






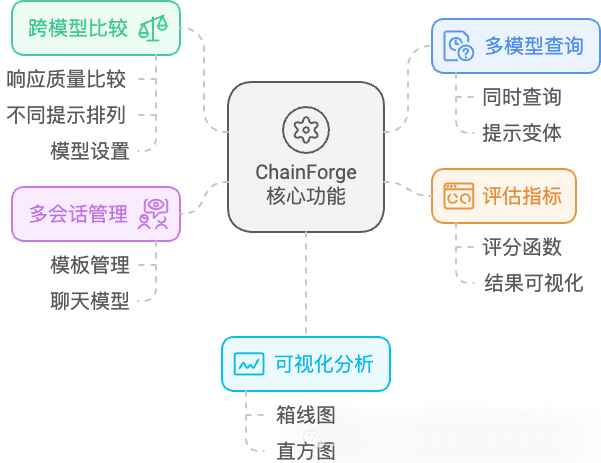
在人工智能和自然语言处理领域,大型语言模型(LLM)的兴起为各行各业带来了巨大变革。然而,如何有效地评估和优化这些模型的输出一直是一个挑战。为了解决这个问题,来自哈佛大学人机交互实验室的研究人员开发了ChainForge - 一个开源的可视化工具包,旨在简化提示词工程及评估测试的过程。
核心功能
ChainForge 的设计理念是提升提示工程和 LLM 评估的直观性和效率。其主要功能包括:
-
• 多模型同时查询:用户可以同时向多个大模型发送请求,快速对比不同模型的效果。
-
• 跨模型比较:支持在不同提示排列、模型和模型设置之间比较响应质量,帮助用户为特定用例选择最佳提示词和模型。
-
• 评估指标设置:用户可以设置评估的函数,并支持可视化展示评估结果。
-
• 多会话管理:支持跨模板参数和聊天模型进行多个对话,用户不仅可以模板化提示,还可以模板化后续的聊天消息。
-
• 可视化分析:提供直观的可视化工具,如用于数值指标的分组箱线图和用于布尔指标的直方图,帮助用户更好地理解评估结果。
安装方法
推荐在python venv虚拟环境中安装.
pip install chainforge
启动方式:
执行 chainforge serve
Serving Flask server on localhost on port 8000...
* Serving Flask app 'chainforge.flask_app'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://localhost:8000
然后在 Chrome、Firefox或Edge 浏览器中打开 http://localhost:8000
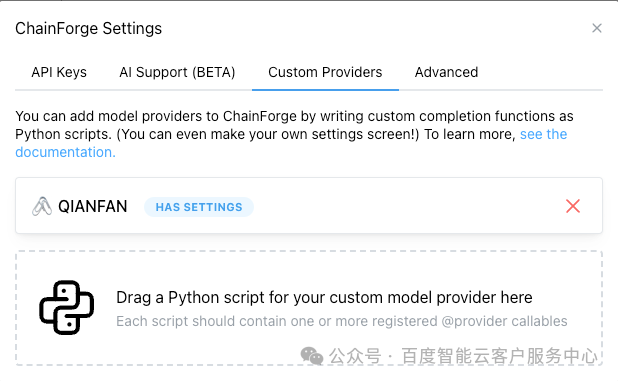
添加千帆大模型
import os
import qianfan
import json
from chainforge.providers import provider
os.environ["QIANFAN_ACCESS_KEY"] = ""
os.environ["QIANFAN_SECRET_KEY"] = ""
COHERE_SETTINGS_SCHEMA = {
"settings": {
"temperature": {
"type": "number",
"title": "temperature",
"description": "温度.",
"default": 0.80,
"minimum": 0,
"maximum": 1.0,
"multipleOf": 0.01,
},
"system": {
"type": "string",
"title": "system",
"description": "系统人设.",
"default": "",
},
"disable_search": {
"type": "boolean",
"title": "disable_search",
"description": "是否强制关闭实时搜索功能.",
"default": True,
},
},
"ui": {
"temperature": {
"ui:help": "Defaults to 0.80. 较高的数值会使输出更加随机,而较低的数值会使其更加集中和确定",
"ui:widget": "range"
},
"system": {
"ui:widget": "textarea"
},
"disable_search": {
"ui:widget": "radio"
}
}
}
@provider(name="QIANFAN",
emoji="🖇",
models=list(qianfan.ChatCompletion().models()),
settings_schema=COHERE_SETTINGS_SCHEMA,
)
def QianfanCompletion(prompt: str, model: str, chat_history=None, temperature: float = 0.80, **kwargs) -> str:
chat_comp = qianfan.ChatCompletion()
print(f"Calling qianfan model {model} with prompt '{prompt}'...")
messages = []
if chat_history:
for item in chat_history:
role = item['role']
content = item['content']
if role != 'user':
content = json.loads(content.lstrip('\\').replace('\\{', '{').replace('\\}', '}')).get('result')
messages.append({"role": role, "content": content})
messages.append({"role": "user", "content": prompt})
print(f"messages: {messages}")
resp = chat_comp.do(model=model, messages=messages, temperature=temperature, **kwargs)
result = resp['body']
# 格式化历史消息,一并输出到结果中
last_text = [f"{'user' if item['role'] == 'user' else model}: {item['content']}" for item in messages]
result['history'] = '\n\n'.join(last_text) + f"\n\n{model}: {resp['body']['result']}"
return json.dumps(result, ensure_ascii=False)
上述python内容保存为文件拖入即可
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈

快速使用
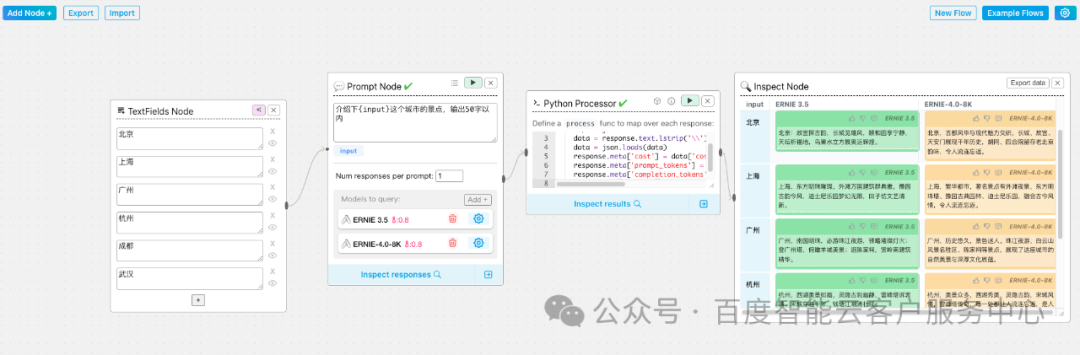
Chainforge可以很方便的通过可视化的方法编辑工作流
示例:对比ERNIE3.5和ERNIE 4.0在同一提示词场景下的效果
主要支持的节点如下:
- • Tabular Data Node
支持导入excel文件进行批量测试,选择对应的列作为参数传入到prompt中
- • TextFields Node
文本输入,支持同时输入多个文本内容传入到prompt
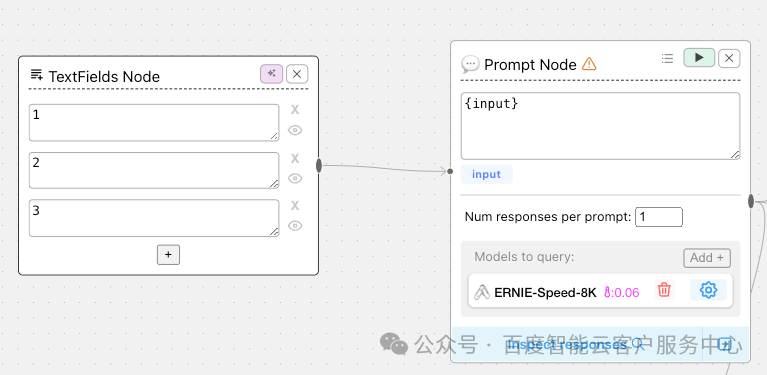
- • Prompt Node
提示词节点,提示词支持变量,变量使用{}表示,如果提示词中{}需要转义,使用 \ 即可
可以选择多个模板同时执行
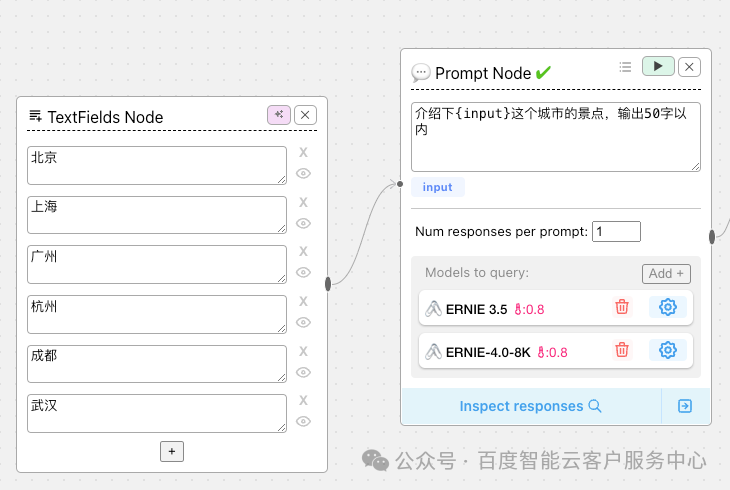
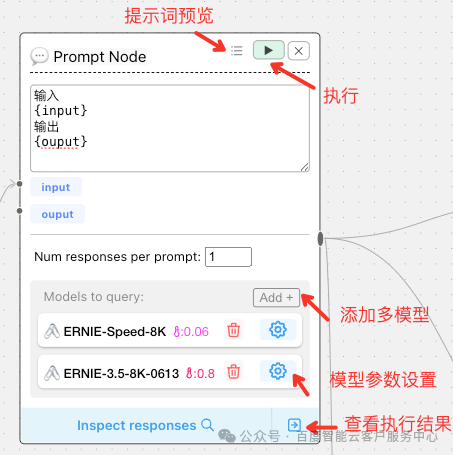
运行完成后,点击Inspect responses 即可查看结果
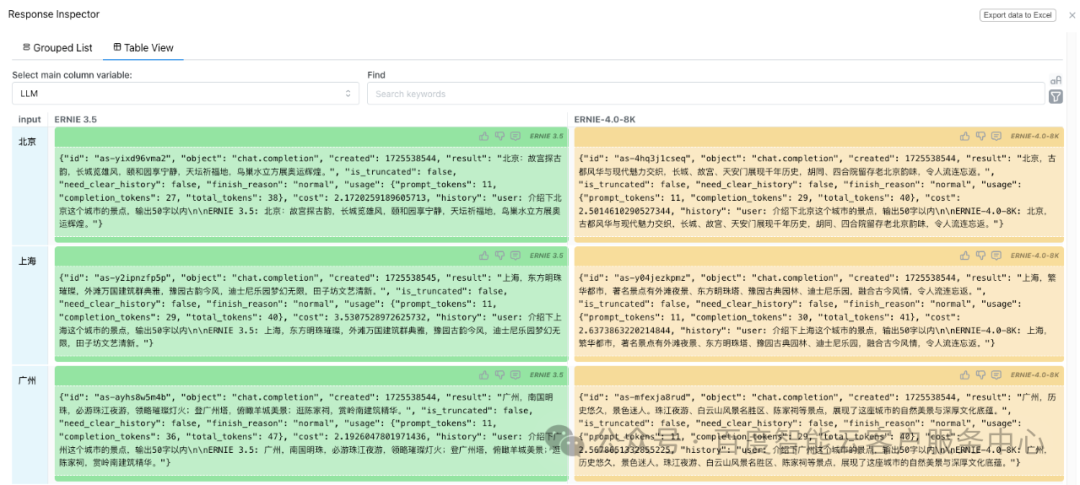
- • Inspect Node
查看结果,支持手动标注结果及导出execl
Processor Node
代码处理节点,支持编写代码对输入输出进行处理,例如对response提取指定参数等
示例:对响应内容的格式进行处理,只提取结果等。
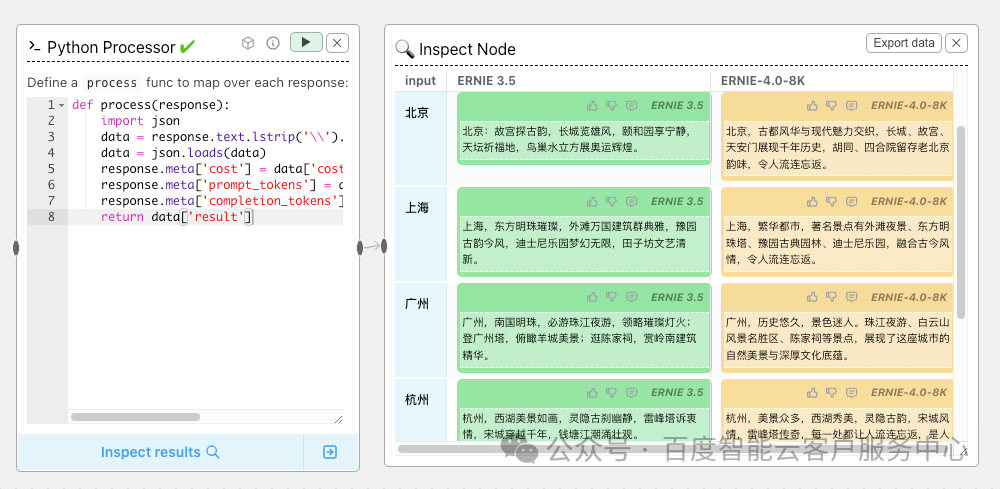
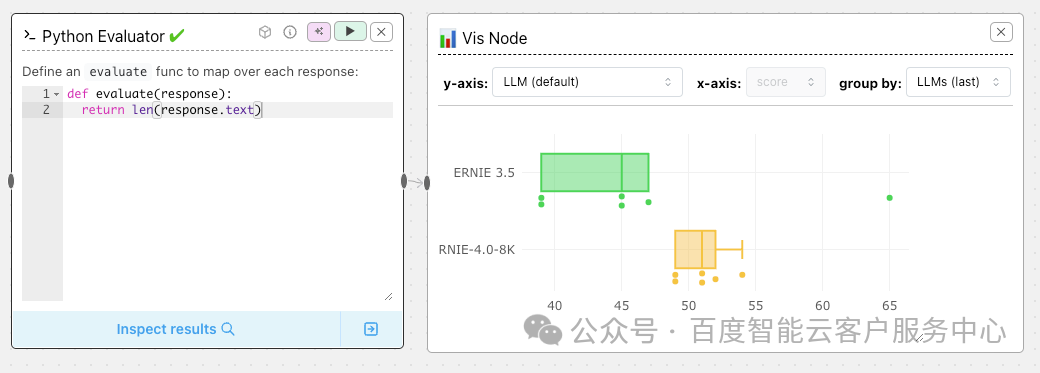
Evaluator Node
评估节点,支持编写JS、Python代码执行对比评估,可以根据自身需求定制评估函数,例如相似度计算、格式校验等等,代码也是本地环境中执行,可以按需在自己的环境中安装第三方库。
示例:对输出的文本长度进行比较,可以很直观的对比不同模型的表现。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}