







深度学习目标检测YOLOv5如何训练使用排水管道缺陷检测数据集 检测排水管道中支管暗接、变形、沉积、错口、残墙坝根、异物插入、腐蚀、浮渣、结垢、破裂、起伏、树根、渗漏、脱节、材料脱落等
文章目录
以下文字及代码仅供参考。、
排水管道缺陷检测包含数据集

16类:支管暗接、变形、沉积、错口、残墙坝根、异物插入、腐蚀、浮渣、结垢、破裂、起伏、树根、渗漏、脱节、材料脱落、障碍物。
检测等级:根据CJJ181技术规程定义,不同类别对应不同等级,最小为1级,最大为4级。
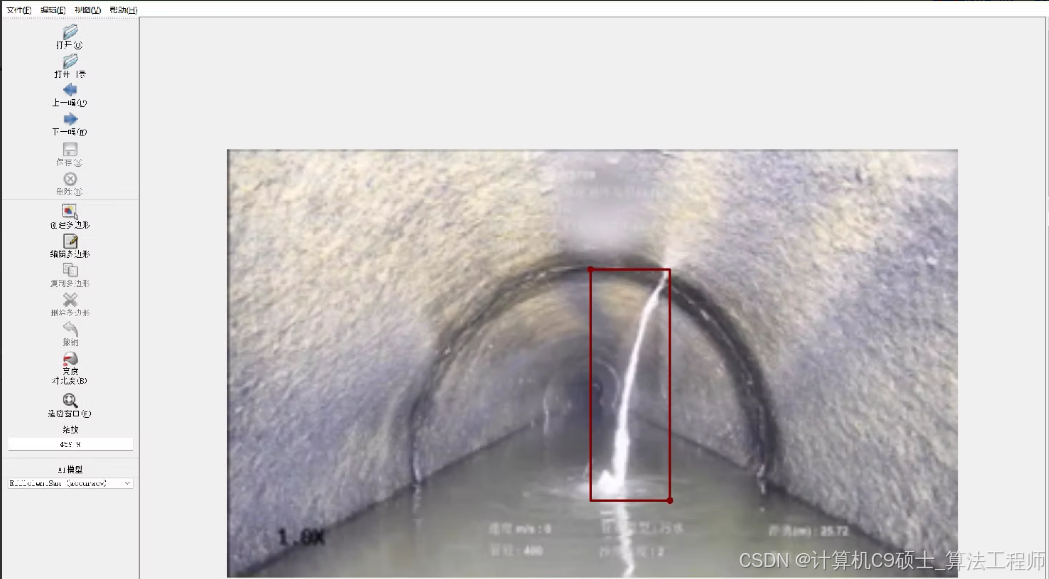
数据集12013张,数据集由labelme标注且有缺陷的类别和等级标签
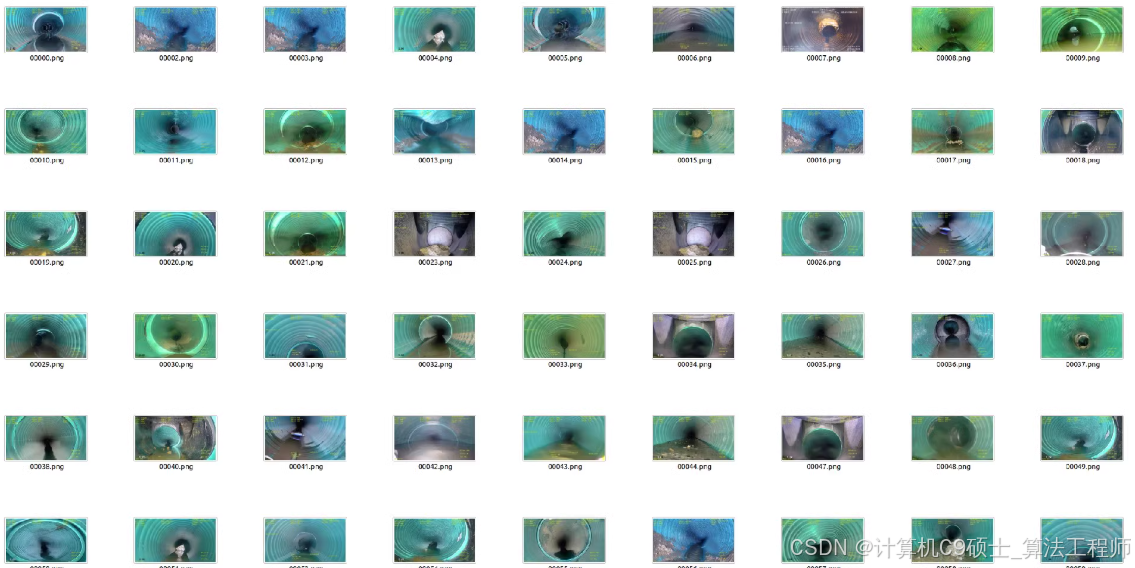
排水管道缺陷检测数据集
数据集为排水管道内部缺陷的自动检测和分类任务设计,包含12,013张标注图像,覆盖了16种不同的排水管道缺陷类别。
数据集详情
- 图像数量:12,013张
- 缺陷类别:共16类,包括:
- 支管暗接
- 变形
- 沉积
- 错口
- 残墙坝根
- 异物插入
- 腐蚀
- 浮渣
- 结垢
- 破裂
- 起伏
- 树根
- 渗漏
- 脱节
- 材料脱落
- 障碍物
- 检测等级:依据CJJ181技术规程,不同类型的缺陷被划分为1至4个等级,代表了缺陷的严重程度。
- 标注格式:采用LabelMe工具进行标注,生成的标注文件中既包括缺陷类别也包括其对应的等级标签。
使用指南
数据准备
确保您的环境中安装了必要的库:
pip install labelme tensorflow torchvision opencv-python lxml
加载数据
使用LabelMe进行标注,数据集中的每个图像都会有一个对应的JSON格式的标注文件。简单的Python脚本示例,用于读取这些JSON文件并提取相关信息。
import json
import os
from PIL import Image
def load_labelme_dataset(annotations_dir, images_dir):
dataset = []
for annotation_file in os.listdir(annotations_dir):
if annotation_file.endswith('.json'):
with open(os.path.join(annotations_dir, annotation_file), 'r') as f:
data = json.load(f)
image_filename = data['imagePath']
img = Image.open(os.path.join(images_dir, image_filename))
for shape in data['shapes']:
defect_type = shape['label']
points = shape['points']
# 这里可以添加代码来处理点,例如转换成边界框或掩码
dataset.append({
'image': img,
'defect_type': defect_type,
'points': points,
})
return dataset
模型训练
选择合适的目标检测模型架构(如YOLOv5、Faster R-CNN等)并利用上述加载的数据进行训练。请根据自己的需求调整模型参数,如学习率、批次大小和训练轮数等。
:使用YOLOv5进行训练
假设已经下载并配置好了YOLOv5环境,并按照要求修改了数据配置文件data/coco128.yaml指向你的数据集路径和类别数量。
# 修改YOLOv5的数据配置文件data/coco128.yaml,指定新的路径和类别数量
train: ./path/to/train/images
val: ./path/to/val/images
nc: 16 # 类别数量
names: ['branch_pipe', 'deformation', 'sediment', 'misalignment', 'dam_root', 'foreign_body', 'corrosion', 'scum', 'scale', 'crack', 'undulation', 'tree_root', 'leakage', 'disconnection', 'material_loss', 'obstacle']
# 开始训练
python train.py --img 640 --batch 16 --epochs 100 --data path/to/your/data.yaml --weights yolov5s.pt
排水管道缺陷检测数据集进行模型训练、可视化评估及推理,我们可以遵循以下步骤。这里我们将以YOLOv5,因为它是一个流行且性能强大的目标检测框架,并且易于上手和部署。
1. 环境配置
首先,确保你的环境中安装了必要的依赖项:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
pip install -r requirements.txt
2. 数据准备
根据您的描述,数据集包含图像和对应的LabelMe标注文件(JSON格式)。我们需要将这些标注转换为YOLOv5可接受的格式(即labels文件夹下的文本文件,每行代表一个边界框及其类别ID)。
转换LabelMe JSON到YOLOv5标签格式的Python脚本示例:
import json
from pathlib import Path
import cv2
def convert_labelme_to_yolo(labelme_json, output_dir, classes):
with open(labelme_json) as f:
data = json.load(f)
image_height = data['imageHeight']
image_width = data['imageWidth']
output_file_path = Path(output_dir) / (Path(labelme_json).stem + '.txt')
with open(output_file_path, 'w') as out_f:
for shape in data['shapes']:
label = shape['label']
points = shape['points']
# 计算YOLO格式需要的中心点坐标、宽度和高度
x_center = (points[0][0] + points[1][0]) / 2.0 / image_width
y_center = (points[0][1] + points[1][1]) / 2.0 / image_height
width = abs(points[0][0] - points[1][0]) / image_width
height = abs(points[0][1] - points[1][1]) / image_height
class_id = classes.index(label)
out_f.write(f"{class_id} {x_center} {y_center} {width} {height}\n")
# 使用方法
classes = ['branch_pipe', 'deformation', 'sediment', ...] # 按照实际类别填写
for json_file in Path('path/to/your/annotations').glob('*.json'):
convert_labelme_to_yolo(str(json_file), 'path/to/output/labels', classes)
同时,你需要创建一个data.yaml文件来定义你的数据集路径和类别信息:
train: ./path/to/train/images
val: ./path/to/val/images
nc: 16 # 类别数量
names: ['branch_pipe', 'deformation', 'sediment', ..., 'obstacle'] # 根据实际情况调整
3. 模型训练
使用YOLOv5进行训练:
python train.py --img 640 --batch 16 --epochs 100 --data path/to/your/data.yaml --weights yolov5s.pt
4. 可视化与评估
训练完成后,可以使用以下命令进行验证集上的评估并生成预测结果的可视化:
python detect.py --weights runs/train/exp/weights/best.pt --source ./path/to/val/images --save-txt --save-conf --conf-thres 0.5
这将在指定的输出目录中生成带有边界框的图像,以及每个检测结果的置信度分数。
5. 推理
对于新的图片或视频流,你可以使用类似的命令进行推理:
python detect.py --weights runs/train/exp/weights/best.pt --source ./path/to/new/image.jpg --conf-thres 0.5
进行推理(即使用已经训练好的模型对新的数据做出预测)的过程通常包含几个步骤:加载模型、准备输入数据、运行推理以及解析结果。基于之前讨论的YOLOv5框架,下面是具体如何操作的指南:
1. 确认环境已配置
确保你的环境中已经安装了所有必要的库和YOLOv5框架,并且你已经有了一套训练好的权重文件(.pt或.weights格式)。如果按照之前的指导进行了模型训练,你应该在runs/train/exp/weights/目录下找到best.pt或last.pt。
2. 使用YOLOv5进行推理
YOLOv5提供了一个方便的脚本detect.py用于执行推理。你可以直接使用这个脚本来进行预测。
基本命令:
python detect.py --weights runs/train/exp/weights/best.pt --source path/to/your/image/or/video --conf-thres 0.5 --save-txt
--weights:指定你的模型权重文件路径。--source:可以是单张图片、一个包含多张图片的文件夹、视频文件甚至是网络摄像头('0'表示默认摄像头)的路径。--conf-thres:置信度阈值,默认为0.25。你可以根据实际情况调整,以控制预测结果的准确性。--save-txt:保存每个检测到的对象的信息为文本文件,如果你需要进一步处理这些信息的话。
3. 解析结果
运行上述命令后,YOLOv5会生成带有边界框和标签的新图像或视频,并将它们保存在inference/output目录中。如果你想获取更详细的结果,比如每个检测对象的具体位置和类别信息,可以通过设置--save-txt选项来实现。这会在inference/output目录下生成对应的文本文件,其中每行代表一个检测对象,包含了它的类别ID、置信度分数及其边界框的位置信息。
4. 自定义代码进行推理
如果你想要更多自定义的推理过程,例如集成到自己的应用中,可以直接调用YOLOv5的API。以下是一个简单的例子:
from models.experimental import attempt_load
from utils.general import non_max_suppression, scale_coords
from utils.torch_utils import select_device
import torch
# 加载模型
device = select_device('') # 使用CPU或者指定GPU, e.g., '0'
model = attempt_load('runs/train/exp/weights/best.pt', map_location=device)
model.eval()
# 准备输入(这里假设img是一个已经预处理过的torch.Tensor)
img = ... # 这里应该是你读取并预处理后的图片
img = img.to(device)
# 推理
with torch.no_grad():
pred = model(img)[0]
# 后处理
pred = non_max_suppression(pred, conf_thres=0.5, iou_thres=0.45)
# pred现在包含了一系列检测结果,你可以遍历它们并做进一步处理
for det in pred:
if len(det):
# 尺寸调整等后续处理
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], img_shape).round()
# 对于每一个det,你可以得到它的坐标、类别ID和置信度分数
以上就是使用YOLOv5进行推理的基本流程。


















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









