









在日常的工作中,例如自动化测试开展时,经常涉及到一些验证码识别、文本识别、图像识别的场景,市面上虽也有很多识别工具,但质量、准确性参差不齐。
今天给大家推荐一个开源OCR项目:Umi-OCR,功能很强大,而且还可以离线使用,现在已经有了19.7k+的星标,足见该项目的受欢迎程度。
1、项目介绍

该项目是基于PaddleOCR开发的,用Python编写,目前只支持Windows平台运行,跨平台还在筹备中。
项目地址:
-
https://github.com/hiroi-sora/Umi-OCR -
https://gitee.com/mirrors/Umi-OCR.git
项目结构:
-
Umi-OCR -
├─ Umi-OCR.exe -
└─ UmiOCR-data -
├─ main.py ** -
├─ version.py ** -
├─ site-packages -
│ └─ python包 -
├─ runtime -
│ └─ python解释器 -
├─ qt_res ** -
│ └─ 项目qt资源,包括图标和qml源码 -
├─ py_src ** -
│ └─ 项目python源码 -
├─ plugins -
│ └─ 插件 -
└─ i18n ** -
└─ 翻译文件
项目特点:
-
免费:本项目所有代码开源,完全免费。
-
方便:解压即用,离线运行,无需网络。
-
高效:自带高效率的离线OCR引擎,内置多种语言识别库。
-
灵活:支持命令行、HTTP接口等多种调用方式。
-
功能:截图OCR / 批量OCR / PDF识别 / 二维码 / 公式识别
2、项目使用
直接在releases中选择合适的版本,可选择以下方式下载:
-
GitHub https://github.com/hiroi-sora/Umi-OCR/releases/latest -
蓝奏云 https://hiroi-sora.lanzoul.com/s/umi-ocr -
Source Forge https://sourceforge.net/projects/umi-ocr
本软件无需安装,解压后,点击 Umi-OCR.exe 即可启动程序。
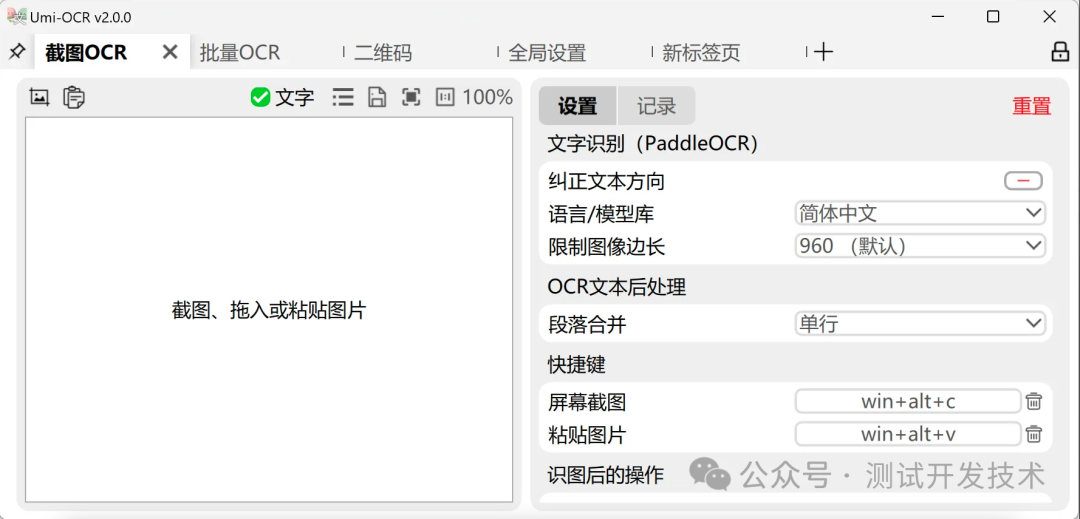
截图OCR
这个功能很适合在一些不能复制的网页上使用,速度很快,准确率也很高。
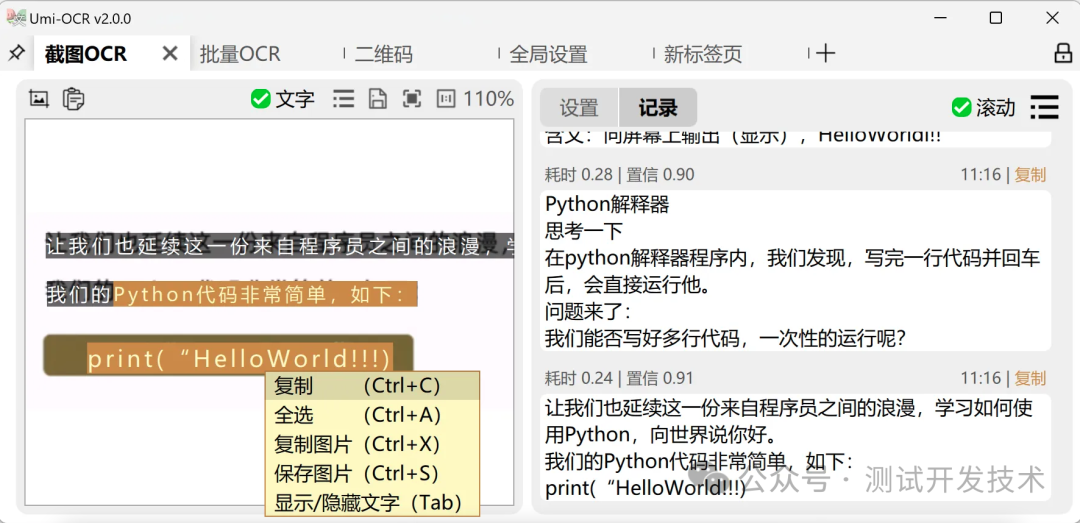
截图OCR:打开这一页后,就可以用快捷键唤起截图,识别图中的文字。
-
左侧的图片预览栏,可直接用鼠标划选复制。
-
右侧的识别记录栏,可以编辑文字,允许划选多个记录复制。
-
也支持在别处复制图片,粘贴到Umi-OCR进行识别。
批量OCR
如果需要一次性识别多图片,这个功能值得拥有 只需要将所有的图片导入,然后点击开始任务,就可以批量识别了。
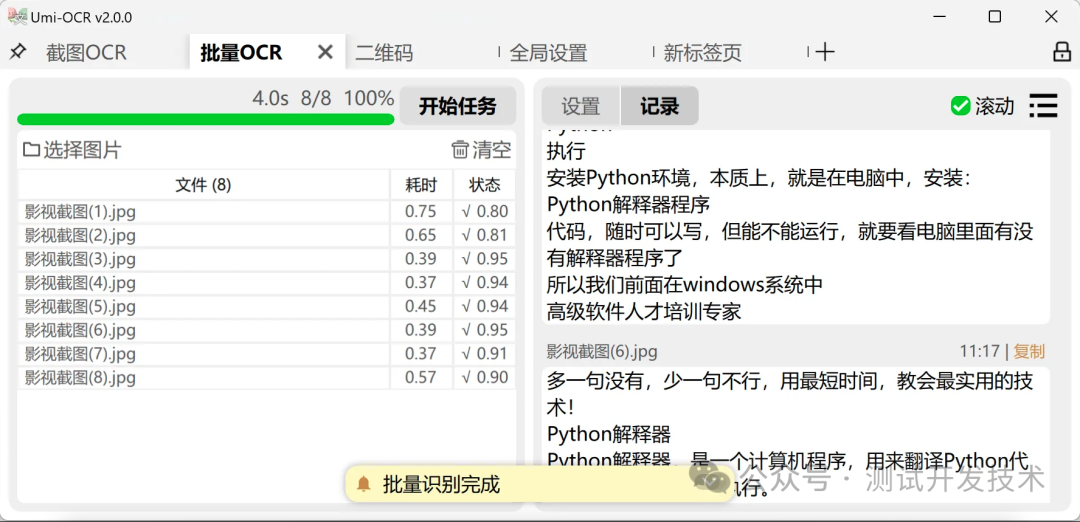
批量OCR:这一页支持批量导入本地图片并识别。
-
识别内容可以保存为 txt / jsonl / md / csv(Excel) 等多种格式。
-
与截图OCR一样,支持文本后处理功能,整理OCR文本的排版和顺序。
-
支持 忽略区域 。
-
没有数量上限,可一次性导入几百张图片进行任务。
可自定义忽略区域
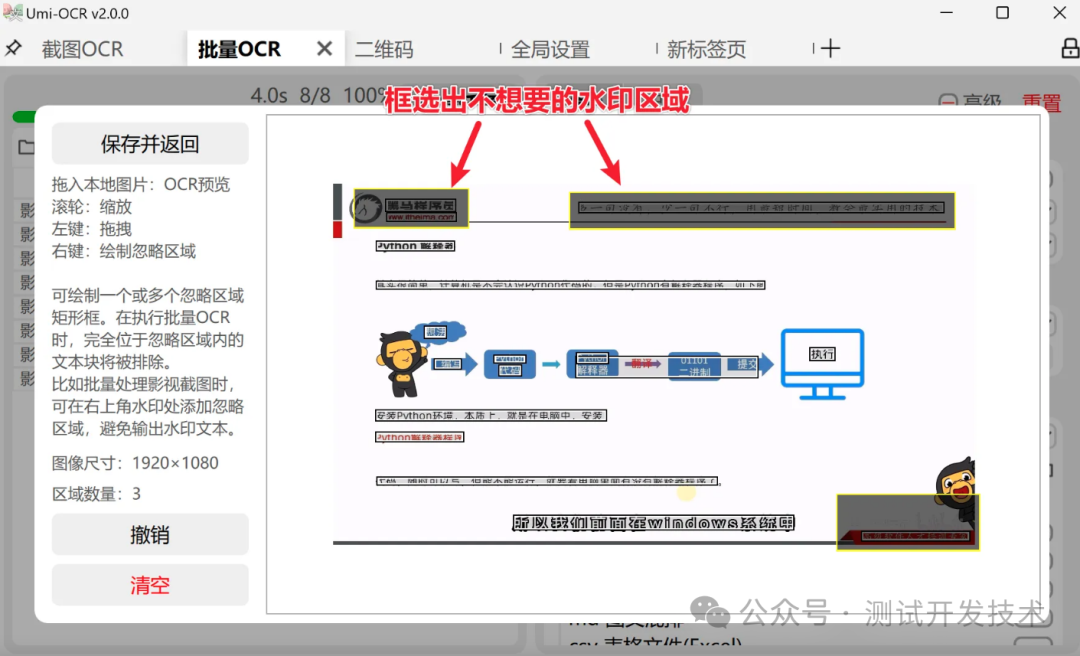
忽略区域:批量OCR中的一种特殊功能,适用于排除图片中的不想要的文字。
文档识别
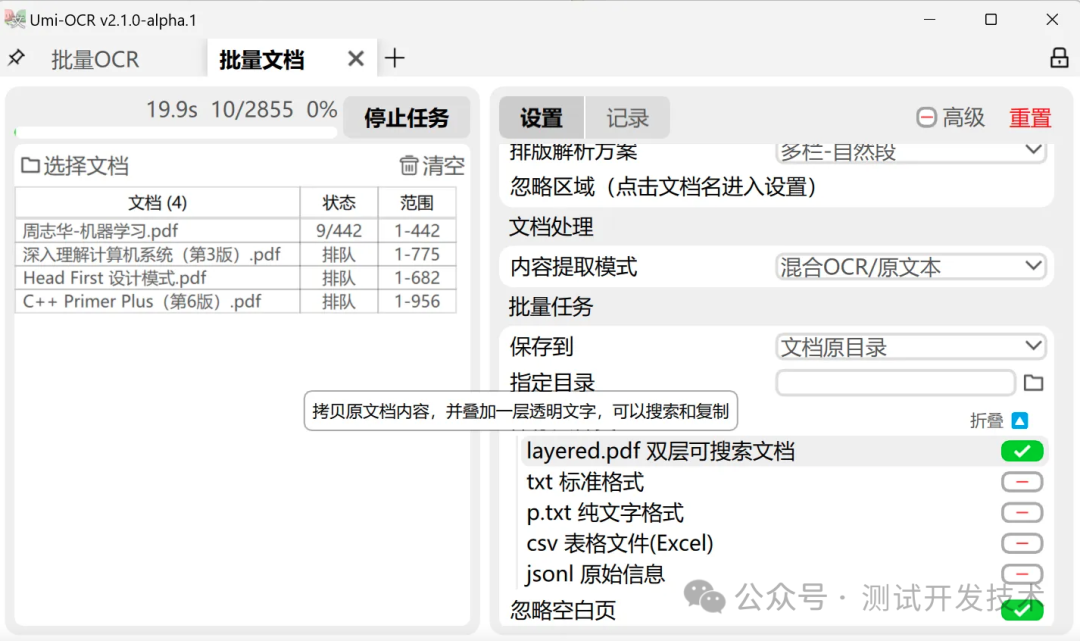
文档识别:
-
支持导入 pdf, xps, epub, mobi, fb2, cbz 格式的文件。
-
对扫描件进行OCR,或提取原有文本。可输出为 双层可搜索PDF 。
-
支持设定 忽略区域 ,可用于排除页眉页脚的文字。
-
可设置任务完成后 自动关机/休眠 。
支持命令行、接口调用
支持通过命令行或HTTP接口的方式来调用,命令行调用入口就是主程序 Umi-OCR.exe
OCR指令命令行使用:
-
截屏:Umi-OCR.exe --screenshot -
粘贴图片:Umi-OCR.exe --clipboard -
指定地址:Umi-OCR.exe --path "D:/xxx.png" -
结果输出:Umi-OCR.exe --screenshot --> test.txt
OCR指令均可在控制台回传识别结果。请耐心等待,在一次指令结束前不要输入下一条指令。所有指令支持用前几个字母替代,如--screenshot、--clipboard可以分别简写为--sc、--cl。具体可自己尝试。
HTTP接口 需先勾选开启HTTP服务,

必须允许HTTP服务才能使用HTTP接口(默认开启)。如果需要允许被局域网访问,请将主机切换到任何可用地址。
示例如下:
-
import requests -
import json -
url = "http://127.0.0.1:1224/api/ocr" -
data = { -
"base64": "iVBORw0KGgoAAAANSUhEUgAAAC4AAAAXCAIAAAD7ruoFAAAACXBIWXMAABnWAAAZ1gEY0crtAAAAEXRFWHRTb2Z0d2FyZQBTbmlwYXN0ZV0Xzt0AAAHjSURBVEiJ7ZYrcsMwEEBXnR7FLuj0BPIJHJOi0DAZ2qSsMCxEgjYrDQqJdALrBJ2ASndRgeNI8ledutOCLrLl1e7T/mRkjIG/IXe/DWBldRTNEoQSpgNURe5puiiaJehrMuJSXSTgbaby0A1WzLrCCQCmyn0FwoN0V06QONWAt1nUxfnjHYA8p65GjhDKxcjedVH6JOejBPwYh21eE0Wzfe0tqIsEkGXcVcpoMH4CRZ+P0lsQp/pWJ4ripf1XFDFe8GHSHlYcSo9Es31t60RdFlN1RUmrma5oTzTVB8ZUaeeYEC9GmL6kNkDw9BANAQYo3xTNdqUkvHq+rYhDKW0Bj3RSEIpmyWyBaZaMTCrCK+tJ5Jsa07fs3E7esE66HzralRLgJKp0/BD6fJRSxvmDsb6joqkcFXGqMVVFFEHDL2gTxwCAaTabnkFUWhDCHTd9iYrGcAL1ZnqIp5Vpiqh7bCfua7FA4qN0INMcN1+cgCzj+UFxtbmvwdZvGIrI41JiqhZBWhhF8WxorkYPpQwJiWYJeA3rXE4hzcwJ+B96F9zCFHC0FcVegghvFul7oeEE8PvHeJqC0w0AUbbFIT8JnEwGbPKcS2OxU3HMTqD0r4wgEIuiKJ7i4MS16+og8/+bPZRPLa+6Ld2DSzcAAAAASUVORK5CYII=", -
# 可选参数 -
# Paddle引擎模式 -
# "options": { -
# "ocr.language": "models/config_chinese.txt", -
# "ocr.cls": False, -
# "ocr.limit_side_len": 960, -
# "tbpu.parser": "multi_para", -
# "data.format": "text", -
# } -
# Rapid引擎模式 -
# "options": { -
# "ocr.language": "简体中文", -
# "ocr.angle": False, -
# "ocr.maxSideLen": 1024, -
# "tbpu.parser": "multi_para", -
# "data.format": "text", -
# } -
} -
headers = {"Content-Type": "application/json"} -
data_str = json.dumps(data) -
response = requests.post(url, data=data_str, headers=headers) -
if response.status_code == 200: -
res_dict = json.loads(response.text) -
print("返回值字典\n", res_dict)
更多详细使用可参考:
-
https://gitee.com/mirrors/Umi-OCR/blob/main/docs/README_CLI.md
-
https://gitee.com/mirrors/Umi-OCR/blob/main/docs/README_HTTP.md
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。

软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


视频文档获取方式:
这份文档和视频资料,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!以上均可以分享,点下方小卡片即可自行领取。

















 5380
5380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









