







 本文探讨了RAG系统在内容检索和生成过程中遇到的五个问题,包括答案质量控制、文档检索精度、上下文理解和回答具体性。提出了解决方案,如设置质量阈值、分析用户意图、文档标签管理和模型微调等,以及应对大数据的分布式处理策略。
本文探讨了RAG系统在内容检索和生成过程中遇到的五个问题,包括答案质量控制、文档检索精度、上下文理解和回答具体性。提出了解决方案,如设置质量阈值、分析用户意图、文档标签管理和模型微调等,以及应对大数据的分布式处理策略。
1 内容缺失
- 知识库中缺少必要的上下文信息。
- 当知识库没有包含正确答案时,RAG 系统可能会给出一个貌似合理但实际上错误的回答,而不是明确表示它不知道答案。
1.1 解决方法
1.1.1 设置阈值
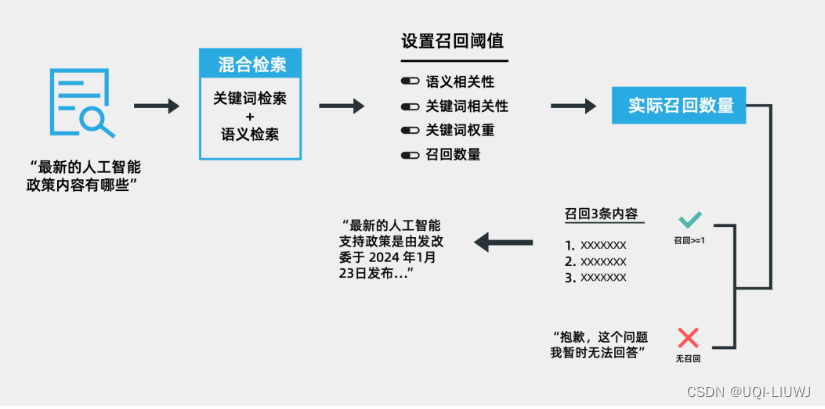
- 在回答问题前先设定一个质量标准。
- 如果召回内容达不到标准或无召回,系统不会提供答案,而是告诉用户需要更多信息或返回固定话术,防止错误或不准确的信息误导用户。
2 遗漏重要文档
- 在初始的检索步骤中,有时会漏掉关键文档,导致它们没有出现在系统返回的最顶端结果之中
- ——>正确的答案可能被忽略了,使得系统无法准确回答问题
2.1 解决方法
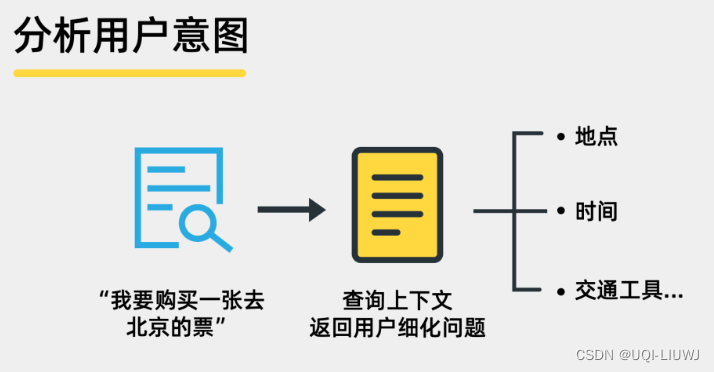
2.1.1 分析用户意图
分析用户的查询词汇和历史交互,缩小搜索范围,提高检索的相关性
3 脱离上下文
- 数据库检索到了包含答案的文档,但这些文档没有被纳入生成答案的上下文中
- 这种情况发生在从数据库返回许多文档并进行整合过程以检索答案时
3.1 解决方法
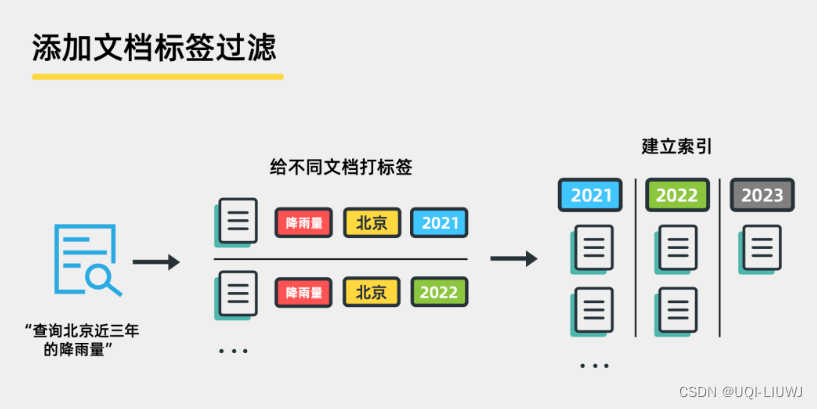
3.1.1 添加文档标签过滤
通过标签分类文档,在搜索时通过标签来缩小搜索范围,减少无关信息干扰,检索与用户查询最相关的文档
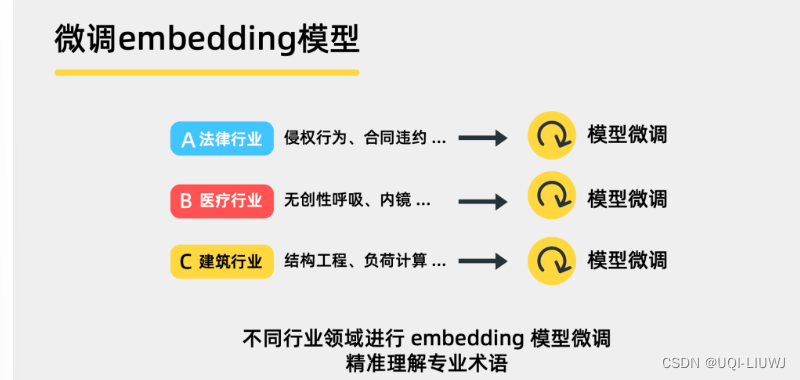
3.1.2 微调 embedding 模型
- 进一步调整文档的embedding
- 使用特定领域的数据集进一步finetune,以适应特定领域的任务或需求
4 错误的特定性
- 回答在响应中返回,但不够具体或太具体,无法满足用户的需求
4.1 解决方法
4.1.1 级联增强
- 根据用户的初始查询生成回答
- 系统分析第一次回答的结果,识别出更多细节,并据此生成更具体的问题
- 系统使用更具体的问题再次进行 RAG,逐步提高回答的质量。
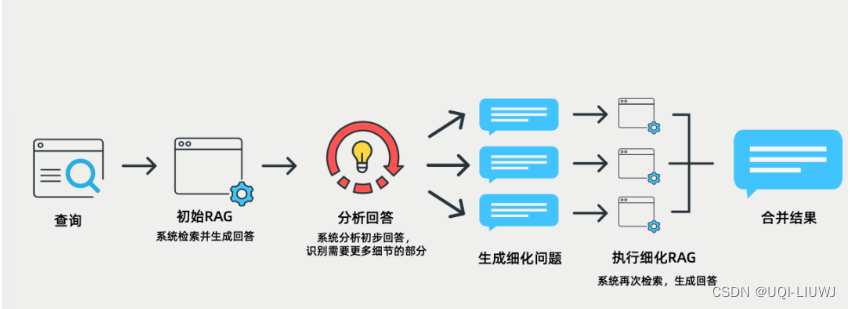
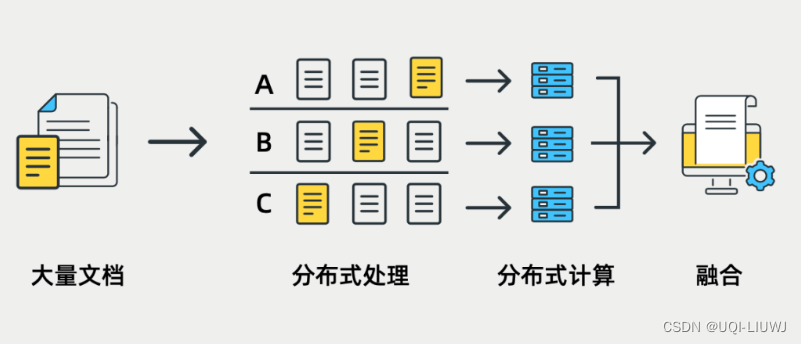
5 数据量大
5.1 解决方法
5.1.1 分布式处理
采用分布式处理框架提升力,确保系统在面对大规模数据时仍能保持高性能和高可用性
参考内容:RAG开发中常见的12个痛点及天壤解法


















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











