






特征降维
实际数据中,有时候特征很多,会增加计算量,降维就是去掉一些特征,或者转化多个特征为少量个特征
特征降维其目的:是减少数据集的维度,同时 尽可能保留数据的重要信息。
特征降维的好处:
减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
特征降维的方式:
- 特征选择
- 从原始特征集中挑选出最相关的特征
- 主成份分析(PCA)
- 主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
1 .特征选择
(a) VarianceThreshold 低方差过滤特征选择
-
Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标值之间关联
-
方差选择法: 低方差特征过滤
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
- 计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
- 设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
- 过滤特征:移除所有方差低于设定阈值的特征
-
创建对象,准备把方差为等于小于2的去掉,threshold的缺省值为2.0
sklearn.feature_selection.VarianceThreshold(threshold=2.0)
把x中低方差特征去掉, x的类型可以是DataFrame、ndarray和list
VananceThreshold.fit_transform(x)
fit_transform函数的返回值为ndarray
去除方差较小的特征的代码如下:
from sklearn.feature_selection import VarianceThreshold
import pandas as pd
# 1、获取数据,data是一个DataFrame,可以是读取的csv文件
data=pd.DataFrame([[10,1],[11,3],[11,1],[11,5],[11,9],[11,3],[11,2],[11,6]])
print("data:\n", data)
'''0 1
0 10 1
1 11 3
2 11 1
3 11 5
4 11 9
5 11 3
6 11 2
7 11 6
'''
# 实例化一个转换器
transfer=VarianceThreshold(threshold=1)#阈值,把方差小于1的去掉
# 调用fit_transform(),获取修改后的数据集
data_new=transfer.fit_transform(data)
print(data_new)
'''
[[1]
[3]
[1]
[5]
[9]
[3]
[2]
[6]]
'''
利用sklearn.feature_selection的varianceThreshold(threshold)方法可以将方差小于threshold的特征去除,因为,方差较小的特征不能很好的验证与目标值的关系。
(b) 根据相关系数的特征选择
<1>理论
正相关性(Positive Correlation)是指两个变量之间的一种统计关系,其中一个变量的增加通常伴随着另一个变量的增加,反之亦然。在正相关的关系中,两个变量的变化趋势是同向的。当我们说两个变量正相关时,意味着:
- 如果第一个变量增加,第二个变量也有很大的概率会增加。
- 同样,如果第一个变量减少,第二个变量也很可能会减少。
正相关性并不意味着一个变量的变化直接引起了另一个变量的变化,它仅仅指出了两个变量之间存在的一种统计上的关联性。这种关联性可以是因果关系,也可以是由第三个未观察到的变量引起的,或者是纯属巧合。
在数学上,正相关性通常用正值的相关系数来表示,这个值介于0和1之间。当相关系数等于1时,表示两个变量之间存在完美的正相关关系,即一个变量的值可以完全由另一个变量的值预测。
举个例子,假设我们观察到在一定范围内,一个人的身高与其体重呈正相关,这意味着在一般情况下,身高较高的人体重也会较重。但这并不意味着身高直接导致体重增加,而是可能由于营养、遗传、生活方式等因素共同作用的结果。
负相关性(Negative Correlation)与正相关性刚好相反,但是也说明相关,比如运动频率和BMI体重指数程负相关
不相关指两者的相关性很小,一个变量变化不会引起另外的变量变化,只是没有线性关系. 比如饭量和智商
皮尔逊相关系数(Pearson correlation coefficient)是一种度量两个变量之间线性相关性的统计量。 它提供了两个变量间关系的方向(正相关或负相关)和强度的信息。皮尔逊相关系数的取值范围是 [−1,1], 其中:
- ρ = 1 \rho=1 ρ=1 表示完全正相关,即随着一个变量的增加,另一个变量也线性增加。
- ρ = − 1 \rho=-1 ρ=−1 表示完全负相关,即随着一个变量的增加,另一个变量线性减少。
- ρ = 0 \rho=0 ρ=0 表示两个变量之间不存在线性关系。
相关系数 ρ \rho ρ的绝对值为0-1之间,绝对值越大,表示越相关,当两特征完全相关时,两特征的值表示的向量是在同一条直线上,当两特征的相关系数绝对值很小时,两特征值表示的向量接近在同一条直线上。当相关系值为负数时,表示负相关
<2>皮尔逊相关系数:pearsonr相关系数计算公式, 该公式出自于概率论
对于两组数据 𝑋={𝑥1,𝑥2,…,𝑥𝑛} 和 𝑌={𝑦1,𝑦2,…,𝑦𝑛},皮尔逊相关系数可以用以下公式计算:
ρ = Cos ( x , y ) D x ⋅ D y = E [ ( x − E x ) ( y − E y ) ] D x ⋅ D y = ∑ i = 1 n ( x − x ~ ) ( y − y ˉ ) / ( n − 1 ) ∑ i = 1 n ( x − x ˉ ) 2 / ( n − 1 ) ⋅ ∑ i = 1 n ( y − y ˉ ) 2 / ( n − 1 ) \rho=\frac{\operatorname{Cos}(x, y)}{\sqrt{D x} \cdot \sqrt{D y}}=\frac{E[(x_-E x)(y-E y)]}{\sqrt{D x} \cdot \sqrt{D y}}=\frac{\sum_{i=1}^{n}(x-\tilde{x})(y-\bar{y}) /(n-1)}{\sqrt{\sum_{i=1}^{n}(x-\bar{x})^{2} /(n-1)} \cdot \sqrt{\sum_{i=1}^{n}(y-\bar{y})^{2} /(n-1)}} ρ=Dx⋅DyCos(x,y)=Dx⋅DyE[(x−Ex)(y−Ey)]=∑i=1n(x−xˉ)2/(n−1)⋅∑i=1n(y−yˉ)2/(n−1)∑i=1n(x−x~)(y−yˉ)/(n−1)
x ˉ \bar{x} xˉ和 y ˉ \bar{y} yˉ 分别是𝑋和𝑌的平均值
|ρ|<0.4为低度相关; 0.4<=|ρ|<0.7为显著相关; 0.7<=|ρ|<1为高度相关
<3>api:
scipy.stats.personr(x, y y y) 计算两特征之间的相关性
返回对象有两个属性:
statistic皮尔逊相关系数[-1,1]
pvalue零假设(了解),统计上评估两个变量之间的相关性,越小越相关
代码实例如下:
# 引入相关系数的库
from scipy.stats import pearsonr
import numpy as np
x=np.array([[10,1],[11,3],[11,1],[11,5],[11,9],[11,3],[11,2],[11,6]])
y=np.array([[10],[30],[10],[50],[90],[30],[20],[6]])
# print(x[:,0],y.flatten())
r1=pearsonr(x[:,0],y.flatten())
r2=pearsonr(x[:,1],y.flatten())
print(r1.statistic,r1.pvalue) #0.29988923251978944 0.47051074984152286
#r1.statistic:相关性, 负数表示负相关,正数表示正相关 r1.pvalue相关性,越小越相关
print(r2.statistic,r2.pvalue) #0.7642675514280182 0.027231980994256444
开发中一般不使用求相关系数的方法,一般使用主成分分析,因为主成分分样过程中就包括了求相关系数 了。 了。 了。
2.主成份分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
(a) 原理
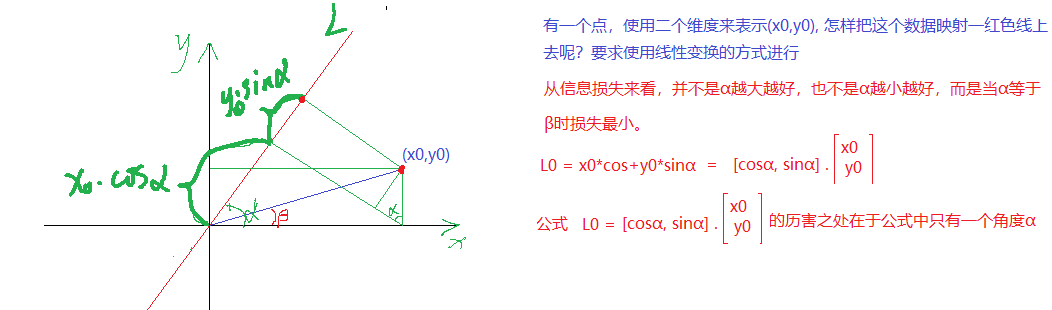
x
0
x_0
x0投影到L的大小为
x
0
∗
c
o
s
α
x_0*cos \alpha
x0∗cosα
y 0 y_0 y0投影到L的大小为 y 0 ∗ s i n α y_0*sin\alpha y0∗sinα
使用 ( x 0 , y 0 ) (x_0,y_0) (x0,y0)表示一个点, 表明该点有两个特征, 而映射到L上有一个特征就可以表示这个点了。这就达到了降维的功能 。
投影到L上的值就是降维后保留的信息,投影到与L垂直的轴上的值就是丢失的信息。保留信息/原始信息=信息保留的比例
下图中红线上点与点的距离是最大的,所以在红色线上点的方差最大,粉红线上的刚好相反.
所以红色线上点来表示之前点的信息损失是最小的。
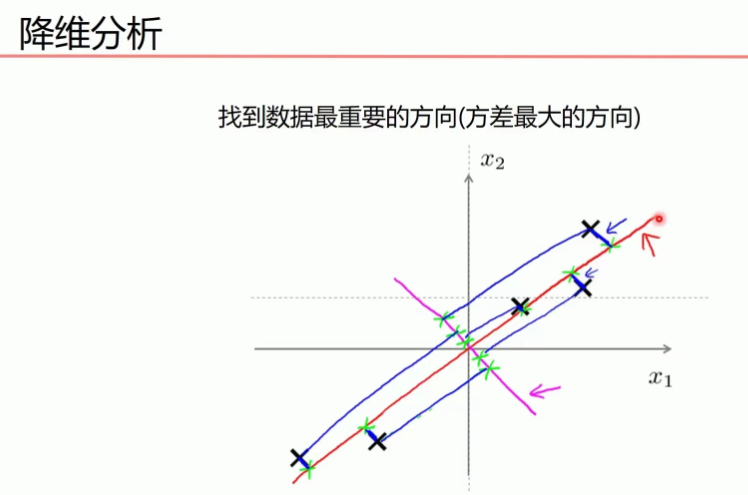
上图中红线上点与点的距离是最大的,信息保留比越大,而后进行模型训练时,保留特征的信息就越多,就对模型有利
(b) 步骤
-
得到矩阵
-
用矩阵P对原始数据进行线性变换,得到新的数据矩阵Z,每一列就是一个主成分, 如下图就是把10维降成了2维,得到了两个主成分
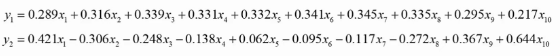
- 根据主成分的方差等,确定最终保留的主成分个数, 方差大的要留下。一个特征的多个样本的值如果都相同,则方差为0, 则说明该特征值不能区别样本,所以该特征没有用。
比如下图的二维数据要降为一维数据,图形法是把所在数据在二维坐标中以点的形式标出,然后给出一条直线,让所有点垂直映射到直线上,该直线有很多,只有点到线的距离之和最小的线才能让之前信息损失最小。
这样之前所有的二维表示的点就全部变成一条直线上的点,从二维降成了一维。
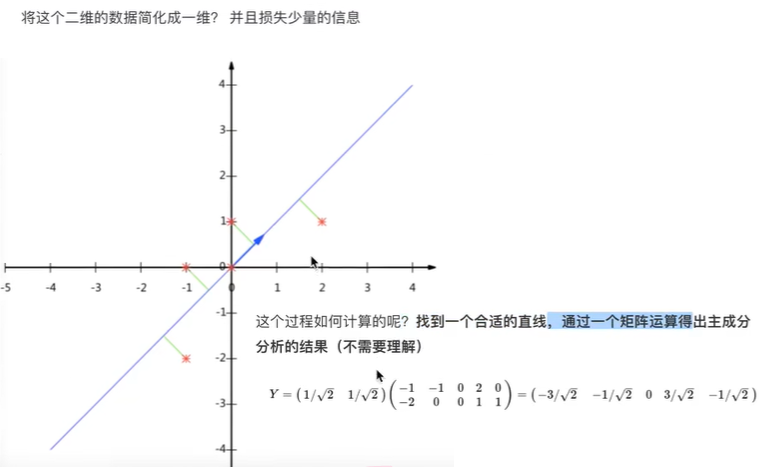
上图是一个从二维降到一维的示例:的原始数据为
| 特征1-X1 | 特征2-X2 |
|---|---|
| -1 | -2 |
| -1 | 0 |
| 0 | 0 |
| 2 | 1 |
| 0 | 1 |
降维后新的数据为
| 特征3-X0 |
|---|
| -3/√2 |
| -1/√2 |
| 0 |
| 3/√2 |
| -1/√2 |
3.api
- from sklearn.decomposition import PCA
- PCA(n_components=None)
- 主成分分析
- n_components:
- 实参为小数时:表示降维后保留百分之多少的信息
- 实参为整数时:表示减少到多少特征
(3)示例-n_components为小数
# 引入PCA的库
from sklearn.decomposition import PCA
data = [[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
# 1、实例化一个转换器类,
# 降维后还要保留原始数据0.95%的信息,
# 最后的结果中发现由4个特征降维成2个特征了
transfer=PCA(n_components=0.95)
data_new=transfer.fit_transform(data)
print(data_new)
'''
[[-1.28620952e-15 3.82970843e+00]
[-5.74456265e+00 -1.91485422e+00]
[ 5.74456265e+00 -1.91485422e+00]]
'''
(4)示例-n_components为整数
data = [[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
# 实例化一个转换器类, 降维到只有3个特征
transfer = PCA(n_components=3)
data_new=transfer.fit_transform(data)
print(data_new)
'''
[[-1.28620952e-15 3.82970843e+00 5.26052119e-16]
[-5.74456265e+00 -1.91485422e+00 5.26052119e-16]
[ 5.74456265e+00 -1.91485422e+00 5.26052119e-16]]
'''
注意
- n_components=a为小数时,表示信息保留比为a,但维度是不确定的
- n_components=b为整数时,表示维度是b维,但是信息保留比也是不确定的

















 1336
1336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









