






print(“=================================”)
c = np.asarray(((1, 2), (3, 4)))
print©
print(“=================================”)
d = np.asarray((((1, 2), (3, 4)), ((5, 6), (7, 8))))
print(d)
print(“=================================”)
e = np.asarray(a)
print(e)

②formbuffer()方法
用formbuffer()方法创建数组,该方法的特点及优势在于,该方法接收字节流形式的参数。
语法
np.frombuffer(buffer, dtype=None, count=-1, offset=0)
-
buffer指实现了__buffer__方法的对象。当buffer参数值为字符串时,因为python3默认字符串是Unicode类型,所以要转换成Byte string类型,需要在原字符串前加上b。
-
dtype 即数据类型,默认为浮点型。
-
count 读取数据的数量,默认值-1表示读取所有数据。
-
offset 读取的起始位置,默认从0位置开始。
通过以下一系列示例,快速理解其用法。
n1 = np.frombuffer(b"12345678987654321", dtype=‘S1’)
print(n1)
print(“=================================”)
n2 = np.frombuffer(b"1234567887654321", dtype=‘S2’)
print(n2)
print(“=================================”)
n3 = np.frombuffer(b"1234567887654321", dtype=‘S4’)
print(n3)
print(“=================================”)
n4 = np.frombuffer(b"abcdefghijklmnop", dtype=‘S4’)
print(n4)
print(“=================================”)
n5 = np.frombuffer(b"abcdefghijklmnop") # 转浮点型了
print(n5)
print(n5.dtype)

③fromiter()方法
fromiter()方法可用于从可迭代对象(iterable) 中创建数组。
创建一个生成器
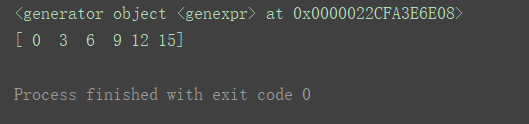
a1 = (x * 3 for x in range(6))
print(a1)
通过生成器这个可迭代对象创建数组
a2 = np.fromiter(a1, dtype=‘int’)
print(a2)
数据较多时这种方法比较高效。可以实现快速将生成器中的大量数据导入数组中。
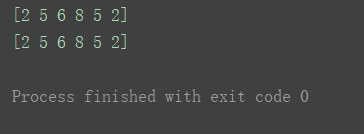
a3 = np.fromiter((2, 5, 6, 8, 5, 2), dtype=‘int’)
print(a3)
a4 = np.fromiter([2, 5, 6, 8, 5, 2], dtype=‘int’)
print(a4)
- 需要注意的一点是,使用fromiter()方法时,传入的可迭代对象不能是 有嵌套其他可迭代对象 的可迭代对象。fromiter()方法不支持套娃。
④empty_like()方法
创建一个与给定数组相同shape的未初始化的数组
语法
empty_like(prototype, dtype=None, order=None, subok=None, shape=None)
n = np.arange(1, 7).reshape(2, 3)
print(n)
print(“===============================”)
a = np.empty_like(n)
print(a)

⑤zeros_like()方法
创建一个与给定数组相同shape的全零数组
语法
zeros_like(a, dtype=None, order=‘K’, subok=True, shape=None)
n = np.arange(1, 7).reshape(2, 3)
print(n)
print(“===============================”)
a = np.zeros_like(n)
print(a)

⑥ones_like()方法
创建一个与给定数组相同shape的 全一数组
语法
ones_like(a, dtype=None, order=‘K’, subok=True, shape=None)
n = np.arange(1, 7).reshape(2, 3)
print(n)
print(“===============================”)
a = np.ones_like(n)
print(a)

⑦fulls_like()方法
创建一个与给定数组相同shape的指定值填充的数组
语法
full_like(a, fill_value, dtype=None, order=‘K’, subok=True, shape=None)
n = np.arange(1, 7).reshape(2, 3)
print(n)
print(“===============================”)
a = np.full_like(n, 100)
print(a)

======================================================================================
通过上述方法创建数组时,上边的示例中并未指定数据类型。
通过上边的示例可以看到,不指定数据类型创建数组时,如果不是根据一个传入的 具体的有数组接口方法对象来创建,则创建出的数组的数值类型默认为浮点型。其中,除了使用arange()且各个数字刚好是整数时,是个例外,得到的数组的数据类型为整数型(回顾一下上文的arange即可理解,因为arange方法与array()里边放一个 list(range(n)) 是类似的。)
关于创建数组时数据类型默认具体是怎么样的(int32, int64, float32, float64…),我现在所了解的资源中说法有很多,有的说是跟个人的操作系统有关,有的认为是保存对象所需的最小类型。目前我不清楚哪一种是对的,不过可以确定的是,我们最好在创建数组的时候,我们通常不采用默认值,最好自己指定,这样就不会产生因为数据类型带来的问题了。(如有观点或其他答案欢迎在评论区补充。)
对类型的位数有需求时,不建议使用常规的时int,float,unit指定,而后边不跟数字,也不建议使用默认值。最好自己手动指定到位。
常用的基本数据类型如下表所示:
| 类型 | 类型代码/简写 | 描述 |
| — | — | — |
| int8,uint8 | i1,u1 | 有符号和无符号的8数位整数(-128127)(0255) |
| int16,uint16 | i2,u2 | 有符号和无符号的16数位整数(-3276832767)(065535) |
| int32,uint32 | i4,u4 | 有符号和无符号的32数位整数(-21474836482147483647)(04294967295) |
| int64,uint64 | i8,u8 | 有符号和无符号的64数位整数(-92233720368547758089223372036854775807)(018446744073709551615) |
| float16 | f2 | 半精度浮点数:1个符号位,5位指数,10位尾数 |
| float32 | f4 | 标准单精度浮点数:1个符号位,8位指数,23位尾数 |
| float64 | f8 | 标准双精度浮点数:1个符号位,11位指数,52位尾数 |
| bool | ------------ | 存储一个字节的布尔值,存储True或False。(也可写为bool_) |
| complex64 | ------------ | 复数,由两个32位浮点表示(实部和虚部) |
| complex128 | 简写:complex_ | 复数,由两个64位浮点表示(实部和虚部) |
| datatime64 | ------------ | 日期和事件类型 |
| timedelta | ------------ | 两个时间类型的间隔 |
| string_ | S | ASCII字符串类型(即字节类型),eg:‘S10’ |
| unicode_ | U | Unicode类型(python3的默认字符串是Unicode类型),eg:‘U10’ |
其中unit16表示16位无符号整数,unit32表示32位无符号整数。
其中,复数不能转化为其他数值类型。
几种变换,简单了解。
print(np.int32(12.56), type(np.int32(12.56)))
print(np.float64(13), type(np.float64(13)))
print(np.complex128(1+2j), type(np.complex(1+2j)))
print(np.unicode(‘20’), type(np.unicode(‘20’)))

根据上表,创建数组时,指定数据类型,可以使用类型的全名,也可以使用类型代码。
使用array(),zeros(),ones(),empty(),arange(),linspace(),logspace(),eye()等方法创建数组时都可以通过dtype参数指定数据类型。dtype默认为None。
下边通过一些调用示例,来完成这个部分的学习。
2.3.1 整数与浮点数
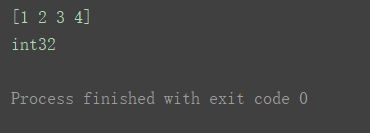
a1 = np.array([1.23, 2.34, 3.45, 4.56], dtype=int)
print(a1)
print(a1.dtype)
a2 = np.arange(0, 10, 2, dtype=‘int’)
print(a2)
print(a2.dtype)
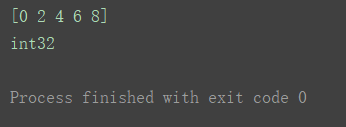
(不同:a1中传入的是关键字int,a2中传入的是字符串int。达到的效果一样。)
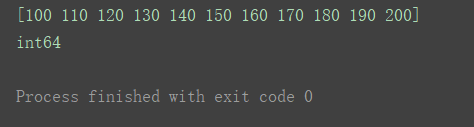
a3 = np.linspace(100, 200, 11, dtype=‘int64’)
print(a3)
print(a3.dtype)
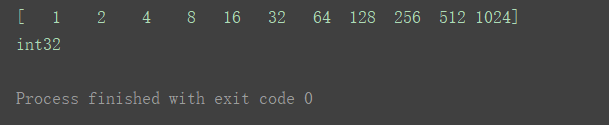
a4 = np.logspace(0, 10, 11, base=2, dtype=‘int32’)
print(a4)
print(a4.dtype)
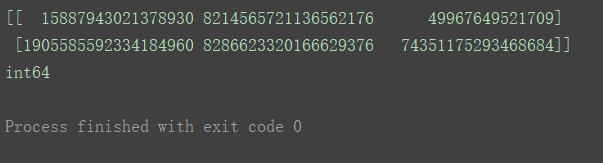
a5 = np.empty([2, 3], dtype=‘i8’)
print(a5)
print(a5.dtype)
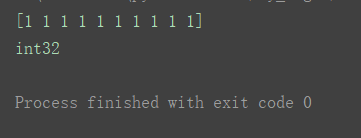
a6 = np.ones(10, dtype=‘i4’)
print(a6)
print(a6.dtype)
a7 = np.zeros(10, dtype=‘f4’)
print(a7)
print(a7.dtype)

print(a8)
print(a8.dtype)

2.3.2 字节类型
a9 = np.full((3, 4), ‘99.0’, dtype=‘S’)
print(a9)
print(a9.dtype)
a10 = np.full((3, 4), ‘99.0’, dtype=‘S2’)
print(a10)
print(a10.dtype)
a11 = np.full((3, 4), ‘aaaaaaaaaaa’, dtype=‘|S5’)
print(a11)
print(a11.dtype)

如图,数据类型分别是,一个字节,二个字节,五个字节。
直接指定为"S"表示S1,也可以在S前加一个竖杠"|’ 符号,这个符号可有可无。
如果传入汉字,则无法转化为字节,则发生报错。
a11 = np.full((3, 4), ‘侯小啾’, dtype=‘S5’)
print(a11)
print(a11.dtype)
报错。

2.3.3 字符串类型
python3的默认字符串是Unicode类型。
a12 = np.full((3, 4), ‘99.0’)
print(a12)
print(a12.dtype)
a13 = np.full((3, 4), 99.0, dtype=‘U1’)
print(a13)
print(a13.dtype)
a14 = np.full((3, 4), 99.0, dtype=‘<U3’)
print(a14)
print(a14.dtype)
a15 = np.full((3, 4), 99.0, dtype=‘U9’)
print(a15)
print(a15.dtype)

不指定时,则为数据中心字符串的长度的字符串类型,这里为U4,也可以写为<U4。
字符长度长短不一时,数组的数据类型由数据中最长的字符串所决定。
a16 = np.array([[‘a’, ‘aa’, ‘aaa’], [‘aaaa’, ‘aaaaa’, ‘aaaaaa’]])
print(a16)
print(a16.dtype)
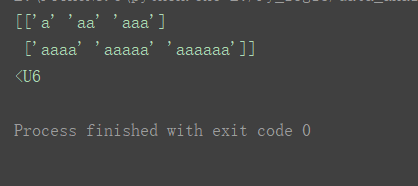
支持汉字,这里一个汉字记为一个长度。
a17 = np.array([‘侯小啾’, ‘支持小啾’, ‘关注他!’, ‘给他四连!’])
print(a17)
print(a17.dtype)
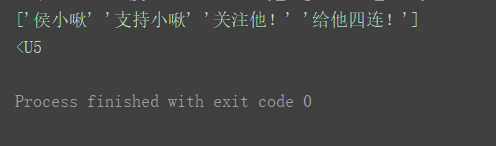
最长的字符是“给他四连!”,长度为5,所以数组的数据类型为"<U5"
====================================================================================
为了方便快速查看数组的属性,特定义以下函数,务必带走方便在学习及编程过程中随时调用。
def print_array(name, a):
print(name)
print(a)
print('rank = ', a.ndim) # 秩,即有几个轴,几维
print('shape = ', a.shape) # 形状
print('size = ', a.size) # 数据个数
print('data type = ', a.dtype) # 数据类型
print('element size = ', a.itemsize) # 每个元素占的字节数
print('data location = ', a.data) # 数据存储的位置
print()
n = np.array([[1, 2, 3], [4, 5, 6]])
print_array(“数组n:”, n)

3.2.1 reshape()与resize()
对数据的结果进行重塑可以使用reshape() 或 resize()方法。
这两种方法的区别在于使用reshape()不修改原数组,而resize()是对原数组进行修改。
- 关于reshape
新建一个一维数组
a1 = np.arange(30)
print(a1)
print(“=====================”)
一维变二维
a2 = a1.reshape((5, 6))
print(a2)
print(“=====================”)
一维变三维
a3 = a1.reshape((2, 3, 5))
print(a3)
print(“=====================”)
三维变一维
a4 = a3.reshape((30,))
print(a4)
print(“=====================”)
三维变二维
a5 = a3.reshape((5, 6))
print(a5)

- 关于resize()
a1 = np.arange(30)
print(a1)
print(“=====================”)
一维变二维
a1.resize((5, 6))
print(a1)

如图,用法resize()用法与reshape()一致,只是resize()直接修改了原数组a1。具体根据实践过程合理选择使用。
- 修改shape时,shape的每个数字相乘必须等于数组元素的个数,否则会报错。
3.2.2flatten() 与 ravel()
使用flatten()和ravel()方法,可以直接将数组从多维变为一维。
a6 = a3.flatten()
print(a6)
a7 = a3.ravel()
print(a7)

fallen()与ravel()的区别在于,fallen()得到的新数组与原数组不共享存储,即为copy过来的,所以修改a3.fallen()时不会影响a3。而ravel()得到的新数组与原数组共享存储,修改a3.ravel()时,a3会被同步修改。
n1 = np.arange(12).reshape(3, 4)
print(n1)
print(n1.shape)
print(“=====================”)
n2 = n1.T
print(n2)
print(n2.shape)

3.4.1 索引
①一维数组为例
首先创建一个一维数组
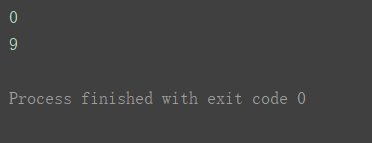
a1 = np.arange(10)
print(a1)
取出该数组第一个数值 和 最后一个数值
print(a1[0])
print(a1[-1])
②二维数组为例
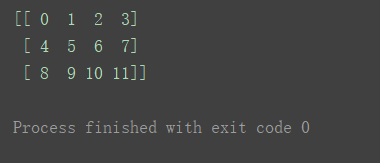
创建一个二维数组
a2 = np.arange(12).reshape(3, 4)
print(a2)
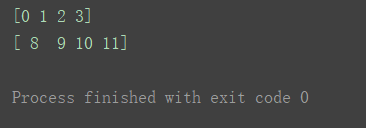
取出第一“行” 和 最后一“行”(这里说“行”只能用于二维数组,在更高维的数组是不准确的,不能说是行,而需要理解为是 在其所有维度中,序号为第一层的维度,或者说是最外层的维度 处的坐标。计数从0计起。):
print(a2[0])
print(a2[-1])
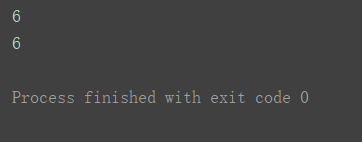
- 取出指定位置处的元素
print(a2[1][2])
print(a2[1, 2])
③三维数组为例(高维)
(关于三维及其以上的高维数组,使用为描述趋于)
a3 = np.arange(30).reshape((2, 3, 5))
print(a3)

取出其最外层维度下的第一个对象:
print(a3[0])
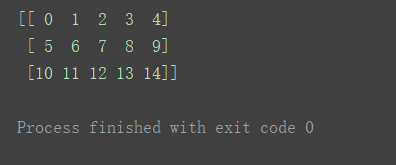
再剥一层:
print(a3[0][1])
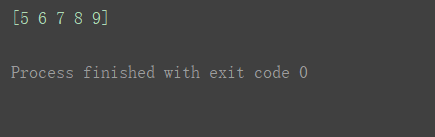
再剥一层:
print(a3[0][1][2])
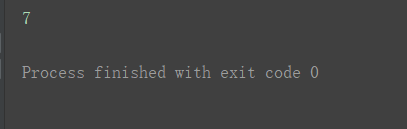
一个括号的写法:
print(a3[0, 1, 2])
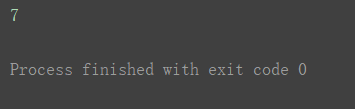
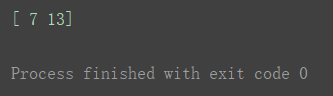
**重点,易混淆点!如果想要取出多个值(不用切片),则可以在括号内嵌套括号。
如下列代码,值得注意的是,这样取出的不是四个值,而是两个值。
不是在第二次取出1,2后,再分别在1,2两个行中取出2和3。而是取出的是(0,1,2)和(0,2,3)。**
print(a3[0, [1, 2], [2, 3]])
(这一点在学习了DataFrame的操作后后如果理解得不够透彻则容易弄混淆。)
3.4.2 切片
①一维数组为例
首先创建一个一维数组
a1 = np.arange(10)
print(a1)
print(a1[2:5])
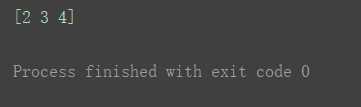
- 还是一如既往的左闭右开。
②二维数组为例
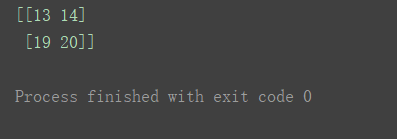
创建一个二维数组
a2 = np.arange(30).reshape(5, 6)
print(a2)

print(a2[2:4, 1:3])
一种不太常用的用法可以了解一下,
start:stop 后边可以再接一个冒号和数值,该数值表示step,步长。
步长通常为正。
如果想要倒序取值,则需要满足start>stop,然后把步长设置为负值。(只把步长设为负值的话会得到一个空数组。)
a1 = np.arange(10)
print(a1[2:7])
print(a1[2:9:2])
print(a1[9:2:-1])
print(a1[9:2:-2])
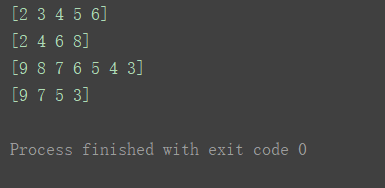
③三维数组为例(高维)
a3 = np.arange(120).reshape(4, 5, 6)
print(a3)

print(a3[0:2, 1:3, 2:5])

3.4.3 布尔索引
n1 = np.arange(30).reshape(5, 6)
print(n1)

print(n1 > 10)
print(“======================================”)
print((n1 > 10) & (n1 < 20))
print(“======================================”)
print(n1[n1 > 10])
print(“======================================”)
print(n1[(n1 > 10) & (n1 < 20)])
print(“======================================”)
print(n1[(n1 < 10) | (n1 > 20)])

使用布尔索引,不管原数组是几维,取出的数据存放在一个一维数组中。
==============================================================================
准备两个数组的数据,两个数组的shape必须相同,才能进行加减乘除运算
n1 = np.arange(1, 7).reshape(2, 3)
n2 = np.arange(7, 13).reshape(2, 3)
n3 = np.arange(4, 7).reshape(1, 3)
n4 = np.arange(5, 7).reshape(2, 1)
print(n1)
print(“-------------------------------”)
print(n2)
print(“-------------------------------”)
print(n3)
print(“-------------------------------”)
print(n4)

数据具有广播机制
其规则为:如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
这里的后缘维度,即指的是二维数组中的行和列这两个维度,在更高维数组中则指0轴和1轴的两个维度。在进行加减乘除幂等运算时,广播机制将发挥作用,
这一点可以分为以下几种情况来理解:
- 两个shape相同的数组之间进行运算,
则广播机制不启用,数组中相同位置的数据一一对应进行运算。
- 两个shape不同的数组a、b之间运算,如果数组b的0轴或1轴的长度为1,且长度为1的轴经过一定的倍数扩展后可以满足两个数组的shape相同,则广播机制启用,该长度为1的维度扩展到与数组a 在该维度的长度相等再进行运算。
具体可以分为以下几种情况:
例如,
一个4行5列的数组,可以与与一个1行5列的数组运算,运算时将次1行复制为4行;
也可以与一个5行1列的数组进行运算,运算时将该1列复制为5列。
但是不可以与一个4行2列、2行5列的数组进行运算。
也不可以与一个3行1列的数组,或者一个1行6列的数组进行运算。
再例如,一个1行8列的数组,可以和一个7行1列的数组进行运算,因为1行可以广播为7行,1列也可以广播为8列,经过广播后两数组之间的运算就相当于两个7行8列的数组之间的运算。
- 一个数组与常数之间的运算,也是广播机制在起作用。该常数分别与该数组中的每个元素运算。
具体见下方示例演示:
- 加法
print(n1+n2)
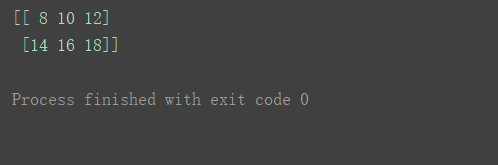
读代码体会广播机制
print(n1+n3)
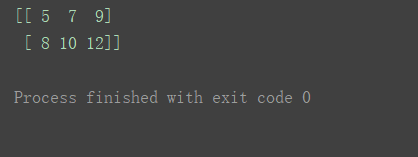
读代码体会广播机制
print(n1+n4)
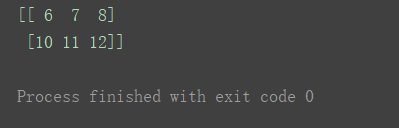
读代码体会广播机制
行、列都不相同的两个数组,但是只要后缘轴存在长度为1的,就嫩运算:
print(n3+n4)
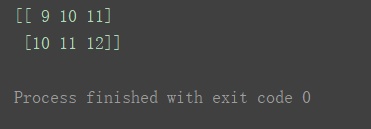
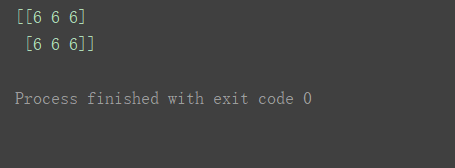
- 减法
print(n2-n1)
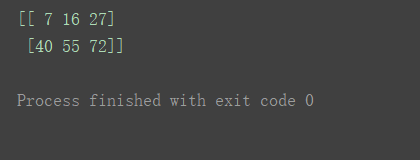
- 乘法
print(n1*n2)
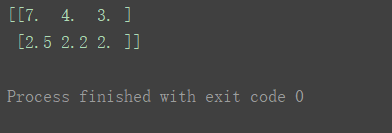
- 除法
print(n2/n1)
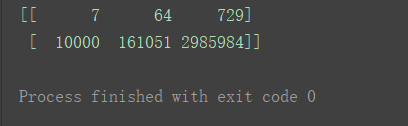
- 幂运算
print(n2**n1)
比较运算,即可以得到能够作为布尔索引的条件的数组。
print(n2 > n1)
print(“-------------------------------”)
print(n1 <= n2)
print(“-------------------------------”)
print(n1 != n2)
print(“-------------------------------”)
print(n1 == n2)

print(n1 + 2)
print(“-------------------------------”)
print(n1 - 2)
print(“-------------------------------”)
print(n1 * 2)
print(“-------------------------------”)
print(n1 / 2)
print(“-------------------------------”)
print(n1 ** 2)

===================================================================================
5.1.1 hstack()方法 与 vstack()方法
对于二维数组,可以按照水平方向增加数据,也可以按照垂直方向增加。
水平方向上的二维数组合并可以使用hstack()方法
垂直方向上的二维数组合并可以使用vstack()方法
首先创建两个二维数组
n1 = np.arange(1, 7).reshape((2, 3))
n2 = np.arange(7, 13).reshape((2, 3))
- hstack()方法
print(n1)
print(“=================================”)
print(n2)
print(“=================================”)
print(np.hstack((n1, n2)))

- vstack()方法
print(n1)
print(“=================================”)
print(n2)
print(“=================================”)
print(np.vstack((n1, n2)))

- 需要注意的是,注意这里括号的数量。hstack()函数 和 vstack()函数 需要传入的参数都是一个由数组构成元组,而不是两个数组。
在二维数组中,也许hstack()函数 和 vstack()比较常用,但是对于更高维度的数组之间,hstack()方法 与 vstack()方法则显得有些能力有限。它又是怎么执行的呢?
下边先准备一组三维数组合并的示例,然后对其进行解读。
- hstack()
n1 = np.arange(1, 25).reshape((2, 3, 4))
n2 = np.arange(26, 50).reshape((2, 3, 4))
print(n1)
print(“=================================”)
print(n2)
print(“=================================”)
print(np.hstack((n1, n2)))

- vstack()
print(n1)
print(“=================================”)
print(n2)
print(“=================================”)
print(np.vstack((n1, n2)))

观察上述程序执行结果,不难发现规律。
根据上边二维数组和三维数组合并的四组示例,针对其shape的改变,可以表示为:
- vstack()
(2,3) + (2,3) → (4,3)
(2, 3, 4) + (2, 3, 4) → (4,3,4)
- hstack()
(2,3) + (2,3) → (2,6)
(2, 3, 4) + (2, 3, 4) → (2,6,4)
在多维数组的0,1,2,3,4,5…众多轴中, vstack()函数仅仅作用于0轴 , hstack()函数 仅仅作用于1轴。不不能再以所谓的行、列来描述。
如果想要更方便地对数组进行合并,而且不限于数组的维度和轴,推荐使用使用**np.concatenate()**方法。
5.1.2 np.concatenate()方法
np.concatenate()方法在数组的合并中显得更为灵活,可以更好地操作高维数组,指定到每一个轴。
语法
concatenate(arrays, axis=None, out=None)
-
arrays 是数组构的序列,如元组
-
axis表示合并参照的轴
-
out这个参数不常用。通常也用不上。是一个数组,需要与合并后的数组的shape相同,用于放置程序执行的结果数组。
n1 = np.arange(1, 25).reshape((2, 3, 4))
n2 = np.arange(26, 50).reshape((2, 3, 4))
print(np.concatenate((n1, n2), axis=0))
print(np.concatenate((n1, n2), axis=1))
print(np.concatenate((n1, n2), axis=2))
由于程序执行结果过长,这里不再展示,还请自行测试查看。
5.1.3合并的逆操作—数组的分割split()
hsplit()、vsplit()、array_split()
刚刚详述了合并的写法,这里的分割也是同理的。也是有三个方法,分别是上边三个方法hstack()、 vstack() 和 concatenate()的逆操作:
hsplit()、vsplit()、array_split()。
语法
hsplit(ary, indices_or_sections)
vsplit(ary, indices_or_sections)
array_split(ary, indices_or_sections, axis=0)
其中 indices_or_sections表示分割成几部分。分割时是均等分割,所以这个数字必须要够分。比如,所分的轴有4个对象的话,则可以被分成4部分,2部分。不能被分成3部分,5部分,否则会报错。
- hsplit 操作1轴
a1 = np.arange(16.0).reshape(4, 4)
print(a1)
print(“=================================”)
print(np.hsplit(a1, 2))

- vsplit()操作0轴
print(a1)
print(“=================================”)
print(np.vsplit(a1, 2))

- array_split()方便操作每一个维度每一个轴
对一个三维数组:
n = np.arange(1, 25).reshape((2, 3, 4))
print(n)

对0轴
print(np.array_split(n, 2)) # 默认axis=0
print(“=================================”)
对1轴
print(np.array_split(n, 2, axis=1))
print(“=================================”)
对2轴
print(np.array_split(n, 2, axis=2))

5.2.1 关于二维数组
创建一个二维数组
n = np.array([[1, 2], [3, 4], [5, 6]])
print(n)
axis为0表示删除行,axis为1表示删除列。
n1 = np.delete(n, 2, axis=0) # 删除一行 (第3行)
print(n1)
print(“-------------------------------”)
n2 = np.delete(n, 0, axis=1) # 删除一列,第1列
print(n2)
print(“-------------------------------”)
n3 = np.delete(n, (1, 2), 0) # 删除多行
print(n3)

5.2.2站在更高维度来理解
创建一个更高维度的数组,以该四维数组为例。
a = np.arange(120).reshape(2, 3, 4, 5)
print(a)

该数组的数据结构如图所示。该数组shape为(2 ,3, 4, 5)共有4个轴,分别记为0轴,1轴,2轴,3轴。
从上图数据来看,0轴即最外层的部分,包含两个数组对象。
1轴,2轴,3轴依次向内。
其中1轴则包含三个数组对象
2轴包含四个数组对象,即我们在二维中所说的“行”,
3轴在最内层,包含了5个数据对象(不再是数组对象),也即为二维中我们所说的“列”。
遂执行以下删除操作,观察结果。依次删除每个维度的第一个对象。
- 对0轴
a1 = np.delete(a, 0, axis=0)
print(a1)

- 对1轴
a2 = np.delete(a, 0, axis=1)
print(a2)

对2轴
a3 = np.delete(a, 0, axis=2)
print(a3)

对3轴
a4 = np.delete(a, 0, axis=3)
print(a4)

准备一个简单二维数组
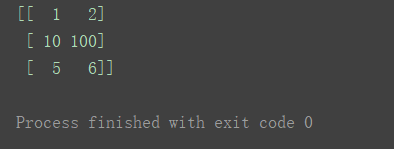
n = np.array([[1, 2], [3, 4], [5, 6]])
print(n)
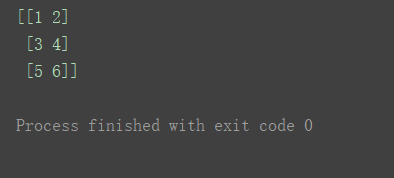
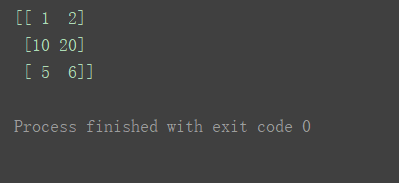
使用索引的方式对齐值进行修改
- 修改数组数组的一部分(多个值,批量修改)
则用一个数组来赋值
n[1] = [10, 20]
print(n)
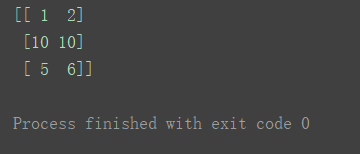
如过要修改为相同的值,也可以这样,直接某一轴(行、列)赋值一个常数。
n[1] = 10
print(n)
- 修改一个值
n[1][1] = 100
print(n)
数组的查询除了可以使用索引和切片,还可以使用where方法。
语法:
np.where(condition,x,y)
结果返回一个数组,满足condition的元素位置为x,不满足的元素的位置为y。具体如下所示:
准备一个简单二维数组
n = np.array([[1, 2], [3, 4], [5, 6]])
print(n)
print(np.where(n > 5, 1, 0))
print(“-------------------------------”)
print(np.where(n > 5, ‘对’, ‘错’))

=====================================================================================
| 函数 | 描述 | 示例 |
| — | — | — |
| add() | 加 | np.add(n1,n2),np.add(n1,2) |
| subtract() | 减 | subtract(n1,n2),subtract(n1,3) |
| multiply() | 乘 | multiply(n1,n2),multiply(n1,3) |
| divide() | 除 | divide(n1,n2),divide(n1,2) |
| abs() | 绝对值 | abs(n) |
| square() | 平方 | square(n) |
| sqrt() | 平方根 | sqrt(n) |
| log() | 自然对数 | log(n) |
| log10() | 以10为底的对数 | np.log10(n) |
| log2() | 以2位底的对数 | np.log2(n) |
| reciprocal() | 求倒数 | np.reciprocal(n) |
| power() | 第一个数组中的元素作为底数,第二个数组中元素为指数,相应位置之间求幂 | np.power(n1, n2) |
| mod() | 求相除后的余数 | np.mod(n1, n2) |
| around() | 制定小数位数,四舍五入 | around(n, x) |
| ceil() | 向上取整 | np.ceil(n) |
| floor() | 向下取整 | np.floor(n) |
| sin() | 正弦函数 | np.sin(n) |
| cos() | 余弦函数 | np.cos(n) |
| tan() | 正切函数 | np.tan(n) |
| modf() | 将元素的小数部分和整数部分分割开,得到两个独立的数组(两个数组放在一个元组里返回) | np.modf(n) |
| exp() | 以自然对数的底e为底数,数组中的数字为指数,求幂 | np.exp(n) |
| sign() | 求符号值,1表示正数,0表示0,-1表示负数 | np.sign(n) |
| maximum() | 求最大值 | np.maximum(n) |
| fmax() | 求最大值,同上 | ---------- |
| minimum() | 求最小值 | np.minimum(n) |
| fmin() | 求最小值,同上 | ----------- |
| copysign(a,b) | 将数组b的符号给数组a对应的元素 | copysign(n1,n2) |
表中,n1,n2,n都表示数组,x表示常数。
计算倒数时,要注意数据类型,如果数组数据类型为整数的话,多数整数的倒数会被显示为0。
| 函数 | 描述 |
| — | — |
| sum() | 求和 |
| cumsum() | 累计求和 |
| cumprod() | 累计求积 |
| mean() | 求均值 |
| min() | 求最小值 |
| max() | 求最大值 |
| average() | 求加权平均值 |
| meaian() | 求中位数 |
| var() | 求方差 |
| std() | 求标准差 |
| eg() | 对数组第二维度的数据求平均 |
| argmin() | 获取最小值的下标 (是变换为一维下的下标) |
| argmax() | 获取最大值的下标 (是变换为一维下的坐标) |
| unravel_index() | 一维下标转为多维下标 |
| ptp() | 计算数组最大值和最小值的差(极差) |
调用示例展示如下:
n = np.array([[3, 2, 1], [4, 5, 6], [9, 8, 7]])
print(n)
print(“==================”)
求和
print(n.sum())
求累加
print(n.cumsum())
求累积

n = np.array([[3, 2, 1], [4, 5, 6], [9, 8, 7]])
print(n)
print(“==================”)
print(n.cumprod())
求均值
print(n.mean())
求最大值
print(n.max())
求最小值
print(n.min())
求每一列的最大值
print(n.max(axis=0))
求每一列的最小值
print(n.min(axis=0))
求每一行的最大值
print(n.max(axis=1))
求每一行的最小值
print(n.min(axis=1))

n = np.array([[3, 2, 1], [4, 5, 6], [9, 8, 7]])
print(n)
print(“==================”)
求加权平均
w = [[12, 15, 16], [14, 10, 8], [10, 14, 12]]
print(np.average(n, weights=w))
求中位数
print(np.median(n))
求方差、标准差
print(np.var(n))
print(np.std(n))

求最小值、最大值在 数组变换为一维下 的坐标
print(np.argmin(n))
print(np.argmax(n))
输入一个一维下的坐标(一个数字),返回这个坐标在多维数组下的坐标
print(np.unravel_index(5, n.shape))
print(np.unravel_index(np.argmax(n),n.shape))
求极差
print(np.ptp(n))

sort()
语法
sort(a, axis=-1, kind=None, order=None)
- axis默认值为-1,表示默认按照最后一个轴排列。
n = np.array([[3, 5, 9], [4, 1, 6], [2, 8, 7]])
print(n)
print(“按最后一个轴(1轴)”)
np.sort(n)
print(n)
print(“=按0轴==”)
np.sort(n, axis=0)
print(n)
print(“按1轴”)
np.sort(n, axis=1)
print(n)

argsort()
argsort()函数即排名函数。
语法
argsort(a, axis=-1, kind=None, order=None)
print(“按最后一个轴(1轴)”)
print(np.argsort(n))
print(“=按0轴==”)
print(np.argsort(n, axis=0))
print(“按1轴”)
print(np.argsort(n, axis=1))

lexsort()
lexsort()可以实现对多个序列进行排序。(即多轮排序,可以当做是给表格排序,当第一个字段的值相同时比较第二个字段,第二个相同时比较第三个。)
要排序的列放在一个元组中传入lexsort()函数。排序时,优先排序传入时位置靠后的列。
具体见下例:
如某选拔标准:先按照score排名,score相同的按ability,ability相同的按contribution
按此标准进行排名:
names = np.array([“a某”, “b某”, “c某”, “d某”, “e某”, “f某”])
score = np.array([97, 90, 100, 97, 96, 96])
ability = np.array([80, 94, 86, 80, 77, 89])
contribution = np.array([98, 81, 94, 93, 88, 83])
sort_result排序时,优先排序传入时位置靠后的列
sort_result = np.lexsort((contribution, ability, score))
print(sort_result)
print(“==================”)
输出排名后的表格:
print(np.array([[contribution[i], ability[i], score[i]] for i in sort_result]))

6.4 自定义功能函数 np.apply_along_axis()
当要对数组进行某种变换时,可以将这种变换打包在函数中。这里使用到了np.apply_along_axis()方法。
语法:
apply_along_axis(func1d, axis, arr, *args, **kwargs)
- fun1d 是一个应用于一维数组的function。
示例:
需求,求出数组每一行去除最大值和最小值后的平均值。
a = np.arange(16).reshape(4, 4)
print(a)
print(“=========================================”)
b = np.apply_along_axis(lambda x: x[(x != x.max()) & (x != x.min())].mean(), axis=1,arr=a)
print(b)

a = np.array([12, 14, 23, 28, 12, 11, 35, 30, 12, 35])
print(np.unique(a))
print(np.unique(a, return_counts=True))
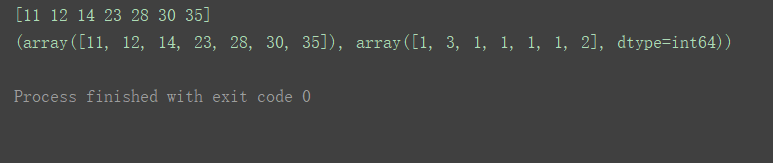
return_counts设置为True后,可以同时打印出每个值在原数组中出现的次数。
===============================================================================
数组array和矩阵matrix是Numpy库中存在的两种不同的数据类型。
mat()方法创建简单矩阵
创建矩阵时,参数采用字符串形式传入,数据之间用空格隔开,行之间用引号隔开。
如下示例所示:
a1 = np.mat(“1 2;3 4”)
print(a1)
print(“==========================”)
a2 = np.mat(“1 2 3;4 5 6;7 8 9”)
print(a2)
print(type(a2))

显然这样过于麻烦。
此外,也可以通过传入数组 来实现矩阵的快速创建。
创建随机小数 矩阵
print(np.mat(np.random.rand(4, 4)))

创建随机整数矩阵
print(np.mat(np.random.randint(1, 100, size=(5, 5))))

创建全零矩阵
- 创建一个5×5的全零矩阵
m = np.mat(np.zeros((5, 5)))
print(m)

创建全一矩阵
m = np.mat(np.ones((4, 5), dtype=‘i8’))
print(m)

创建对角矩阵
m = np.mat(np.eye(5, dtype=‘i8’))
print(m)

创建 对角线 矩阵
a = [1, 2, 3, 4, 5]
m = np.mat(np.diag(a))
print(m)

mat()方法只适用于创建二维矩阵,维度超过二维的array数组则更通用。
①矩阵与标量运算
矩阵与标量之间的运算,即
将矩阵中的每一个元素分别与这个标量运算,结果得到的矩阵与原矩阵有着相同的shape。
m1 = np.mat([[3, 4], [6, 12], [9, 20]])
print(m1)
print(“=======================”)
print(m1 + 2)
print(“=======================”)
print(m1 - 2)
print(“=======================”)
print(m1 * 2)
print(“=======================”)
print(m1 / 2)

(矩阵与标量的加减乘除运算效果与numpy数组相同。矩阵没有幂运算)
②矩阵与矩阵运算
m1 = np.mat([[3, 4], [6, 12], [9, 20]])
m2 = np.mat([3, 4])
print(“m1=:”)
print(m1)
print(“m2=:”)
print(m2)
print(“======= m1 + m2 =======:”)
print(m1 + m2)
print(“======= m1 - m2 =======:”)
print(m1 - m2)
print(“========m1 / m2 =======:”)
print(m1 / m2)

这里展示了矩阵之间加、减、除的运算。
矩阵之间从乘法运算较特殊。
m1 × m2 ,必须满足m1的列数等于m2的行数,才可计算。
且 m1 × m2 与 m2 × m1 是不可逆的。
示例如下:
m1 = np.mat([[3, 4], [6, 12], [9, 20]])
m2 = np.mat([[3], [4]])
m3 = m1 * m2
print(“m1=:”)
print(m1)
print(“m2=:”)
print(m2)
print(“========= m3 ==========:”)
print(m3)

- m1 (3 × 2) 与m2 (2 × 1) 的乘积m3 (3 × 1),的行数等于m1的行数,列数等于m2的列数。















 5794
5794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









