






最近客户遇到了一个BUG,这个BUG非常特殊,与PDF和字体相关。客户的系统中有一个能够根据报表信息生成PDF文件的功能,该功能主要包含两块内容,一块是PDF的文件展示,一块是PDF的文件下载。客户的报表功能中会用到一些科学计数法的写法,也因此就会用到一些特殊的字符,比如2*10³,3*10²。但是这些次方符号在显示的时候,却存在一些问题。这个问题还比较诡异,不同电脑生成的PDF、同一个PDF不同工具打开,有的时候这些数字上标是能够正常显示出来的,有的时候就有问题。
就我们的团队而言,所有电脑、所有系统生成的PDF,都可以使用pdfjs来进行打开,并且正确无误。下图中红色的方框框选出来的部分,就是可能会产生问题的数字上标,它的实现原理很简单,就是使用特殊字符:

但是在Adobe Acrobat的阅读器中,情况就有些不同了。同事A的电脑生成的PDF,可以在Adobe Acrobat下正确显示,同事B的电脑就不行。公司有两台测试服务器,一台是ubuntu,另一台则是CentOS。奇怪的是,在ubuntu的系统中生成的PDF是可以正确的在Adobe Acrobat下打开的,但是在CentOS服务器生成的PDF打开的时候特殊字符却是会丢失的。
同事A、ubuntu生成的PDF,可以在Adobe Acrobat正常展示特殊的上标符号:

同事B、CentOS生成的PDF,在Adobe Acrobat中特殊的上标符号,无法正常展示:

因为这个PDF生成工具是由第三方公司提供的,所以我们先决定和第三方公司沟通一番,确认他们的PDF的生成逻辑,再做进一步问题的定位。他们的PDF使用了IText工具生成的,默认的情况下使用的字体是宋体。并且他们给了我们一个网站,这个网站提供了一系列的角标的字符供用户复制使用。我进入了这个网站,并将其中的角标复制下来了:
⁰ ¹ ² ³ ⁴ ⁵ ⁶ ⁷ ⁸ ⁹ ⁺ ⁻ ⁼ ⁽ ⁾ ⁿ º ˙
然后我打开IDEA,写了几行Java代码,把这几个角标对应的Unicode编码给找出来了,以下是实现的代码:
public class App {
public static void main(String[] args) {
char c0 = '⁰',c1 = '¹',c2 = '⁶';
// '⁰' unicode编码为8304,十六进制值是2070
System.out.println((int) c0 + " " + Integer.toHexString(c0));
// '¹' unicode编码是185,十六进制值是b9
System.out.println((int) c1 + " " + Integer.toHexString(c1));
// '⁶' unicode编码是8310,十六进制编码是2076
System.out.println((int) c2 + " " + Integer.toHexString(c2));
}
}确认好这些特殊字符的编码之后,我下载了字符查看工具FontForge,并使用FontForge检查了宋体字符文件里面这些特殊字符的情况。显然,宋体这个字体里面的0 1 2 3的上标都是正常设计的的。因此在系统生成PDF的时候,如果某些特殊字符的上标是0 1 2 3,一般情况下也是没有问题的。但是如果上标是4 5 6,在有些电脑生成的PDF文件中,就会出现问题了。
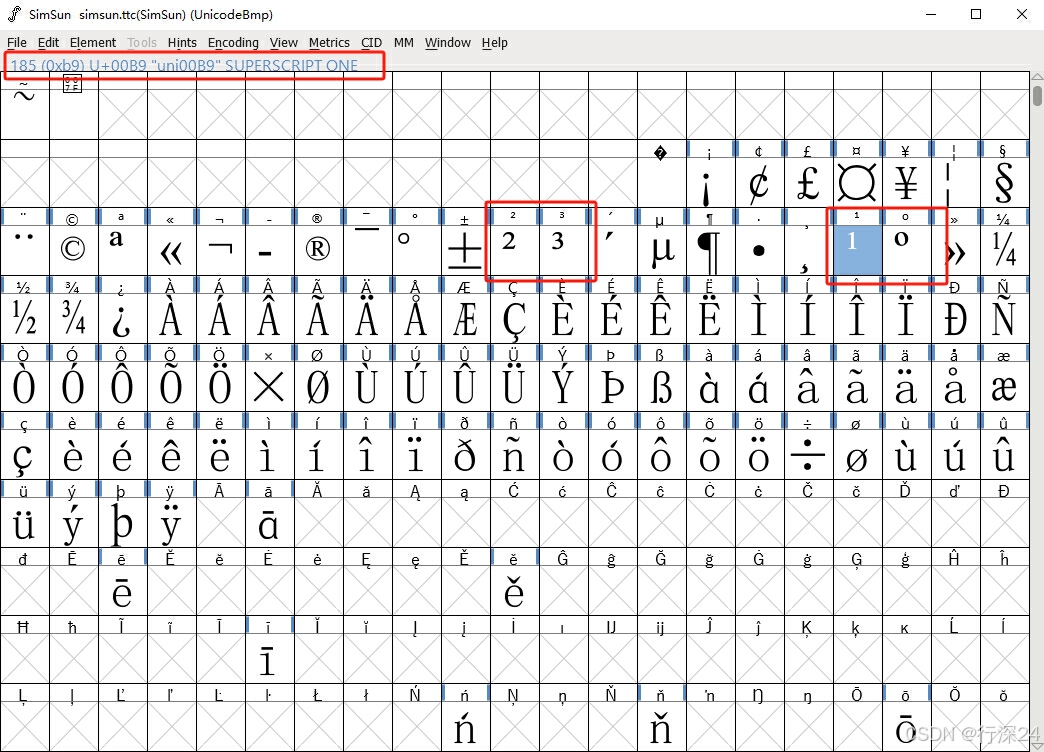
在查看了0 1 2 3的上标之后,我又查看了4 5 6的上标,他们的编码都在8310(对应的十六进制2076)的前后。于是我们使用了FontForge查看了8310前后相关的字符信息:
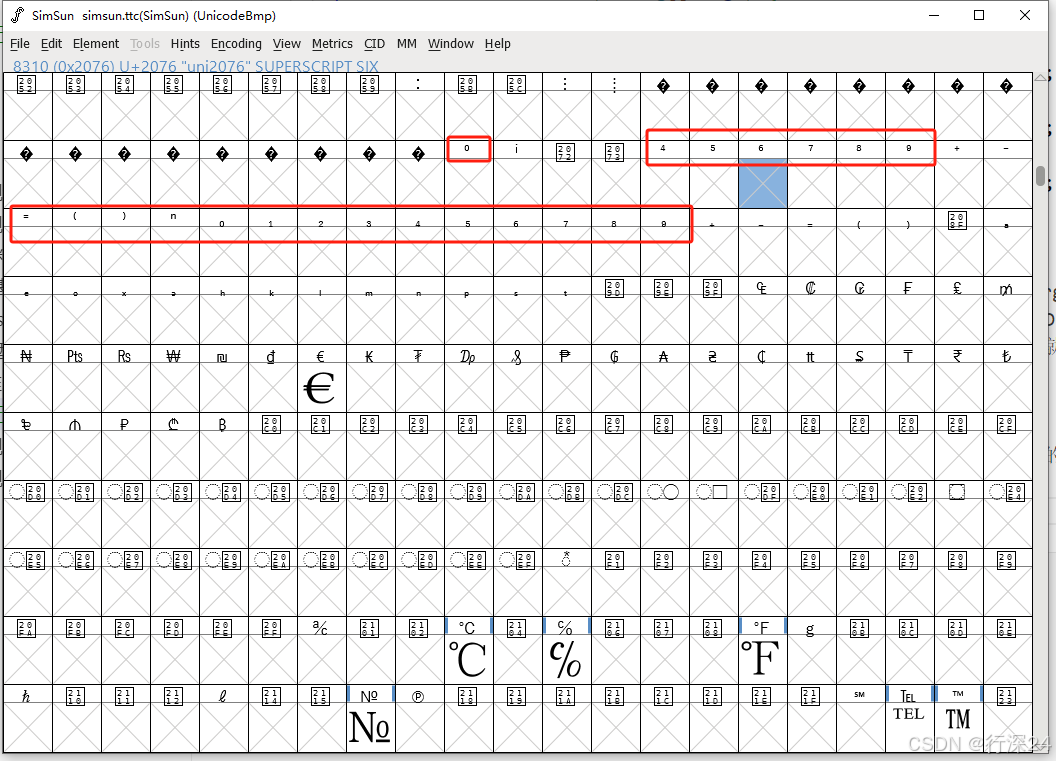
通过这张图,我们可以看到,宋体的font文件中,并没有包含对上标4-9的设计,而且上标0其实出现了两次,第一次是和上标1 2 3在一起,第二次是和上标4 5 6 7 8 9出现在一起。
尽管PDF生成工具的供应商表示他们使用宋体来生成数据,但是宋体的font文件中却缺失了一些上标,这可能会导致一些问题。但是还有一个奇怪的点,那就是这些特殊的上标,在PDF和Adobe Acrobat中,是能够正常显式的。这说明问题其实并不是缺失几个字符那么简单。通过查阅相关资料之后,我了解到了几样东西,他们主要就是用来解决“某个字符在指定字体中不存在,那么该如何显示这个字符?”这个问题的。他们分别是字符回退机制和Font-Family。
字符回退机制(Font Substitutes/Font Fallback)/Font Family
字符回退机制是一种特别且重要的机制。我们可以按照先后顺序设置一系列的字体,让某个字符在用户指定字体中缺失的情况下,可以使用多个其它字体进行依次替代。假设我要求PDF阅读器使用宋体来显示一段文字,那么我只需要在PDF中将字体设置为宋体就可以了。但是考虑到这段文字中可能存在特殊字符,而宋体的字符文件可能出现涵盖不到的情况下,我又设置一系列的回退字体,按照优先级从前到后,分别是微软雅黑、楷书、Arial。那么当系统或者PDF工具试图用宋体来显示上标5这个特殊字符的时候,发现宋体中没有设计上标5这个字符,那么他会先试图用微软雅黑来显示上标5,微软雅黑也不行,那就试试楷书,楷书还不行的话,就用Arial。如果全都不行,那就不显示,或者显示一个□。Font-Family的机制也是类似的。
有了这个之后,我通过调试PDFjs解析PDF文件的过程发现,pdfjs在这方面做得比较好。它有几个兜底的字体,monospace字体和sans-serif字体。这两个字体对上标支持的比较好,因此在不同电脑、不同系统下生成的PDF文件,它都能够较好的展示出来。而Adobe Acrobat可就不太一样了,它比较严格。
于是我的目光更多的聚焦到了Adobe Acrobat的字体回退机制上来了。首先我查看了Windows下的字体回退配置,这个配置在注册表里面,key为:
计算机\HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion\FontSubstitutes
它里面配置了一系列的字体回退策略:
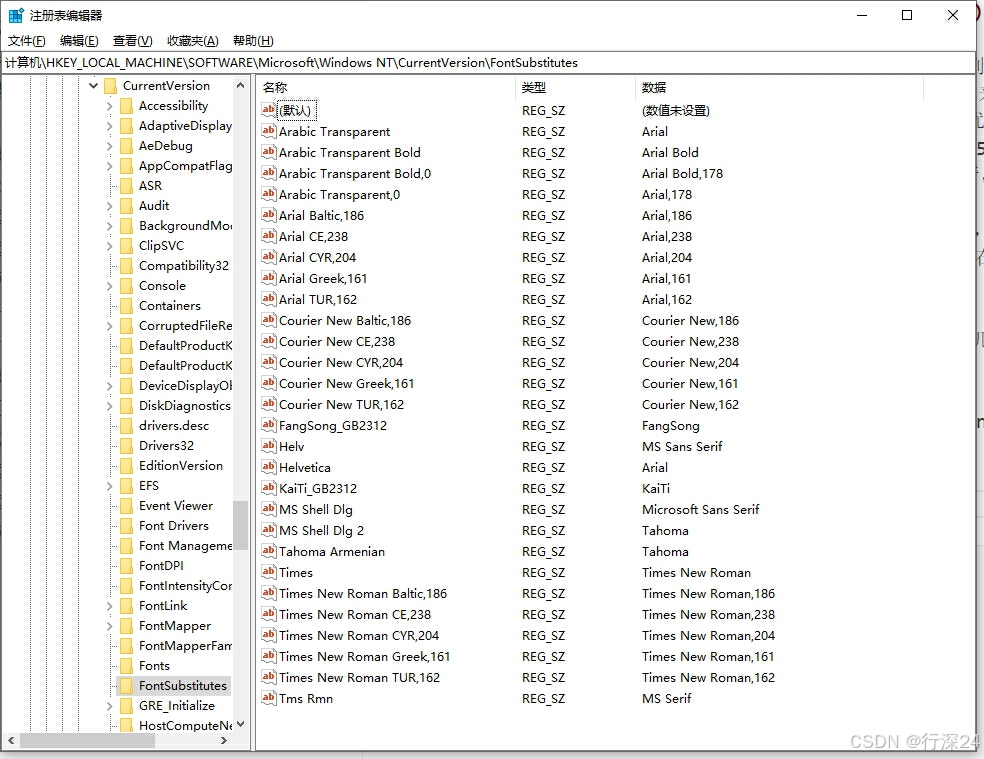
我们比对了多台电脑上的字体回退配置,发现基本上都是完全一样的。而且根据经验,操作系统对于这种已经成熟的不能再成熟的功能,应该也不会去修改,用户主动修改的概率也是不高。因此问题可能出现在这里,但是概率其实还是比较低的。
反编译jar包,查看字体获取的相关逻辑
分析完系统的情况之后,问题还是没有得到解决。不过多多少少得到了一些推进,但是似乎还是没有触及根本。于是只能使用一种更为彻底的问题解决方案了,就是反编译jar包,研究PDF渲染的逻辑。但是事实上并没有研究多深,问题就浮出水面了。我找到生成PDF相关的代码,并进行了一个初步的调试,发现源代码中是使用下面的这种方式来获取字体信息的:
public class App {
public static void main(String[] args) {
GraphicsEnvironment ge = GraphicsEnvironment.getLocalGraphicsEnvironment();
String[] fontNames = ge.getAvailableFontFamilyNames(Locale.getDefault());
for (String fontName : fontNames) {
System.out.println(fontName);
}
}
}它是按照字典序的方式,将可用的字体以数组的形式返回回来。我把这段代码编译成了一个class文件,然后在同事A、同事B的电脑里面都运行了一遍,发现两台电脑返回的字体是有一些差异的:
同事A的电脑中,返回的是字体是这样的:
Agency FB
Algerian
Arial
Arial Black
Arial Narrow
Arial Rounded MT Bold
Arial Unicode MS
Bahnschrift
Baskerville Old Face
Bauhaus 93
Bell MT
Berlin Sans FB
Berlin Sans FB Demi
Bernard MT Condense
...
同事B的电脑中,返回的是字体是这样的:
Adobe Devanagari
Agency FB
Algerian
AR PL UKai CN
AR PL UKai HK
AR PL UKai TW
AR PL UKai TW MBE
Arial
Arial Black
Arial Narrow
Arial Rounded MT Bold
Arvo
Bahnschrift
Baskerville Old Face
Bauhaus 93
Bell MT
Berlin Sans FB
Berlin Sans FB Demi
Bernard MT Condensed
...
同事B的电脑里缺少了Arial Unicode MS字体,Arial是使用的比较广泛的,而Unicode又是相对比较齐全的字体,因此我们怀疑是同事B电脑里缺少这个字体导致的。于是将这个字体从Arial从同事A的电脑里拷贝到同事B的电脑里,发现问题依旧。这说明,还不是这个问题导致的。
同事A相较于同事B,也少了一些Adobe相关的字体,尽管当时我们觉得这不是特别要紧,但它实际上就是BUG的根源。只是我们一开始并没有想到这个问题。
于是我们回过头继续研究同事B的电脑,发现它的程序在运行代码生成PDF的时候,报了一个告警:
WARNING: PDF load font:Adobe Devanagari failure, use default font instead.
这行日志的意思似乎是Adobe Devanagari这个字体似乎存在一些问题,或者说配置Adobe Devanagari不当。再联想到前面了解到的字体回退机制、按照字典序返回的字体家族,我大概想到了问题所在。
这个问题的原因应当是这样的:
当系统想要使用宋体去渲染一个PDF的时候,发现宋体中缺少了一些特殊字符,因此无法正确的将这些特殊字符渲染出来。这个时候它就尝试依次从多个字体中,找出一个合适的字体来代替宋体渲染这些特殊字符。而它所“依次尝试”的方式,就是按照字典序,从系统中拿出多个字体来逐个尝试。不幸的是,当它拿到第一个字体Adobe Devanagari,处理就出现了错误。于是我们把Adobe Devanagari字体卸载掉了,结果问题依旧,不过报错变成了另一个。
WARNING: PDF load font:AR PL UKai CN failure, use default font instead.
我们找到这个字体arplukai对应的文件,也进行了一个卸载。卸载完成之后,再次使用同事B的电脑生成PDF,这次没有warning,也生成的文件也可以在多个平台上正确展示。问题终于得到了解决。
这里就不得不提另一个问题了,为什么同事A的电脑生成PDF却是正常的?答案是这样的:当同事A的电脑尝试生成PDF的时候,也会先加载宋体。但是当宋体处理不了特殊字符的时候,同事A的程序就会试图加载整个系统中“字典序排序为第一的字体”,而它的电脑里没有安装Adobe Devanagari、arplukai这样的字体。因此程序就直接加载了兼容性特别强的Arial字体(arplukai排在Arial前面,因为arplukai被解析后会变成‘ar pl ukai’,空格的优先级更高),因此也就不存在这个问题了。当同事B将系统中的Adobe Devanagari和arplukai这样的字体卸载后,Arial又变回到了字典序的第一名上去。程序在使用宋体渲染不了的特殊字符的时候,就会使用Arial了,因而也就没有问题了。
CentOS中的字体
解决完本地开发的问题之后,我们需要解决CentOS环境中的问题了。我使用了fontconfig工具中的fc-list、fc-match检查了CentOS系统,发现里面既没有Adobe Devanagari字体,也没有arplukai字体。但是在应用程序启动的时候,发现还是会报错:
WARNING: PDF load font:Adobe Devanagari failure, use default font instead.
这令我感到吃惊。可以肯定的是系统中存在着这个Adobe Devanagari字体,也并且仍然在被程序使用着。但是我却找不到这个字体文件在哪里。使用fc-list和fc-match也不能够解决问题。
这说明这几个字体文件,是存在于系统中的,并且可以被Java访问,但是却无法被FontConfig所管理。应该是隐藏在某个程序下的私有文件夹下的。我是用前面的程序打印所有的字体,发现CentOS中是一直存在Adobe Devanagari、arplukai这样的字体的。即使我删除了一些看似是这两个字体的文件,或与这两个字体有关的文件。但是通过Java获取字体的时候,这两个字体始终排在所有字体的最前方,不动如山。
没办法,我只好直接使用暴力搜索,检索整个系统中的文件,试图让字体文件无所遁形:
find / -type f -name "*Adobe*"果然,在java的安装目录下,我们发现了一个字体配置目录jre/lib/fonts/fallback/里面配置了一系列的字体,对整个PDF生成逻辑有影响的就是Adobe Devanagari和arplukai这两个字体。和同事交流过后发现,java目录上的这些字体,是同事B按照之前工具供应商的需求从Windows主机上拷贝过去的。也正是这一操作,将本来在同事B上所特有的BUG,一块带到了CentOS中。
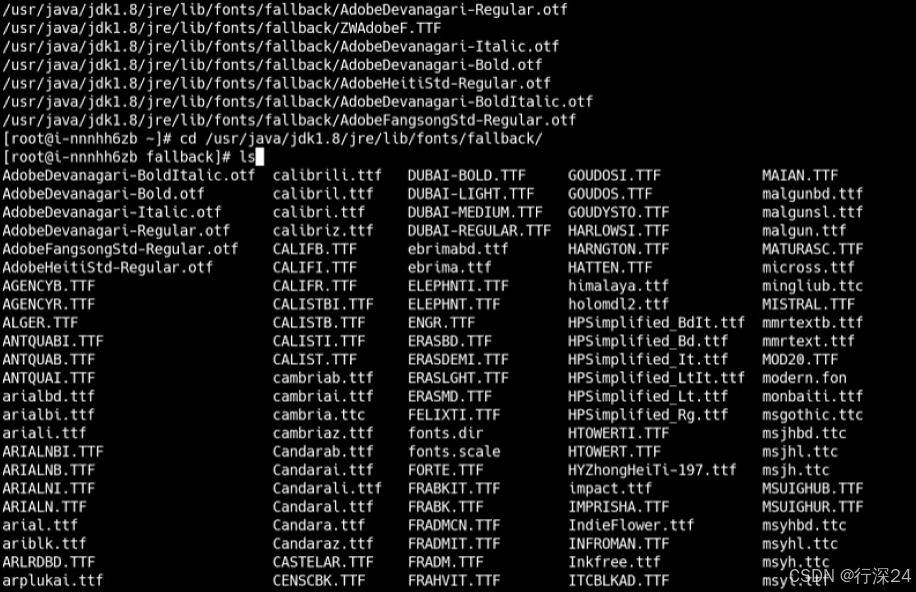
删除Java目录下那些可能会对PDF生成造成影响的字体后,这个问题总算是顺利解决了。这下,终于在所有电脑、所有系统生成的PDF,都能够显示正常了。

















 823
823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









