







 排水管道缺陷(分割)数据集
排水管道缺陷(分割)数据集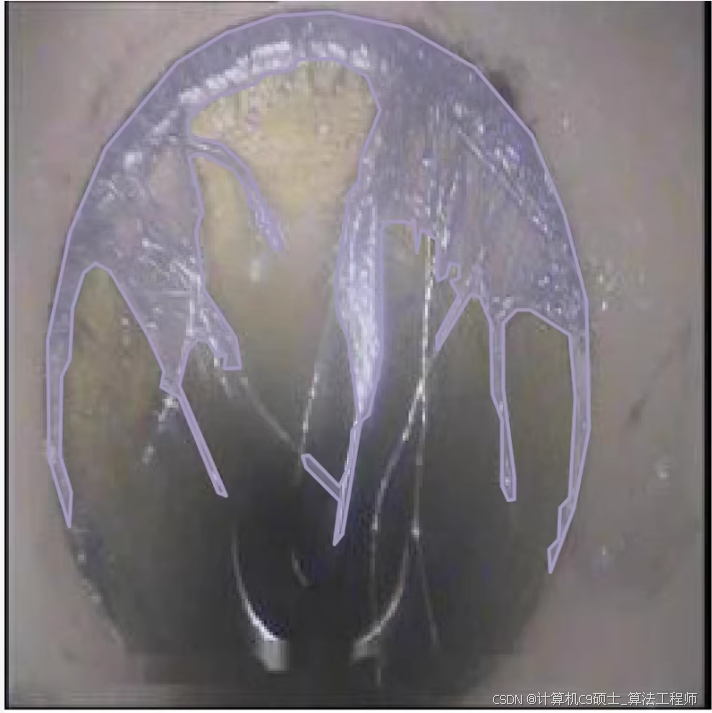
共4055张图像,均为原图,未经过数据增强
按照我国规程CJJ181-2012标注了7类缺陷
数据集包括图片和相应标注文件,有VOC数据集格式,文件后缀为.xml,可用于大部分模型训练。
使用YOLOv8来训练一个包含4055张图像的排水管道缺陷分割数据集。这个数据集包含7类缺陷,已标注为VOC格式,可以直接用于模型训练。
数据集描述
- 数据量:4055张图像
- 类别:
- 0: 缺陷1
- 1: 缺陷2
- 2: 缺陷3
- 3: 缺陷4
- 4: 缺陷5
- 5: 缺陷6
- 6: 缺陷7
- 标注格式:VOC格式(.xml文件)
- 应用场景:排水管道缺陷检测和分割
数据集组织
假设你的数据集目录结构如下:
drain_pipe_defect_dataset/
├── images/
│ ├── 000001.jpg
│ ├── 000002.jpg
│ └── ...
├── annotations/
│ ├── 000001.xml
│ ├── 000002.xml
│ └── ...
└── data.yaml # 数据配置文件数据配置文件
创建或确认data.yaml文件是否正确配置了数据集路径和类别信息:
train: ./images/train/ # 训练集图像路径
val: ./images/val/ # 验证集图像路径
# Classes
nc: 7 # 类别数量
names:
- 缺陷1
- 缺陷2
- 缺陷3
- 缺陷4
- 缺陷5
- 缺陷6
- 缺陷7 # 类别名称列表转换VOC标注为YOLO格式
首先,我们需要将VOC格式的标注文件转换为YOLO格式。可以使用Python脚本来完成这个任务。
import os
import xml.etree.ElementTree as ET
import shutil
# 定义类别映射
class_map = {
'缺陷1': 0,
'缺陷2': 1,
'缺陷3': 2,
'缺陷4': 3,
'缺陷5': 4,
'缺陷6': 5,
'缺陷7': 6
}
# 定义转换函数
def convert_voc_to_yolo(voc_file, yolo_file, image_size, class_map):
tree = ET.parse(voc_file)
root = tree.getroot()
with open(yolo_file, 'w') as f:
for obj in root.findall('object'):
class_name = obj.find('name').text
if class_name not in class_map:
continue
class_id = class_map[class_name]
bbox = obj.find('bndbox')
x_min = int(bbox.find('xmin').text)
y_min = int(bbox.find('ymin').text)
x_max = int(bbox.find('xmax').text)
y_max = int(bbox.find('ymax').text)
x_center = (x_min + x_max) / 2.0 / image_size[0]
y_center = (y_min + y_max) / 2.0 / image_size[1]
width = (x_max - x_min) / image_size[0]
height = (y_max - y_min) / image_size[1]
f.write(f"{class_id} {x_center} {y_center} {width} {height}\n")
# 读取图像尺寸
def get_image_size(image_path):
from PIL import Image
with Image.open(image_path) as img:
return img.width, img.height
# 转换所有标注文件
def convert_all_annotations(image_dir, annotation_dir, output_dir):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for filename in os.listdir(annotation_dir):
if filename.endswith('.xml'):
image_filename = filename.replace('.xml', '.jpg')
image_path = os.path.join(image_dir, image_filename)
voc_file = os.path.join(annotation_dir, filename)
yolo_file = os.path.join(output_dir, filename.replace('.xml', '.txt'))
image_size = get_image_size(image_path)
convert_voc_to_yolo(voc_file, yolo_file, image_size, class_map)
# 调用转换函数
image_dir = './drain_pipe_defect_dataset/images'
annotation_dir = './drain_pipe_defect_dataset/annotations'
output_dir = './drain_pipe_defect_dataset/labels'
convert_all_annotations(image_dir, annotation_dir, output_dir)安装YOLOv8
如果你还没有安装YOLOv8,可以使用以下命令安装:
pip install ultralytics训练模型
使用YOLOv8训练模型的命令非常简单,你可以直接使用以下命令开始训练:
cd path/to/drain_pipe_defect_dataset/
# 克隆YOLOv8仓库
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
# 开始训练
python yolo.py detect train data=../data.yaml model=yolov8n.pt epochs=100 imgsz=640 batch=16在这个命令中:
data=../data.yaml:指定数据配置文件。model=yolov8n.pt:指定预训练权重,这里使用的是YOLOv8的小模型。epochs=100:训练轮数。imgsz=640:输入图像的大小。batch=16:批量大小。
模型评估
训练完成后,可以使用以下命令评估模型在验证集上的表现:
python yolo.py detect val data=../data.yaml model=runs/detect/train/weights/best.pt imgsz=640这里的runs/detect/train/weights/best.pt是训练过程中产生的最佳模型权重文件。
模型预测
你可以使用训练好的模型对新图像进行预测:
python yolo.py detect predict source=path/to/your/image.jpg model=runs/detect/train/weights/best.pt imgsz=640 conf=0.4 iou=0.5查看训练结果
训练过程中的日志和结果会保存在runs/detect/目录下,你可以查看训练过程中的损失、精度等信息。
数据增强
为了进一步提高模型性能,可以使用数据增强技术。以下是一个简单的数据增强示例:
-
安装
albumentations库:pip install -U albumentations -
在
yolo.py中添加数据增强:import albumentations as A from albumentations.pytorch import ToTensorV2 import cv2 # 定义数据增强 transform = A.Compose([ A.RandomSizedBBoxSafeCrop(width=640, height=640, erosion_rate=0.2), A.HorizontalFlip(p=0.5), A.VerticalFlip(p=0.5), A.Rotate(limit=10, p=0.5, border_mode=cv2.BORDER_CONSTANT), A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2, p=0.5), A.GaussNoise(var_limit=(10.0, 50.0), p=0.5), A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]), ToTensorV2() ], bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels'])) # 在数据加载器中应用数据增强 def collate_fn(batch): images, targets = zip(*batch) transformed_images = [] transformed_targets = [] for img, target in zip(images, targets): bboxes = target['bboxes'] class_labels = target['labels'] augmented = transform(image=img, bboxes=bboxes, class_labels=class_labels) transformed_images.append(augmented['image']) transformed_targets.append({ 'bboxes': augmented['bboxes'], 'labels': augmented['class_labels'] }) return torch.stack(transformed_images), transformed_targets
注意事项
- 数据集质量:确保数据集的质量,包括清晰度、标注准确性等。
- 模型选择:可以选择更强大的模型版本(如YOLOv8m、YOLOv8l等)以提高性能。
- 超参数调整:根据实际情况调整超参数,如批量大小(
batch)、图像大小(imgsz)等。 - 监控性能:训练过程中监控损失函数和mAP指标,确保模型收敛。
通过上述步骤,你可以使用YOLOv8来训练一个排水管道缺陷检测数据集,并使用训练好的模型进行预测。

















 881
881

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









