







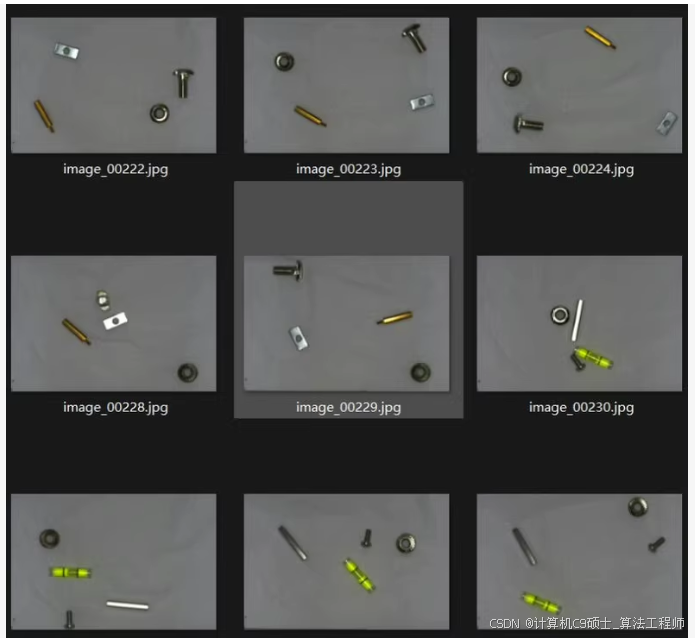
工业零部件篇——13种工业零件检测数据集 该数据集共有2100张图片数据; 已处理成yolo格式、voc格式;
标签类别及标签个数: Double hexagonal column 双六角柱 917 Flange nut 法兰螺母 867 Hexagon nut 六角螺母 943 Hexagon pillar 六角柱 903 Hexagon screw 六角螺钉 895 Hexagonal steel column 六角钢柱 920 Horizontal bubble 水平仪 897 Keybar 垫片 945 Plastic cushion pillar 塑料缓冲柱 908 Rectangular nut 矩形螺母 924 Round head screw 圆头螺丝 889 Spring washer 弹簧垫圈 940 T-shaped screw T 型螺丝 910


使用YOLOv8来训练一个包含2100张图像的13种工业零件检测数据集。这个数据集已经处理成YOLO格式和VOC格式,可以直接用于模型训练。
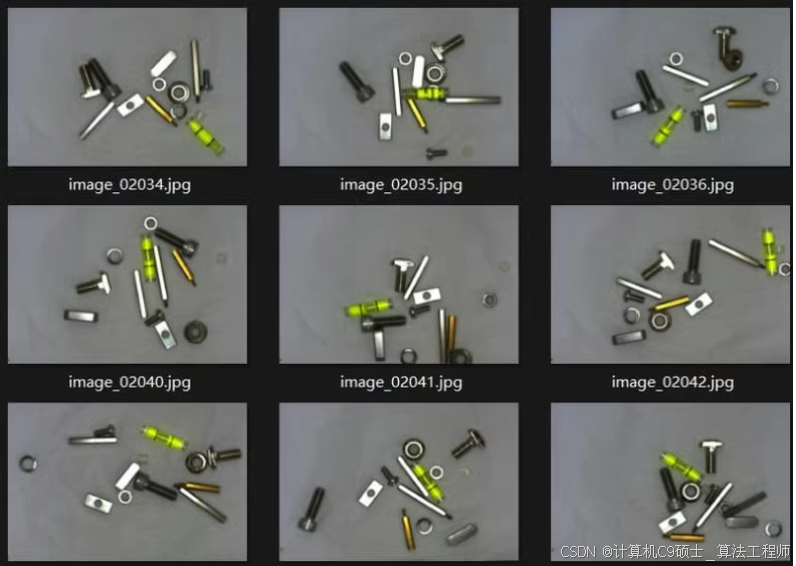
数据集描述
数据量:2100张图像
类别:
0: Double hexagonal column(双六角柱)
1: Flange nut(法兰螺母)
2: Hexagon nut(六角螺母)
3: Hexagon pillar(六角柱)
4: Hexagon screw(六角螺钉)
5: Hexagonal steel column(六角钢柱)
6: Horizontal bubble(水平仪)
7: Keybar(垫片)
8: Plastic cushion pillar(塑料缓冲柱)
9: Rectangular nut(矩形螺母)
10: Round head screw(圆头螺丝)
11: Spring washer(弹簧垫圈)
12: T-shaped screw(T型螺丝)
标注格式:YOLO格式、VOC格式
应用场景:工业零件检测
数据集组织
假设你的数据集目录结构如下:
industrial_parts_dataset/
├── images/
│ ├── train/
│ │ ├── 000001.jpg
│ │ ├── 000002.jpg
│ │ └── …
│ ├── val/
│ │ ├── 000001.jpg
│ │ ├── 000002.jpg
│ │ └── …
│ └── test/
│ ├── 000001.jpg
│ ├── 000002.jpg
│ └── …
├── labels_yolo/
│ ├── train/
│ │ ├── 000001.txt
│ │ ├── 000002.txt
│ │ └── …
│ ├── val/
│ │ ├── 000001.txt
│ │ ├── 000002.txt
│ │ └── …
│ └── test/
│ ├── 000001.txt
│ ├── 000002.txt
│ └── …
├── labels_voc/
│ ├── train/
│ │ ├── 000001.xml
│ │ ├── 000002.xml
│ │ └── …
│ ├── val/
│ │ ├── 000001.xml
│ │ ├── 000002.xml
│ │ └── …
│ └── test/
│ ├── 000001.xml
│ ├── 000002.xml
│ └── …
└── data.yaml # 数据配置文件
数据配置文件
创建或确认data.yaml文件是否正确配置了数据集路径和类别信息:
yaml
深色版本
train: ./images/train/ # 训练集图像路径
val: ./images/val/ # 验证集图像路径
test: ./images/test/ # 测试集图像路径

Classes
nc: 13 # 类别数量
names:
- Double hexagonal column
- Flange nut
- Hexagon nut
- Hexagon pillar
- Hexagon screw
- Hexagonal steel column
- Horizontal bubble
- Keybar
- Plastic cushion pillar
- Rectangular nut
- Round head screw
- Spring washer
- T-shaped screw # 类别名称列表
安装YOLOv8
如果你还没有安装YOLOv8,可以使用以下命令安装:
bash
深色版本
pip install ultralytics
训练模型
使用YOLOv8训练模型的命令非常简单,你可以直接使用以下命令开始训练:
bash
深色版本
cd path/to/industrial_parts_dataset/
克隆YOLOv8仓库
git clone https://github.com/ultralytics/ultralytics.git
cd ultralytics
开始训练
python yolo.py detect train data=…/data.yaml model=yolov8n.pt epochs=100 imgsz=640 batch=16
在这个命令中:
data=…/data.yaml:指定数据配置文件。
model=yolov8n.pt:指定预训练权重,这里使用的是YOLOv8的小模型。
epochs=100:训练轮数。
imgsz=640:输入图像的大小。
batch=16:批量大小。
模型评估
训练完成后,可以使用以下命令评估模型在验证集上的表现:
bash
深色版本
python yolo.py detect val data=…/data.yaml model=runs/detect/train/weights/best.pt imgsz=640
这里的runs/detect/train/weights/best.pt是训练过程中产生的最佳模型权重文件。
模型预测
你可以使用训练好的模型对新图像进行预测:
bash
深色版本
python yolo.py detect predict source=path/to/your/image.jpg model=runs/detect/train/weights/best.pt imgsz=640 conf=0.4 iou=0.5
查看训练结果
训练过程中的日志和结果会保存在runs/detect/目录下,你可以查看训练过程中的损失、精度等信息。
数据增强
为了进一步提高模型性能,可以使用数据增强技术。以下是一个简单的数据增强示例:
安装albumentations库:
bash
深色版本
pip install -U albumentations
在yolo.py中添加数据增强:
python
深色版本
import albumentations as A
from albumentations.pytorch import ToTensorV2
import cv2
定义数据增强
transform = A.Compose([
A.RandomSizedCrop(min_max_height=(400, 640), height=640, width=640, p=0.5),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Rotate(limit=10, p=0.5, border_mode=cv2.BORDER_CONSTANT),
A.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2, p=0.5),
A.GaussNoise(var_limit=(10.0, 50.0), p=0.5),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2()
], bbox_params=A.BboxParams(format=‘yolo’, label_fields=[‘class_labels’]))
在数据加载器中应用数据增强
def collate_fn(batch):
images, targets = zip(*batch)
transformed_images = []
transformed_targets = []
for img, target in zip(images, targets):
bboxes = target['bboxes']
class_labels = target['labels']
augmented = transform(image=img, bboxes=bboxes, class_labels=class_labels)
transformed_images.append(augmented['image'])
transformed_targets.append({
'bboxes': augmented['bboxes'],
'labels': augmented['class_labels']
})
return torch.stack(transformed_images), transformed_targets
注意事项
数据集质量:确保数据集的质量,包括清晰度、标注准确性等。
模型选择:可以选择更强大的模型版本(如YOLOv8m、YOLOv8l等)以提高性能。
超参数调整:根据实际情况调整超参数,如批量大小(batch)、图像大小(imgsz)等。
监控性能:训练过程中监控损失函数和mAP指标,确保模型收敛。
通过上述步骤,你可以使用YOLOv8来训练一个包含13种工业零件检测的数据集,并使用训练好的模型进行预测。

















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









