






深度学习模型 如何使用Swin-Transformer进行路面分割 并建立基于swin-transformer的路面分割
以下文字及代码仅供参考。
基于swin-transformer的路面分割
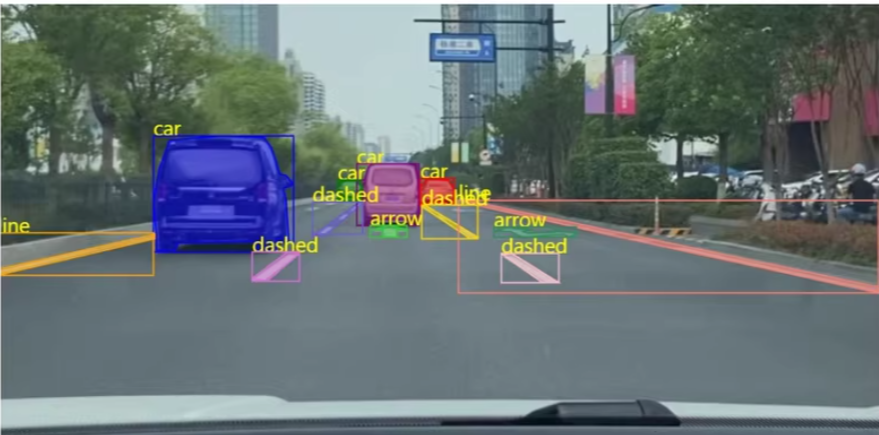
1
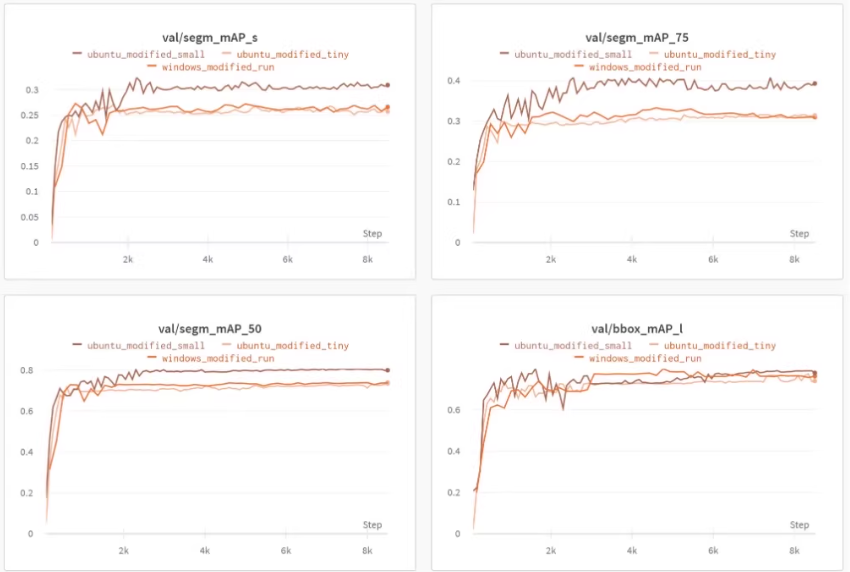
基于Swin-Transformer的路面分割是一个复杂的任务,涉及到深度学习模型的设计、数据准备、训练和推理等多个步骤。以下是一个详细的代码示例,展示如何使用Swin-Transformer进行路面分割。
1. 环境搭建
确保安装了必要的库:
pip install torch torchvision torchaudio timm numpy opencv-python matplotlib
2. 数据准备
2.1 数据集格式
假设你已经有了标注好的数据集,其中包含图像文件和对应的分割标签文件(通常为.png格式)。
2.2 数据加载
编写一个自定义的数据加载器来读取图像和标签:
import os
import torch
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import numpy as np
class RoadSegmentationDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_path = os.path.join(self.image_dir, self.images[index])
mask_path = os.path.join(self.mask_dir, self.images[index].replace('.jpg', '.png'))
image = np.array(Image.open(img_path).convert("RGB"))
mask = np.array(Image.open(mask_path), dtype=np.float32)
mask[mask == 255.0] = 1.0
if self.transform is not None:
augmentations = self.transform(image=image, mask=mask)
image = augmentations["image"]
mask = augmentations["mask"]
return image, mask
# 示例:创建数据加载器
from albumentations.pytorch import ToTensorV2
import albumentations as A
transform = A.Compose(
[
A.Resize(height=256, width=256),
A.Normalize(
mean=[0.0, 0.0, 0.0],
std=[1.0, 1.0, 1.0],
max_pixel_value=255.0,
),
ToTensorV2(),
],
)
dataset = RoadSegmentationDataset(
image_dir="path/to/images",
mask_dir="path/to/masks",
transform=transform,
)
dataloader = DataLoader(dataset, batch_size=4, shuffle=True, num_workers=2)
3. 模型构建
使用Swin-Transformer作为编码器,并添加解码器部分以进行分割任务:
import torch.nn as nn
import timm
class SwinTransformerSegmentation(nn.Module):
def __init__(self, num_classes=1):
super(SwinTransformerSegmentation, self).__init__()
self.encoder = timm.create_model('swin_base_patch4_window7_224', pretrained=True, in_chans=3)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(1024, 512, kernel_size=2, stride=2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(512, 256, kernel_size=2, stride=2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2),
nn.ReLU(inplace=True),
nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2),
nn.ReLU(inplace=True),
nn.Conv2d(64, num_classes, kernel_size=1),
)
def forward(self, x):
features = self.encoder.forward_features(x)
out = self.decoder(features)
return out
model = SwinTransformerSegmentation(num_classes=1)
4. 训练模型
编写训练循环来优化模型参数:
import torch.optim as optim
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for images, masks in dataloader:
images = images.to(device)
masks = masks.unsqueeze(1).to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, masks)
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
5. 推理与可视化
在新的图像上进行推理并可视化结果:
import matplotlib.pyplot as plt
def predict_and_visualize(image_path):
model.eval()
image = Image.open(image_path).convert("RGB")
image = transform(image=image)["image"].unsqueeze(0).to(device)
with torch.no_grad():
output = model(image)
output = torch.sigmoid(output).squeeze().cpu().numpy()
output = (output > 0.5).astype(np.uint8)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(cv2.cvtColor(cv2.imread(image_path), cv2.COLOR_BGR2RGB))
plt.title('Input Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(output, cmap='gray')
plt.title('Predicted Mask')
plt.axis('off')
plt.show()
predict_and_visualize("path/to/test/image.jpg")
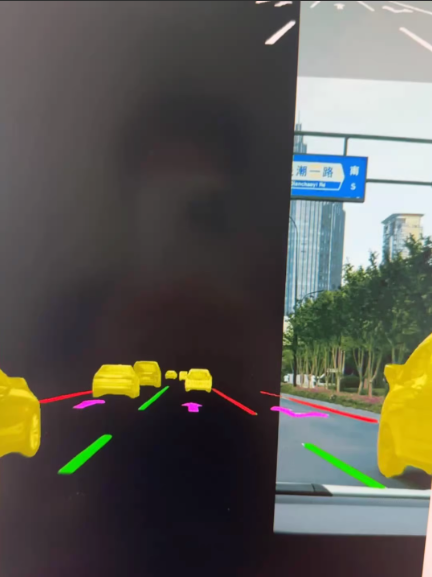
通过上述步骤,你可以构建一个基于Swin-Transformer的路面分割系统,并在新的图像上进行推理和可视化。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









