










盲道分割与盲道障碍物检测数据集。

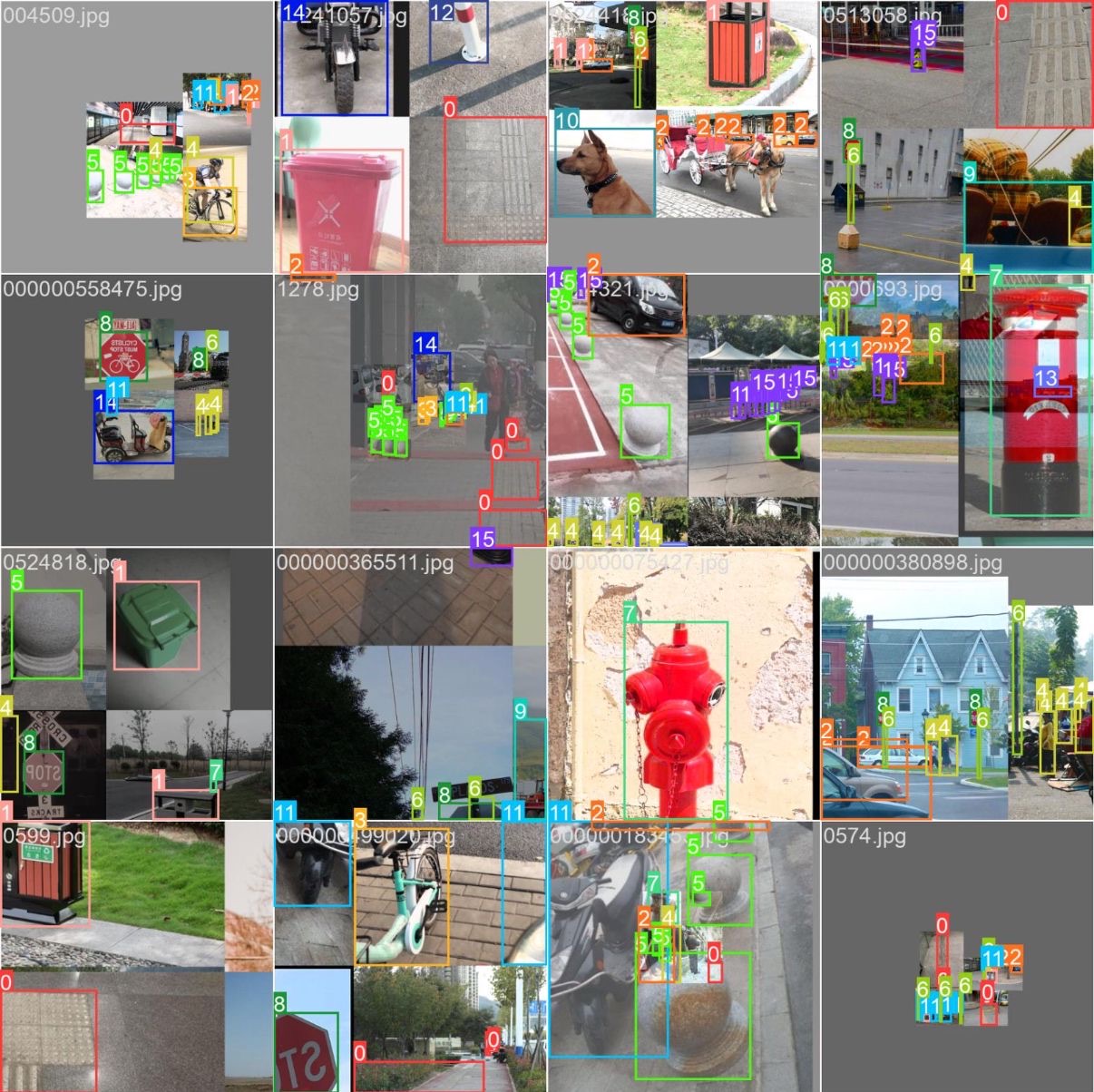
一,盲道分割数据集,共1.7GB,标注路人行走视角盲道位置,以mask图形式标注。二,盲道及周边障碍物检测数据集,共7900张6.4Gvoc格式标注人汽车路障狗等

part1盲道分割数据集,共1.7GB,标注路人行走视角下的盲道位置,以mask图的形式标注。
part2盲道及周边障碍物检测数据集

声明,文章所有代码仅供参考!
共7900余张图像,6.4GB
voc格式标注,stop_sign: 停止标志
person: 人bicycle: 自行车bus: 公共汽车
truck: 卡车car: 汽车motorbike: 摩托车
reflective_cone: 反光锥ashcan: 垃圾箱
warning_column: 警示柱spherical_roadblock: 球形路障
pole: 杆子dog: 狗tricycle: 三轮车fire_hydrant: 消防栓
-
第一部分:盲道分割数据集
- 大小:1.7GB
- 标注方式:以mask图的形式标注行人视角下的盲道位置。
- 应用场景:用于训练分割模型,识别盲道的位置。
-
第二部分:盲道及周边障碍物检测数据集
- 大小:6.4GB
- 图像数量:约7900余张图像
- 标注格式:VOC格式
- 标注类别:
- stop_sign: 停止标志
- person: 人
- bicycle: 自行车
- bus: 公共汽车
- truck: 卡车
- car: 汽车
- motorbike: 摩托车
- reflective_cone: 反光锥
- ashcan: 垃圾箱
- warning_column: 警示柱
- spherical_roadblock: 球形路障
- pole: 杆子
- dog: 狗
- tricycle: 三轮车
- fire_hydrant: 消防栓
- 应用场景:用于训练检测模型,识别盲道周围的潜在障碍物。
数据集结构
第一部分:盲道分割数据集
BlindPathSegmentationDataset/
├── images/
│ ├── image_00001.jpg
│ ├── image_00002.jpg
│ └── ...
├── masks/
│ ├── mask_00001.png
│ ├── mask_00002.png
│ └── ...
└── README.md # 数据集说明第二部分:盲道及周边障碍物检测数据集
BlindPathObstacleDetectionDataset/
├── images/
│ ├── image_00001.jpg
│ ├── image_00002.jpg
│ └── ...
├── annotations/
│ ├── image_00001.xml
│ ├── image_00002.xml
│ └── ...
└── README.md # 数据集说明数据集使用说明
第一部分:盲道分割数据集
- images/:包含原始图像文件。
- masks/:包含对应图像的mask图,用于标注盲道的位置。
- README.md:包含数据集的具体说明和使用指南。
第二部分:盲道及周边障碍物检测数据集
- images/:包含原始图像文件。
- annotations/:包含XML格式的标注文件,使用VOC格式标注每个对象的位置。
- README.md:包含数据集的具体说明和使用指南。
示例代码
分割模型训练示例代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
from torchvision.models import deeplabv3_resnet101
from PIL import Image
import os
import numpy as np
class BlindPathSegmentationDataset(torch.utils.data.Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.image_dir = os.path.join(root_dir, 'images')
self.mask_dir = os.path.join(root_dir, 'masks')
self.images = os.listdir(self.image_dir)
self.transform = transform
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_name = self.images[idx]
image = Image.open(os.path.join(self.image_dir, img_name))
mask = Image.open(os.path.join(self.mask_dir, img_name.replace('.jpg', '.png')))
if self.transform:
image = self.transform(image)
mask = self.transform(mask)
return image, mask
def train_segmentation_model(model, dataloader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for inputs, labels in dataloader:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)['out']
loss = criterion(outputs, labels.squeeze(1).long())
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
epoch_loss = running_loss / len(dataloader.dataset)
return epoch_loss
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dataset = BlindPathSegmentationDataset(root_dir='data/BlindPathSegmentationDataset')
dataloader = DataLoader(dataset, batch_size=4, shuffle=True)
model = deeplabv3_resnet101(pretrained=True)
model.classifier[4] = nn.Conv2d(256, 2, kernel_size=(1, 1), stride=(1, 1))
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 20
for epoch in range(num_epochs):
train_loss = train_segmentation_model(model, dataloader, criterion, optimizer, device)
print(f'Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}')
if __name__ == '__main__':
main()检测模型训练示例代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.transforms import ToTensor
from torchvision.datasets.voc import VOCSegmentation
import os
import xml.etree.ElementTree as ET
class BlindPathObstacleDetectionDataset(torch.utils.data.Dataset):
def __init__(self, root_dir, transform=None):
self.root_dir = root_dir
self.image_dir = os.path.join(root_dir, 'images')
self.annotations_dir = os.path.join(root_dir, 'annotations')
self.images = os.listdir(self.image_dir)
self.transform = transform
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
img_name = self.images[idx]
image = Image.open(os.path.join(self.image_dir, img_name))
annotation = ET.parse(os.path.join(self.annotations_dir, img_name.replace('.jpg', '.xml')))
objects = annotation.findall('object')
boxes = []
labels = []
for obj in objects:
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text)
ymin = int(bbox.find('ymin').text)
xmax = int(bbox.find('xmax').text)
ymax = int(bbox.find('ymax').text)
label = obj.find('name').text
label_map = {'stop_sign': 1, 'person': 2, 'bicycle': 3, 'bus': 4, 'truck': 5, 'car': 6,
'motorbike': 7, 'reflective_cone': 8, 'ashcan': 9, 'warning_column': 10,
'spherical_roadblock': 11, 'pole': 12, 'dog': 13, 'tricycle': 14, 'fire_hydrant': 15}
label_id = label_map[label]
boxes.append([xmin, ymin, xmax, ymax])
labels.append(label_id)
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
if self.transform:
image = self.transform(image)
return image, {'boxes': boxes, 'labels': labels}
def train_detection_model(model, dataloader, optimizer, device):
model.train()
running_loss = 0.0
for images, targets in dataloader:
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
running_loss += losses.item()
epoch_loss = running_loss / len(dataloader)
return epoch_loss
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dataset = BlindPathObstacleDetectionDataset(root_dir='data/BlindPathObstacleDetectionDataset')
dataloader = DataLoader(dataset, batch_size=4, shuffle=True, collate_fn=lambda b: tuple(zip(*b)))
model = fasterrcnn_resnet50_fpn(pretrained=True, num_classes=16)
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 20
for epoch in range(num_epochs):
train_loss = train_detection_model(model, dataloader, optimizer, device)
print(f'Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}')
if __name__ == '__main__':
main()项目目录结构
BlindPathData/
├── BlindPathSegmentationDataset/
│ ├── images/
│ ├── masks/
│ └── README.md
├── BlindPathObstacleDetectionDataset/
│ ├── images/
│ ├── annotations/
│ └── README.md
└── src/
├── segmentation.py # 分割模型训练代码
├── detection.py # 检测模型训练代码
└── README.md项目运行
确保安装了必要的依赖库:
pip install torch torchvision pillow然后分别运行分割和检测模型的训练代码:
python src/segmentation.py
python src/detection.py学习资源
项目中的代码包含了详细的注释,帮助初学者理解各个部分的功能和作用。同时,提供的数据集可以让用户快速上手,了解如何使用深度学习模型进行盲道分割和障碍物检测。
总结
这个盲道分割与障碍物检测系统是一个完整的解决方案,它不仅包含了数据集,还包括了训练分割和检测模型的代码。通过本项目,你可以深入学习如何使用深度学习模型进行图像分割和物体检测,并将其应用于实际场景中,提高智能系统的安全性。对于初学者来说,这是一个很好的学习平台,可以深入了解分割和检测技术及其在实际应用中的实现


















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









