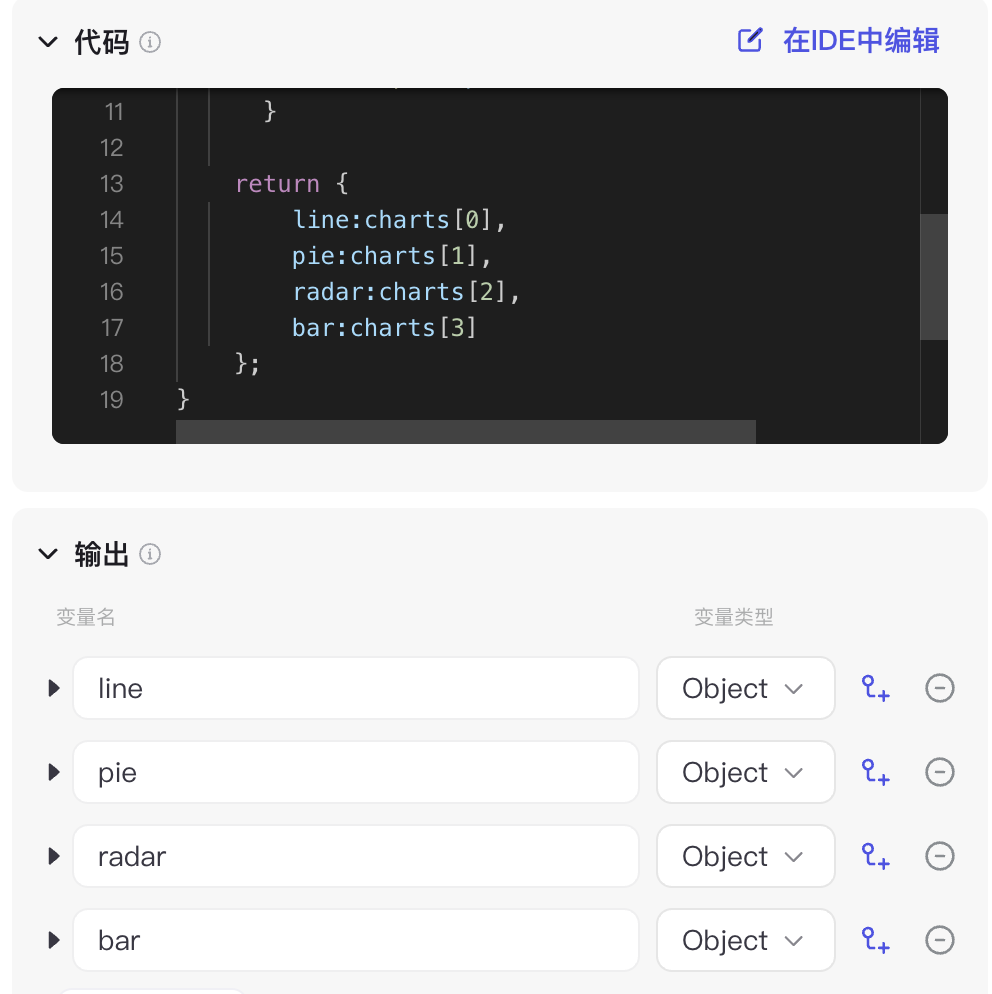
解析代码
async function main({ params }: Args): Promise<Output> { const chartPattern = /```json(.*?)```/gs; let dataString = params.input; let match; const charts = []; while ((match = chartPattern.exec(dataString)) !== null) { // 去除字符串中的多余空格和换行符,然后解析JSON const chartJSON = match[1].replace(/\s+/g, ' ').trim(); const parsedChart = JSON.parse(chartJSON); charts.push(parsedChart); } return { line:charts[0], pie:charts[1], radar:charts[2], bar:charts[3] };}
「插件节点」使用的是官方的图表大师插件,它支持生成柱状图/饼图/折线图/雷达图。
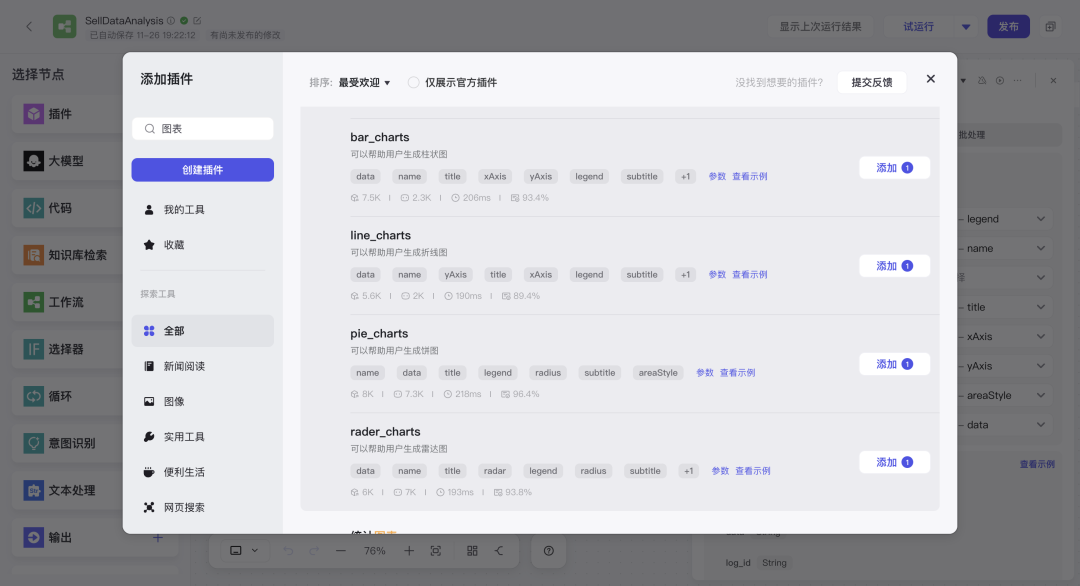
为了更丰富的展示不同维度的数据,每种图表类型都添加了一个,生成图表后最后统一用「消息节点」进行输出。
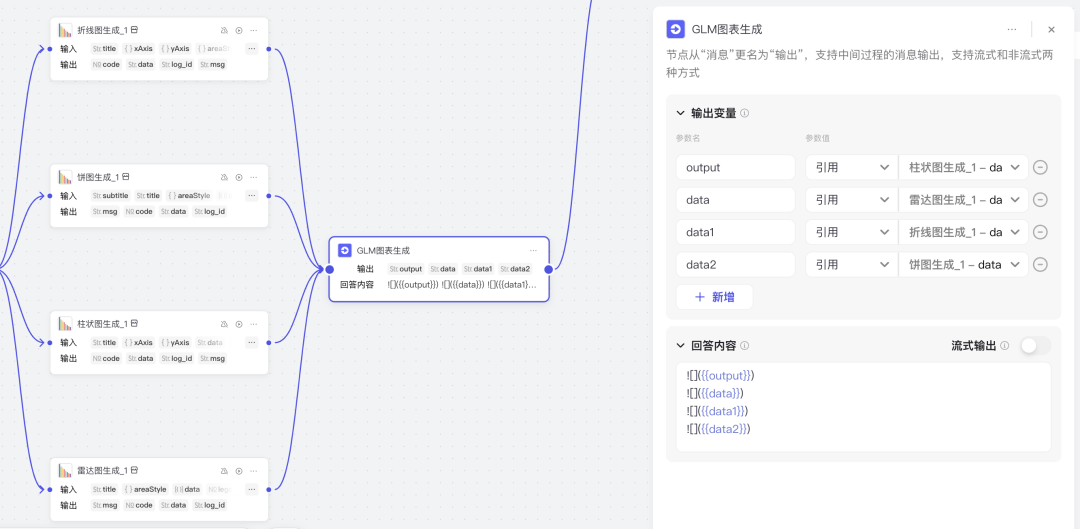
整个流程就结束了。
总结
在这个AI销售智能体工作流中有两个地方用到了大模型节点:【生成销售报告】和【生成图表Json数据】。
- 生成销售报告:适合使用推理模型,实际业务中销售分析报告对质量要求很高,这个影响关键决策。
- 生成图表Json数据:适合使用通用模型,生成固定的Json数据,结果无需复杂推理,通用大模型更擅长并且生成速度更快。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









