






前言
自DeepSeek-R1发布以来,Reasoning model(推理模型)可谓是大火。同时,LLM领域近期也发生了三件事:
- • 字节团队发布Seed-Thinking-v1.5技术报告;
- • 清华&上交团队在paper中提出:RL并不能真正提升LLM的推理能力;
- • 具备Reasoning能力的Qwen3问世,号称思考更深、行动更快。
既然推理模型如此重要,笔者本次就针对几款主流的模型做一个总结,主要回答两个问题:
- • RL能否提升LLM的推理能力?
- • 如何让LLM具备Reasoning能力?
一、RL能否提升LLM的推理能力?
1.1 DeepSeek-Math的回答
论文指出:评估了Instruct和RL模型在两个基准测试上的Pass@K和Maj@K准确率。如图7所示,RL提升了Maj@K的性能,但没有提升Pass@K。这一发现表明,RL通过使模型的输出分布更加稳健来提升整体性能,换句话说,改进似乎是通过将正确答案从TopK中提升而实现的,而不是通过提升模型的基础推理能力。类似地,在推理任务中发现了SFT模型中的误对齐问题,并表明通过一系列偏好对齐策略可以提升SFT模型的推理性能。
在DeepSeek-Math的实验结果如下图1-1(包括Maj@K和Pass@K的定义):
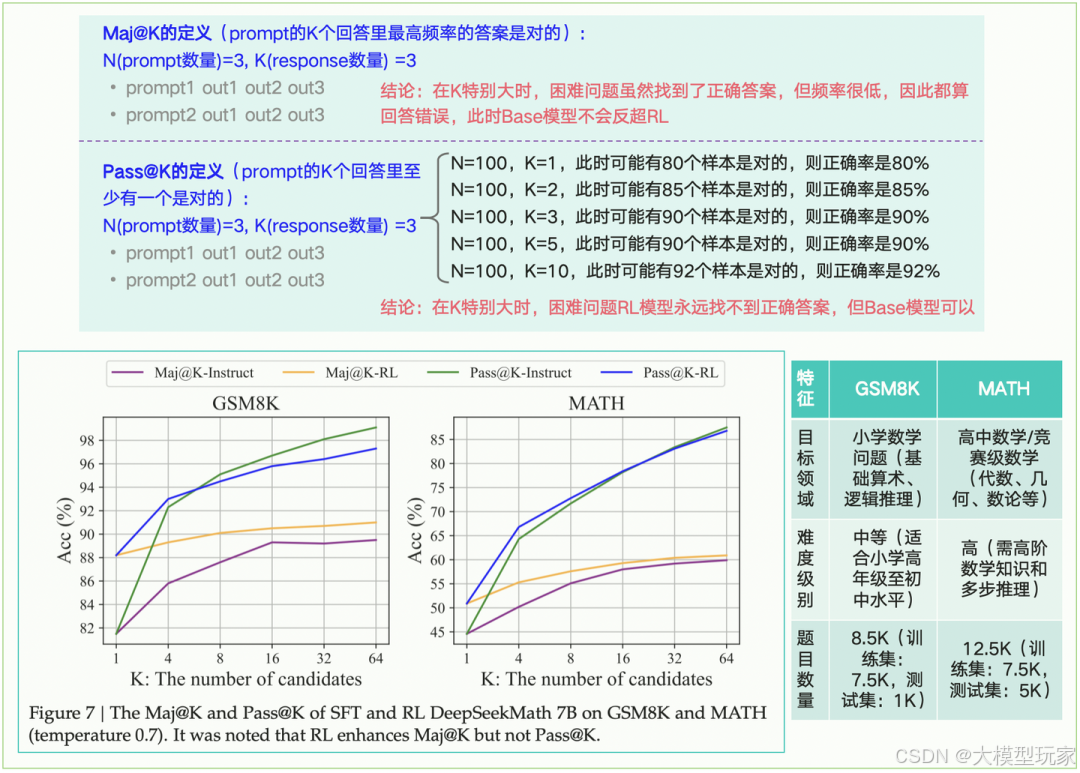
图1-1:DeepSeek-Math的5.5.2小节内容
1.2 清华paper的回答
这里的paper是指近期清华&上交团队合作发表的论文《Does Reinforcement Learning Really Incentivize ReasoningCapacity in LLMs Beyond the Base Model?》。
论文指出:RL训练模型生成的推理路径已包含在基础模型的采样分布中,这表明RL训练模型中表现出的大多数推理能力已由基础模型获得。RL训练通过偏向更可能产生奖励的路径来提高性能,从而更高效地采样正确的响应。但这也限制了其探索能力,导致推理能力边界比基础模型更窄。
对比可知,该paper的回答和DeepSeek的回答是相似的,即RL训练模型中表现出的大多数推理能力已由基础模型获得。但该paper给出了更多的实验(细节可参考原文),主要包括:
- • 验证基础模型中存在推理模式
- • 验证蒸馏(如DeepSeek-R1-Distill-Qwen-7B模型)可以扩展推理边界
- • 对比不同RL算法(如PPO、GRPO、DAPO等)的效果
二、如何让LLM具备Reasoning能力?
2.1 Seed-Thinking-v1.5
Seed-Thinking-v1.5是一种MoE(混合专家)模型,规模相对较小:总参数200B&激活参数20B。该团队为了开发一个高质量的推理模型,在三个关键点投入了大量精力:训练数据、RL算法、RL infrastructure(本文不展开)。
1)RL阶段的训练数据准备

图2-1:Seed-Thinking-v1.5的RL数据准备
2)Reward模型
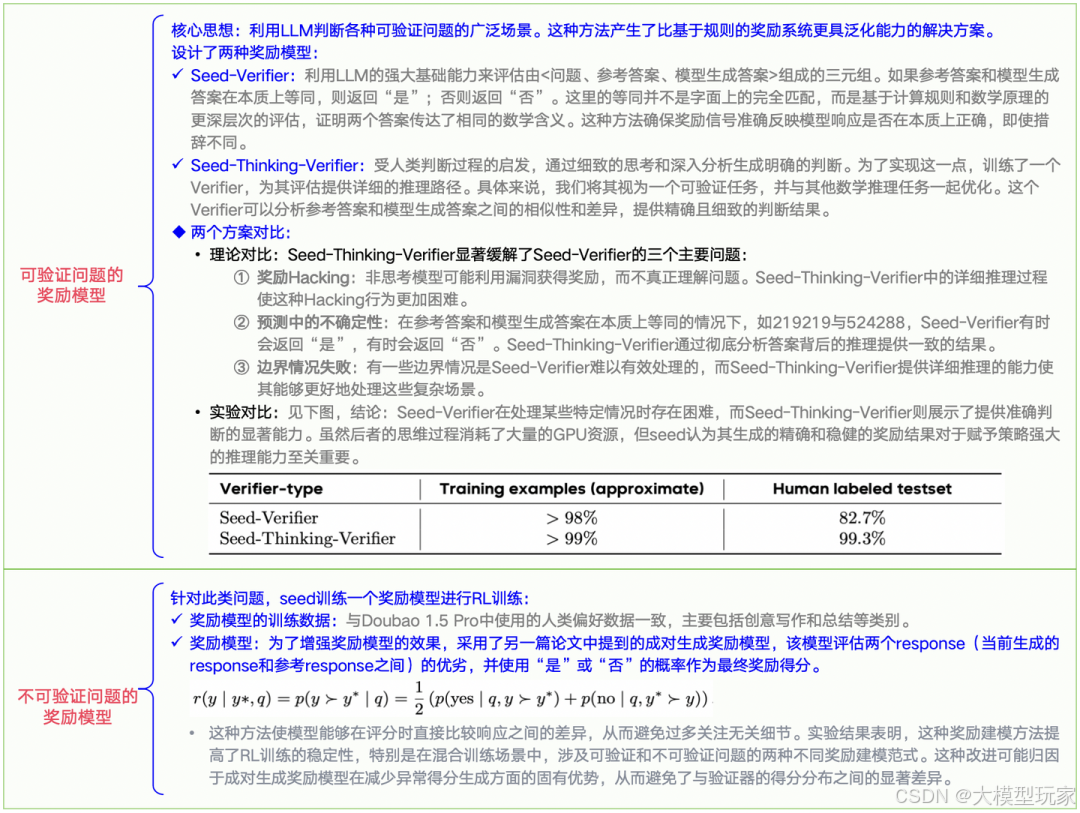
图2-2:Seed-Thinking-v1.5的奖励模型
3)SFT阶段的数据和训练

图2-3:Seed-Thinking-v1.5的SFT阶段

4)RL阶段的训练
 图2-4:Seed-Thinking-v1.5的RL算法
图2-4:Seed-Thinking-v1.5的RL算法
2.2 DeepSeek-R1
DeepSeek-R1的训练流程,如下:
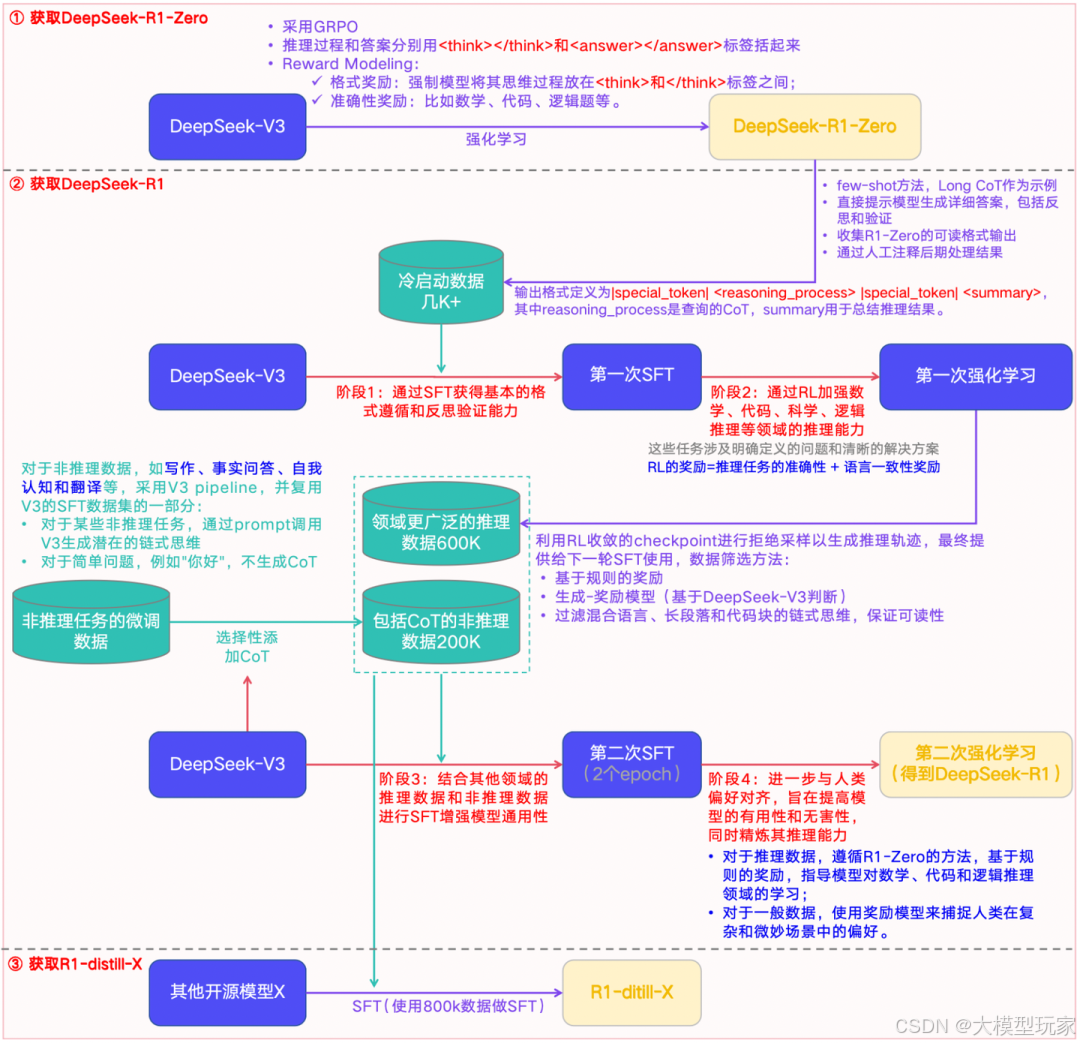
图2-5:DeepSeek-R1全流程
整体分为两大步:
1)获取DeepSeek-R1-Zero:通过"纯"强化学习(无任何监督数据,Prompt模板见下图1-1)去生成一个新模型,即R1-Zero,然后用它生产几千+带CoT的冷启动数据,作为后续R1模型的燃料之一。
 图2-6:DeepSeek-R1-Zero的Prompt模板
图2-6:DeepSeek-R1-Zero的Prompt模板
2)获取DeepSeek-R1:主要包括四个核心训练阶段(阶段1、2、3、4)和2个数据准备阶段(阶段0、2.5):
- • 阶段0:即获取DeepSeek-R1-Zero。
- • 阶段1:基于R1-Zero的几千+数据,在V3-Base上执行第一次SFT,获得基本的格式遵循和反思验证的能力。
- • 阶段2:执行第一次强化学习,加强模型在数学、代码、逻辑推理等领域的推理能力。
- • 阶段2.5:基于阶段2的模型,获取领域更广泛的600K数据;基于V3-Base,获取包括CoT的非推理数据200K。
- • 阶段3:基于获取的800K数据,在V3-Base上执行第二次SFT,增强模型的通用性。
- • 阶段4:执行第二次强化学习,进一步对齐人类偏好,提升模型的可用性和无害性,并精炼推理能力。
因此,模型在四个阶段都在努力注入Reasoning能力。
2.3 Kimi-K1.5
这是一个多模态模型,观感上,其数据整理、奖励模型、SFT训练、RL训练和Seed-Thinking-v1.5相似,但仍然有特殊之处,需要额外了解的如下:
1)RL的数据往哪个方向收集?
作者明确指出,高质量的 RL 提示集具有以下三个关键特性:
- • 多样覆盖(Diverse Coverage):prompt涵盖全面,如STEM、编码和一般推理,以增强模型在不同领域的广泛适用性。
- • 平衡难度(Balanced Difficulty):prompt集合应包括易、中、难问题的均衡分布,以促进逐步学习,防止过拟合到特定复杂度水平。
- • 准确可评估性(Accurate Evaluability):允许verifier进行客观和可靠的评估,确保模型性能基于正确推理而非表面模式或随机猜测。
2)采样策略

图2-7:Kimi-K1.5的采样策略
3)RL算法(online policy mirror decent)

图2-8:Kimi-K1.5的RL算法
关于为什么要删除value模型,作者考虑了2个原因:
- • 1)设想模型生成了一个部分链式思维(z1,z2,…,zt),有两个潜在的下一个推理步骤:zt+1和zt+1′。假设zt+1直接导致正确答案,而zt+1′包含一些错误。如果有一个value函数,它会指示zt+1比zt+1′具有更高的价值。根据标准的信用分配原则,选择zt+1′将被惩罚,因为它相对于当前策略具有负优势。然而,探索zt+1′对于训练模型生成长链式思维非常有价值。
- • 2)降低RL的复杂度。
2.4 Qwen3
1)预训练阶段
 图2-9:Qwen3预训练阶段
图2-9:Qwen3预训练阶段
2)后训练阶段
为了开发既能进行逐步Reasoning又能快速响应的混合模型,实现了一个四阶段训练流程(见图2-10):
- • 第1阶段——Long CoT冷启动:使用各种Long CoT 数据对模型进行微调,涵盖数学、编程、逻辑推理和 STEM 问题等各种任务和领域。此过程旨在使模型具备基本的推理能力。
- • 第2阶段——基于推理的RL:这一阶段专注扩展强化学习的计算资源,利用基于规则的奖励来增强模型的探索和利用能力。
- • 第3阶段——Thinking模式融合:通过结合Long CoT数据和常用的指令fine-tuning数据对Thinking模型进行微调,将非思考能力融入到Thinking模型中。这些数据由第2阶段的增强型Thinking模型生成,确保推理能力与快速响应能力的无缝融合。
- • 第4阶段——通用RL:将强化学习应用于20多个通用领域任务,以进一步增强模型的通用能力并纠正不良行为。这些任务包括指令遵循、格式遵循和Agent能力等。
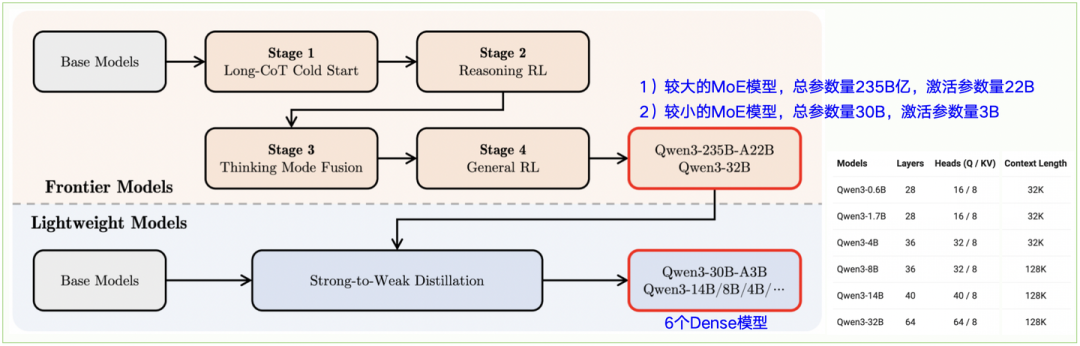 图2-10:Qwen3后训练阶段
图2-10:Qwen3后训练阶段
2.5 总结
一个优秀的Reasoning model诞生,需要关注以下几点:
- • Base模型够强(如DeepSeek-V3)
- • 数据需要覆盖完整&高质量(如Seed-Thinking-v1.5和Kimi-K1.5)
- • 预训练中,可以在最后一个阶段就加入推理数据
- • 奖励模型非常重要,如果能够针对性对CoT打分则更佳
- • 后训练中,在SFT和RL过程均加入推理数据
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
如果你真的想学习大模型,请不要去网上找那些零零碎碎的教程,真的很难学懂!你可以根据我这个学习路线和系统资料,制定一套学习计划,只要你肯花时间沉下心去学习,它们一定能帮到你!
大模型全套学习资料领取
这里我整理了一份AI大模型入门到进阶全套学习包,包含学习路线+实战案例+视频+书籍PDF+面试题+DeepSeek部署包和技巧,需要的小伙伴文在下方免费领取哦,真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

部分资料展示
一、 AI大模型学习路线图
整个学习分为7个阶段


二、AI大模型实战案例
涵盖AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,皆可用。



三、视频和书籍PDF合集
从入门到进阶这里都有,跟着老师学习事半功倍。



四、LLM面试题


五、AI产品经理面试题

六、deepseek部署包+技巧大全

😝朋友们如果有需要的话,可以V扫描下方二维码联系领取~

















 8653
8653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









