






在利用Stable
Diffusion生成角色图片时,一个常见的问题是如何保持角色的一致性。目前,大多数人的解决方案是训练一个LoRA模型。在训练一个固定的形象角色中,最重要的是面部特征,其次是体型、服装、配饰等。
对于现实人物,我们可以通过照片进行训练。但是,如果要训练一个动漫角色或由AI生成的角色呢?训练一个动漫角色的一个现有解决方案是上网搜索该角色的图片或截图。然而,这些图片往往需要后续处理,因为它们大多不清晰,会耗费大量时间。
目前,AI生成的角色很难保持一致性,随机性较高。因此,在收集训练集时,需要花费大量时间。为了解决这个问题,可以尝试以下方法:

1
前期设置
1、在开始生图之前,需要准备两张图片:一张是一个包含15个不同角度的人脸图片,用于生成不同角度的人脸的OpenPose骨骼图,另一张是一个包含15个格子的网格图片,用于引导SD将15张图像保留在特定的框内。

(15个角度的人脸图片)

(15个格子的网格图片)
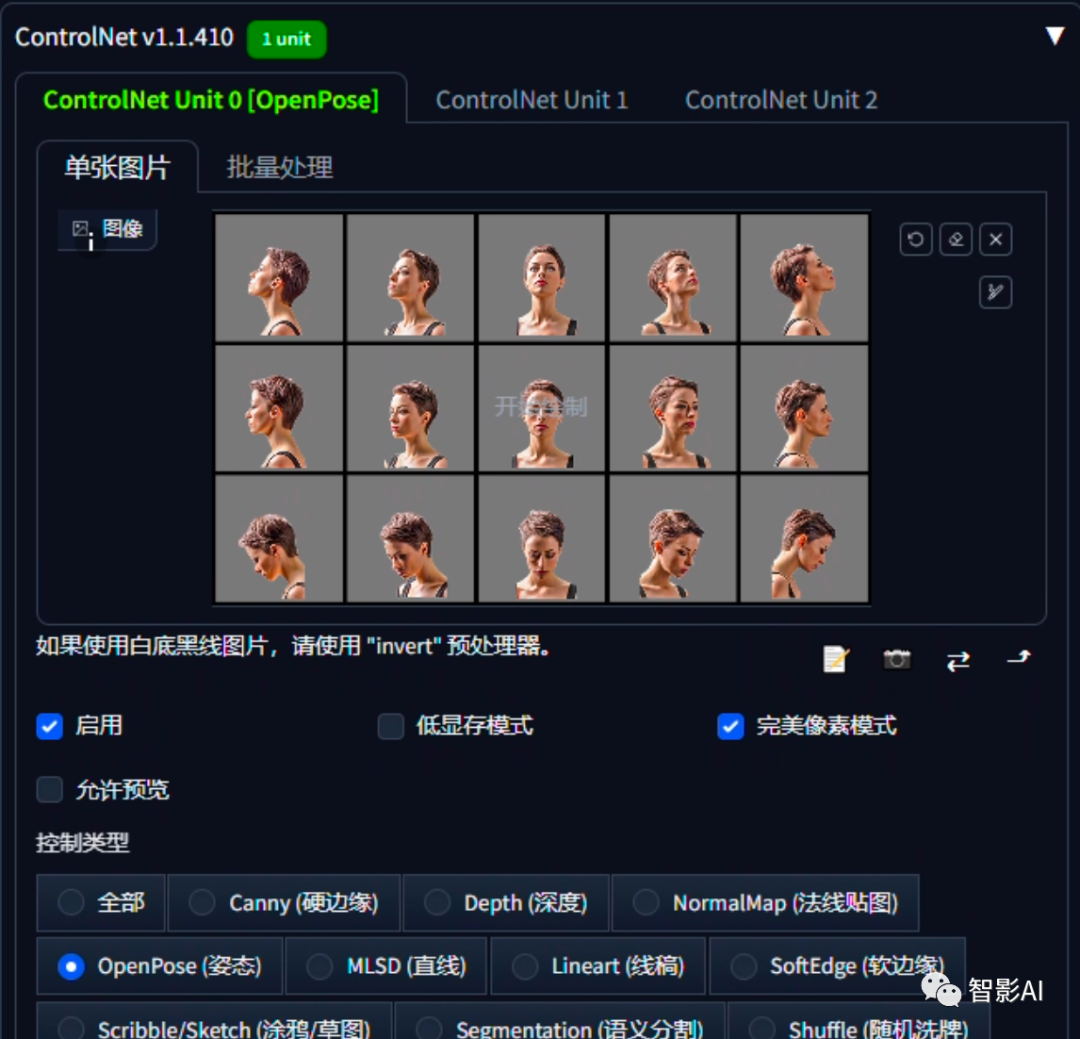
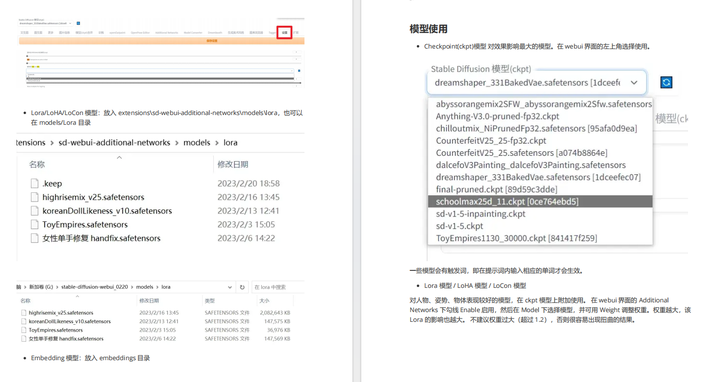
2、在准备好上述两张图片后,接下来需要设置ControlNet。将第一张图片(包含15个不同角度的人脸图片)上传到“ControlNet”的“Unit0”中,并勾选“完美像素模式”,选择“OpenPose”模型。
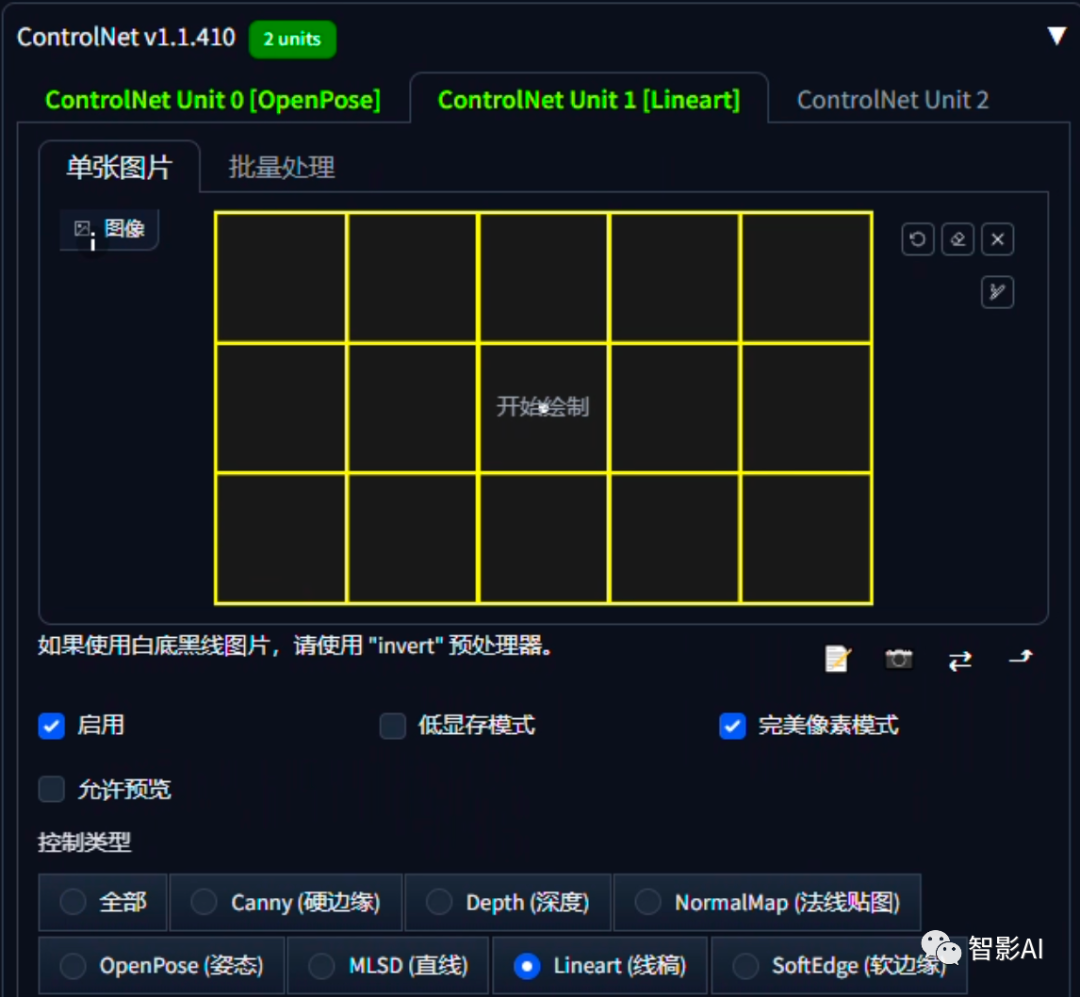
3、点击“ControlNet Unit1”,上传第二张图片(包含15个格子的网格图片),并勾选“完美像素模式”,选择“Lineart”模型。
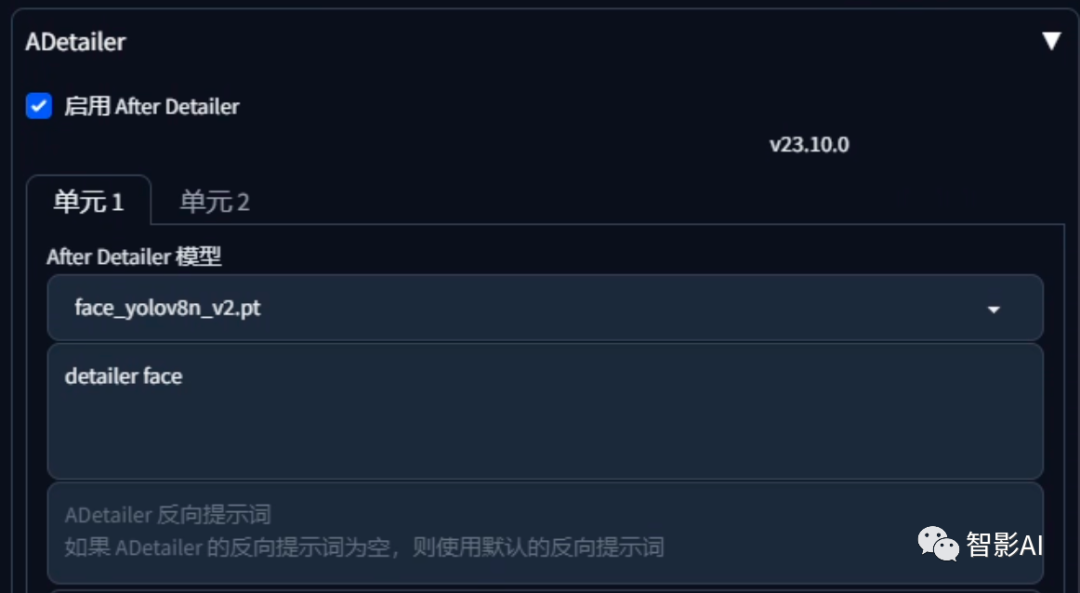
4、可以使用“ADetailer”防止脸部崩坏(可开可不开,开了生成图片的速度会变慢,如果选择不开,可以等待图片生成完成之后,利用放大来修复脸部。)
2
生成图片
设置好上述所有的设置之后,就可以开始写提示词,设置生成图片的参数啦!
1、选择一个模型,输入正向提示词以及反向提示词。
(以下是我输入的提示词,可以根据自己的需求输入任意提示词)
正向提示词:(best quality,4k,8k,highres,masterpiece:1.2),(ultra-
detailed),1girl,grey background
反向提示词:EasyNegative,(nsfw:1.5),verybadimagenegative_v1.3,
ng_deepnegative_v1_75t, (ugly face:0.8),cross-eyed,sketches, (worst
quality:2), (low quality:2), (normal quality:2), lowres, normal quality,
((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, bad anatomy,
DeepNegative, facing away, tilted head, Multiple people, lowres, bad anatomy,
bad hands, text, error, missing fingers, extra digit, fewer digits, cropped,
worstquality, low quality, normal quality, jpegartifacts, signature,
watermark, username, , bad feet, cropped, poorly drawn hands, poorly drawn
face, mutation, deformed, worst quality, low quality, normal quality, jpeg
artifacts, signature, watermark, extra fingers, fewer digits, extra limbs,
extra arms,extra legs, malformed limbs, fused fingers, too many fingers, long
neck, cross-eyed,mutated hands, polar lowres, bad body, bad proportions, gross
proportions, text, error, missing fingers, missing arms, missing legs, extra
digit, extra arms, extra leg, extra foot, ((repeating hair))
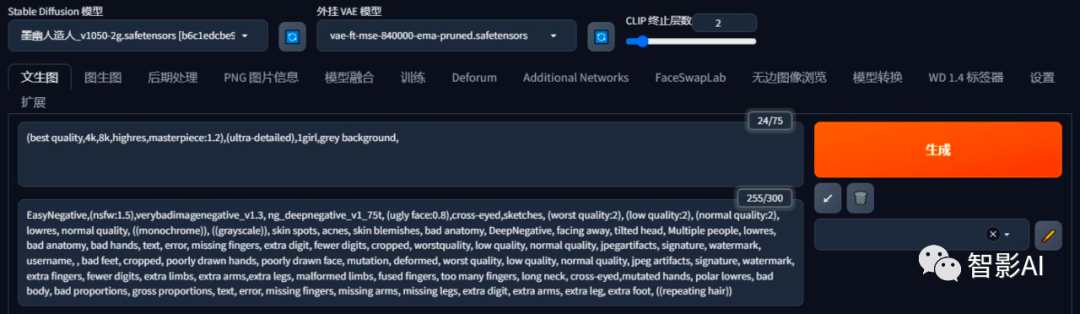
2、设置生成参数:这里主要是尺寸,1328*800,需要跟“ControlNet”上的两张图片一样的大小,其他的可以根据自己的需求设置。
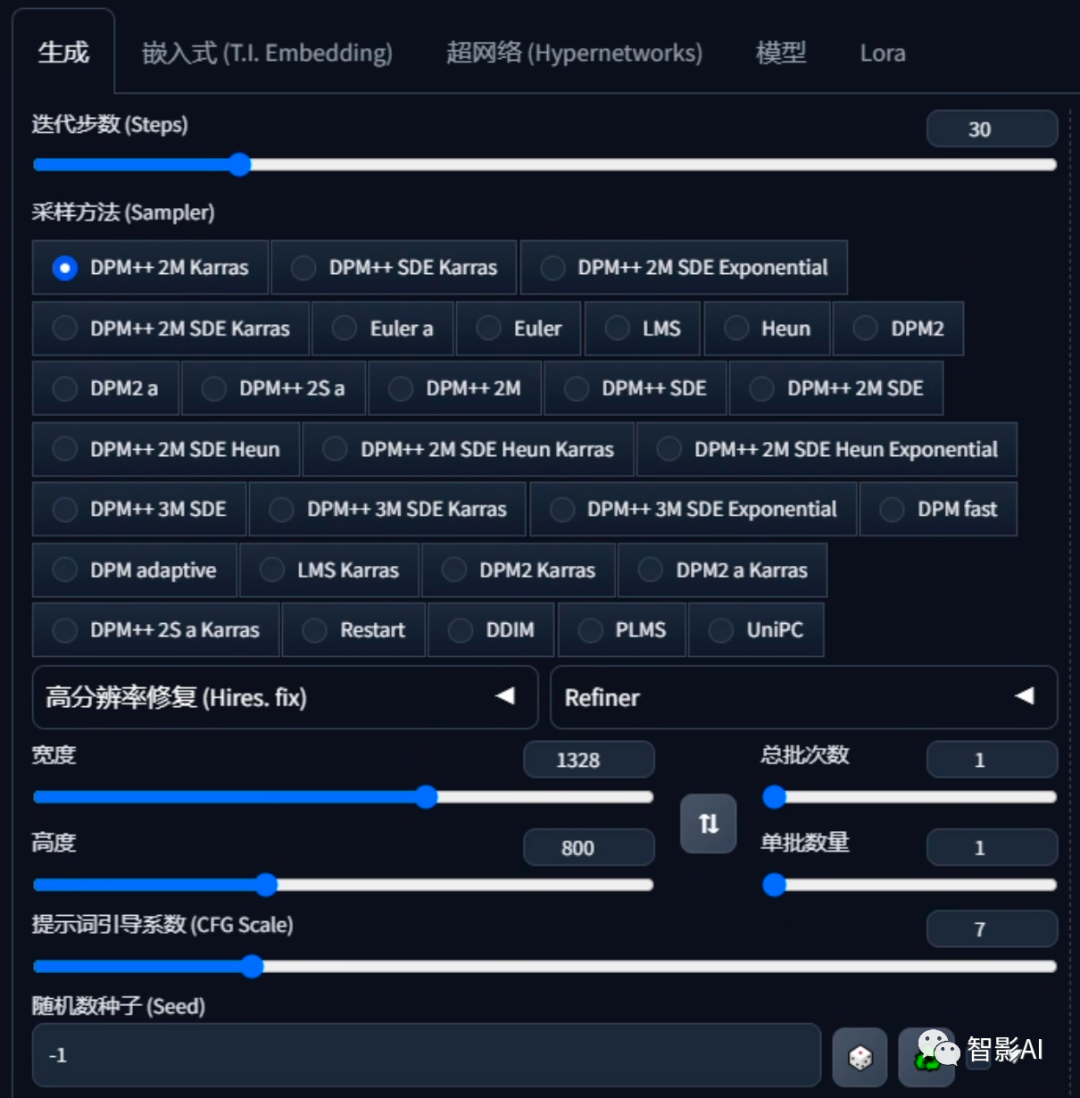
3、设置完成之后,点击“生成”即可

3
图片放大
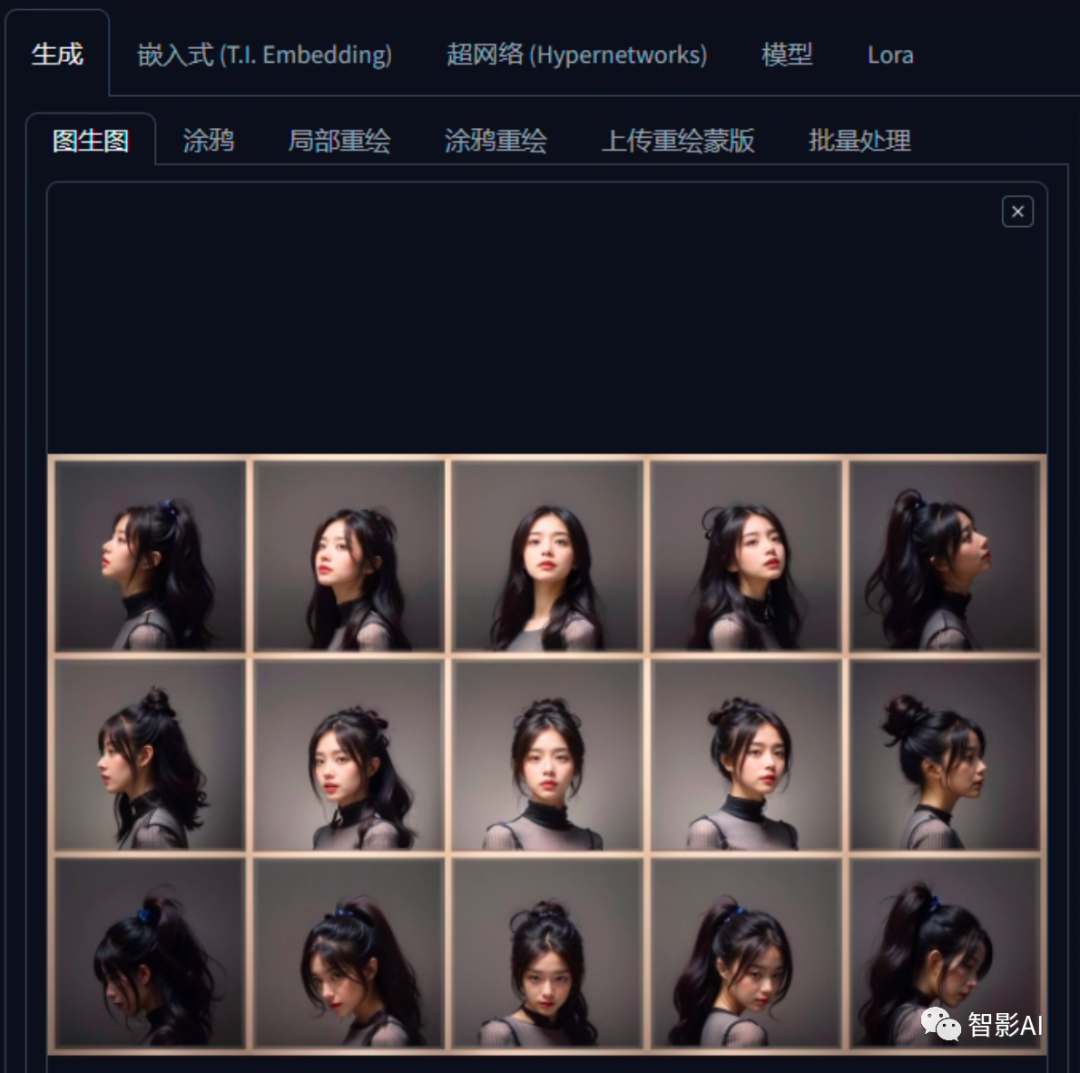
1、点击文生图生成的图片下方的图生图按钮,将图片发送到图生图。
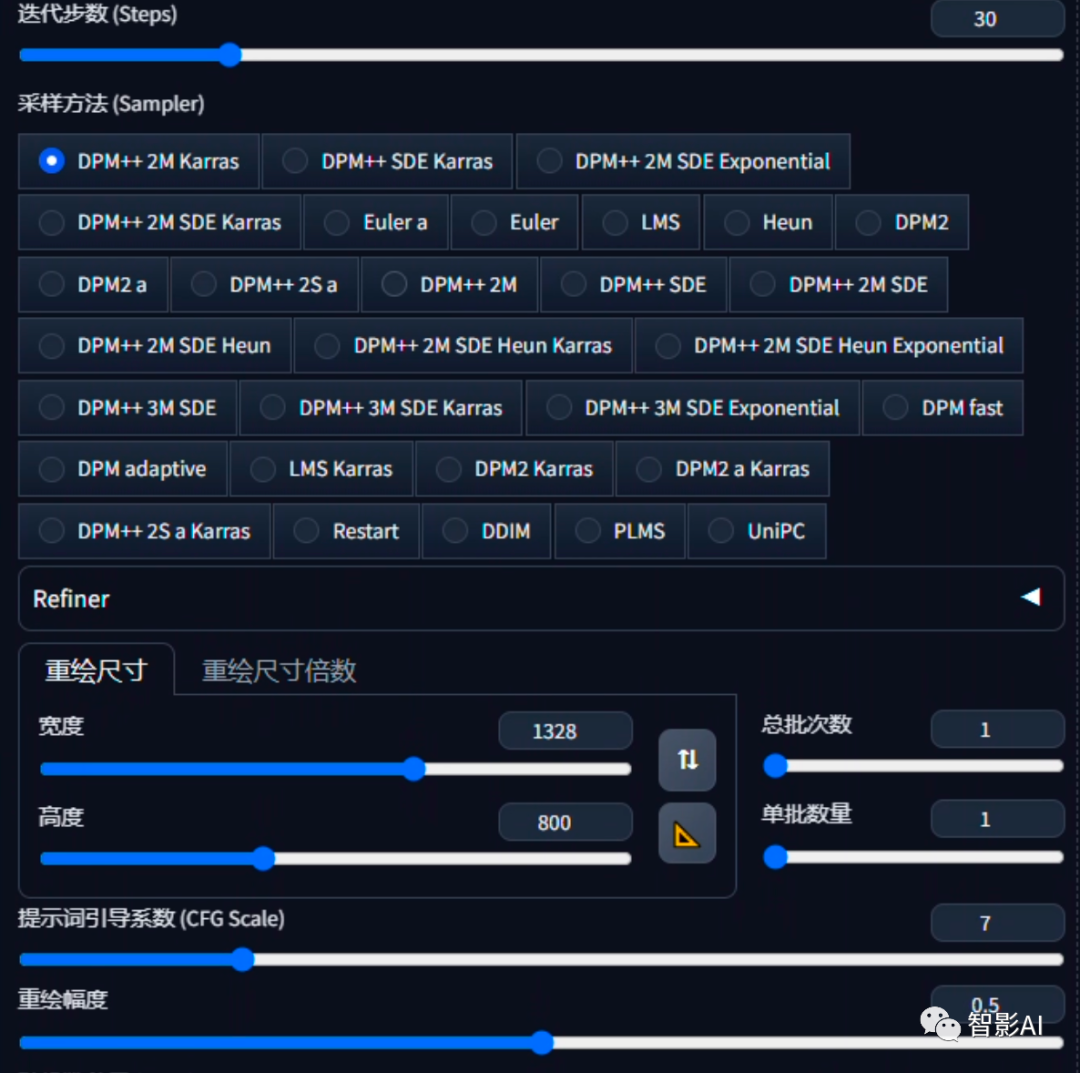
2、调整“重绘幅度”,建议调整到0.4-0.6范围内的值,有助于消除脸部的变形。其他的参数和文生图保持一样即可。
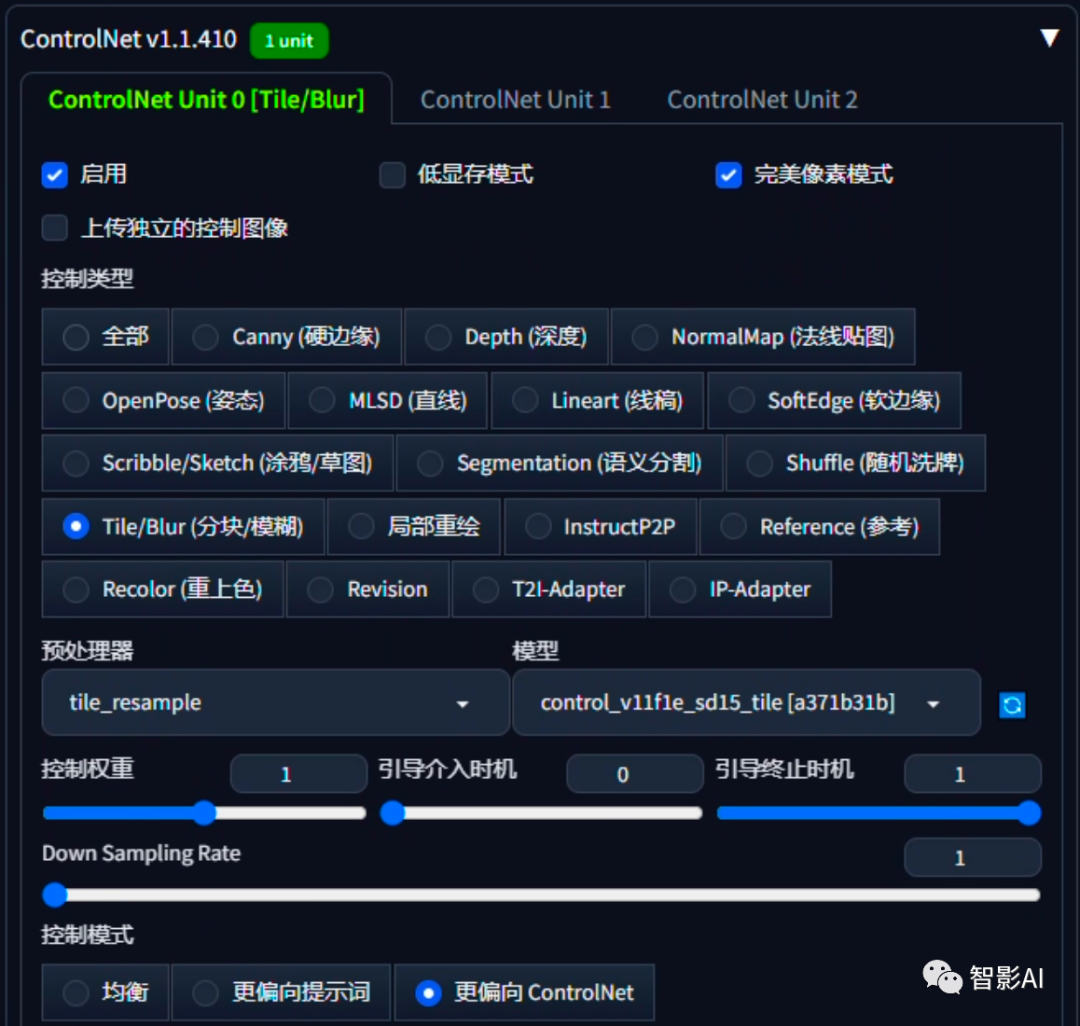
3、设置“ControlNet”,点击“启用”并勾选“完美像素模式”,选择“Tile/Blur”模型,在“控制模式”中选择“更偏向 ControlNet”。
4、在脚本中选择“Ultimate SD
upscale“脚本。在“目标尺寸类型”中选择“从图像大小缩放”,放大算法选择“4x-UltraSharp“(也可以选择其他的放大算法)。
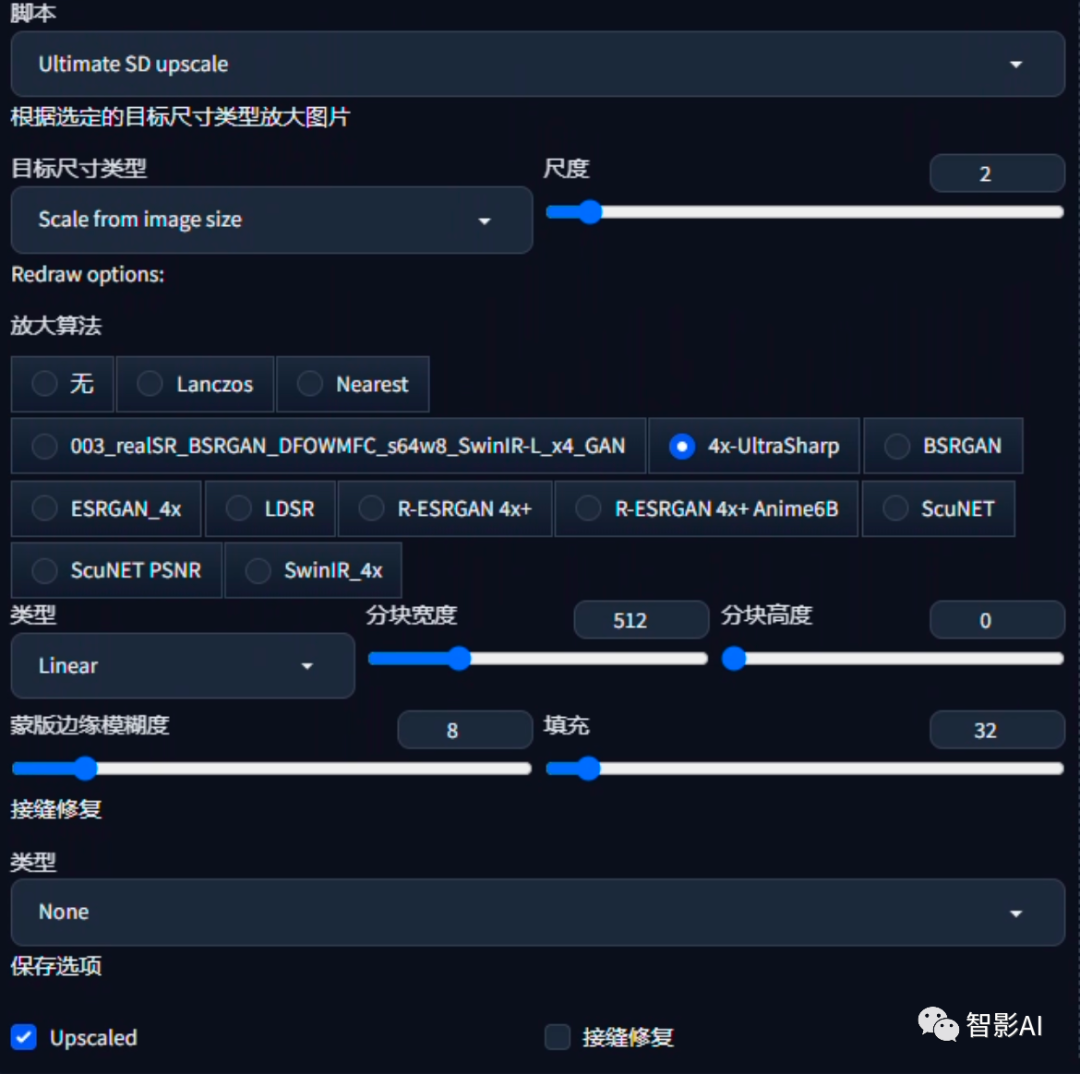
5、设置完成之后,点击“生成”即可

4
总结
以上是在Stable Diffusion同样的角色生成不同角度图片的方法,不仅仅可以生成写实人物,还可以生成二次元人物、3D人物等等。
AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。
写这篇文章的初衷,网上的Stable Diffusion教程太多了,但是我真正去学的时候发现,没有找到一个对小白友好的,被各种复杂的参数、模型的专业词汇劝退。
所以在我学了之后,给大家带来了腾讯出品的Stable Diffusion新手入门手册
希望能帮助完全0基础的小白入门,即使是完全没有代码能力和手绘能力的设计师也可以完全学得会。
软件从来不应该是设计师的限制,设计师真正的门槛是审美。
需要完整版的朋友,戳下面卡片即可直接免费领取了!
目录

- 硬件要求
- 环境部署
- 手动部署
- 整合包
- …
- 文生图最简流程
- 提示词
- 提示词内容
- 提示词语法
- 提示词模板
- …
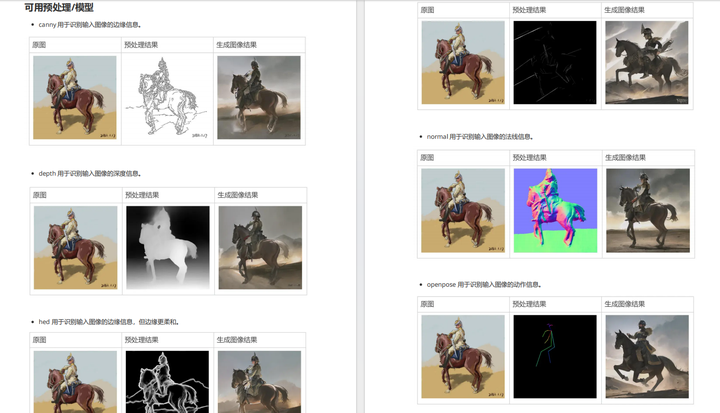
- Controlnet
- 可用预处理/模型
- 多ControlNet合成
- …
- 模型下载
- 模型安装
- 模型训练
- …
- 训练流程
- 风格训练
- 人物训练
- …
需要完整版的朋友,戳下面卡片即可直接免费领取了!

















 3081
3081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









