






基于大数据情感分析的网络舆情分析系统
实现功能
在文本挖掘领域,文本聚类是一类常见而又重要的数据挖掘手段,同时也是很多其他挖掘操作的前置工作。随着互联网的高速发展,文本聚类在Web数据处理相关方面应用尤其广泛,例如推荐系统、网络舆情、各类文本挖掘及相关应用。本项目收集了微博相关热点文章数据,并对评论进行情感分析统计,建立web可视化系统。
1
基于大数据情感分析的网络舆情分析系统是一个综合性,涉及数据收集、文本处理、情感分析、数据可视化等多个环节。\关键代码片段和技术细节。分享
关键代码部分,展示,仅供参考。
1. 环境配置
确保安装了必要的库:
pip install pandas numpy jieba requests beautifulsoup4 flask plotly dash wordcloud matplotlib seaborn
2. 数据收集
使用Python的requests和BeautifulSoup库从微博等平台抓取热点文章及其评论数据。
import requests
from bs4 import BeautifulSoup
import pandas as pd
def fetch_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 根据网页结构解析数据
articles = []
for article in soup.find_all('div', class_='article'):
title = article.find('h2').text
content = article.find('p').text
comments = [comment.text for comment in article.find_all('span', class_='comment')]
articles.append({'title': title, 'content': content, 'comments': comments})
return pd.DataFrame(articles)
# 示例URL
url = 'https://example.com/weibo'
data = fetch_data(url)
3. 文本预处理
使用jieba进行中文分词,并对文本进行清洗和标准化处理。
import jieba
import re
def preprocess_text(text):
text = re.sub(r'\W+', ' ', text) # 移除非字母数字字符
words = list(jieba.cut(text))
return ' '.join(words)
data['content'] = data['content'].apply(preprocess_text)
data['comments'] = data['comments'].apply(lambda x: [preprocess_text(comment) for comment in x])
4. 情感分析
使用预训练的情感分析模型或自定义规则进行情感分析。
from transformers import pipeline
sentiment_pipeline = pipeline("sentiment-analysis", model="distilbert-base-uncased-finetuned-sst-2-english")
def analyze_sentiment(text):
result = sentiment_pipeline(text)[0]
return result['label'], result['score']
data['sentiment'] = data['content'].apply(analyze_sentiment)
data['comments_sentiment'] = data['comments'].apply(lambda x: [analyze_sentiment(comment) for comment in x])
5. 数据可视化
使用Plotly和Dash构建Web可视化系统。
import plotly.express as px
from dash import Dash, dcc, html
from dash.dependencies import Input, Output
app = Dash(__name__)
app.layout = html.Div([
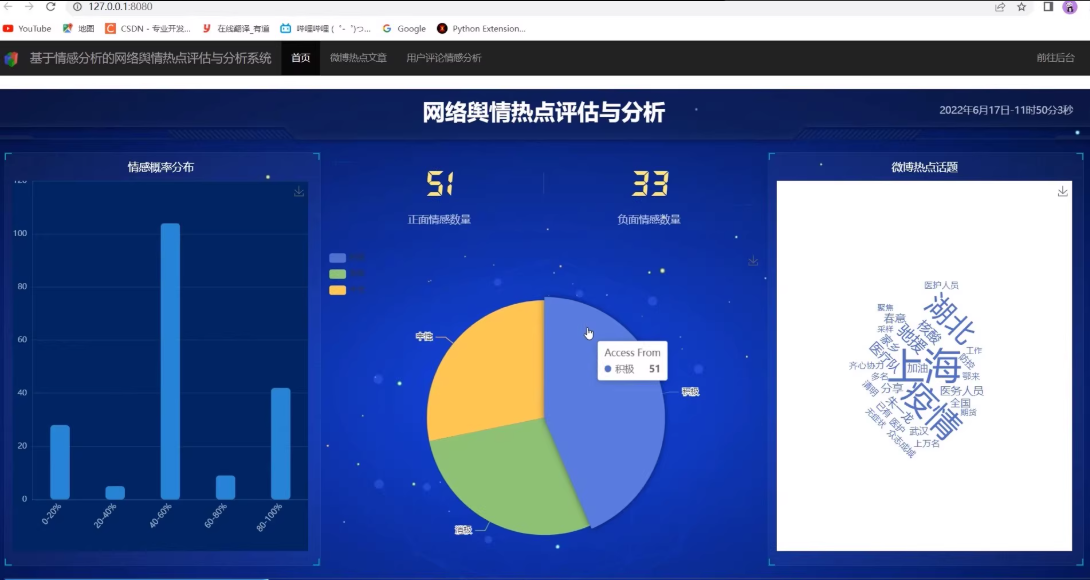
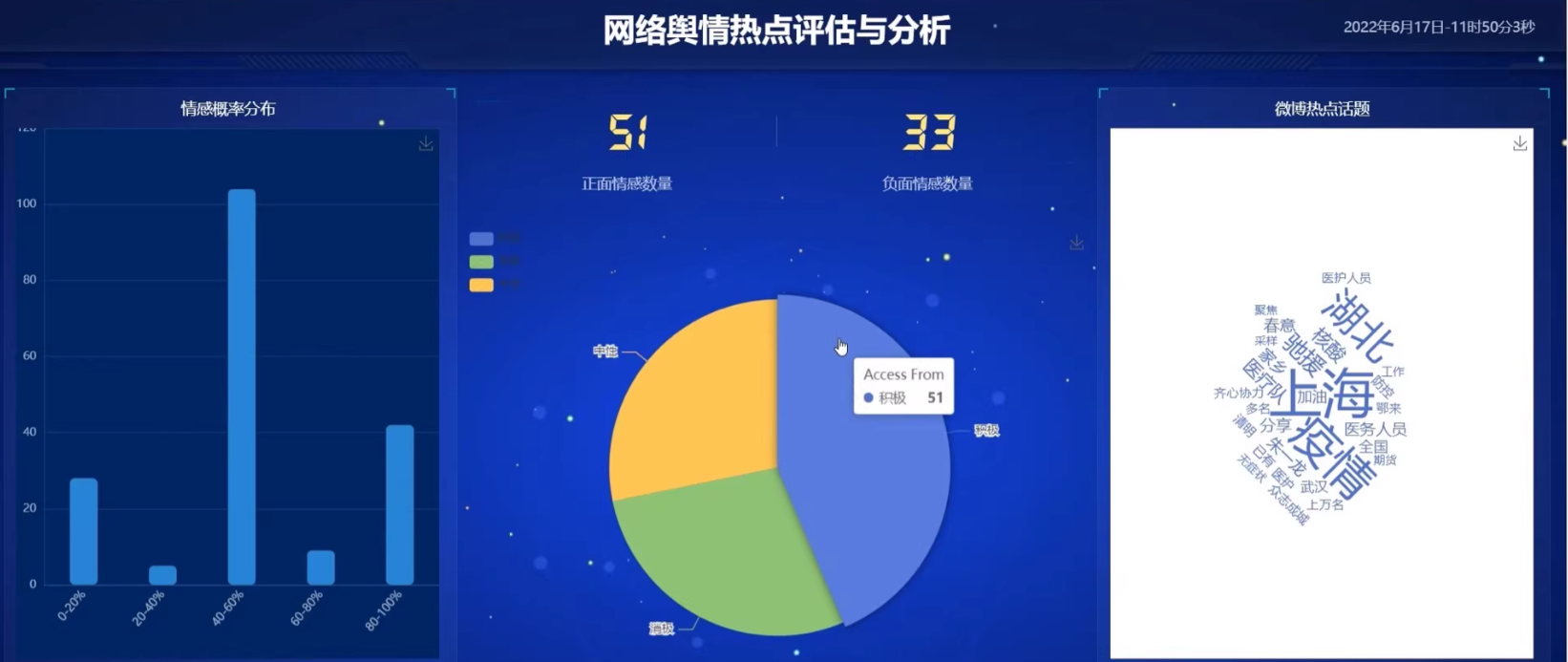
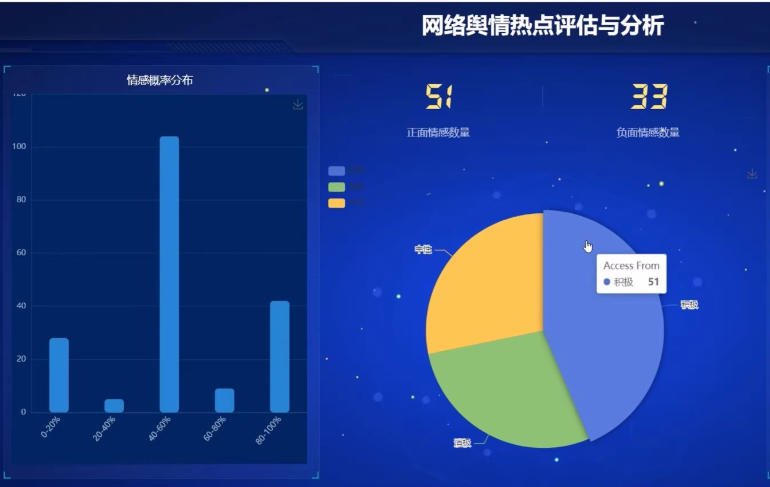
html.H1("网络舆情热点评估与分析"),
dcc.Graph(id='sentiment-pie'),
dcc.Graph(id='sentiment-histogram'),
dcc.Graph(id='word-cloud')
])
@app.callback(
Output('sentiment-pie', 'figure'),
Input('sentiment-pie', 'hoverData')
)
def update_pie_chart(hoverData):
labels = ['正面', '负面']
values = [sum([1 for s in data['sentiment'] if s[0] == 'POSITIVE']),
sum([1 for s in data['sentiment'] if s[0] == 'NEGATIVE'])]
fig = px.pie(values=values, names=labels, title='情感分布')
return fig
@app.callback(
Output('sentiment-histogram', 'figure'),
Input('sentiment-histogram', 'hoverData')
)
def update_histogram(hoverData):
scores = [s[1] for s in data['sentiment']]
fig = px.histogram(x=scores, nbins=10, title='情感概率分布')
return fig
@app.callback(
Output('word-cloud', 'figure'),
Input('word-cloud', 'hoverData')
)
def update_word_cloud(hoverData):
all_words = ' '.join(data['content'])
wordcloud = WordCloud(width=800, height=400).generate(all_words)
fig = px.imshow(wordcloud, title='词云图')
return fig
if __name__ == '__main__':
app.run_server(debug=True)
6. 运行系统
启动Flask服务器并访问指定端口查看可视化结果。
python app.py
打开浏览器访问http://127.0.0.1:8050/即可看到网络舆情分析系统的可视化界面。
以上就是构建一个基于大数据情感分析的网络舆情分析系统的完整流程。根据具体需求和数据特点,可以进一步优化模型结构、调整超参数或采用更复杂的预处理技术以提高分析精度。
仅供参考部分关键代码。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









