






前言
本文首先分析微调脚本trainer.sh的内容,再剖析ChatGLM是如何与Huggingface平台对接,实现transformers库的API直接调用ChatGLM模型,最后定位到了ChatGLM模型的源码文件。
脚本分析
微调脚本:
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path THUDM/chatglm-6b \
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
脚本配置项分析:
PRE_SEQ_LEN=128: 定义了序列长度为128。这个参数通常用于设置输入序列的最大长度。LR=2e-2: 定义了学习率为0.02。学习率是模型训练中的一个重要超参数,它决定了模型参数更新的幅度。CUDA_VISIBLE_DEVICES=0: 这个环境变量用于设置哪些GPU将被TensorFlow框架使用。在这个脚本中,只使用了第一个GPU(索引为0)。python3 main.py: 这一行开始执行主训练脚本main.py。--do_train: 这个标志告诉脚本执行训练过程。--prompt_column content: 这个标志指定了输入列的名称,这里称为content。这是模型接收的输入列的名称。--response_column summary: 这个标志指定了输出列的名称,这里称为summary。这是模型需要生成的输出列的名称。--model_name_or_path THUDM/ChatGLM-6b: 这个标志指定了预训练模型的名称或路径。这里使用的是名为THUDM/ChatGLM-6b的预训练模型。--output_dir output/adgen-ChatGLM-6b-pt-$PRE_SEQ_LEN-$LR: 这个标志指定了输出目录。目录名为output/adgen-ChatGLM-6b-pt-128-0.02,其中128和0.02分别由 P R E _ S E Q _ L E N 和 PRE\_SEQ\_LEN和 PRE_SEQ_LEN和LR变量替换。--per_device_train_batch_size 1: 这个标志设置了每个设备上的训练批次大小为1。--per_device_eval_batch_size 1: 这个标志设置了每个设备上的评估批次大小为1。--gradient_accumulation_steps 16: 这个标志设置了梯度累积的步数为16。这意味着在每个更新步骤中,会将最近16个步骤的梯度相加。--max_steps 3000: 这个标志设置了训练过程中的最大步数为3000。--save_steps 1000: 这个标志设置了保存模型检查点的步数为1000。这意味着每1000个步骤后,将保存一次模型的状态。--learning_rate $LR: 这个标志设置了学习率为之前定义的LR变量(0.02)。--pre_seq_len $PRE_SEQ_LEN: 这个标志设置了序列长度为之前定义的PRE_SEQ_LEN变量(128)。
在官方的微调文档中,用的是ADGEN数据集,其格式也就是上述的--prompt_column content和--response_column summary配置项决定的。而最终保存在output_dir配置项指定的目录下有多个checkpoint文件,其生成频率就是由save_steps配置项决定。
main.py
main文件中,依赖了trainer_seq2seq.py,而这又依赖了trainer.py文件。trainer.py文件则是直接copy自transformers库的同名文件。
transformers库的
目前的大模型都会对接到transformers库中,通过transformers库简化调用开发。AI模型的对接,遵循HuggingFace平台的要求。整个ChatGLM系列的推理、训练、微调都可以直接调用transformers库的API。常用的是如下三句:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
huggingface平台与ChatGLM
在ChatGLM的部署过程中,需要在huggingface平台上下载模型参数以及配置初始化文件。而这些配置文件,transformers库的API能够调用的原因。
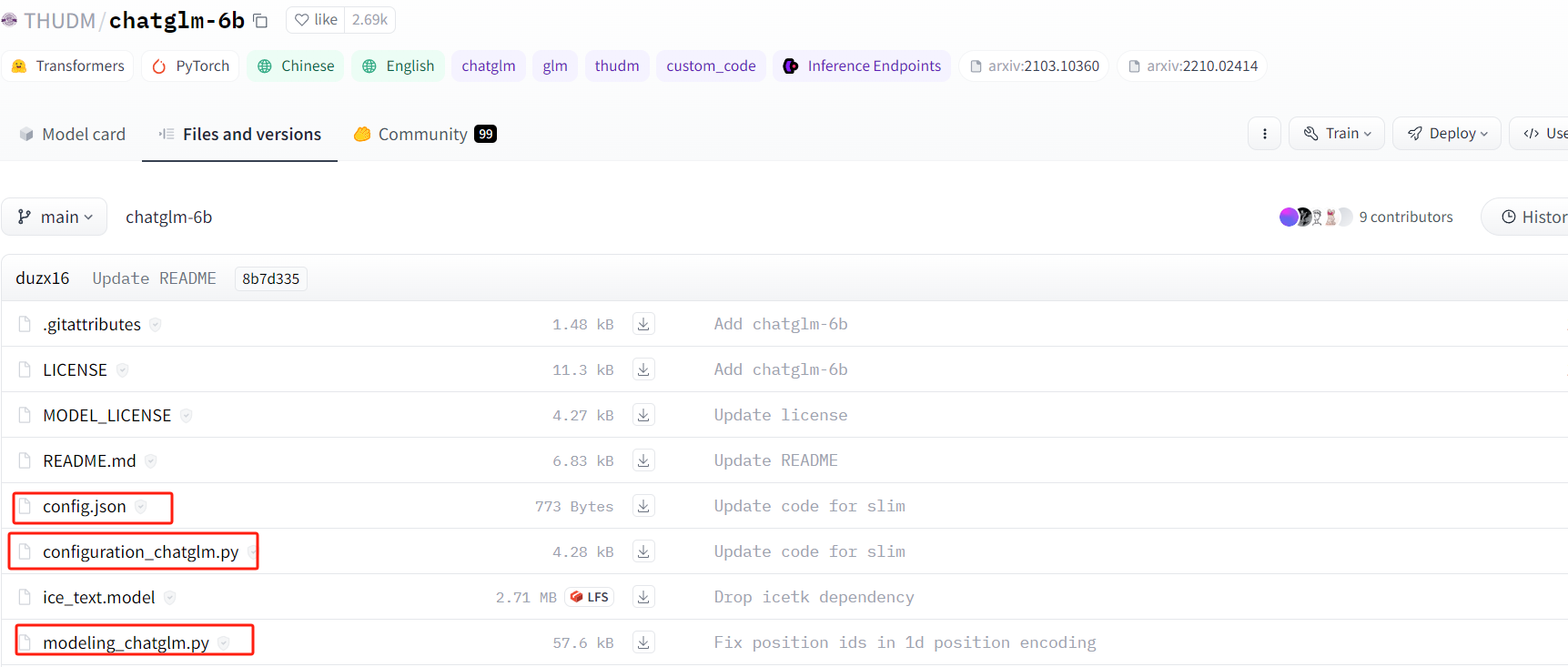

比较重要的,就是圈出来的三个。config.json文件中,配置了模型的基本信息以及transformers API的调用关系:
{
"_name_or_path": "THUDM/chatglm-6b",
"architectures": [
"ChatGLMModel"
],
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration"
},
"bos_token_id": 130004,
"eos_token_id": 130005,
"mask_token_id": 130000,
"gmask_token_id": 130001,
"pad_token_id": 3,
"hidden_size": 4096,
"inner_hidden_size": 16384,
"layernorm_epsilon": 1e-05,
"max_sequence_length": 2048,
"model_type": "chatglm",
"num_attention_heads": 32,
"num_layers": 28,
"position_encoding_2d": true,
"torch_dtype": "float16",
"transformers_version": "4.23.1",
"use_cache": true,
"vocab_size": 130528
}
如上的auto_map配置项。configuration_chatglm文件是该config文件的类表现形式。
modeling_chatglm.py文件是源码文件,ChatGLM对话模型的所有源码细节都在该文件中。我之前一直没找到ChatGLM的源码,就是神经网络的相关代码,经过一波的分析,终于是定位到了。所以在config文件中会配置AutoModel API直接取调用modeling_chatglm.ChatGLMForConditionalGeneration。
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 892
892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









