






深度学习目标检测框架训练使用Wider Face人脸检测数据集 _YOLO(You Only Look Once)系列算法进行人脸识别检测任务
Wider Face人脸检测数据集
voc和yolo两种格式,yolo
标注face
训练集:12876
验证集:3226
测试集:8049

1
1

1

1

1


1

针对Wider Face人脸检测数据集,、使用YOLO(You Only Look Once)系列算法进行人脸检测任务,并且数据集已经提供YOLO格式的标注文件,、准备数据、训练模型、评估性能以及一些优化策略。
数据准备
假设您的数据和标签已经按照YOLO的要求组织好,即每张图像对应一个.txt文件,该文件包含边界框信息。每个.txt文件中的每一行代表一个对象,格式如下:
class_id center_x center_y width height
所有值都是相对于图像尺寸归一化后的浮点数。确保你的数据集按照以下结构组织:
wider_face_dataset/
├── images/
│ ├── train/
│ ├── val/
│ └── test/
└── labels/
├── train/
├── val/
└── test/
并且有一个配置文件data.yaml来定义数据集路径和类别信息:
train: ./wider_face_dataset/images/train/
val: ./wider_face_dataset/images/val/
nc: 1 # 类别数量,这里是1因为只检测face
names: ['face'] # 类别名
模型训练
以YOLOv5为例进行模型训练。首先确保你已经安装了YOLOv5的相关依赖。可以从GitHub上克隆YOLOv5仓库并安装依赖:
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -r requirements.txt
然后,开始训练过程:
from ultralytics import YOLO
def main_train():
model = YOLO('yolov5s.yaml') # 或者选择其他预训练模型,例如 'yolov5m.pt', 'yolov5l.pt', 'yolov5x.pt'
results = model.train(
data='./path/to/data.yaml', # 替换为你的data.yaml路径
epochs=300,
imgsz=640, # 根据需要调整图像大小
batch=16, # 根据你的硬件条件调整batch size
project='./runs/detect',
name='wider_face_detection',
optimizer='SGD',
device='0', # 使用GPU编号,'0'表示第一个GPU
save=True,
cache=True,
)
if __name__ == '__main__':
main_train()
模型评估
在训练完成后,可以使用验证集对模型进行评估:
from ultralytics import YOLO
model = YOLO('./runs/detect/wider_face_detection/weights/best.pt')
metrics = model.val(data='./path/to/data.yaml')
print(metrics.box.map) # 输出mAP值等指标
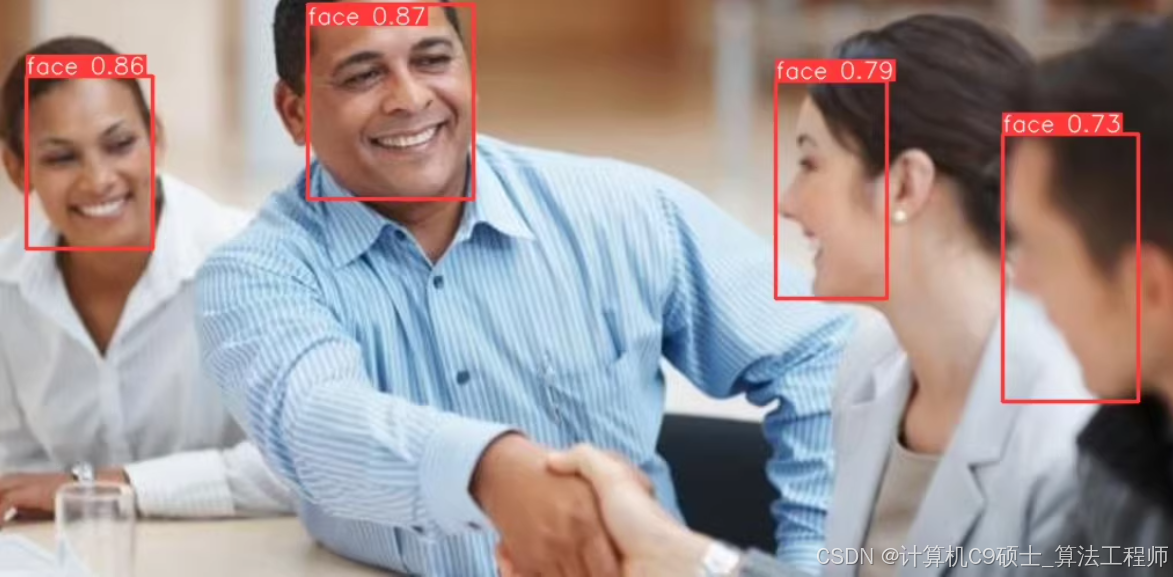
推理与可视化
加载训练好的模型进行推理,并可视化结果:
from ultralytics import YOLO
import cv2
from PIL import Image
model = YOLO('./runs/detect/wider_face_detection/weights/best.pt')
def detect_faces(image_path):
results = model.predict(source=image_path)
img = cv2.imread(image_path)
for result in results:
boxes = result.boxes.numpy()
for box in boxes:
r = box.xyxy
x1, y1, x2, y2 = int(r[0]), int(r[1]), int(r[2]), int(r[3])
label = result.names[int(box.cls)]
confidence = box.conf
if confidence > 0.5: # 设置置信度阈值
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2) # 绘制矩形框
cv2.putText(img, f'{label} {confidence:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
return img
# 示例调用
result_image = detect_faces('your_test_image.jpg')
Image.fromarray(cv2.cvtColor(result_image, cv2.COLOR_BGR2RGB)).show() # 使用PIL显示图像


















 435
435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









