






Python医学图像分割 通过训练医学类眼部血管分割数据集 建立基于UNet的眼底血管图像分割系统
以下文字及代码仅供参考。
Python医学图像分割(眼底血管分割)
基于UNet的眼底血管图像分割
构建一个基于UNet的眼底血管图像分割系统是一个涉及数据准备、模型设计与训练、以及结果评估等多个步骤的过程。以下是一个详细的指南,包括环境搭建、数据预处理、模型定义与训练、以及使用Python实现整个系统的代码示例。
1. 环境搭建
首先,确保你的开发环境已经安装了必要的库和工具。这里以Anaconda和PyTorch为例。
安装依赖
# 创建并激活虚拟环境
conda create -n retinal_segmentation python=3.8
conda activate retinal_segmentation
# 安装PyTorch和相关库
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
pip install numpy matplotlib scikit-image
2. 数据准备
收集和标注眼底血管图像数据集,用于训练UNet模型进行图像分割。常用的公开数据集有DRIVE、STARE等。
数据预处理
对数据进行预处理,包括裁剪、缩放、归一化等操作,以便于模型训练。
import os
import cv2
import numpy as np
from skimage import io
from torch.utils.data import Dataset, DataLoader
class RetinaDataset(Dataset):
def __init__(self, image_dir, mask_dir, transform=None):
self.image_dir = image_dir
self.mask_dir = mask_dir
self.transform = transform
self.images = os.listdir(image_dir)
def __len__(self):
return len(self.images)
def __getitem__(self, index):
img_path = os.path.join(self.image_dir, self.images[index])
mask_path = os.path.join(self.mask_dir, self.images[index].replace('.tif', '_manual1.gif'))
image = io.imread(img_path)
mask = io.imread(mask_path, as_gray=True)
if self.transform is not None:
image = self.transform(image)
mask = self.transform(mask)
return image, mask
def preprocess_image(image):
# 裁剪和缩放
image = cv2.resize(image, (512, 512))
# 归一化
image = image / 255.0
return image
3. 模型定义与训练
UNet模型定义
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels=3, n_classes=1):
super(UNet, self).__init__()
self.inc = DoubleConv(n_channels, 64)
self.down1 = nn.MaxPool2d(2)
self.conv1 = DoubleConv(64, 128)
self.down2 = nn.MaxPool2d(2)
self.conv2 = DoubleConv(128, 256)
self.up1 = nn.ConvTranspose2d(256, 128, kernel_size=2, stride=2)
self.conv3 = DoubleConv(256, 128)
self.up2 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.conv4 = DoubleConv(128, 64)
self.outc = nn.Conv2d(64, n_classes, kernel_size=1)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x2 = self.conv1(x2)
x3 = self.down2(x2)
x3 = self.conv2(x3)
x = self.up1(x3)
x = torch.cat([x2, x], dim=1)
x = self.conv3(x)
x = self.up2(x)
x = torch.cat([x1, x], dim=1)
x = self.conv4(x)
x = self.outc(x)
return torch.sigmoid(x)
训练模型
import torch.optim as optim
# 初始化模型和优化器
model = UNet()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 定义损失函数
criterion = nn.BCELoss()
# 训练循环
num_epochs = 100
for epoch in range(num_epochs):
for images, masks in dataloader:
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, masks.unsqueeze(1).float())
loss.backward()
optimizer.step()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
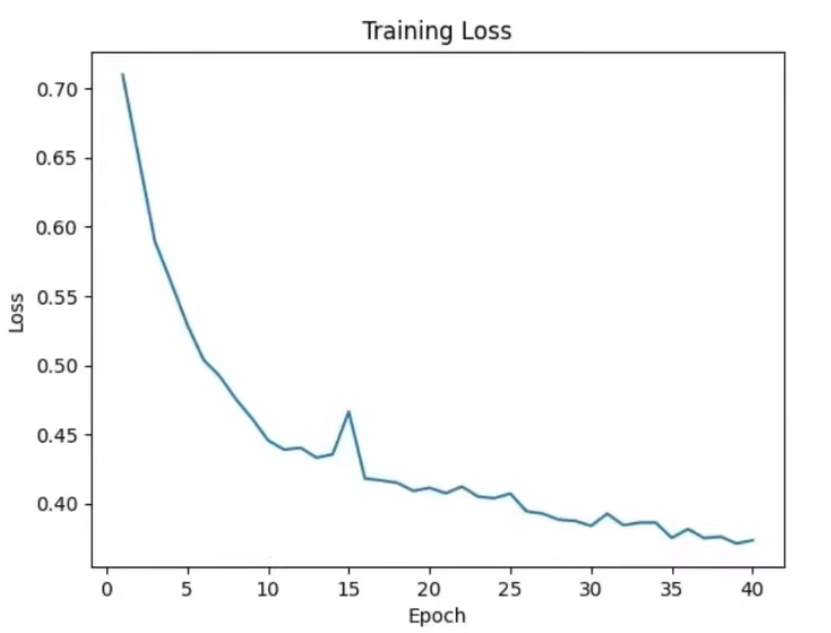
4. 结果评估与可视化
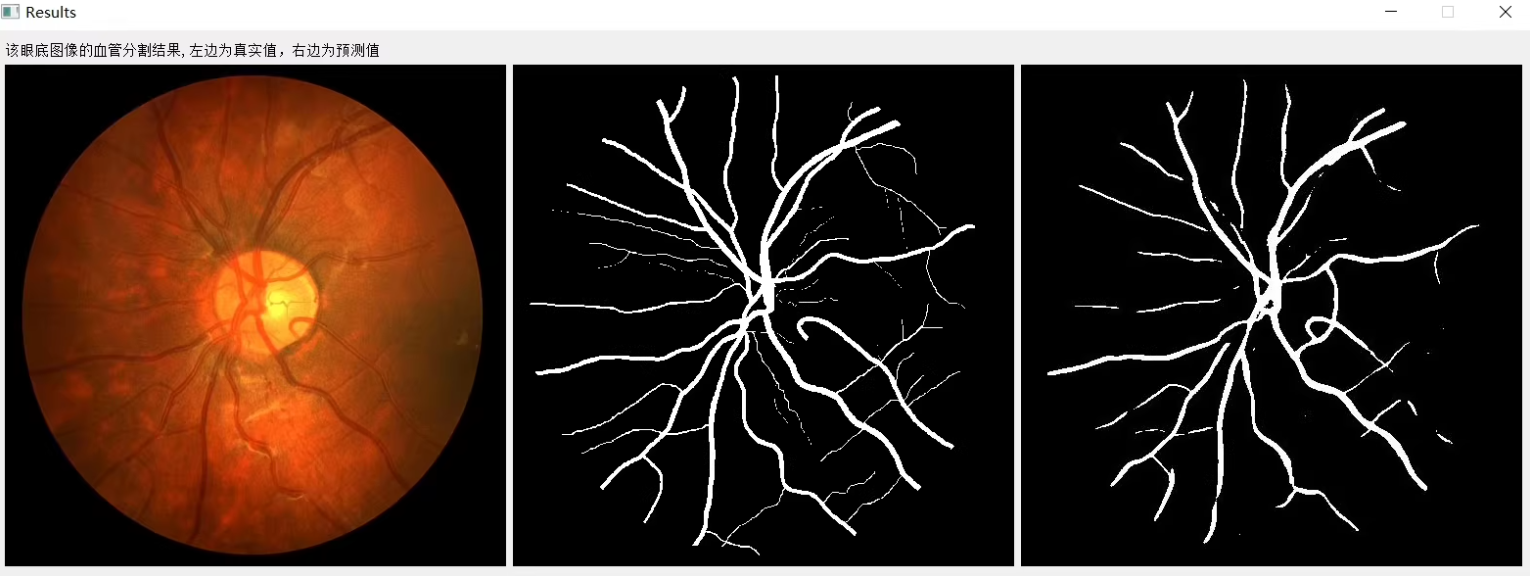
在完成模型训练后,可以使用训练好的模型进行眼底血管图像分割,并将结果可视化。
import matplotlib.pyplot as plt
def evaluate_model(model, test_loader):
model.eval()
with torch.no_grad():
for images, masks in test_loader:
outputs = model(images)
predicted_masks = (outputs > 0.5).float()
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
axs[0].imshow(images[0].permute(1, 2, 0))
axs[0].set_title('Original Image')
axs[1].imshow(masks[0], cmap='gray')
axs[1].set_title('Ground Truth')
axs[2].imshow(predicted_masks[0][0], cmap='gray')
axs[2].set_title('Predicted Mask')
plt.show()
# 使用测试数据集评估模型
evaluate_model(model, test_loader)
以上代码仅供参考。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









