






list_1 = [1, [22, 33, 44], (5, 6, 7), {"name": "Sarah"}]
- 浅拷贝
# list\_3 = list\_1 # 错误!!!
list_2 = list_1.copy() # 或者list\_1[:] \ list(list\_1) 均可实习浅拷贝
- 对浅拷贝前后两列表分别进行操作
list_2[1].append(55)
print("list\_1: ", list_1)
print("list\_2: ", list_2)
list_1: [1, [22, 33, 44, 55], (5, 6, 7), {'name': 'Sarah'}]
list_2: [1, [22, 33, 44, 55], (5, 6, 7), {'name': 'Sarah'}]
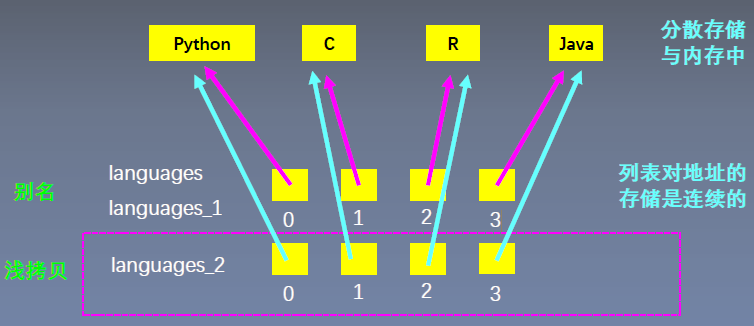
2、列表的底层实现
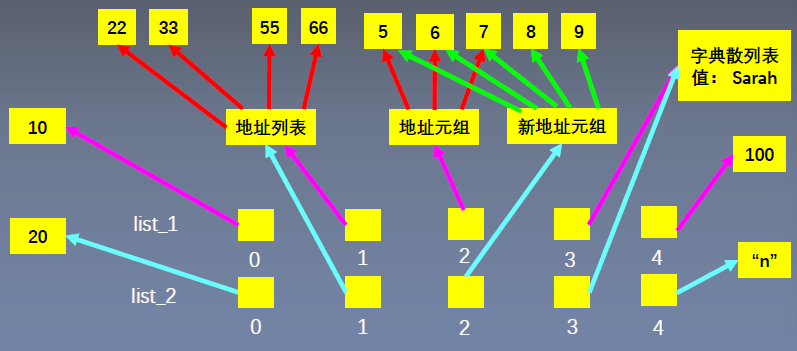
引用数组的概念
列表内的元素可以分散的存储在内存中
列表存储的,实际上是这些元素的地址!!!——地址的存储在内存中是连续的
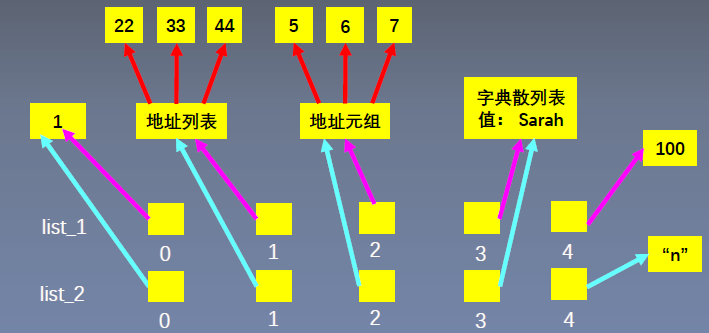
list_1 = [1, [22, 33, 44], (5, 6, 7), {"name": "Sarah"}]
list_2 = list(list_1) # 浅拷贝 与list\_1.copy()功能一样
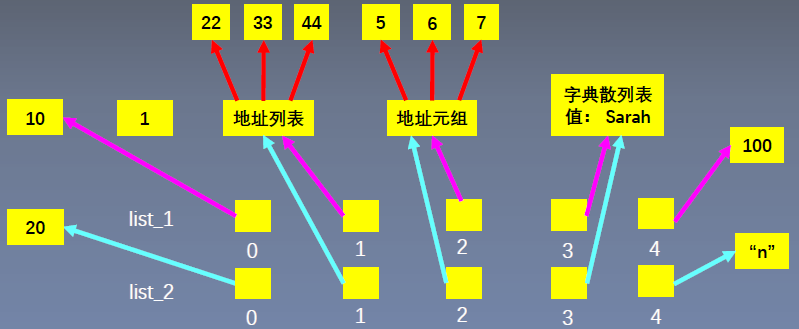
(1)新增元素
list_1.append(100)
list_2.append("n")
print("list\_1: ", list_1)
print("list\_2: ", list_2)
list_1: [1, [22, 33, 44], (5, 6, 7), {'name': 'Sarah'}, 100]
list_2: [1, [22, 33, 44], (5, 6, 7), {'name': 'Sarah'}, 'n']
(2)修改元素
list_1[0] = 10
list_2[0] = 20
print("list\_1: ", list_1)
print("list\_2: ", list_2)
list_1: [10, [22, 33, 44], (5, 6, 7), {'name': 'Sarah'}, 100]
list_2: [20, [22, 33, 44], (5, 6, 7), {'name': 'Sarah'}, 'n']
(3)对列表型元素进行操作
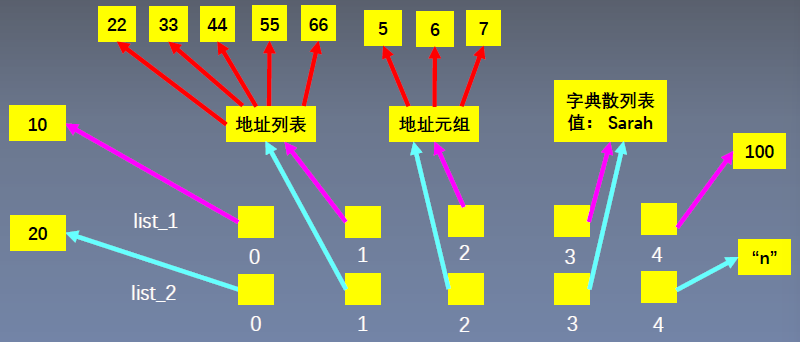
list_1[1].remove(44)
list_2[1] += [55, 66]
print("list\_1: ", list_1)
print("list\_2: ", list_2)
list_1: [10, [22, 33, 55, 66], (5, 6, 7), {'name': 'Sarah'}, 100]
list_2: [20, [22, 33, 55, 66], (5, 6, 7), {'name': 'Sarah'}, 'n']
因为操作的是列表,而原列表映射的是地址,修改元素后对地址进行映射,因此list1和2的修改相同
(4)对元组型元素进行操作
list_2[2] += (8,9)
print("list\_1: ", list_1)
print("list\_2: ", list_2)
list_1: [10, [22, 33, 55, 66], (5, 6, 7), {'name': 'Sarah'}, 100]
list_2: [20, [22, 33, 55, 66], (5, 6, 7, 8, 9), {'name': 'Sarah'}, 'n']
元组是不可变的!!!相当于新加了一个元组(5, 6, 7, 8, 9),而list2指向该元组。
(5)对字典型元素进行操作
list_1[-2]["age"] = 18
print("list\_1: ", list_1)
print("list\_2: ", list_2)
list_1: [10, [22, 33, 55, 66], (5, 6, 7), {'name': 'Sarah', 'age': 18}, 100]
list_2: [20, [22, 33, 55, 66], (5, 6, 7, 8, 9), {'name': 'Sarah', 'age': 18}, 'n']
- 列表字典这种可变的类型,内容发生改变,地址不会变
- 而像元组,数字,字符串等不可变类型,内容发生改变,地址就会发生改变
3、引入深拷贝
浅拷贝之后
- 针对不可变元素(数字、字符串、元组)的操作,都各自生效了
- 针对不可变元素(列表、集合)的操作,发生了一些混淆
引入深拷贝
- 深拷贝将所有层级的相关元素全部复制,完全分开,泾渭分明,避免了上述问题
import copy
list_1 = [1, [22, 33, 44], (5, 6, 7), {"name": "Sarah"}]
list_2 = copy.deepcopy(list_1)
list_1[-1]["age"] = 18
list_2[1].append(55)
print("list\_1: ", list_1)
print("list\_2: ", list_2)
list_1: [1, [22, 33, 44], (5, 6, 7), {'name': 'Sarah', 'age': 18}]
list_2: [1, [22, 33, 44, 55], (5, 6, 7), {'name': 'Sarah'}]
8.1.2 神秘的字典
1、快速的查找
import time
ls_1 = list(range(1000000))
ls_2 = list(range(500))+[-10]\*500
start = time.time()
count = 0
for n in ls_2:
if n in ls_1:
count += 1
end = time.time()
print("查找{}个元素,在ls\_1列表中的有{}个,共用时{}秒".format(len(ls_2), count,round((end-start),2)))
查找1000个元素,在ls_1列表中的有500个,共用时6.19秒
import time
d = {i:i for i in range(100000)}
ls_2 = list(range(500))+[-10]\*500
start = time.time()
count = 0
for n in ls_2:
try:
d[n]
except:
pass
else:
count += 1
end = time.time()
print("查找{}个元素,在ls\_1列表中的有{}个,共用时{}秒".format(len(ls_2), count,round(end-start)))
查找1000个元素,在ls_1列表中的有500个,共用时0秒
2、字典的底层实现
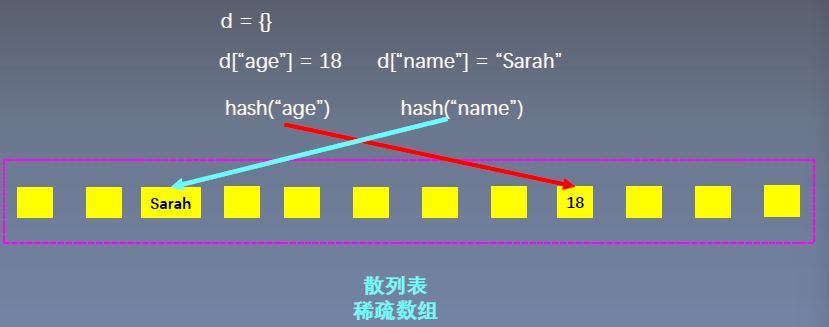
通过稀疏数组来实现值的存储与访问
字典的创建过程
- 第一步:创建一个散列表(稀疏数组 N >> n)
d = {}
- 第一步:通过hash()计算键的散列值
print(hash("python"))
print(hash(1024))
print(hash((1,2)))
-4771046564460599764
1024
3713081631934410656
d["age"] = 18 # 增加键值对的操作,首先会计算键的散列值hash("age")
print(hash("age"))
- 第二步:根据计算的散列值确定其在散列表中的位置
极个别时候,散列值会发生冲突,则内部有相应的解决冲突的办法
- 第三步:在该位置上存入值
for i in range(2, 2):
print(i)
键值对的访问过程
d["age"]
- 第一步:计算要访问的键的散列值
- 第二步:根据计算的散列值,通过一定的规则,确定其在散列表中的位置
- 第三步:读取该位置上存储的值
如果存在,则返回该值
如果不存在,则报错KeyError
3、小结
(1)字典数据类型,通过空间换时间,实现了快速的数据查找
- 也就注定了字典的空间利用效率低下
(2)因为散列值对应位置的顺序与键在字典中显示的顺序可能不同,因此表现出来字典是无序的
- 回顾一下 N >> n
如果N = n,会产生很多位置冲突 - 思考一下开头的小例子,为什么字典实现了比列表更快速的查找
8.1.3 紧凑的字符串
通过紧凑数组实现字符串的存储
- 数据在内存中是连续存放的,效率更高,节省空间
- 思考一下,同为序列类型,为什么列表采用引用数组,而字符串采用紧凑数组:
- 列表可以变化,不方便预留空间
8.1.4 是否可变
1、不可变类型:数字、字符串、元组
在生命周期中保持内容不变
- 换句话说,改变了就不是它自己了(id变了)
- 不可变对象的 += 操作 实际上创建了一个新的对象
x = 1
y = "Python"
print("x id:", id(x))
print("y id:", id(y))
x id: 140718440616768
y id: 2040939892664
x += 2
y += "3.7"
print("x id:", id(x))
print("y id:", id(y))
x id: 140718440616832
y id: 2040992707056
元组并不是总是不可变的
- 元组中如果含有可以变的类型,则该元组还是可以变的
t = (1,[2])
t[1].append(3)
print(t)
(1, [2, 3])
2、可变类型:列表、字典、集合
- id 保持不变,但是里面的内容可以变
- 可变对象的 += 操作 实际在原对象的基础上就地修改
ls = [1, 2, 3]
d = {"Name": "Sarah", "Age": 18}
print("ls id:", id(ls))
print("d id:", id(d))
ls id: 2040991750856
d id: 2040992761608
ls += [4, 5]
d_2 = {"Sex": "female"}
d.update(d_2) # 把d\_2 中的元素更新到d中
print("ls id:", id(ls))
print("d id:", id(d))
ls id: 2040991750856
d id: 2040992761608
8.1.5 列表操作的几个小例子
【例1】 删除列表内的特定元素
- 方法1 存在运算删除法
缺点:每次存在运算,都要从头对列表进行遍历、查找、效率低
alist = ["d", "d", "d", "2", "2", "d" ,"d", "4"]
s = "d"
while True:
if s in alist:
alist.remove(s)
else:
break
print(alist)
['2', '2', '4']
- 方法2 一次性遍历元素执行删除
首先alist被删除元素时不断在变,但是索引s是按照顺序来的,因此会造成可能跨过某一元素的现象,但是删除仍是按照从列表头开始扫描的顺序进行的。
alist = ["d", "d", "d", "2", "2", "d" ,"d", "4"]
for s in alist:
if s == "d":
alist.remove(s) # remove(s) 删除列表中第一次出现的该元素
print(alist)
['2', '2', 'd', 'd', '4']
解决方法:使用负向索引
负向索引相当于倒序扫描,确保每次遍历的是列表头,同时删除的也是列表头。
alist = ["d", "d", "d", "2", "2", "d" ,"d", "4"]
for i in range(-len(alist), 0):
if alist[i] == "d":
alist.remove(alist[i]) # remove(s) 删除列表中第一次出现的该元素
print(alist)
['2', '2', '4']
【例2】 多维列表的创建
ls = [[0]\*10]\*5
ls
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
ls[0][0] = 1
ls
[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
因为下面的四个列表都是第一个列表的复制,因此第一个列表变了,下面的几个都会发生变化。
8.2 简洁的语法
8.2.1 解析语法
ls = [[0]\*10 for i in range(5)]
ls
[[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
ls[0][0] = 1
ls
[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
这里都是独立创建的,因此互不影响。
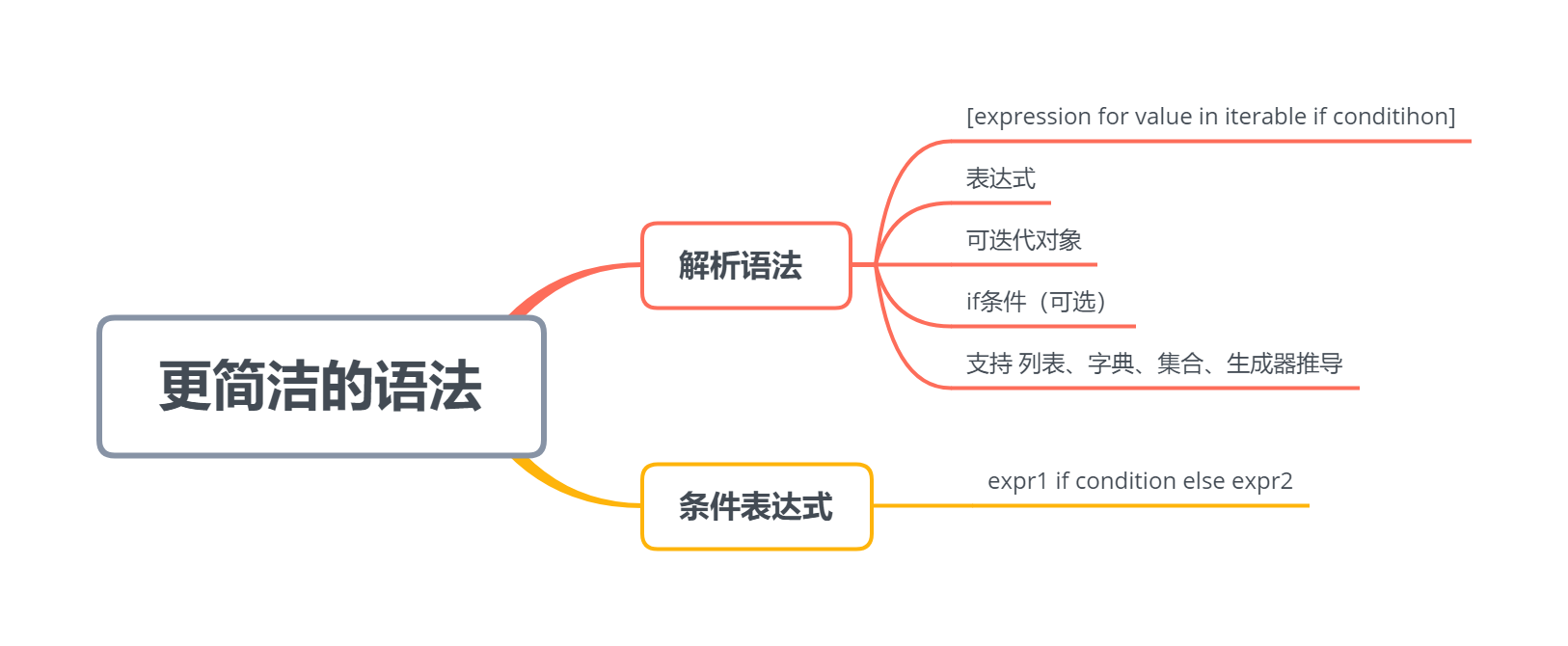
1、解析语法的基本结构——以列表解析为例(也称为列表推导)
[expression for value in iterable if conditihon]
- 三要素:表达式、可迭代对象、if条件(可选)
执行过程
(1)从可迭代对象中拿出一个元素
(2)通过if条件(如果有的话),对元素进行筛选
若通过筛选:则把元素传递给表达式
若未通过: 则进入(1)步骤,进入下一次迭代
(3)将传递给表达式的元素,代入表达式进行处理,产生一个结果
(4)将(3)步产生的结果作为列表的一个元素进行存储
(5)重复(1)~(4)步,直至迭代对象迭代结束,返回新创建的列表
# 等价于如下代码
result = []
for value in iterale:
if condition:
result.append(expression)
【例】求20以内奇数的平方
squares = []
for i in range(1,21):
if i%2 == 1:
squares.append(i\*\*2)
print(squares)
[1, 9, 25, 49, 81, 121, 169, 225, 289, 361]
squares = [i\*\*2 for i in range(1,21) if i%2 == 1]
print(squares)
[1, 9, 25, 49, 81, 121, 169, 225, 289, 361]
支持多变量
x = [1, 2, 3]
y = [1, 2, 3]
results = [i\*j for i,j in zip(x, y)]
results
[1, 4, 9]
支持循环嵌套
colors = ["black", "white"]
sizes = ["S", "M", "L"]
tshirts = ["{} {}".format(color, size) for color in colors for size in sizes]
tshirts
['black S', 'black M', 'black L', 'white S', 'white M', 'white L']
2、其他解析语法的例子
- 解析语法构造字典(字典推导)
squares = {i: i\*\*2 for i in range(10)}
for k, v in squares.items():
print(k, ": ", v)
0 : 0
1 : 1
2 : 4
3 : 9
4 : 16
5 : 25
6 : 36
7 : 49
8 : 64
9 : 81
- 解析语法构造集合(集合推导)
squares = {i\*\*2 for i in range(10)}
squares
{0, 1, 4, 9, 16, 25, 36, 49, 64, 81}
- 生成器表达式
squares = (i\*\*2 for i in range(10))
squares
<generator object <genexpr> at 0x000001DB37A58390>
colors = ["black", "white"]
sizes = ["S", "M", "L"]
tshirts = ("{} {}".format(color, size) for color in colors for size in sizes)
for tshirt in tshirts:
print(tshirt)
black S
black M
black L
white S
white M
white L
8.2.2 条件表达式
expr1 if condition else expr2
【例】将变量n的绝对值赋值给变量x
n = -10
if n >= 0:
x = n
else:
x = -n
x
10
n = -10
x = n if n>= 0 else -n
x
10
条件表达式和解析语法简单实用、运行速度相对更快一些,相信大家会慢慢的爱上它们
8.3 三大神器

8.3.1 生成器
ls = [i\*\*2 for i in range(1, 1000001)]
for i in ls:
pass
缺点:占用大量内存
生成器
(1)采用惰性计算的方式
(2)无需一次性存储海量数据
(3)一边执行一边计算,只计算每次需要的值
(4)实际上一直在执行next()操作,直到无值可取
1、生成器表达式
- 海量数据,不需存储
squares = (i\*\*2 for i in range(1000000))
for i in squares:
pass
- 求0~100的和
无需显示存储全部数据,节省内存
sum((i for i in range(101))) # 求和,里面是一个生成器
5050
2、生成器函数——yield
- 生产斐波那契数列
数列前两个元素为1,1 之后的元素为其前两个元素之和
def fib(max):
ls = []
n, a, b = 0, 1, 1
while n < max:
ls.append(a)
a, b = b, a + b
n = n + 1
return ls
fib(10)
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
中间尝试
def fib(max):
n, a, b = 0, 1, 1
while n < max:
print(a)
a, b = b, a + b
n = n + 1
fib(10)
1
1
2
3
5
8
13
21
34
55
构造生成器函数
在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行
def fib(max):
n, a, b = 0, 1, 1
while n < max:
yield a
a, b = b, a + b
n = n + 1
fib(10)
<generator object fib at 0x000001BE11B19048>
for i in fib(10):
print(i)
1
1
2
3
5
8
13
21
34
55
8.3.2 迭代器
1、可迭代对象
可直接作用于for循环的对象统称为可迭代对象:Iterable
(1)列表、元组、字符串、字典、集合、文件
可以使用isinstance()判断一个对象是否是Iterable对象
from collections import Iterable
isinstance([1, 2, 3], Iterable)
True
isinstance({"name": "Sarah"}, Iterable)
True
isinstance('Python', Iterable)
True
(2)生成器
squares = (i\*\*2 for i in range(5))
isinstance(squares, Iterable)
True
生成器不但可以用于for循环,还可以被next()函数调用
print(next(squares))
print(next(squares))
print(next(squares))
print(next(squares))
print(next(squares))
0
1
4
9
16
直到没有数据可取,抛出StopIteration
print(next(squares))
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-66-f5163ac9e49b> in <module>
----> 1 print(next(squares))
StopIteration:
可以被next()函数调用并不断返回下一个值,直至没有数据可取的对象称为迭代器:Iterator
2、迭代器
可以使用isinstance()判断一个对象是否是Iterator对象
(1) 生成器都是迭代器
from collections import Iterator
squares = (i\*\*2 for i in range(5))
isinstance(squares, Iterator)
True
(2) 列表、元组、字符串、字典、集合不是迭代器
isinstance([1, 2, 3], Iterator)
False
可以通过iter(Iterable)创建迭代器
isinstance(iter([1, 2, 3]), Iterator)
True
for item in Iterable 等价于:
先通过iter()函数获取可迭代对象Iterable的迭代器
然后对获取到的迭代器不断调用next()方法来获取下一个值并将其赋值给item
当遇到StopIteration的异常后循环结束
(3)zip enumerate 等itertools里的函数是迭代器
x = [1, 2]
y = ["a", "b"]
zip(x, y)
<zip at 0x1be11b13c48>
for i in zip(x, y):
print(i)
isinstance(zip(x, y), Iterator)
(1, 'a')
(2, 'b')
True
numbers = [1, 2, 3, 4, 5]
enumerate(numbers)
<enumerate at 0x1be11b39990>
for i in enumerate(numbers):
print(i)
isinstance(enumerate(numbers), Iterator)
(0, 1)
(1, 2)
(2, 3)
(3, 4)
(4, 5)
True
(4) 文件是迭代器
with open("测试文件.txt", "r", encoding = "utf-8") as f:
print(isinstance(f, Iterator))
True
(5)迭代器是可耗尽的
squares = (i\*\*2 for i in range(5))
for square in squares:
print(square)
0
1
4
9
16
for square in squares:
print(square)
再迭代不出来了,因为已经耗尽了
(6)range()不是迭代器
numbers = range(10)
isinstance(numbers, Iterator)
False
print(len(numbers)) # 有长度
print(numbers[0]) # 可索引
print(9 in numbers) # 可存在计算
next(numbers) # 不可被next()调用
10
0
True
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-76-7c59bf859258> in <module>
2 print(numbers[0]) # 可索引
3 print(9 in numbers) # 可存在计算
----> 4 next(numbers) # 不可被next()调用
TypeError: 'range' object is not an iterator
for number in numbers:
print(number)
0
1
2
3
4
5
6
7
8
9
不会被耗尽。
for number in numbers:
print(number)
0
1
2
3
4
5
6
7
8
9
可以称range()为懒序列
它是一种序列
但并不包含任何内存中的内容
而是通过计算来回答问题
8.3.3 装饰器
1、需求的提出
(1)需要对已开发上线的程序添加某些功能
(2)不能对程序中函数的源代码进行修改
(3)不能改变程序中函数的调用方式
比如说,要统计每个函数的运行时间
def f1():
pass
def f2():
pass
def f3():
pass
f1()
f2()
f3()
没问题,我们有装饰器!!!
2、函数对象
函数是Python中的第一类对象
(1)可以把函数赋值给变量
(2)对该变量进行调用,可实现原函数的功能
def square(x):
return x\*\*2
print(type(square)) # square 是function类的一个实例















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









