






前言
本篇文章我们将基于Ollama本地运行大语言模型(LLM),并结合ChormaDB、Langchain来建立一个小型的基于网页内容进行本地问答的RAG应用。
概念介绍
先简单了解下这些术语:
LLM (A large language model) 是通过使用海量的文本数据集(书籍、网站等)训练出来的,具备通用语言理解和生成的能力。虽然它可以推理许多内容,但它们的知识仅限于特定时间点之前用于训练的数据。
[LangChain] 是一个用于开发由大型语言模型(LLM)驱动的应用程序的框架。提供了丰富的接口、组件、能力简化了构建LLM应用程序的过程。
[Ollama] 是一个免费的开源框架,可以让大模型很容易的运行在本地电脑上。
RAG(Retrieval Augmented Generation)是一种利用额外数据增强 LLM 知识的技术,它通过从外部数据库获取当前或相关上下文信息,并在请求大型语言模型(LLM)生成响应时呈现给它,从而解决了生成不正确或误导性信息的问题。
工作流程图解如下:
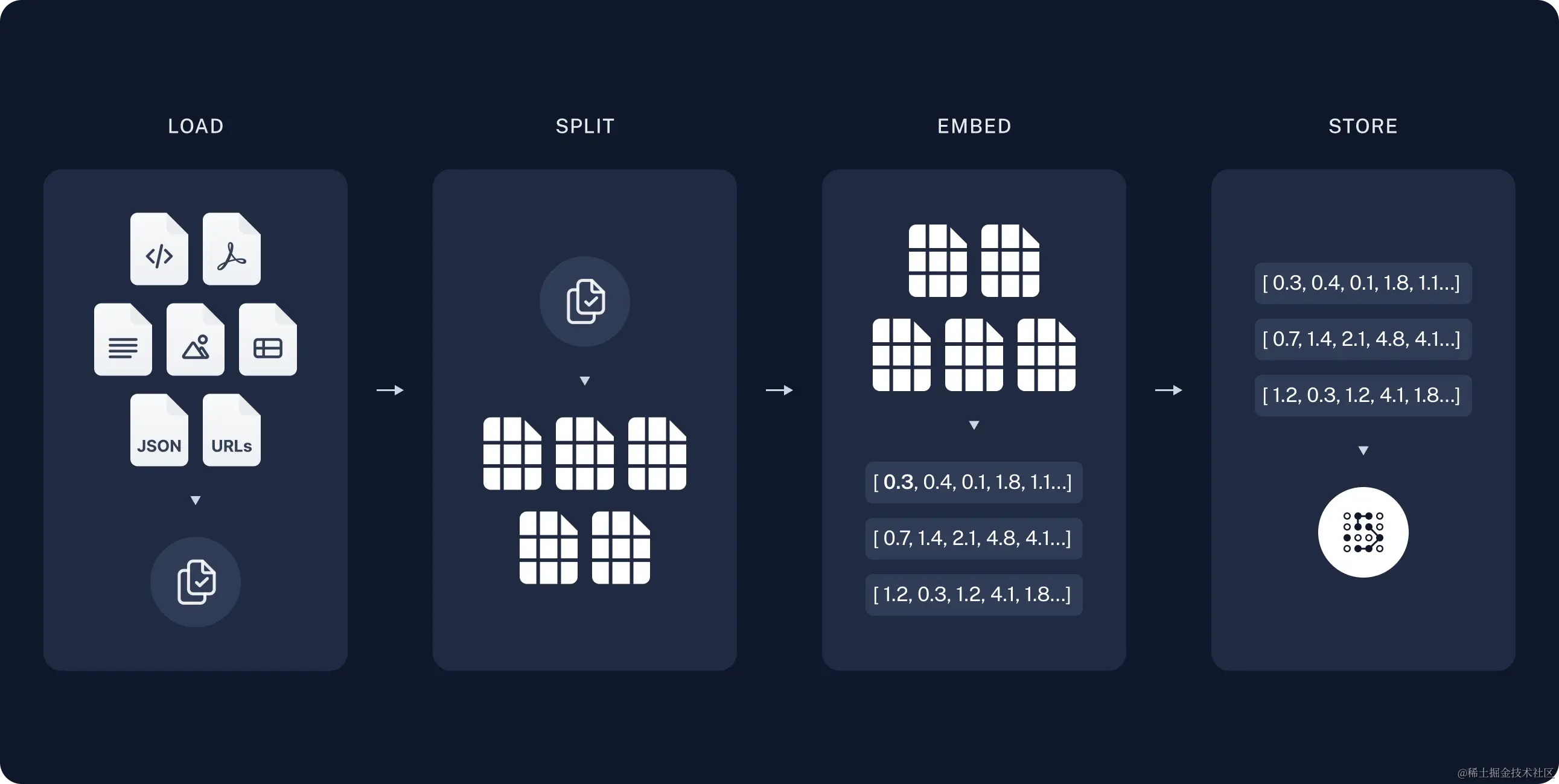
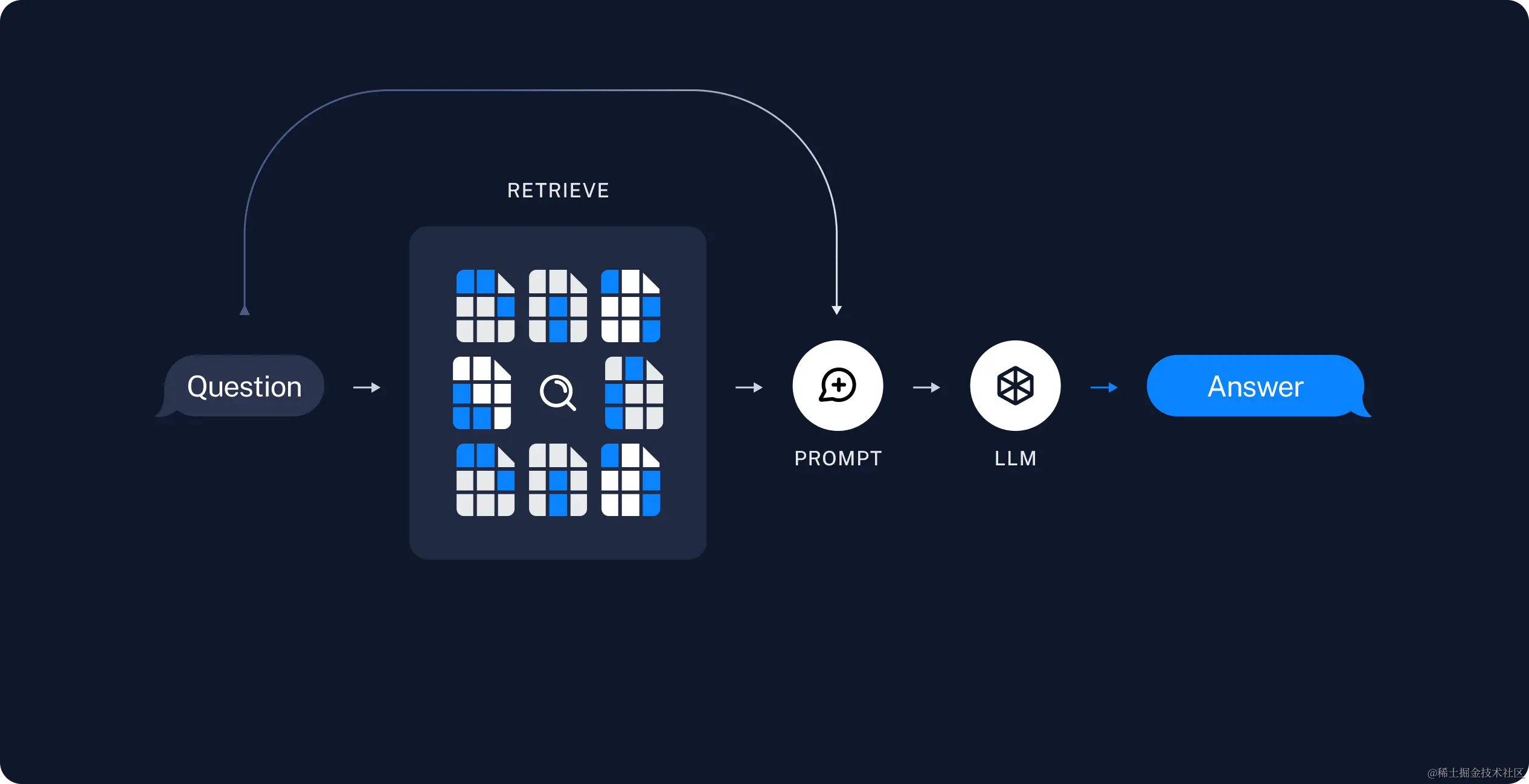
基于上述RAG步骤,接下来我们将使用代码完成它。
开始搭建
1. 依据Ollama使用指南完成大模型的本地下载和的运行。
# LLM
ollama pull llama3
# Embedding Model
ollama pull nomic-embed-text
2. 安装langchain、langchain-community、bs4
pip install langchain langchain-community bs4
3. 初始化langchain提供的Ollama对象
from langchain_community.llms import Ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# 1. 初始化llm, 让其流式输出
llm = Ollama(model="llama3",
temperature=0.1,
top_p=0.4,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()])
)
temperature控制文本生成的创造性,为0时响应是可预测,始终选择下一个最可能的单词,这对于事实和准确性非常重要的答案是非常有用的。为 1时生成文本会选择更多的单词,会产生更具创意但不可能预测的答案。
top_p 或 核心采样 决定了生成时要考虑多少可能的单词。高top_p值意味着模型会考虑更多可能的单词,甚至是可能性较低的单词,从而使生成的文本更加多样化。
较低的temperature和较高的top_p,可以产生具有创意的连贯文字。 由于temperature较低,答案通常具有逻辑性和连贯性,但由于top_p较高,答案仍然具有丰富的词汇和观点。比较适合生成信息类文本,内容清晰且能吸引读者。
较高的temperature和较低的top_p,可能会把单词以难以预测的方式组合在一起。 生成的文本创意高,会出现意想不到的结果,适合创作。
4. 获取RAG检索内容并分块
#`BeautifulSoup'解析网页内容:按照标签、类名、ID 等方式来定位和提取你需要的内容
import bs4
#Load HTML pages using `urllib` and parse them with `BeautifulSoup'
from langchain_community.document_loaders import WebBaseLoader
#文本分割
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader(
web_paths=("https://vuejs.org/guide/introduction.html#html",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("content",),
# id=("article-root",)
)
),
)
docs = loader.load()
# chunk_overlap:分块的重叠部分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
chunk_overlap:分块的重叠部分,重叠有助于降低将语句与与其相关的重要上下文分开的可能性。 chunk_size: 分块的大小,合理的分词设置会提高RAG的效果
- 内容基于本地的词嵌入模型
nomic-embed-text嵌入向量数据库中
# 向量嵌入 ::: conda install onnxruntime -c conda-forge
from langchain_community.vectorstores import Chroma
# 有许多嵌入模型
from langchain_community.embeddings import OllamaEmbeddings
# 基于ollama运行嵌入模型 nomic-embed-text : A high-performing open embedding model with a large token context window.
vectorstore = Chroma.from_documents(documents=splits,
embedding=OllamaEmbeddings(model="nomic-embed-text"))
# 相似搜索
# vectorstore.similarity_search("vue")
此处的嵌入模型也可以使用其他的比如llama3、mistral,但是在本地运行太慢了,它们和nomic-embed-text 一样不支持中文的词嵌入。如果想试试建立一个中文的文档库,可以试试 herald/dmeta-embedding-zh词嵌入的模型,支持中文。
ollama pull herald/dmeta-embedding-zh:latest
- 设置
Prompt规范输出
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate(
input_variables=['context', 'question'],
template=
"""You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the
question. you don't know the answer, just say you don't know
without any explanation Question: {question} Context: {context} Answer:""",
)
- 基于
langchain实现检索问答
from langchain.chains import RetrievalQA
# 向量数据库检索器
retriever = vectorstore.as_retriever()
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=retriever,
chain_type_kwargs={"prompt": prompt}
)
# what is Composition API?
question = "what is vue?"
result = qa_chain.invoke({"query": question})
# output
# I think I know this one! Based on the context,
# Vue is a JavaScript framework for building user interfaces
# that builds on top of standard HTML, CSS, and JavaScript.
# It provides a declarative way to use Vue primarily in
# low-complexity scenarios or for building full applications with
# Composition API + Single-File Components.
如果我问的问题与文档无关它的回答是怎样呢?
question = "what is react?"
result = qa_chain.invoke({"query": question})
最终执行后输出了I don't know.。
构建用户界面
Gradio是一个用于构建交互式机器学习界面的Python库。Gradio使用非常简单。你只需要定义一个有输入和输出的函数,然后Gradio将自动为你生成一个界面。用户可以在界面中输入数据,然后观察模型的输出结果。
整合上述代码,构建可交互的UI:
import gradio as gr
from langchain_community.llms import Ollama
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import OllamaEmbeddings
from langchain.chains import RetrievalQA
from langchain_core.prompts import PromptTemplate
def init_ollama_llm(model, temperature, top_p):
return Ollama(model=model,
temperature=temperature,
top_p=top_p,
callback_manager=CallbackManager([StreamingStdOutCallbackHandler()])
)
def content_web(url):
loader = WebBaseLoader(
web_paths=(url,),
)
docs = loader.load()
# chunk_overlap:分块的重叠部分,重叠有助于降低将语句与与其相关的重要上下文分开的可能性,
# 设置了chunk_overlap效果会更好
# 合理的分词会提高RAG的效果
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
return splits
def chroma_retriever_store_content(splits):
# 基于ollama运行嵌入模型 nomic-embed-text : A high-performing open embedding model with a large token context window.
vectorstore = Chroma.from_documents(documents=splits,
embedding=OllamaEmbeddings(model="nomic-embed-text"))
return vectorstore.as_retriever()
def rag_prompt():
return PromptTemplate(
input_variables=['context', 'question'],
template=
"""You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the
question. you don't know the answer, just say you don't know
without any explanation Question: {question} Context: {context} Answer:""",
)
def ollama_rag_chroma_web_content(web_url, question,temperature,top_p):
llm = init_ollama_llm('llama3', temperature, top_p)
splits = content_web(web_url)
retriever = chroma_retriever_store_content(splits)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=retriever, chain_type_kwargs={"prompt": rag_prompt()})
return qa_chain.invoke({"query": question})["result"]
demo = gr.Interface(
fn=ollama_rag_chroma_web_content,
inputs=[gr.Textbox(label="web_url",value="https://vuejs.org/guide/introduction.html",info="爬取内容的网页地址"),
"text",
gr.Slider(0, 1,step=0.1),
gr.Slider(0, 1,step=0.1)],
outputs="text",
title="Ollama+RAG Example",
description="输入网页的URL,然后提问, 获取答案"
)
demo.launch()
运行后会输出网页地址Running on local URL: http://127.0.0.1:7860, 打开后效果如下: 
那么,我们该如何学习大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









