






舌象分割在中医舌诊中具有重要的意义。舌诊是中医通过观察舌象了解人体生理功能和病理变化的一种诊断方法。舌象分割是将舌面划分为不同的区域,每个区域对应着不同的脏腑和病理变化。
UNet++,它是一种深度监督的编码器-解码器网络,通过一系列嵌套的密集跳跃连接将编码器和解码器子网连接起来。UNet++的设计目标是减少编码器和解码器子网特征图之间的语义差距,使得优化器在面对语义相似的特征图时,学习任务变得更加简单。
在中医舌诊中,舌象分割不仅涉及将舌面划分为不同的区域,而且每个区域对应着人体的不同脏腑和病理变化。使用UNet++模型进行舌象分割能够有效提取这些区域,并通过深度监督的方式优化编码器和解码器之间的特征图差异,使得学习过程更加高效。
UNet++ 是一种改进的U-Net架构,它通过一系列嵌套的密集跳跃连接(Nested Dense Skip Connections)来连接编码器和解码器子网。这种设计减少了编码器和解码器之间特征图的语义差距,使得网络更容易学习到相似语义特征,从而提高了分割精度。 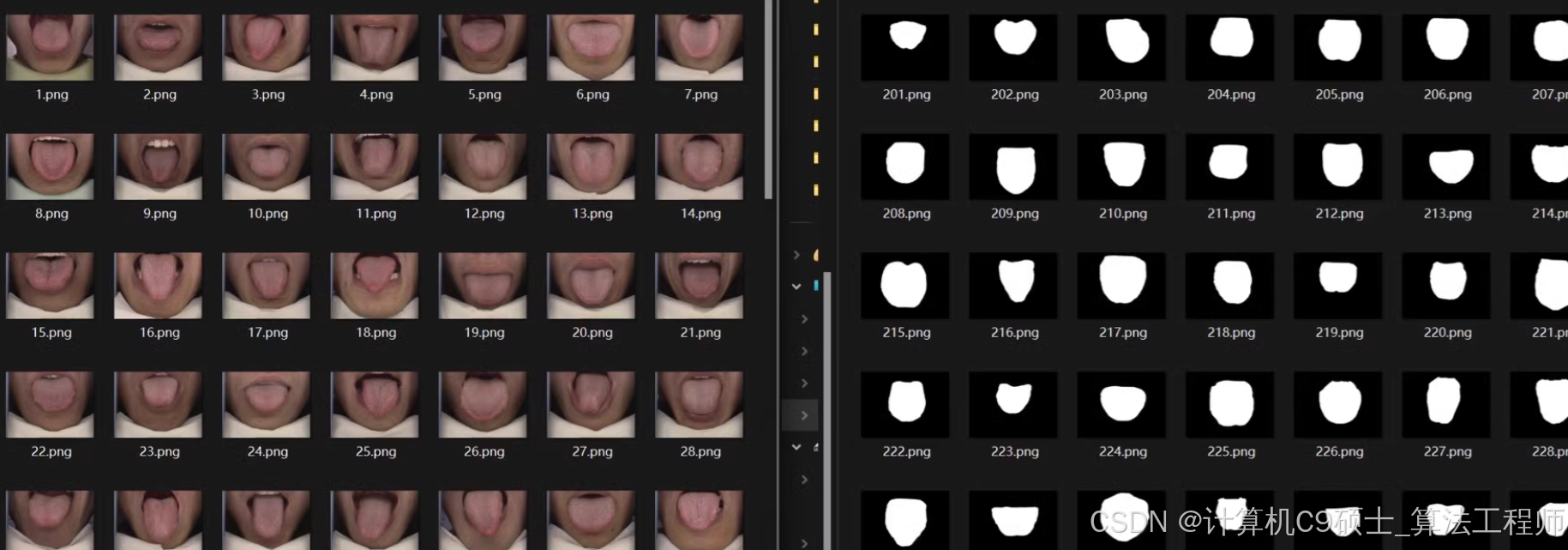
构建一个基于UNet++的舌象分割系统,涉及数据集准备、模型训练、测试以及用户界面开发。下面将提供一个详细的指南和代码示例,帮助你从头开始构建这个系统。
以下文章及代码仅供参考。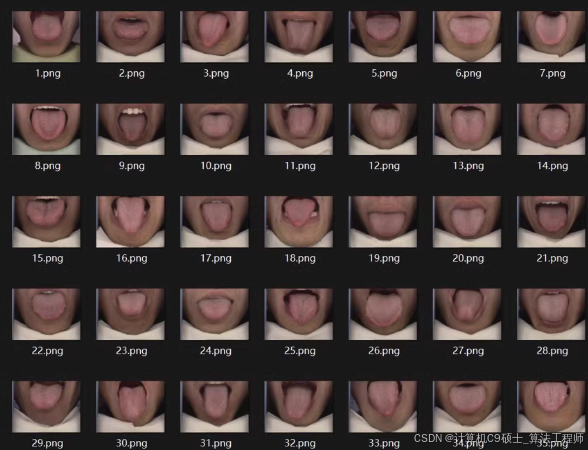
1. 环境搭建
首先,确保你的Python环境已安装必要的库:
pip install torch torchvision numpy matplotlib opencv-python PyQt5
如果你计划使用预训练的UNet++模型,还需要安装segmentation_models_pytorch库:
pip install segmentation-models-pytorch

2. 数据集准备
假设你的数据集已经准备好,并且被正确地分为图像和对应的标签(即分割掩码)。通常情况下,你需要组织数据集如下:
images/: 包含所有原始舌象图片。masks/: 包含对应每个图片的分割掩码。
创建一个简单的数据加载器来读取这些数据:
import os
from torch.utils.data import Dataset, DataLoader
import cv2
import numpy as np
from torchvision.transforms import transforms
class TongueDataset(Dataset):
def __init__(self, img_dir, mask_dir, transform=None):
self.img_dir = img_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(img_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.images[idx])
mask_path = os.path.join(self.mask_dir, self.images[idx].replace('.jpg', '_mask.png')) # 假设掩码文件名以'_mask'结尾
image = cv2.imread(img_path)
mask = cv2.imread(mask_path, 0) # 读取为灰度图
if self.transform:
image = self.transform(image)
mask = self.transform(mask)
return image, mask
3. 模型定义与训练
接下来是使用UNet++进行模型训练的部分。
import segmentation_models_pytorch as smp
import torch
from torch import optim
def train_model():
model = smp.UnetPlusPlus(encoder_name='resnet34', classes=1, activation=None)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
criterion = torch.nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
train_dataset = TongueDataset('path/to/train/images', 'path/to/train/masks', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=8, shuffle=True)
for epoch in range(20): # 训练周期数
model.train()
epoch_loss = 0
for images, masks in train_loader:
images, masks = images.to(device), masks.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, masks.float())
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {epoch_loss}')
torch.save(model.state_dict(), './unetplusplus.pth')
if __name__ == "__main__":
train_model()
4. 测试模型
完成训练后,可以加载训练好的模型并对新图像进行预测。
from PIL import Image
import matplotlib.pyplot as plt
def test_model(image_path):
model = smp.UnetPlusPlus(encoder_name='resnet34', classes=1, activation=None)
model.load_state_dict(torch.load('./unetplusplus.pth'))
model.eval()
image = Image.open(image_path).convert("RGB")
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
image_tensor = transform(image).unsqueeze(0)
with torch.no_grad():
output = model(image_tensor)
output = torch.sigmoid(output).squeeze().cpu().numpy()
plt.imshow(output, cmap='gray')
plt.show()
# 使用方法
test_model('path/to/test/image.jpg')
5. 构建图形用户界面 (GUI)
最后,我们可以利用PyQt5构建一个简单的图形界面,方便用户交互式地选择图像并查看分割结果。
from PyQt5.QtWidgets import QApplication, QWidget, QVBoxLayout, QPushButton, QLabel
from PyQt5.QtGui import QPixmap
import sys
class GUI(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.setWindowTitle('Tongue Segmentation System')
layout = QVBoxLayout()
self.imageLabel = QLabel(self)
layout.addWidget(self.imageLabel)
btn = QPushButton('Load Image', self)
btn.clicked.connect(self.loadImage)
layout.addWidget(btn)
self.setLayout(layout)
def loadImage(self):
fname, _ = QFileDialog.getOpenFileName(self, 'Open file', 'c:\\', "Image files (*.jpg *.png)")
if fname:
pixmap = QPixmap(fname)
self.imageLabel.setPixmap(pixmap.scaled(self.imageLabel.size(), aspectRatioMode=1))
test_model(fname) # 调用之前定义的测试函数
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = GUI()
ex.show()
sys.exit(app.exec_())


















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









