







知识点回顾:
- tensorboard的发展历史和原理
- tensorboard的常见操作
- tensorboard在cifar上的实战:MLP和CNN模型
效果展示如下,很适合拿去组会汇报撑页数:
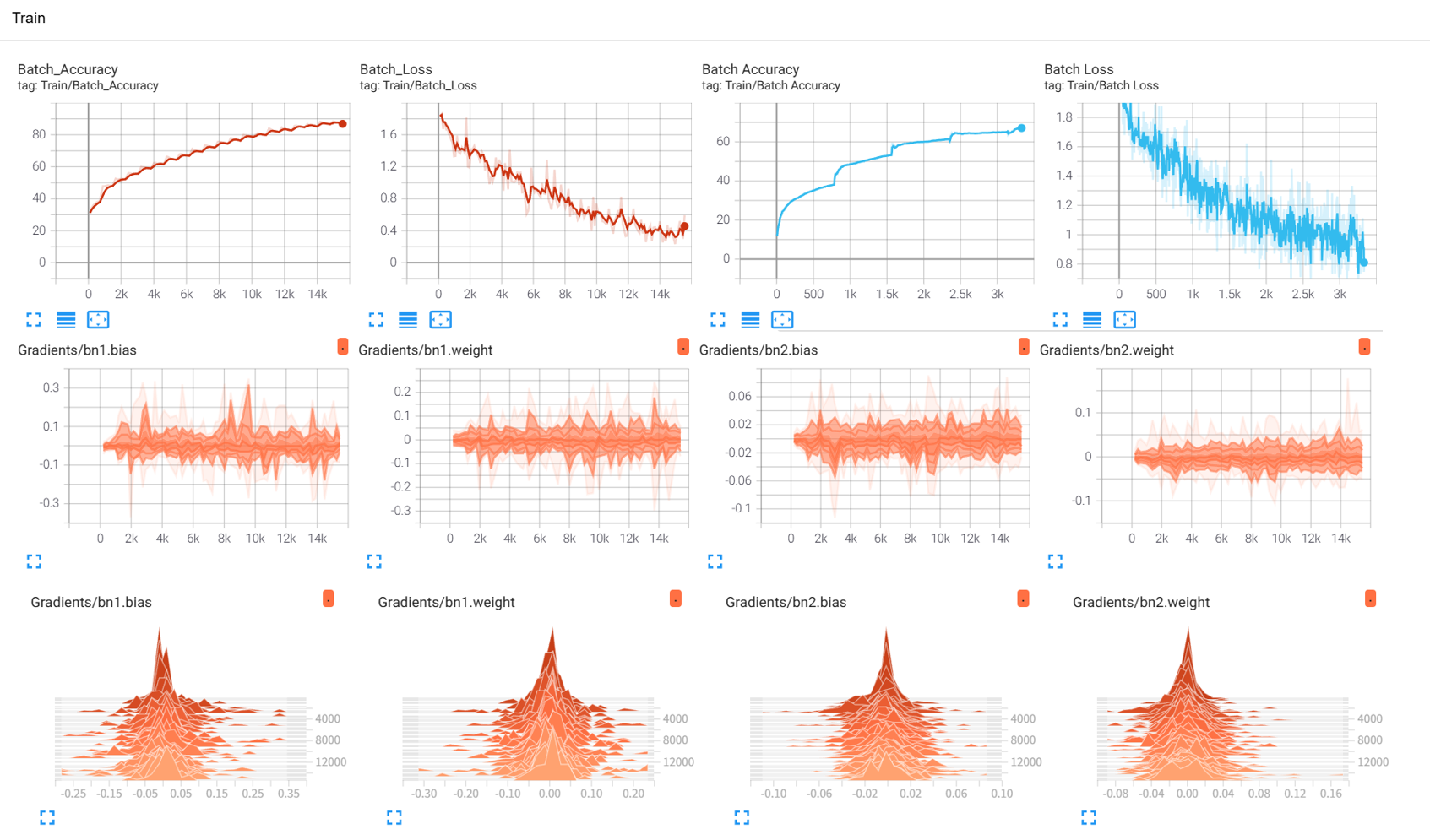
作业:对resnet18在cifar10上采用微调策略下,用tensorboard监控训练过程。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
import os
import torchvision
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
print(f"PyTorch 版本: {torch.__version__}") # 显示当前版本
# 1. 数据预处理
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(
root='./data',
train=True,
download=True,
transform=train_transform
)
test_dataset = datasets.CIFAR10(
root='./data',
train=False,
transform=test_transform
)
# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 加载预训练的ResNet18模型并调整
model = models.resnet18(pretrained=True)
# 修改输入层以适应32x32图像(CIFAR10)
model.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
# 修改输出层以适应CIFAR10的10个类别
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
# 将模型移至GPU
model = model.to(device)
# 定义微调策略:冻结前几层参数,只训练最后几层
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
# 微调策略:冻结前6个残差块,训练剩余层
ct = 0
for child in model.children():
ct += 1
if ct < 7: # 冻结前6个模块(包括conv1和前几个残差块)
for param in child.parameters():
param.requires_grad = False
criterion = nn.CrossEntropyLoss()
# 只优化可训练的参数
params_to_update = []
for name,param in model.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
optimizer = optim.Adam(params_to_update, lr=0.001)
# 移除了不兼容的verbose=True参数
scheduler = optim.lr_scheduler.ReduceLROnPlateau(
optimizer, # 指定要控制的优化器
mode='min', # 监测的指标是"最小化"(如损失函数)
patience=3, # 如果连续3个epoch指标没有改善,才降低LR
factor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)
# ======================== TensorBoard 核心配置 ========================
# 创建 TensorBoard 日志目录(自动避免重复)
log_dir = "runs/cifar10_resnet18_exp"
if os.path.exists(log_dir):
version = 1
while os.path.exists(f"{log_dir}_v{version}"):
version += 1
log_dir = f"{log_dir}_v{version}"
writer = SummaryWriter(log_dir) # 初始化 SummaryWriter
# 5. 训练模型(整合 TensorBoard 记录)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer):
model.train()
all_iter_losses = []
iter_indices = []
global_step = 0 # 全局步骤,用于 TensorBoard 标量记录
# 记录模型结构
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images) # 写入模型结构到 TensorBoard
# 记录原始训练图像
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 取前8张
writer.add_image('原始训练图像(增强前)', img_grid, global_step=0)
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 记录迭代级损失
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append(global_step + 1) # 用 global_step 对齐
# 统计准确率
running_loss += iter_loss
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# ======================== TensorBoard 标量记录 ========================
# 记录每个 batch 的损失、准确率
batch_acc = 100. * correct / total
writer.add_scalar('Train/Batch Loss', iter_loss, global_step)
writer.add_scalar('Train/Batch Accuracy', batch_acc, global_step)
# 记录学习率
writer.add_scalar('Train/Learning Rate', optimizer.param_groups[0]['lr'], global_step)
# 每 200 个 batch 记录一次参数直方图
if (batch_idx + 1) % 200 == 0:
for name, param in model.named_parameters():
if param.requires_grad: # 只记录可训练参数
writer.add_histogram(f'Weights/{name}', param, global_step)
if param.grad is not None:
writer.add_histogram(f'Gradients/{name}', param.grad, global_step)
# 每 100 个 batch 打印控制台日志
if (batch_idx + 1) % 100 == 0:
print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')
global_step += 1 # 全局步骤递增
# 计算 epoch 级训练指标
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
# ======================== TensorBoard epoch 标量记录 ========================
writer.add_scalar('Train/Epoch Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch Accuracy', epoch_train_acc, epoch)
# 测试阶段
model.eval()
test_loss = 0
correct_test = 0
total_test = 0
wrong_images = [] # 存储错误预测样本
wrong_labels = []
wrong_preds = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
_, predicted = output.max(1)
total_test += target.size(0)
correct_test += predicted.eq(target).sum().item()
# 收集错误预测样本
wrong_mask = (predicted != target)
if wrong_mask.sum() > 0:
wrong_batch_images = data[wrong_mask][:8].cpu() # 最多存8张
wrong_batch_labels = target[wrong_mask][:8].cpu()
wrong_batch_preds = predicted[wrong_mask][:8].cpu()
wrong_images.extend(wrong_batch_images)
wrong_labels.extend(wrong_batch_labels)
wrong_preds.extend(wrong_batch_preds)
# 计算 epoch 级测试指标
epoch_test_loss = test_loss / len(test_loader)
epoch_test_acc = 100. * correct_test / total_test
# ======================== TensorBoard 测试集记录 ========================
writer.add_scalar('Test/Epoch Loss', epoch_test_loss, epoch)
writer.add_scalar('Test/Epoch Accuracy', epoch_test_acc, epoch)
# 可视化错误预测样本
if wrong_images:
wrong_img_grid = torchvision.utils.make_grid(wrong_images)
writer.add_image('错误预测样本', wrong_img_grid, epoch)
# 写入错误标签文本
wrong_text = [f"真实: {classes[wl]}, 预测: {classes[wp]}"
for wl, wp in zip(wrong_labels, wrong_preds)]
writer.add_text('错误预测标签', '\n'.join(wrong_text), epoch)
# 更新学习率调度器
scheduler.step(epoch_test_loss)
# 手动打印学习率调整信息(替代removed的verbose=True)
if epoch > 0 and optimizer.param_groups[0]['lr'] < scheduler._last_lr[0]:
print(f"Epoch {epoch+1}: 学习率已调整为 {optimizer.param_groups[0]['lr']}")
print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
# 关闭 TensorBoard 写入器
writer.close()
# 绘制迭代级损失曲线
plot_iter_losses(all_iter_losses, iter_indices)
return epoch_test_acc
# 6. 绘制迭代级损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
plt.xlabel('Iteration(Batch序号)')
plt.ylabel('损失值')
plt.title('每个 Iteration 的训练损失')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# CIFAR-10 类别名
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 7. 执行训练
epochs = 20
print("开始使用ResNet18微调模型...")
print(f"TensorBoard 日志目录: {log_dir}")
print("训练后执行: tensorboard --logdir=runs 查看可视化")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, writer)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
















 166
166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









