






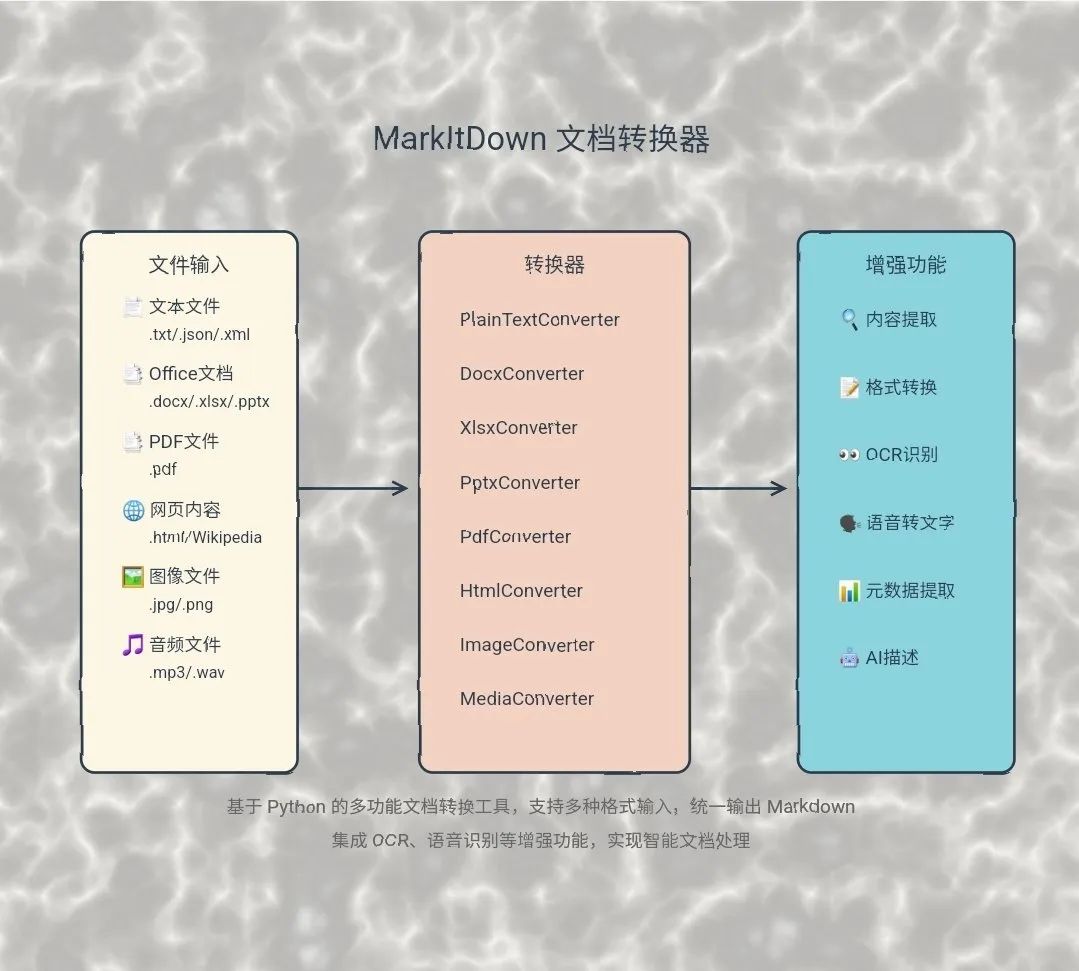
RAG有这么一个说法:“垃圾进,垃圾出”,文档解析与处理以获取高质量数据至关重要。近期,微软开源了MarkItDown,一款将各种文件转换为 Markdown 的实用程序(用于索引、文本分析等)。
https://x.com/shao__meng/status/1867348058662744236
MarkItDown支持:
-
PDF
-
PPT
-
Word
-
Excel
-
图像(EXIF 元数据和 OCR)
-
音频(EXIF 元数据和语音转录)
-
HTML
-
基于文本的格式(CSV、JSON、XML)
-
ZIP 文件
MarkItDown使用
使用 pip: pip install markitdown。或者,从源代码安装它:pip install -e .
Python中的基本用法:
from markitdown import MarkItDown` `md = MarkItDown() result = md.convert("test.xlsx")` `print(result.text_content)
要使用大型语言模型进行图像描述,请提供llm_client和llm_model:
from markitdown import MarkItDown` `from openai import OpenAI client = OpenAI()` `md = MarkItDown(llm_client=client, llm_model="gpt-4o")` `result = md.convert("example.jpg") print(result.text_content)
MarkItDown试用
https://www.html.zone/markitdown/
https://github.com/microsoft/markitdown
零基础如何学习AI大模型
领取方式在文末
为什么要学习大模型?
学习大模型课程的重要性在于它能够极大地促进个人在人工智能领域的专业发展。大模型技术,如自然语言处理和图像识别,正在推动着人工智能的新发展阶段。通过学习大模型课程,可以掌握设计和实现基于大模型的应用系统所需的基本原理和技术,从而提升自己在数据处理、分析和决策制定方面的能力。此外,大模型技术在多个行业中的应用日益增加,掌握这一技术将有助于提高就业竞争力,并为未来的创新创业提供坚实的基础。
大模型典型应用场景
①AI+教育:智能教学助手和自动评分系统使个性化教育成为可能。通过AI分析学生的学习数据,提供量身定制的学习方案,提高学习效果。
②AI+医疗:智能诊断系统和个性化医疗方案让医疗服务更加精准高效。AI可以分析医学影像,辅助医生进行早期诊断,同时根据患者数据制定个性化治疗方案。
③AI+金融:智能投顾和风险管理系统帮助投资者做出更明智的决策,并实时监控金融市场,识别潜在风险。
④AI+制造:智能制造和自动化工厂提高了生产效率和质量。通过AI技术,工厂可以实现设备预测性维护,减少停机时间。
…
这些案例表明,学习大模型课程不仅能够提升个人技能,还能为企业带来实际效益,推动行业创新发展。
学习资料领取
如果你对大模型感兴趣,可以看看我整合并且整理成了一份AI大模型资料包,需要的小伙伴文末免费领取哦,无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]👈

















 249
249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









