






上篇文件介绍了RAG优化与评估的基本概念,以及使用TruLens-Eval在没有Ground-truth的情况下评估RAG应用。本篇文件主要是使用Ragas对RAG应用进行评估;
使用了Gagas生成合成测试数据集,在只有知识库文档并没有Ground-truth(真实答案)的情况下让想评估该知识库文档应用到RAG的的效果如何,这时可以用Ragas生成包含question、context、Ground-truth(真实答案)的数据集。即可在有Ground-truth(真实答案)的情况下评估RAG。
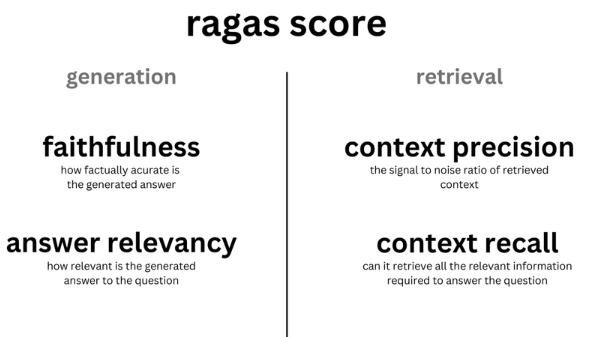
RAG包含两个主要流程,向量检索、响应生成。Ragas把这两个流程评估指标分为:评价检索包括context\_relevancy和context\_recall)和生成指标(faithfulness和answer\_relevancy)。
**Context\_relevancy**:上下文精度,上下文Context与Ground-truth的相关性越高RAG效果越好。
**Context\_recall**:上下文召回率,是否检索到回答问题所需的所有相关信息。根据真实答案(ground truth)估算上下文召回率(Context recall),分析真实答案中的每个句子以确定它是否可以归因于检索到的Context。
**Faithfulness**:答案的事实准确性,答案中提出的所有基本事实都可以从给定的上下文context中推断出来,则生成的答案被认为是忠实的。
**Answer Relevance:** 答案相关性,度量LLM的Response答案与Query提问的相关度。如分低,可能反应了回答不对题。
提示词(prompt)自动适配
在Ragas中默认的Prompt是英文的,如果直接使用生成数据集会出现一些英文数据,所以需要将Ragas内置的Prompt翻译为中文后使用。在Ragas中也提供了Prompt自动适配其他语言的支持;
noun_extractor = Prompt(
name="noun_extractor",
instruction="Extract the noun from given sentence",
examples=[{
"sentence":"The sun sets over the mountains.",
"output":{"nouns":["sun", "mountains"]}
}],
input_keys=["sentence"],
output_key="output",
output_type="json"
)
#生成中文提示词
adapted_prompt =
qa_prompt.adapt(language="chinese",llm=openai_model)
#保存提示词
adapted_prompt.save()
print(adapted_prompt.to_string())
#加载指定提示词
Prompt._load(name="question_generation",language="chinese",cache_dir='/home/linx/.cache/ragas')
Ragas使用LLM将提示词翻译成为目标语言提示词,还可以保存所翻译的提示词到磁盘,默认路径为:/home/linx/.cache/ragas,保存完成后后续可以直接加载使用;
合成测试数据集
在Ragas中生成合成数据集也会是使用LLM配合指定的Prompt用于数据集的生成,还可以生成不同难度级别的问题,生成的数据集按不同难度级别分布,给定LLM、配置文档集即可,其生成原理受到Evol-Inform启发。Ragas中为question_type定义了simple、reasoning、multi_context、conditional四种级别的问题,保证了数据集的多样性。
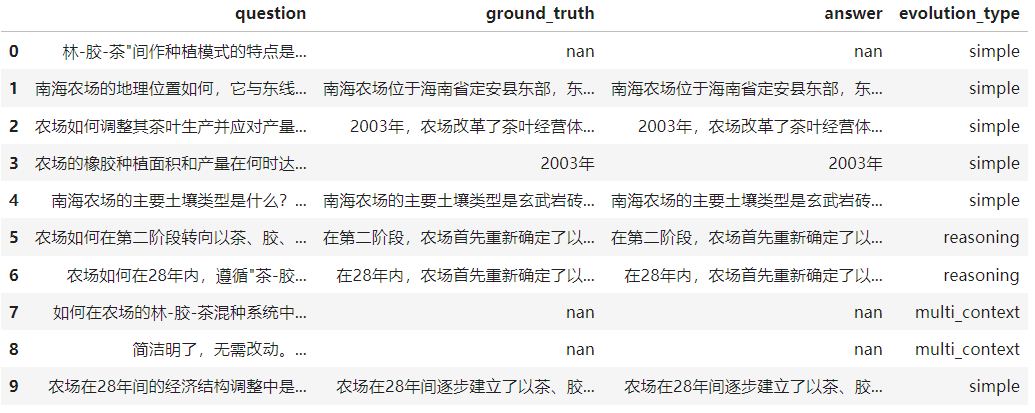
**simple**:简单问题,生成的问题在上下文中得到解答。
**reasoning**:推理问题,该问题的答案从上下文中推理得到。
**multi\_context**:多上下文问题,问题经过重写,问题解答需要从多个上下文中获取信息。
**conditional**:条件问题,问题经过重写,通过影响上下文的条件使问题复杂化。
testset_generator = TestsetGenerator.from_langchain(
generator_llm=generator_llm,
critic_llm=generator_llm,
embeddings=embedding_model
)
language = "chinese"
testset_generator.adapt(language,evolutions=[simple,
reasoning,conditional,multi_context])
testset_generator.save(evolutions=[simple, reasoning,
multi_context,conditional])
distributions = {
simple:0.4
reasoning:0.2,
multi_context:0.2,
conditional:0.2
}
synthetic_dataset =
testset_generator.generate_with_langchain_docs(
documents=load_documents(),
test_size=10,
with_debugging_logs=True
)
from datasets import Dataset
print(synthetic_dataset.to_pandas().head())
print('-------------------')
Dataset.save_to_disk(synthetic_dataset.to_dataset(),'testset')
评估合成测试数据集
生成的数据集没有经过解答未包含answer字段,这里打算把ground\_truth(真实答案)当做answer。
from datasets import load_from_disk,Dataset
#评估生成的数据集
# loading the V2 dataset
ds = load_from_disk("testset")
df = ds.to_pandas()
#复制ground_truth列,由于数据集不存在answer列,将ground_truth复制为该列
answer = df['ground_truth'].copy()
df['answer'] =answer
new_dataset = Dataset.from_pandas(df)
# ds=new_dataset.to_pandas()
# ds.head()
from ragas.metrics import (
answer_relevancy,
faithfulness,
context_recall,
context_precision,
)
from ragas import evaluate
result = evaluate(
llm=generator_llm,
dataset=new_dataset,
embeddings=embedding_model,
metrics=[
context_precision,
faithfulness,
answer_relevancy,
context_recall,
],
)
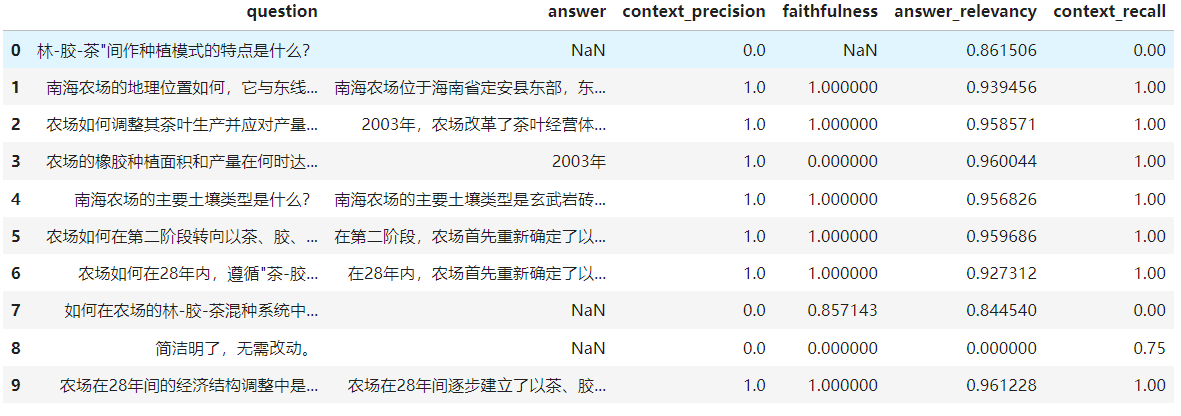
df = result.to_pandas()
print(df)
对数据集的评估结果指标如下,这里只列出了部分字段:
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1009
1009











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









