







【大作业-52】基于改进UNET的细胞图像分割系统(unet、unet++、r2net、attention unet以及unet的改进)
🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳
【大作业-52】基于unet的细胞图像分割系统
🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳
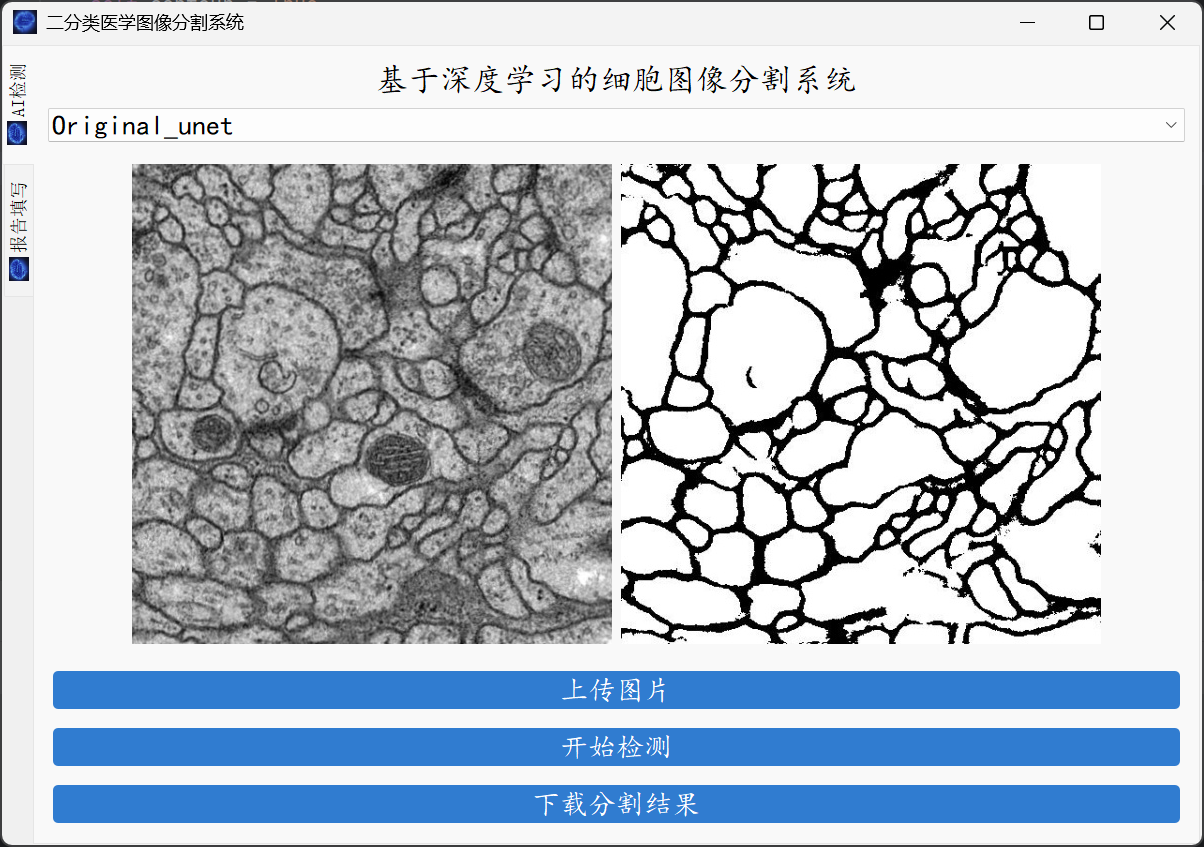
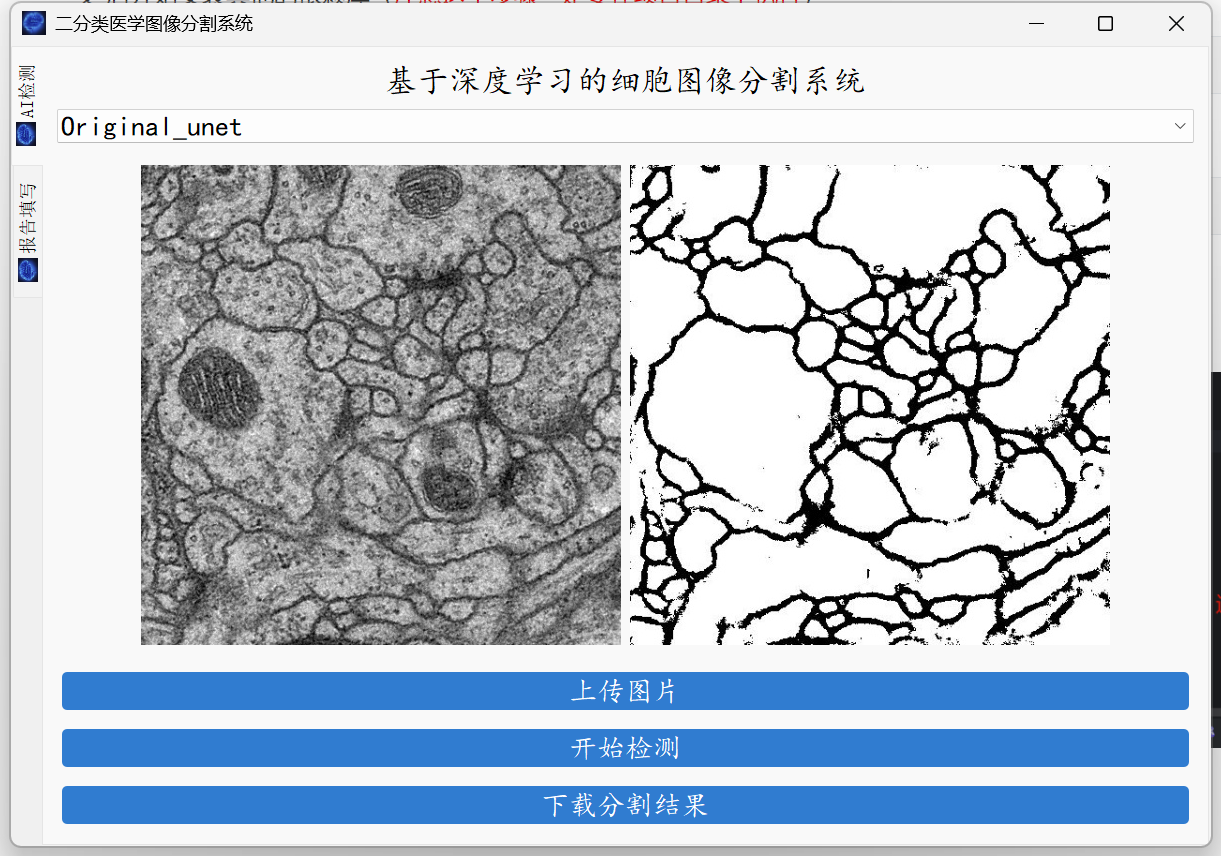
大家好,这里是肆十二!本次,我们为大家带来的是细胞图像分割。细胞图像分割是生物医学研究中的关键任务,对于理解细胞结构、分析细胞功能以及疾病诊断等方面具有重要意义。然而,细胞图像往往具有复杂的背景、多样的形态以及细胞间的相互重叠等特性,这使得传统的分割方法难以准确地提取细胞边界和区域。U-Net作为一种先进的深度学习网络架构,其独特的编码器-解码器结构能够有效捕捉图像的多尺度特征,同时通过跳跃连接将低层次的细节信息与高层次的语义信息相结合,从而在细胞图像分割任务中展现出卓越的性能。它能够自动学习细胞的复杂形状和纹理特征,即使在细胞密集、边界模糊的情况下也能实现高精度的分割,极大地提高了细胞图像分析的效率和准确性,为生物医学研究提供了有力的技术支持。最终实现的效果如下:
(下面这段话是背景意义,主要是帮助没有思绪得朋友凑字数)超声图像分割在医学影像分析中具有重要的临床价值,能够帮助医生精确识别和定位病灶区域,为疾病诊断和治疗规划提供关键依据。然而,超声图像固有的噪声、伪影和低对比度特性使得传统分割方法难以获得理想效果。传统方法通常依赖手工设计特征和先验知识,泛化能力有限,难以应对复杂多变的临床场景。
深度学习方法凭借其强大的特征学习和自动建模能力,为超声图像分割带来了新的突破。通过卷积神经网络(CNN)和Transformer等架构,深度学习能够从大量数据中自动提取多层次特征,有效捕捉图像中的结构信息和上下文关系。此外,U-Net、nnU-Net等网络结构在医学图像分割任务中表现出色,能够实现端到端的像素级分割,显著提升了分割精度和效率。
新增超声图像分割的研究意义在于推动医学影像分析的智能化发展,提高诊断效率和准确性。通过深度学习技术,可以减轻医生的工作负担,减少人为误差,并为个性化治疗提供可靠依据。此外,该技术的进步还能促进远程医疗和基层医疗的发展,使更多患者受益于高质量的医学影像分析服务。未来,结合多模态数据和自监督学习等新兴技术,超声图像分割有望在临床应用中发挥更大作用。
项目实战
原理介绍的部分我们会放置在下方,大家如果对原理或者对文档如何去写不熟悉的小伙伴可以看后面的章节。老规矩,项目请大家在置顶评论中获取,获取之后下载到本地就可以来进行项目的详细配置了。

首先配置之前,如果小伙伴你是python的新手,那请您一定要进行下面内容的学习:Python项目配置前的准备工作_pyenv 设置镜像-CSDN博客
数据集准备
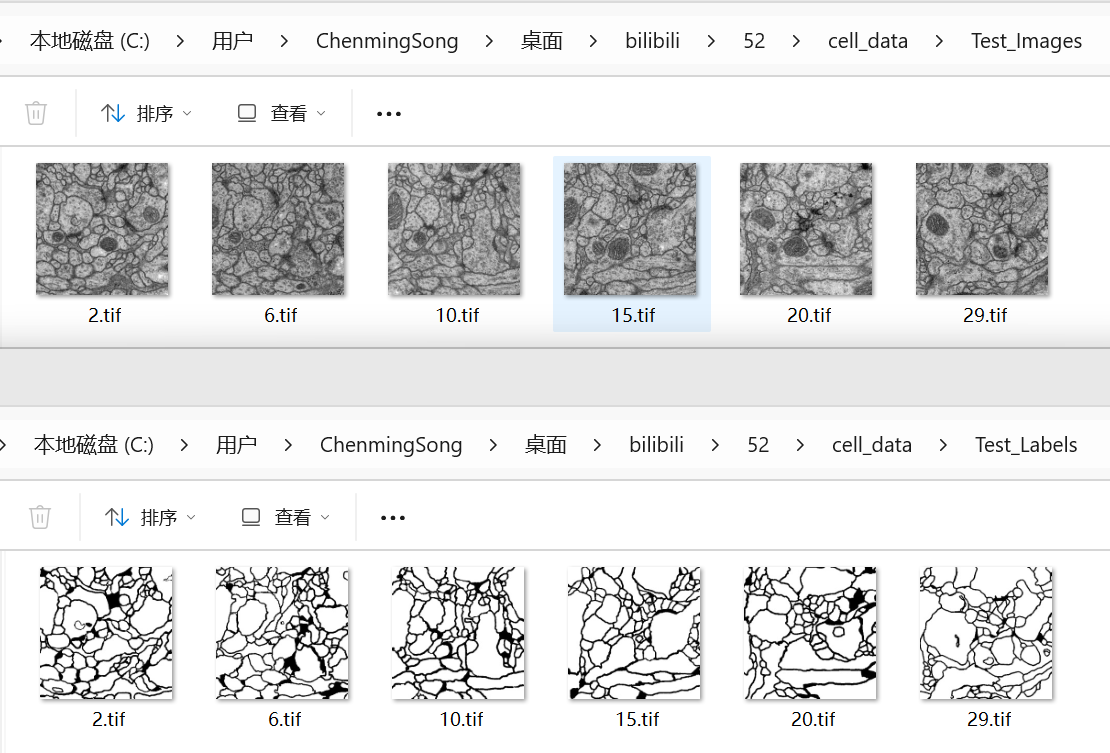
数据集分为训练集和测试集,如下图所示,分别是他们的原始图像和对应的标签文件。
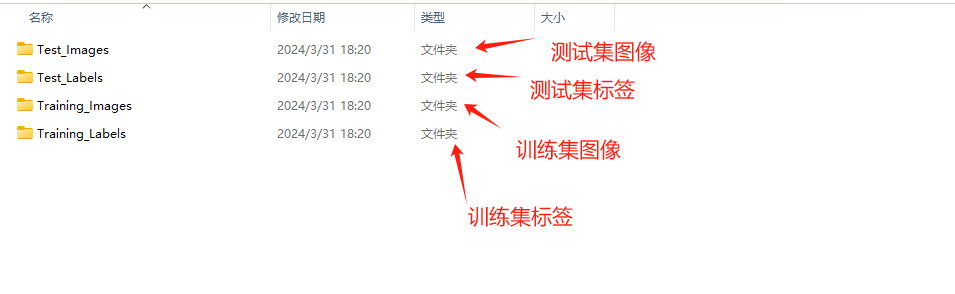
对于图像和标签,一定要注意他们的名称保持一致,只要他们的名称保持一致,后面会省去很多不必要的麻烦。
本地配置
首先我们就是经典的环境配置环境环节。
conda config --remove-key channels
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
conda create -n unet python==3.8.5
y
conda activate unet
在命令行中执行上面的指令之后激活unet的虚拟环境。
之后根据自己实际的设备情况选择合适的pytorch安装指令。
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.10.0 torchvision torchaudio cudatoolkit=11.3 # 30系列以上显卡gpu版本pytorch安装指令
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
之后开始安装其他的依赖库(注意这个步骤一定要在项目目录下执行)
pip install -r requirements.txt
执行完一系列的操作之后,我们直接对图形化的界面进行测试即可。
python window.py
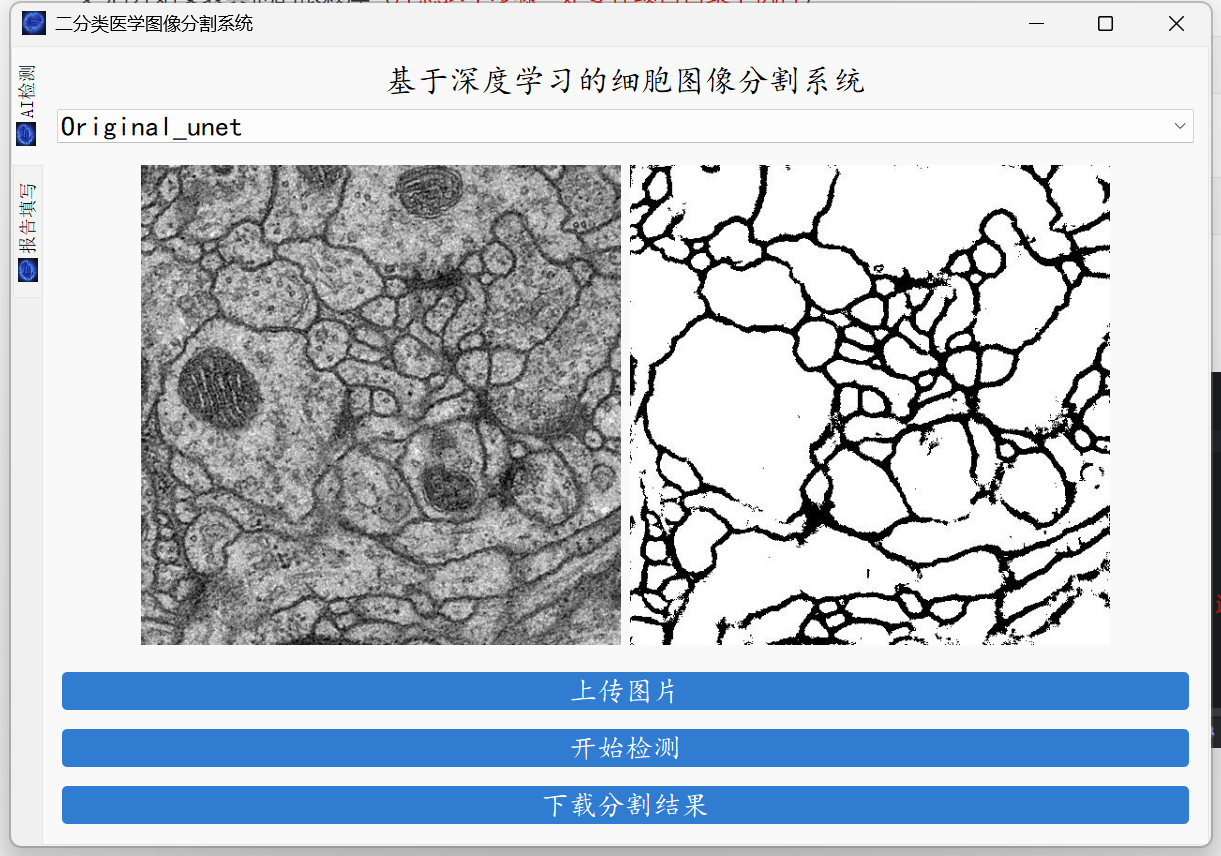
之后再次来到pycharm在pycharm的右下方选择你项目的虚拟环境就可以使用pycharm进行愉快的玩耍了。
模型验证
之后我们可以对我们的模型进行验证,同样的需要修改自己训练好的模型路径以及原始测试集的路径。
语义分割中的评估指标主要用于衡量模型在预测过程中的表现。常用的评估指标包括精确度(Precision)、召回率(Recall)、均值交并比(mIoU)、均值像素准确率(mPA)和Dice系数(Dice Coefficient)。下面对这些指标进行详细说明:
精确度(Precision)
精确度是衡量模型预测为正类的样本中,实际为正类的比例。具体来说,精确度反映了模型预测结果的准确性。其计算公式为:
P
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
{Precision} = \frac{TP}{TP + FP}
Precision=TP+FPTP
其中:
- TP(True Positive):真实正类且被正确预测为正类的像素数。
- FP(False Positive):真实负类但被错误预测为正类的像素数。
精确度越高,表示模型在预测正类时的错误越少,具有较强的精确性。
召回率(Recall)
召回率是衡量模型能够正确识别出实际为正类的像素的比例。换句话说,召回率反映了模型找回正类样本的能力。其计算公式为:
R
e
c
a
l
l
=
T
P
T
P
+
F
N
{Recall} = \frac{TP}{TP + FN}
Recall=TP+FNTP
其中:
- FN(False Negative):真实正类但被错误预测为负类的像素数。
召回率越高,表示模型漏掉的正类样本越少,但可能会牺牲精确度。
均值交并比(mIoU, mean Intersection over Union)
均值交并比(mIoU)是语义分割中最常用的评估指标之一,旨在衡量每个类别的预测结果与真实标签之间的重叠程度。它是计算交集和并集比值的平均值,能够同时考量模型的准确性和鲁棒性。其计算公式为:
I
o
U
i
=
T
P
i
T
P
i
+
F
P
i
+
F
N
i
{IoU}_{i} = \frac{TP_{i}}{TP_{i} + FP_{i} + FN_{i}}
IoUi=TPi+FPi+FNiTPi
其中:
- TP_i:类别 ii 的真实正类且被正确预测为正类的像素数。
- FP_i:类别 ii 的真实负类但被错误预测为正类的像素数。
- FN_i:类别 ii 的真实正类但被错误预测为负类的像素数。
然后计算所有类别的 IoU 的平均值,即为 mIoU:
m
I
o
U
=
1
C
∑
i
=
1
C
IoU
i
{mIoU} = \frac{1}{C} \sum_{i=1}^{C} \text{IoU}_{i}
mIoU=C1i=1∑CIoUi
其中 CC 是类别的总数。mIoU 值越高,表示模型在分割时的表现越好,特别是在不同类别间的均衡表现。
均值像素准确率(mPA, mean Pixel Accuracy)
均值像素准确率是对每个类别的像素级准确率进行平均的结果。像素准确率是指每个类别中被正确分类的像素占该类别总像素数的比例。其计算公式为:
P
A
i
=
T
P
i
T
P
i
+
F
P
i
+
F
N
i
{PA}_{i} = \frac{TP_{i}}{TP_{i} + FP_{i} + FN_{i}}
PAi=TPi+FPi+FNiTPi
然后计算所有类别的平均像素准确率,得到 mPA:
m
P
A
=
1
C
∑
i
=
1
C
PA
i
{mPA} = \frac{1}{C} \sum_{i=1}^{C} \text{PA}_{i}
mPA=C1i=1∑CPAi
mPA 反映了模型对每个类别像素的分类能力,能够更直观地表现出模型在每个类别上的像素级表现。
Dice 系数(Dice Coefficient)
Dice 系数是一个衡量两个集合相似度的指标,广泛用于医学图像分割中。它计算的是预测区域和真实区域的重叠部分与两者的总和之间的比值。其计算公式为:
D
i
c
e
=
2
×
T
P
2
×
T
P
+
F
P
+
F
N
{Dice} = \frac{2 \times TP}{2 \times TP + FP + FN}
Dice=2×TP+FP+FN2×TP
Dice 系数的取值范围是 0 到 1,值越大表示模型的分割结果与真实标签的重合度越高。Dice 系数对类别不平衡问题较为鲁棒,因此在医学图像分割中常常使用。
各指标的总结
- Precision 和 Recall 主要从不同的角度衡量模型在预测正类时的表现,一个注重减少假阳性(Precision),另一个注重减少假阴性(Recall)。
- mIoU 计算了预测与真实标签之间的重叠程度,越高越好。
- mPA 聚焦于每个类别的像素级准确率,适用于多类别的分割任务。
- Dice 系数 是衡量两个区域相似度的一个综合指标,常用于评估医学图像中的目标分割。
这些指标各有侧重,在不同的任务中可能需要选择适合的评估方式。通常,综合考虑多个指标可以更全面地评估分割模型的表现。
以我们的数据为例,下面是改进模型1得到的结果。
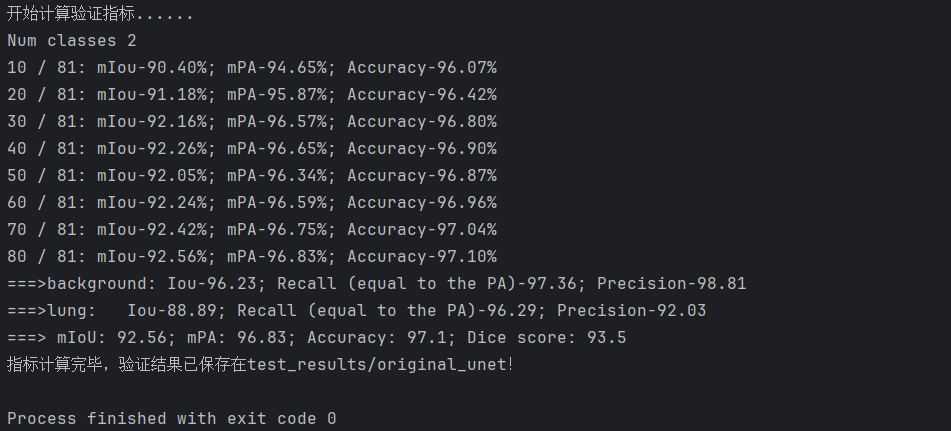
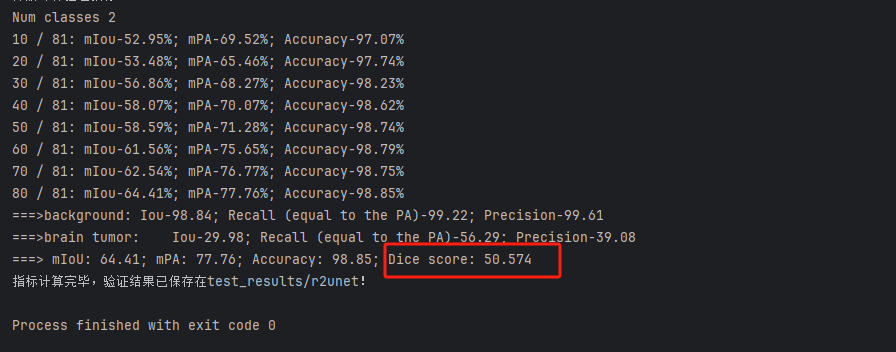
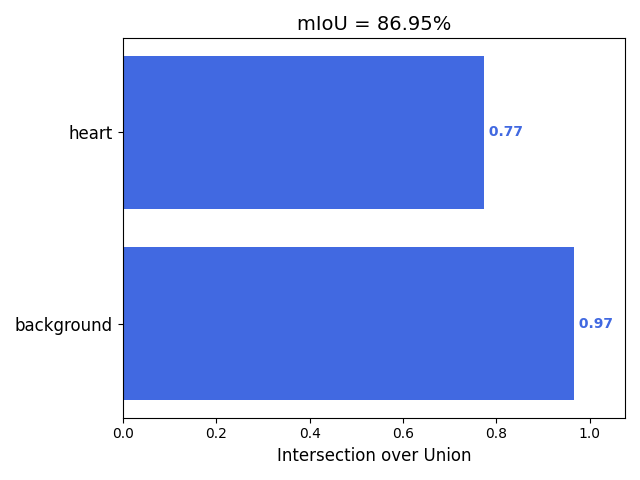
图形化界面封装
最后就是图形化界面的封装了,这里我们使用了pyqt的技术。
如果你是训练了自己的模型,请在下面的位置进行切换。
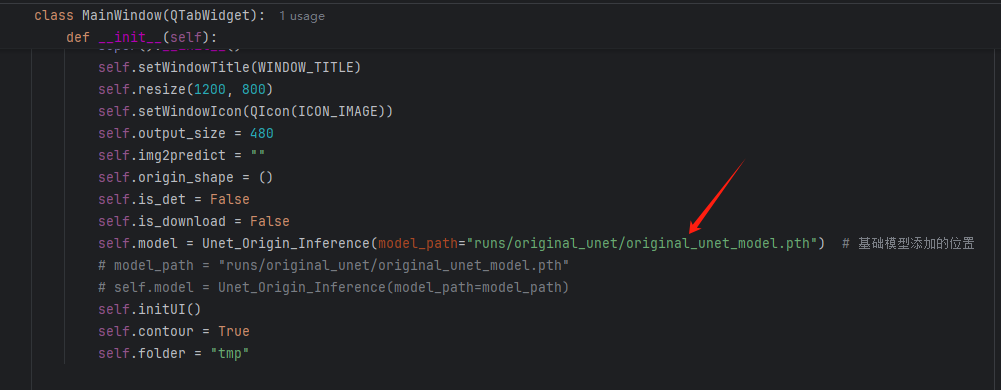
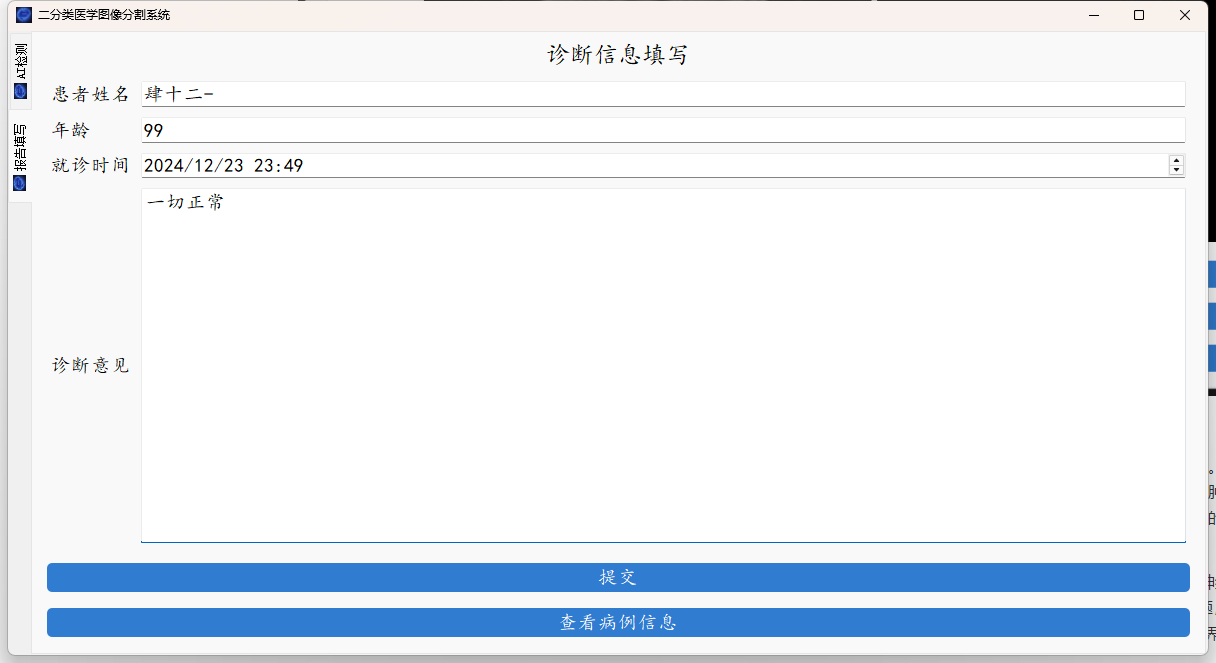
系统支持医学图像的分割、轮廓的查找以及简单的病例的记录。
原理介绍
本次我们主要从一个带改进得实验出发,进行多种网络结构的介绍,在我们的资源目录中附带了每个方法对应的论文,对详细原理感兴趣的小伙伴可以直接去看论文,我们主要以原始的unet作为baseline然后进行改进的实验。改进的实验主要在unet的encoder部分,我们将网络的encoder部分修改为带有预训练的resnet50模型和vgg16模型,另外还有其他的unet的版本。我们下面对这些网络结构进行一一解析。
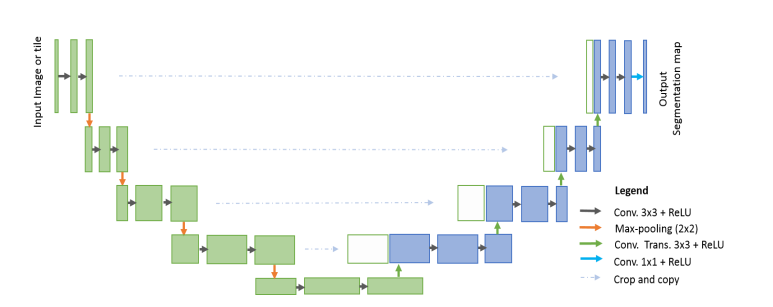
unet
论文地址:
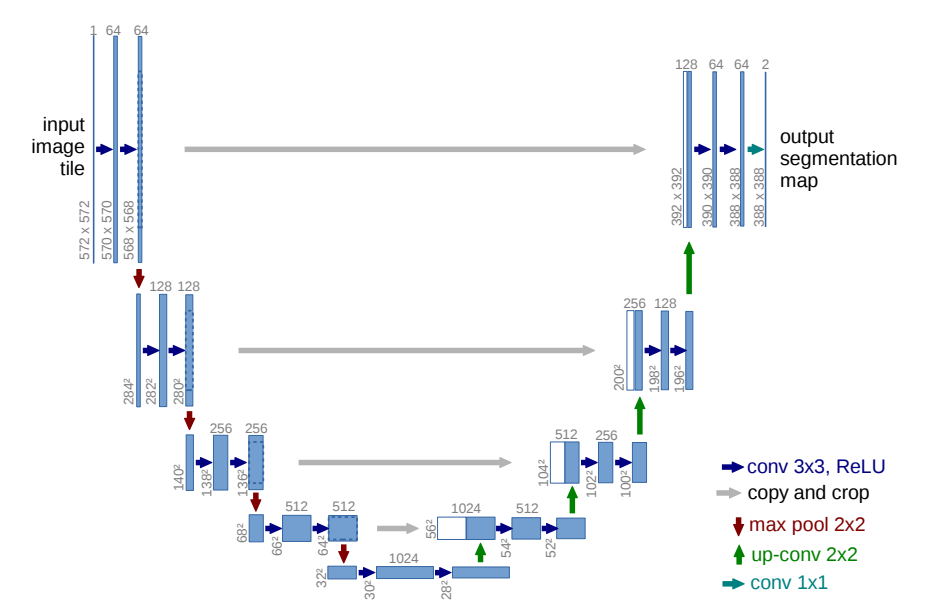
U-Net 是一种经典的用于医学图像分割的卷积神经网络(CNN)架构。它的设计初衷是为了解决医学图像中复杂目标(如肿瘤、器官等)的精确分割问题。U-Net 通过对称的编码器和解码器结构,结合跳跃连接(skip connections),实现了在分割任务中高效的特征提取和精细的空间恢复。
U-Net 的网络结构分为两个主要部分:编码器(下采样部分)和解码器(上采样部分)。编码器部分通常由一系列卷积层和池化层组成,目的是逐步提取图像中的抽象特征并降低空间分辨率。每个卷积层后面跟随一个非线性激活函数(通常是ReLU),用于增强模型的非线性表达能力。池化层(如最大池化)则用于降低空间分辨率并减少计算量。
解码器部分通过上采样逐步恢复图像的空间分辨率。上采样通常通过反卷积层(或转置卷积)实现,目的是将低分辨率的特征图恢复到原始图像的尺寸。解码器中的关键设计是跳跃连接,具体来说,U-Net 会将编码器各层提取的特征图直接传递到解码器对应层进行融合。这种跳跃连接保证了解码器能够使用来自编码器的高分辨率特征,帮助恢复图像的细节,特别是在分割物体的边界部分。
最终,U-Net 使用一个 1x1 的卷积层将解码器的输出映射到所需的分割类别数,生成像素级的分割结果。为了获得更精确的分割结果,输出通常通过一个 Sigmoid(用于二分类)或 Softmax(用于多分类)激活函数进行处理。
U-Net 的优势在于它能够在进行高效特征提取的同时,保留图像中的细节信息,尤其适用于需要精确分割边界的医学图像。通过跳跃连接,U-Net 可以有效地融合来自浅层和深层的特征,使得模型既能捕捉图像的全局语义信息,又不丢失细粒度的局部信息。这使得 U-Net 成为了医学图像分割领域中最常用的深度学习架构之一。
代码实现如下:
""" Full assembly of the parts to form the complete network """
"""Refer https://github.com/milesial/Pytorch-UNet/blob/master/unet/unet_model.py"""
import torch.nn.functional as F
from .unet_parts import *
class UNet_Origin(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet_Origin, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 512)
self.up1 = Up(1024, 256, bilinear)
self.up2 = Up(512, 128, bilinear)
self.up3 = Up(256, 64, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
if __name__ == '__main__':
net = UNet_Origin(n_channels=3, n_classes=1)
print(net)
unet改进1
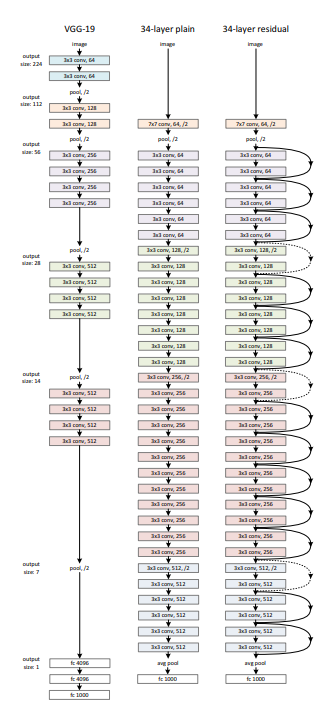
改进1是将原先unet的encoder修改为resnet,并使用其在imagenet上训练的预训练模型。
ResNet(Residual Network)是一种深度卷积神经网络(CNN)架构,主要特点是引入了残差连接(Residual Connection),即跨层跳跃连接,使得网络能够更有效地训练深层网络,并缓解了随着网络深度增加而出现的梯度消失和退化问题。虽然 ResNet 本身并不是专门为图像分割设计的,但其深度残差网络架构被广泛应用于各种视觉任务,包括图像分类、物体检测和图像分割。
ResNet 的核心设计思想是通过引入残差模块(Residual Block)来构建深度网络。每个残差模块由一组卷积层组成,但不同于传统的卷积层堆叠,残差模块通过跳跃连接(skip connection)将输入直接加到卷积输出上,从而形成“输入+卷积输出”的形式。这一设计让网络能够学习“残差”而不是直接学习目标映射,从而减轻了深层网络中信息传递的难度。
ResNet 架构由多个残差模块堆叠而成,其中每个残差模块可以是两层或三层卷积层。每层卷积之后通常会应用批归一化(Batch Normalization)和激活函数(如 ReLU)。在网络的深层,残差模块通常采用更大步幅的卷积来实现下采样(如步幅为 2 的卷积),使得特征图的分辨率逐步降低,同时通过残差连接保留了足够的特征信息。
ResNet 的设计可以有效地增加网络的深度,同时避免了深层网络中常见的退化问题。深度网络能够通过学习残差来“跳过”一些无关的特征,从而更容易训练。对于非常深的网络,ResNet 的残差连接有助于信息流的有效传递,保证了梯度在反向传播过程中的稳定性。
在图像分割任务中,ResNet 通常作为编码器部分的骨干网络(Backbone),负责提取图像的高层次特征。其输出特征图会被传递给解码器部分进行上采样和重建,恢复图像的空间分辨率,最终生成分割结果。在这种应用中,ResNet 通过其深层的特征提取能力,能够捕捉到图像中的复杂语义信息,适应各种分割任务,包括目标检测、医学图像分割等。
总体来说,ResNet 的结构设计使得其在深度学习领域特别适合于处理复杂和大规模的图像分割任务。通过残差连接的引入,网络能够在较深层次上保持有效的学习能力,并在分割任务中提供更加精确和细致的结果。
代码实现如下:
import torch
import torch.nn as nn
from nets.resnet import resnet50
from nets.vgg import VGG16
class unetUp(nn.Module):
def __init__(self, in_size, out_size):
super(unetUp, self).__init__()
self.conv1 = nn.Conv2d(in_size, out_size, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_size, out_size, kernel_size=3, padding=1)
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
self.relu = nn.ReLU(inplace=True)
def forward(self, inputs1, inputs2):
outputs = torch.cat([inputs1, self.up(inputs2)], 1)
outputs = self.conv1(outputs)
outputs = self.relu(outputs)
outputs = self.conv2(outputs)
outputs = self.relu(outputs)
return outputs
class Unet(nn.Module):
def __init__(self, num_classes=21, pretrained=False, backbone='vgg16'):
super(Unet, self).__init__()
if backbone == 'vgg16':
self.vgg = VGG16(pretrained=pretrained)
in_filters = [192, 384, 768, 1024]
elif backbone == "resnet50":
self.resnet = resnet50(pretrained=pretrained)
in_filters = [192, 512, 1024, 3072]
else:
raise ValueError('Unsupported backbone - `{}`, Use vgg, resnet50.'.format(backbone))
out_filters = [64, 128, 256, 512]
# upsampling
# 64,64,512
self.up_concat4 = unetUp(in_filters[3], out_filters[3])
# 128,128,256
self.up_concat3 = unetUp(in_filters[2], out_filters[2])
# 256,256,128
self.up_concat2 = unetUp(in_filters[1], out_filters[1])
# 512,512,64
self.up_concat1 = unetUp(in_filters[0], out_filters[0])
if backbone == 'resnet50':
self.up_conv = nn.Sequential(
nn.UpsamplingBilinear2d(scale_factor=2),
nn.Conv2d(out_filters[0], out_filters[0], kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(out_filters[0], out_filters[0], kernel_size=3, padding=1),
nn.ReLU(),
)
else:
self.up_conv = None
self.final = nn.Conv2d(out_filters[0], num_classes, 1)
self.backbone = backbone
def forward(self, inputs):
if self.backbone == "vgg16":
[feat1, feat2, feat3, feat4, feat5] = self.vgg.forward(inputs)
elif self.backbone == "resnet50":
[feat1, feat2, feat3, feat4, feat5] = self.resnet.forward(inputs)
up4 = self.up_concat4(feat4, feat5)
up3 = self.up_concat3(feat3, up4)
up2 = self.up_concat2(feat2, up3)
up1 = self.up_concat1(feat1, up2)
if self.up_conv != None:
up1 = self.up_conv(up1)
final = self.final(up1)
return final
def freeze_backbone(self):
if self.backbone == "vgg":
for param in self.vgg.parameters():
param.requires_grad = False
elif self.backbone == "resnet50":
for param in self.resnet.parameters():
param.requires_grad = False
def unfreeze_backbone(self):
if self.backbone == "vgg":
for param in self.vgg.parameters():
param.requires_grad = True
elif self.backbone == "resnet50":
for param in self.resnet.parameters():
param.requires_grad = True
unet改进2
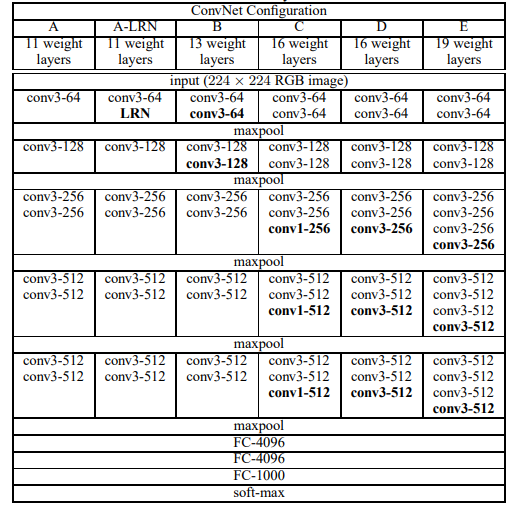
改进1是将原先unet的encoder修改为vgg,并使用其在imagenet上训练的预训练模型。
VGG(Visual Geometry Group)网络是一种经典的卷积神经网络架构,广泛应用于图像分类、目标检测以及图像分割等任务。VGG 网络以其简单而深度的结构而著名,采用了多层堆叠的卷积层和池化层,其特点是每个卷积块中使用相同大小的卷积核(通常为 3x3)和步幅(通常为 1),并通过最大池化层逐步减少空间分辨率,从而有效提取图像的高级特征。
VGG 网络的结构基于层次化的设计,包含多个卷积层和池化层的堆叠。它通常分为若干个卷积块,每个卷积块由多个卷积层和一个池化层组成。VGG 网络的关键设计理念是通过小卷积核(3x3)和步幅为 1 的卷积操作,不断增加网络的深度,同时保持卷积层的感受野逐渐增大。这种设计使得 VGG 能够在较小的感受野内提取细粒度的特征,而深度的堆叠则增加了网络的表达能力。
每个卷积层后面通常跟着一个非线性激活函数(如 ReLU),以增强模型的非线性映射能力。池化层(通常使用最大池化)则用来降低图像的空间维度,减少计算量,同时保持重要的特征信息。通过逐步减少图像的分辨率,VGG 网络能够在较低分辨率的特征图中提取更加抽象和高级的语义信息。
VGG 网络没有使用全连接层来处理特征图的每个像素,而是通过全局池化层(如全局平均池化)或卷积层直接生成固定大小的输出,这种设计使得 VGG 更加高效且适应于多种不同任务。在图像分割任务中,VGG 的输出通常通过卷积层进行处理,再与解码器部分的上采样层结合,恢复图像的空间分辨率,从而进行精细的像素级分割。
在分割网络中,VGG 作为编码器部分,负责从输入图像中提取特征,并将这些特征传递到解码器中。解码器会根据 VGG 提取的特征逐步恢复图像的空间分辨率,最终通过卷积层生成分割结果。
总的来说,VGG 网络的简单结构和高效的特征提取能力使其成为了许多计算机视觉任务中的基础模型,特别是在图像分割任务中,作为骨干网络,VGG 能够有效捕捉图像中的重要信息,同时通过细粒度的卷积操作保持了较高的空间分辨率,有助于提升分割精度。
代码实现如下:
import torch
import torch.nn as nn
from nets.resnet import resnet50
from nets.vgg import VGG16
class unetUp(nn.Module):
def __init__(self, in_size, out_size):
super(unetUp, self).__init__()
self.conv1 = nn.Conv2d(in_size, out_size, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(out_size, out_size, kernel_size=3, padding=1)
self.up = nn.UpsamplingBilinear2d(scale_factor=2)
self.relu = nn.ReLU(inplace=True)
def forward(self, inputs1, inputs2):
outputs = torch.cat([inputs1, self.up(inputs2)], 1)
outputs = self.conv1(outputs)
outputs = self.relu(outputs)
outputs = self.conv2(outputs)
outputs = self.relu(outputs)
return outputs
class Unet(nn.Module):
def __init__(self, num_classes=21, pretrained=False, backbone='vgg16'):
super(Unet, self).__init__()
if backbone == 'vgg16':
self.vgg = VGG16(pretrained=pretrained)
in_filters = [192, 384, 768, 1024]
elif backbone == "resnet50":
self.resnet = resnet50(pretrained=pretrained)
in_filters = [192, 512, 1024, 3072]
else:
raise ValueError('Unsupported backbone - `{}`, Use vgg, resnet50.'.format(backbone))
out_filters = [64, 128, 256, 512]
# upsampling
# 64,64,512
self.up_concat4 = unetUp(in_filters[3], out_filters[3])
# 128,128,256
self.up_concat3 = unetUp(in_filters[2], out_filters[2])
# 256,256,128
self.up_concat2 = unetUp(in_filters[1], out_filters[1])
# 512,512,64
self.up_concat1 = unetUp(in_filters[0], out_filters[0])
if backbone == 'resnet50':
self.up_conv = nn.Sequential(
nn.UpsamplingBilinear2d(scale_factor=2),
nn.Conv2d(out_filters[0], out_filters[0], kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(out_filters[0], out_filters[0], kernel_size=3, padding=1),
nn.ReLU(),
)
else:
self.up_conv = None
self.final = nn.Conv2d(out_filters[0], num_classes, 1)
self.backbone = backbone
def forward(self, inputs):
if self.backbone == "vgg16":
[feat1, feat2, feat3, feat4, feat5] = self.vgg.forward(inputs)
elif self.backbone == "resnet50":
[feat1, feat2, feat3, feat4, feat5] = self.resnet.forward(inputs)
up4 = self.up_concat4(feat4, feat5)
up3 = self.up_concat3(feat3, up4)
up2 = self.up_concat2(feat2, up3)
up1 = self.up_concat1(feat1, up2)
if self.up_conv != None:
up1 = self.up_conv(up1)
final = self.final(up1)
return final
def freeze_backbone(self):
if self.backbone == "vgg":
for param in self.vgg.parameters():
param.requires_grad = False
elif self.backbone == "resnet50":
for param in self.resnet.parameters():
param.requires_grad = False
def unfreeze_backbone(self):
if self.backbone == "vgg":
for param in self.vgg.parameters():
param.requires_grad = True
elif self.backbone == "resnet50":
for param in self.resnet.parameters():
param.requires_grad = True
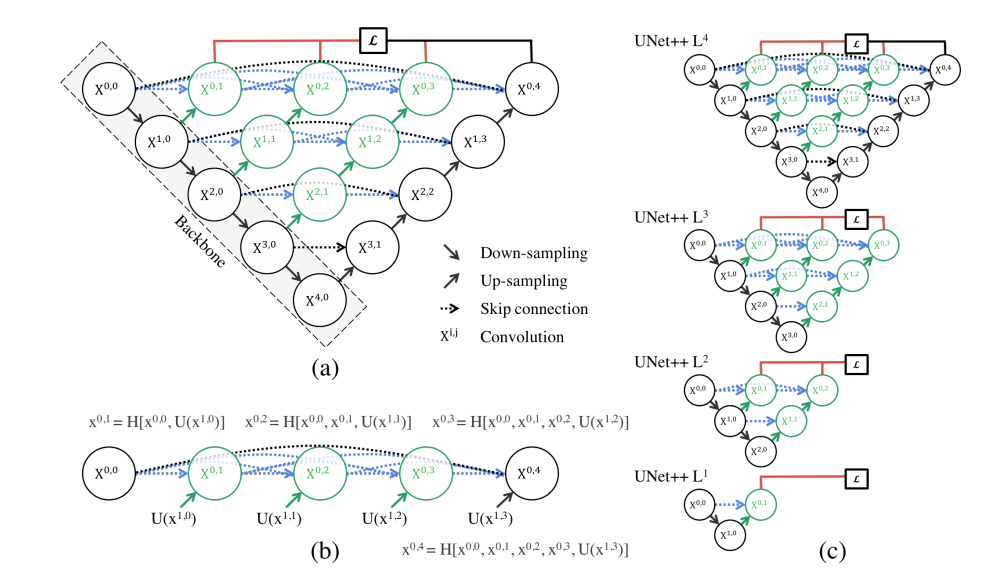
unet++
U-Net++ 是一种改进的 U-Net 分割网络,其主要目标是通过更加细粒度的特征融合与密集的跳跃连接(Dense Skip Connection)机制,进一步提高分割性能。U-Net++ 的设计在 U-Net 的对称编码器-解码器架构基础上进行了增强,使得不同分辨率的特征能够在网络中得到更细致的交互和融合。
U-Net++ 的核心特点在于使用了嵌套和密集的解码路径(Nested and Dense Decoders),同时改进了跳跃连接机制。在传统 U-Net 中,跳跃连接直接将编码器和解码器中相同分辨率的特征进行拼接。而在 U-Net++ 中,跳跃连接由密集卷积模块(Dense Convolution Blocks)代替,使得不同分辨率的特征可以通过逐层细化路径进行多次融合和传递。
U-Net++ 的编码器部分通过一系列卷积、激活(如 ReLU)、批归一化(Batch Normalization)以及最大池化操作提取多尺度特征,与传统 U-Net 相似。但在编码器和解码器之间的跳跃连接上,每一对相邻分辨率的特征图通过一系列密集卷积块逐步传递,而不是简单的直接传递。这些密集卷积块形成了一个嵌套结构,其中高层次特征可以被逐步细化和补充,最终在解码器部分实现更加精准的分割。
解码器部分逐步恢复特征图的空间分辨率,并结合从编码器传递来的多层特征。与传统 U-Net 不同的是,U-Net++ 的解码路径由多个级联的解码子路径组成,这些子路径通过共享特征融合的信息层层优化特征表示。这样,网络能够有效地综合浅层特征的细节信息和深层特征的语义信息。
输出层采用 1x1 卷积,将解码器最终的特征映射到与分割类别数相同的通道数。结合 Sigmoid 或 Softmax 激活函数,生成每个像素的分割概率图。
U-Net++ 的主要优点是通过密集跳跃连接和嵌套解码路径增强了特征的重用性与细粒度融合,使网络对边界复杂的目标区域具有更强的分割能力。此外,这种设计还提升了模型的鲁棒性和泛化能力,特别适合应用于医学图像分割任务中的复杂形态学特征提取。
代码实现如下:
# -*- coding: utf-8 -*-
"""
Implementation of this paper:
https://arxiv.org/pdf/1807.10165.pdf
"""
# import print_function, division
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data
import torch
class conv_block(nn.Module):
"""
Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True),
nn.Conv2d(out_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True))
def forward(self, x):
x = self.conv(x)
return x
class up_conv(nn.Module):
"""
Up Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x
class conv_block_nested(nn.Module):
def __init__(self, in_ch, mid_ch, out_ch):
super(conv_block_nested, self).__init__()
self.activation = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_ch, mid_ch, kernel_size=3, padding=1, bias=True)
self.bn1 = nn.BatchNorm2d(mid_ch)
self.conv2 = nn.Conv2d(mid_ch, out_ch, kernel_size=3, padding=1, bias=True)
self.bn2 = nn.BatchNorm2d(out_ch)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.activation(x)
x = self.conv2(x)
x = self.bn2(x)
output = self.activation(x)
return output
class NestedUNet(nn.Module):
"""
Implementation of this paper:
https://arxiv.org/pdf/1807.10165.pdf
"""
def __init__(self, in_ch=3, out_ch=2):
super(NestedUNet, self).__init__()
n1 = 64
filters = [n1, n1 * 2, n1 * 4, n1 * 8, n1 * 16]
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = conv_block_nested(in_ch, filters[0], filters[0])
self.conv1_0 = conv_block_nested(filters[0], filters[1], filters[1])
self.conv2_0 = conv_block_nested(filters[1], filters[2], filters[2])
self.conv3_0 = conv_block_nested(filters[2], filters[3], filters[3])
self.conv4_0 = conv_block_nested(filters[3], filters[4], filters[4])
self.conv0_1 = conv_block_nested(filters[0] + filters[1], filters[0], filters[0])
self.conv1_1 = conv_block_nested(filters[1] + filters[2], filters[1], filters[1])
self.conv2_1 = conv_block_nested(filters[2] + filters[3], filters[2], filters[2])
self.conv3_1 = conv_block_nested(filters[3] + filters[4], filters[3], filters[3])
self.conv0_2 = conv_block_nested(filters[0] * 2 + filters[1], filters[0], filters[0])
self.conv1_2 = conv_block_nested(filters[1] * 2 + filters[2], filters[1], filters[1])
self.conv2_2 = conv_block_nested(filters[2] * 2 + filters[3], filters[2], filters[2])
self.conv0_3 = conv_block_nested(filters[0] * 3 + filters[1], filters[0], filters[0])
self.conv1_3 = conv_block_nested(filters[1] * 3 + filters[2], filters[1], filters[1])
self.conv0_4 = conv_block_nested(filters[0] * 4 + filters[1], filters[0], filters[0])
self.final = nn.Conv2d(filters[0], out_ch, kernel_size=1)
def forward(self, x):
x0_0 = self.conv0_0(x)
x1_0 = self.conv1_0(self.pool(x0_0))
x0_1 = self.conv0_1(torch.cat([x0_0, self.Up(x1_0)], 1))
x2_0 = self.conv2_0(self.pool(x1_0))
x1_1 = self.conv1_1(torch.cat([x1_0, self.Up(x2_0)], 1))
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.Up(x1_1)], 1))
x3_0 = self.conv3_0(self.pool(x2_0))
x2_1 = self.conv2_1(torch.cat([x2_0, self.Up(x3_0)], 1))
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.Up(x2_1)], 1))
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.Up(x1_2)], 1))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.Up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.Up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.Up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.Up(x1_3)], 1))
output = self.final(x0_4)
return output
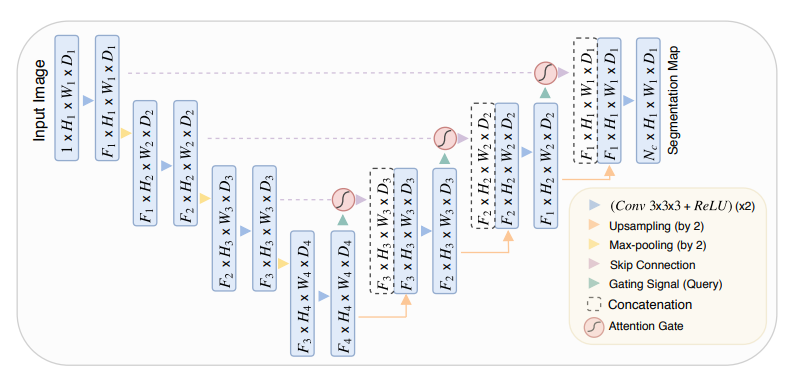
attention unet
Attention U-Net 是一种改进的 U-Net 分割网络,通过引入注意力机制(Attention Mechanism),增强了网络对目标区域的聚焦能力,尤其在医学图像分割任务中表现出色。它在保留 U-Net 对称编码器-解码器结构的基础上,结合了注意力门(Attention Gate, AG),使网络能够自动突出感兴趣区域的特征,同时抑制不相关的背景信息。
Attention U-Net 的整体架构由编码器、解码器和注意力模块组成:
编码器部分负责提取输入图像的多尺度特征。输入图像经过一系列卷积操作、激活函数(通常是ReLU)、批归一化(Batch Normalization)以及最大池化操作,逐步降低分辨率并提取深层特征。
解码器部分逐步恢复特征图的空间分辨率。通过上采样操作(如反卷积或双线性插值),解码器结合编码器的高分辨率特征图恢复目标区域的细节。跳跃连接(Skip Connection)在解码过程中将编码器的特征图直接传递给对应的解码层,确保局部细节信息不丢失。
注意力机制是 Attention U-Net 的核心改进。网络在跳跃连接中引入了注意力门模块,用于选择性地突出相关特征并过滤掉无关区域。注意力门通过计算特征图中的权重分布,使网络更加聚焦于感兴趣区域(如病灶或解剖结构)。具体来说,注意力门会对编码器的特征图和解码器的特征图进行加权融合,生成注意力掩膜(Attention Mask),从而动态调整特征图的权重。这样可以有效提高网络对目标边界的敏感性,同时减少背景噪声的干扰。
最终输出层通过 1x1 的卷积操作生成分割结果,通道数与分割类别数相同。激活函数(如Sigmoid或Softmax)将网络输出映射为像素级概率,用于生成分割掩膜。
Attention U-Net 的优点在于其通过注意力机制显著提高了分割的准确性和鲁棒性,特别是在目标区域较小或边界复杂的情况下。它不仅能增强对感兴趣区域的响应,还能有效降低背景区域的干扰,适用于各种高精度要求的医学图像分割任务。
代码实现如下:
from torch import nn
from torch.nn import functional as F
import torch
from torchvision import models
import torchvision
class conv_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True),
nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x
class up_conv(nn.Module):
def __init__(self, ch_in, ch_out):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x
class Attention_block(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
# 下采样的gating signal 卷积
g1 = self.W_g(g)
# 上采样的 l 卷积
x1 = self.W_x(x)
# concat + relu
psi = self.relu(g1 + x1)
# channel 减为1,并Sigmoid,得到权重矩阵
psi = self.psi(psi)
# 返回加权的 x
return x * psi
class AttU_Net(nn.Module):
def __init__(self, img_ch=3, output_ch=2):
super(AttU_Net, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=img_ch, ch_out=64)
self.Conv2 = conv_block(ch_in=64, ch_out=128)
self.Conv3 = conv_block(ch_in=128, ch_out=256)
self.Conv4 = conv_block(ch_in=256, ch_out=512)
self.Conv5 = conv_block(ch_in=512, ch_out=1024)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Att5 = Attention_block(F_g=512, F_l=512, F_int=256)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Att4 = Attention_block(F_g=256, F_l=256, F_int=128)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Att3 = Attention_block(F_g=128, F_l=128, F_int=64)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Att2 = Attention_block(F_g=64, F_l=64, F_int=32)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64, output_ch, kernel_size=1, stride=1, padding=0)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# encoding path
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
x4 = self.Att5(g=d5, x=x4)
d5 = torch.cat((x4, d5), dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4, x=x3)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3, x=x2)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2, x=x1)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
d1 = self.sigmoid(d1)
return d1
r2unet
R2U-Net 是一种改进的 U-Net 网络,专为医学图像分割任务设计。它结合了 U-Net 的经典架构与循环残差机制(Recurrent Residual Mechanism),以提升特征提取能力和模型的分割性能。
R2U-Net 的编码器和解码器结构基于 U-Net,对称的下采样和上采样过程确保了全局上下文和局部细节信息的融合。在此基础上,R2U-Net 在每个卷积块中引入了循环残差单元(Recurrent Residual Unit, RRU)。RRU 是循环神经网络和残差网络的结合,通过在时间维度上迭代更新特征映射,使网络能够捕捉更丰富的上下文信息,同时减少梯度消失问题。
在编码器部分,输入图像经过卷积和最大池化操作逐步提取特征。与传统 U-Net 不同的是,R2U-Net 在每个特征提取阶段使用循环残差单元来增强网络的记忆能力和特征表达能力。循环残差单元在多个时间步内对特征进行迭代更新,这种递归机制允许网络更深入地提取多尺度和复杂的特征信息。
解码器部分采用上采样操作逐步恢复空间分辨率,同时通过跳跃连接(Skip Connection)将编码器的高分辨率特征融合到解码器中,以增强分割的细节恢复能力。在解码阶段同样使用循环残差单元来保留丰富的上下文信息并减轻信息损失。
R2U-Net 的输出层通常通过一个 1x1 的卷积生成分割结果,输出的通道数等于需要分割的类别数。最后结合 Sigmoid 或 Softmax 激活函数来生成像素级的分割概率图。
R2U-Net 的优点在于其能够更有效地捕捉图像中的上下文和全局信息,同时通过残差连接减轻深层网络的梯度消失问题。这种结构对医学图像中复杂的目标(如病灶区域)具有更强的分割能力,同时能够处理不规则形状和边界模糊的目标区域。
代码实现如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
class up_conv(nn.Module):
def __init__(self, ch_in, ch_out):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x
class Recurrent_block(nn.Module):
def __init__(self, ch_out, t=2):
super(Recurrent_block, self).__init__()
self.t = t
self.ch_out = ch_out
self.conv = nn.Sequential(
nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
for i in range(self.t):
if i == 0:
x1 = self.conv(x)
x1 = self.conv(x + x1)
return x1
class RRCNN_block(nn.Module):
def __init__(self, ch_in, ch_out, t=2):
super(RRCNN_block, self).__init__()
self.RCNN = nn.Sequential(
Recurrent_block(ch_out, t=t),
Recurrent_block(ch_out, t=t)
)
self.Conv_1x1 = nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.Conv_1x1(x)
x1 = self.RCNN(x)
return x + x1
class R2U_Net(nn.Module):
"""
R2U-Unet implementation
Paper: https://arxiv.org/abs/1802.06955
"""
def __init__(self, img_ch=3, output_ch=2, t=2):
super(R2U_Net, self).__init__()
n1 = 64
filters = [n1, n1 * 2, n1 * 4, n1 * 8, n1 * 16]
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.Upsample = nn.Upsample(scale_factor=2)
self.RRCNN1 = RRCNN_block(img_ch, filters[0], t=t)
self.RRCNN2 = RRCNN_block(filters[0], filters[1], t=t)
self.RRCNN3 = RRCNN_block(filters[1], filters[2], t=t)
self.RRCNN4 = RRCNN_block(filters[2], filters[3], t=t)
self.RRCNN5 = RRCNN_block(filters[3], filters[4], t=t)
self.Up5 = up_conv(filters[4], filters[3])
self.Up_RRCNN5 = RRCNN_block(filters[4], filters[3], t=t)
self.Up4 = up_conv(filters[3], filters[2])
self.Up_RRCNN4 = RRCNN_block(filters[3], filters[2], t=t)
self.Up3 = up_conv(filters[2], filters[1])
self.Up_RRCNN3 = RRCNN_block(filters[2], filters[1], t=t)
self.Up2 = up_conv(filters[1], filters[0])
self.Up_RRCNN2 = RRCNN_block(filters[1], filters[0], t=t)
self.Conv = nn.Conv2d(filters[0], output_ch, kernel_size=1, stride=1, padding=0)
# self.active = torch.nn.Sigmoid()
def forward(self, x):
e1 = self.RRCNN1(x)
e2 = self.Maxpool(e1)
e2 = self.RRCNN2(e2)
e3 = self.Maxpool1(e2)
e3 = self.RRCNN3(e3)
e4 = self.Maxpool2(e3)
e4 = self.RRCNN4(e4)
e5 = self.Maxpool3(e4)
e5 = self.RRCNN5(e5)
d5 = self.Up5(e5)
d5 = torch.cat((e4, d5), dim=1)
d5 = self.Up_RRCNN5(d5)
d4 = self.Up4(d5)
d4 = torch.cat((e3, d4), dim=1)
d4 = self.Up_RRCNN4(d4)
d3 = self.Up3(d4)
d3 = torch.cat((e2, d3), dim=1)
d3 = self.Up_RRCNN3(d3)
d2 = self.Up2(d3)
d2 = torch.cat((e1, d2), dim=1)
d2 = self.Up_RRCNN2(d2)
out = self.Conv(d2)
# out = self.active(out)
return out
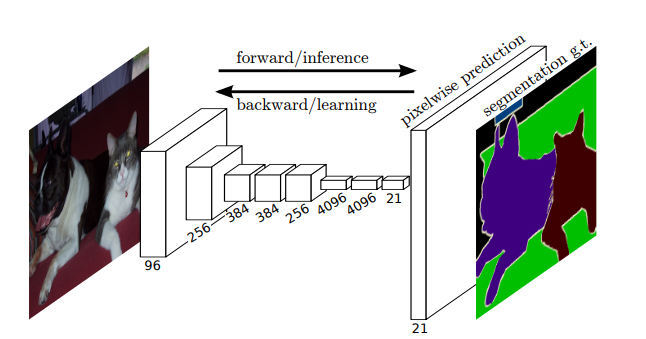
fcn
FCN(Fully Convolutional Network,完全卷积网络)是一种专门用于图像分割任务的神经网络架构,它的设计思想是在传统的卷积神经网络(CNN)的基础上,去除全连接层,并用卷积层替代,使得网络能够接受任意尺寸的输入并生成相同尺寸的输出。
FCN的核心结构由多个卷积层组成,卷积层对输入图像进行特征提取,逐层提取更加抽象的特征信息。通过这种方式,FCN能够生成高分辨率的特征图,并在此基础上进行像素级的分类,进而实现图像分割。
首先,FCN使用了一系列标准的卷积层来进行初步的特征提取,接着这些卷积层会产生较低分辨率的特征图。为了保持输出的空间分辨率,FCN采用了一种上采样(或反卷积)操作。反卷积层通过学习一个转换映射,将低分辨率的特征图恢复到较高的分辨率,从而得到像素级的分类输出。这种上采样操作可以逐步恢复图像的空间结构,使得最终输出的分割结果具有和输入图像相同的尺寸。
在FCN中,卷积层的输入和输出都是特征图,不同于传统CNN中的输入为图像、输出为分类结果。通过这种结构,FCN不仅能够进行像素级分类,而且能够适应不同尺寸的图像输入,从而提高了网络的灵活性和应用范围。
此外,FCN还采用了一些策略来优化网络性能。为了进一步提高分割精度,FCN使用了跳跃连接(skip connections),通过将低层次的特征图与高层次的特征图结合,网络能够更好地捕捉细节信息。这些跳跃连接帮助网络弥补了上采样过程中可能丢失的空间细节,使得分割结果更加精细。
总的来说,FCN是一种非常有效的图像分割模型,能够实现端到端的训练,并能够处理各种不同大小的图像输入。通过卷积层、上采样层和跳跃连接的结合,FCN能够生成高质量的图像分割结果,并且在许多实际应用中取得了优异的表现。
代码实现如下:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models
from torchvision.models.vgg import VGG
import torch
import torch.nn as nn
# from .utils import load_state_dict_from_url
__all__ = [
'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19',
]
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def _vgg(arch, cfg, batch_norm, pretrained, progress, **kwargs):
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def vgg11(pretrained=False, progress=True, **kwargs):
r"""VGG 11-layer model (configuration "A") from
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg11', 'A', False, pretrained, progress, **kwargs)
def vgg11_bn(pretrained=False, progress=True, **kwargs):
r"""VGG 11-layer model (configuration "A") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg11_bn', 'A', True, pretrained, progress, **kwargs)
def vgg13(pretrained=False, progress=True, **kwargs):
r"""VGG 13-layer model (configuration "B")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg13', 'B', False, pretrained, progress, **kwargs)
def vgg13_bn(pretrained=False, progress=True, **kwargs):
r"""VGG 13-layer model (configuration "B") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg13_bn', 'B', True, pretrained, progress, **kwargs)
def vgg16(pretrained=False, progress=True, **kwargs):
r"""VGG 16-layer model (configuration "D")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg16', 'D', False, pretrained, progress, **kwargs)
def vgg16_bn(pretrained=False, progress=True, **kwargs):
r"""VGG 16-layer model (configuration "D") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg16_bn', 'D', True, pretrained, progress, **kwargs)
def vgg19(pretrained=False, progress=True, **kwargs):
r"""VGG 19-layer model (configuration "E")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg19', 'E', False, pretrained, progress, **kwargs)
def vgg19_bn(pretrained=False, progress=True, **kwargs):
r"""VGG 19-layer model (configuration 'E') with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg19_bn', 'E', True, pretrained, progress, **kwargs)
class FCN32s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(64, n_class, kernel_size=1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# print(x.shape)
output = self.pretrained_net(x)
# print(output['x1'].shape)
# print(output['x2'].shape)
# print(output['x3'].shape)
# print(output['x4'].shape)
x4 = output['x4'] # size=(N, 512, x.H/32, x.W/32)
# print(x5.shape)
score = self.bn1(self.relu(self.deconv1(x4))) # size=(N, 512, x.H/16, x.W/16)
# print(score.shape)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
# print(score.shape)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
# print(score.shape)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
# print(score.shape)
# score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
score = self.sigmoid(score)
# print(score.shape)
return score # size=(N, n_class, x.H/1, x.W/1)
class FCN16s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
score = self.relu(self.deconv1(x5)) # size=(N, 512, x.H/16, x.W/16)
score = self.bn1(score + x4) # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
class FCN8s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
x3 = output['x3'] # size=(N, 256, x.H/8, x.W/8)
score = self.relu(self.deconv1(x5)) # size=(N, 512, x.H/16, x.W/16)
score = self.bn1(score + x4) # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.relu(self.deconv2(score)) # size=(N, 256, x.H/8, x.W/8)
score = self.bn2(score + x3) # element-wise add, size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
score = nn.Sigmoid()(score)
return score # size=(N, n_class, x.H/1, x.W/1)
class FCNs(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
self.n_class = n_class
self.pretrained_net = pretrained_net
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
x5 = output['x5'] # size=(N, 512, x.H/32, x.W/32)
x4 = output['x4'] # size=(N, 512, x.H/16, x.W/16)
x3 = output['x3'] # size=(N, 256, x.H/8, x.W/8)
x2 = output['x2'] # size=(N, 128, x.H/4, x.W/4)
x1 = output['x1'] # size=(N, 64, x.H/2, x.W/2)
score = self.bn1(self.relu(self.deconv1(x5))) # size=(N, 512, x.H/16, x.W/16)
score = score + x4 # element-wise add, size=(N, 512, x.H/16, x.W/16)
score = self.bn2(self.relu(self.deconv2(score))) # size=(N, 256, x.H/8, x.W/8)
score = score + x3 # element-wise add, size=(N, 256, x.H/8, x.W/8)
score = self.bn3(self.relu(self.deconv3(score))) # size=(N, 128, x.H/4, x.W/4)
score = score + x2 # element-wise add, size=(N, 128, x.H/4, x.W/4)
score = self.bn4(self.relu(self.deconv4(score))) # size=(N, 64, x.H/2, x.W/2)
score = score + x1 # element-wise add, size=(N, 64, x.H/2, x.W/2)
score = self.bn5(self.relu(self.deconv5(score))) # size=(N, 32, x.H, x.W)
score = self.classifier(score) # size=(N, n_class, x.H/1, x.W/1)
return score # size=(N, n_class, x.H/1, x.W/1)
class VGGNet(VGG):
def __init__(self, pretrained=True, model='vgg16', requires_grad=True, remove_fc=True, show_params=False):
super().__init__(make_layers(cfg[model]))
self.ranges = ranges[model]
if pretrained:
exec("self.load_state_dict(models.%s(pretrained=True).state_dict())" % model)
if not requires_grad:
for param in super().parameters():
param.requires_grad = False
if remove_fc: # delete redundant fully-connected layer params, can save memory
del self.classifier
if show_params:
for name, param in self.named_parameters():
print(name, param.size())
def forward(self, x):
output = {}
# get the output of each maxpooling layer (5 maxpool in VGG net)
for idx in range(len(self.ranges)):
for layer in range(self.ranges[idx][0], self.ranges[idx][1]):
x = self.features[layer](x)
output["x%d" % (idx + 1)] = x
return output
ranges = {
'vgg11': ((0, 3), (3, 6), (6, 11), (11, 16), (16, 21)),
'vgg13': ((0, 5), (5, 10), (10, 15), (15, 20), (20, 25)),
'vgg16': ((0, 5), (5, 10), (10, 17), (17, 24), (24, 31)),
'vgg19': ((0, 5), (5, 10), (10, 19), (19, 28), (28, 37))
}
# cropped version from https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py
cfg = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
def get_fcn32s(n_class=1):
vgg_model = VGGNet(requires_grad=True)
return FCN32s(pretrained_net=vgg_model, n_class=n_class)
def get_fcn8s(n_class=1):
vgg_model = VGGNet(requires_grad=True)
return FCN8s(pretrained_net=vgg_model, n_class=n_class)


















 2502
2502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











