






2024深度学习发论文&模型涨点之——特征选择
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
特征选择(Feature Selection)涉及到从原始特征集中选择最相关、最有信息量的特征子集,能剔除不相关(irrelevant)或冗余(redundant )的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。
我整理了一些特征选择【论文+代码】合集,需要的同学公人人人号【AI创新工场】自取
论文精选
论文1:
【Nature子刊】DUBStepR is a scalable correlation-based feature selection method for accurately clustering single-cell data
DUBStepR:一种可扩展的基于相关性的特征选择方法,用于准确聚类单细胞数据
方法
-
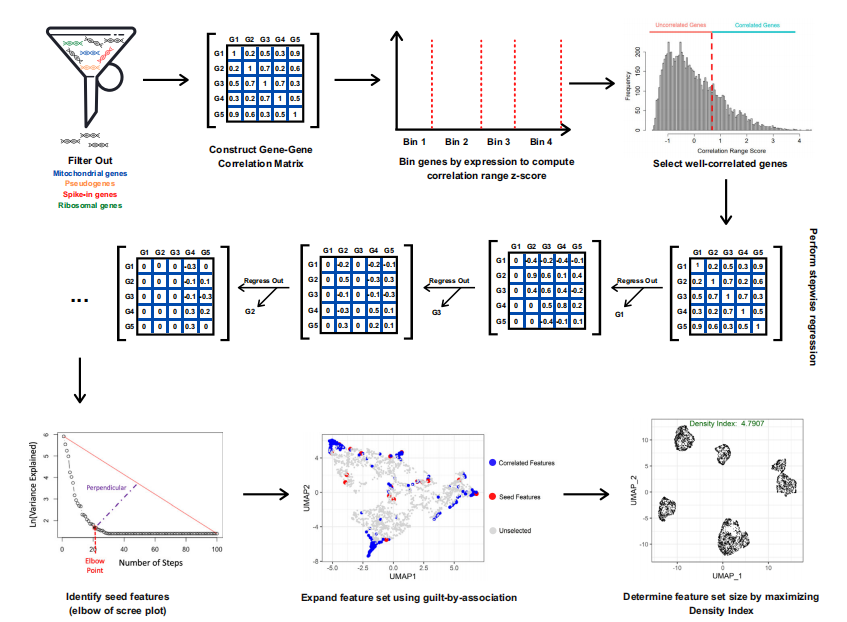
基因-基因相关性分析:通过构建基因-基因相关性(GGC)矩阵,利用基因间的相关性信息进行特征选择。
-
逐步回归(Stepwise Regression):采用逐步回归方法识别一个初始的核心基因集,这些基因最能代表数据集中的一致性表达变化。
-
密度指数(Density Index, DI):定义了一种基于图的细胞聚合度量,用于优化特征数量。
-
相关性范围分数(Correlation Range Score):基于基因最强正相关和最强负相关系数之间的差异来选择候选特征基因。
-
罪责关联(Guilt-by-Association):通过迭代添加与候选特征集中的种子基因集高度相关的基因来扩展特征集。
创新点
-
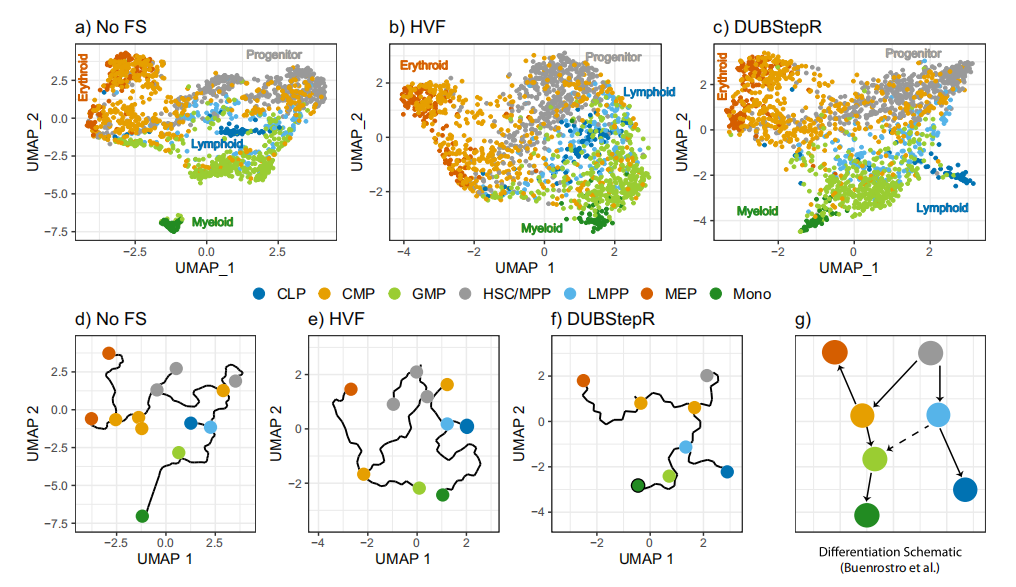
基因-基因相关性利用:DUBStepR通过利用基因间的相关性信息,改进了传统的单细胞数据特征选择方法,这些传统方法通常忽视了这些信息。
-
密度指数(DI):提出了一种新的度量方法,用于在不知道真实细胞类型标签的情况下,优化特征集的大小,以提高聚类效果。
-
可扩展性:DUBStepR能够扩展到超过一百万细胞的数据集,对于处理大规模单细胞数据集具有重要意义。
-
罪责关联方法:通过罪责关联方法,DUBStepR能够优先选择更能代表表达特征的基因,提高了聚类的准确性。
-
跨数据类型的适用性:DUBStepR不仅适用于单细胞RNA测序数据,还有潜力应用于单细胞ATAC测序数据,显示了其广泛的适用性。
论文2:
【Nature子刊】An interpretable deep-learning architecture of capsule networks for identifying cell-type gene expression programs from single-cell RNA-sequencing data
用于从单细胞RNA测序数据中识别细胞类型基因表达程序的可解释胶囊网络深度学习架构
方法
-
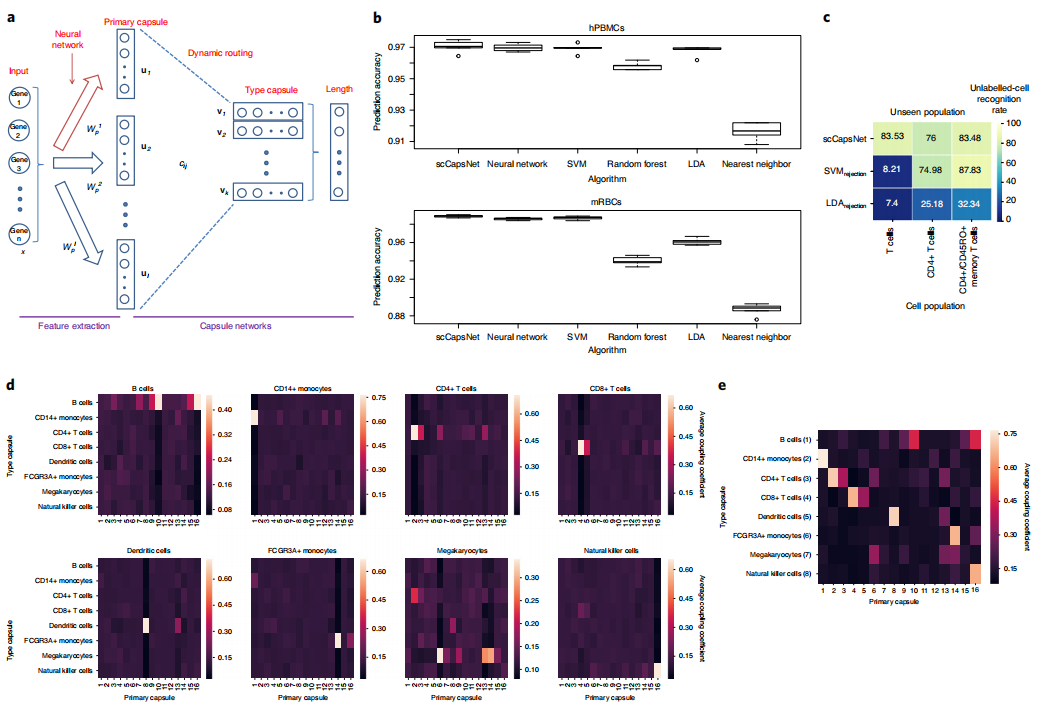
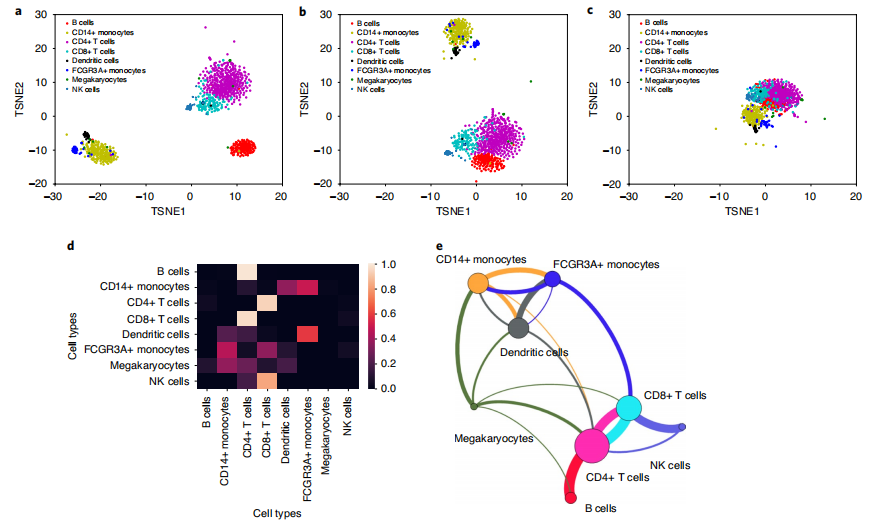
胶囊网络结构:设计了一个包含特征提取模块和胶囊网络模块的深度学习架构,用于单细胞类型的识别。
-
动态路由(Dynamic Routing):在胶囊网络中,通过迭代动态路由算法传递特征,实现从初级胶囊到类型胶囊的转换。
-
内部权重参数分析:通过分析模型内部的权重参数,定义一组核心基因,这些基因集合能够识别具有相同细胞类型的单细胞群组。
-
主成分分析(PCA):利用PCA在内部权重参数上定义核心基因集,这些基因集对于识别特定细胞类型至关重要。
创新点
-
胶囊网络的可解释性:通过分析胶囊网络内部的权重参数,提高了深度学习模型在单细胞数据分析中的可解释性。
-
核心基因集的识别:提出了一种新的方法来识别对于特定细胞类型识别至关重要的核心基因集。
-
跨数据集的稳定性:scCapsNet在不同的单细胞RNA测序数据集上展现出稳定的性能,证明了其在单细胞类型识别中的泛化能力。
-
拒绝选项评估:scCapsNet模型包括一个拒绝选项,能够识别在训练过程中未见过的细胞类型,提高了模型的实用性。
-
基因调控模块的识别:scCapsNet能够识别在功能上密切相关但呈现不同表达模式的基因调控模块,为理解细胞类型的基因表达程序提供了新的视角。
论文3:
Feature selection in machine learning: A new perspective
机器学习中的特征选择:新视角
方法
-
特征选择评估措施:讨论了特征选择中常用的几种评估措施,包括相关性、欧几里得距离、一致性、依赖性和信息度量。
-
监督、无监督和半监督特征选择方法:调查了在机器学习问题中广泛应用的特征选择方法,如分类和聚类。
-
特征选择模型分类:根据使用的训练数据(标记、未标记或部分标记)、与学习方法的关系、评估标准、搜索策略和输出类型对特征选择方法进行分类。
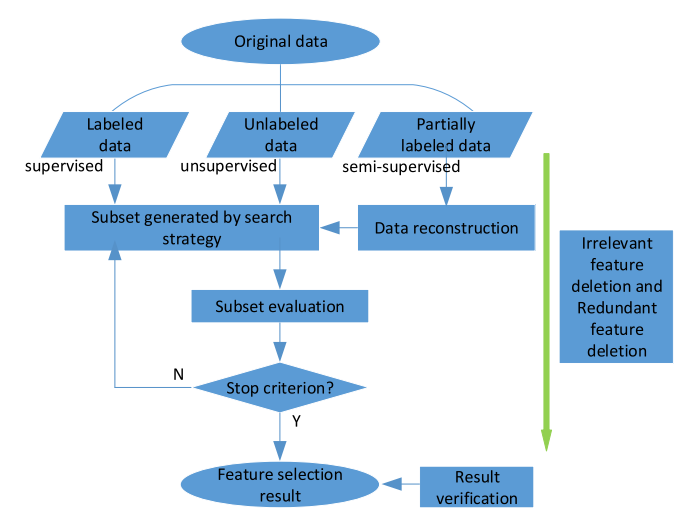
创新点
-
多角度特征选择方法综述:提供了一个统一的框架,用于理解监督、无监督和半监督特征选择方法。
-
特征选择与降维技术比较:明确区分了特征选择和特征提取两种降维技术,并讨论了它们的应用场景和优势。
-
未来挑战的讨论:探讨了特征选择领域的未来挑战,包括极端数据集的特征选择和集成特征选择方法的发展。
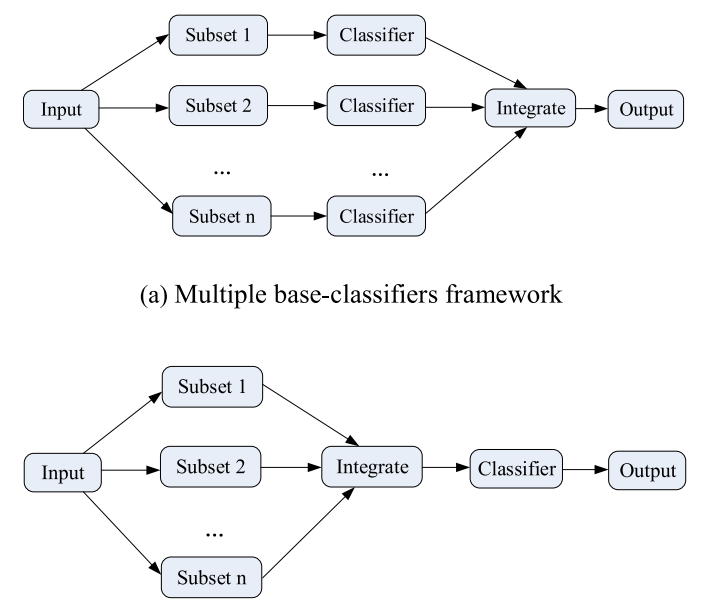
论文4:
Feature Selection Using Principal Component Analysis
使用主成分分析的特征选择
方法
-
遗传算法(GA):应用遗传算法优化子集与完整数据集之间的一致性,避免穷举搜索。
-
广义Procrustes分析:通过广义Procrustes分析中的一致性百分比来衡量信息。
-
主成分分析(PCA):用于研究数据结构,通过最大化数据的方差获得新的正交变量。
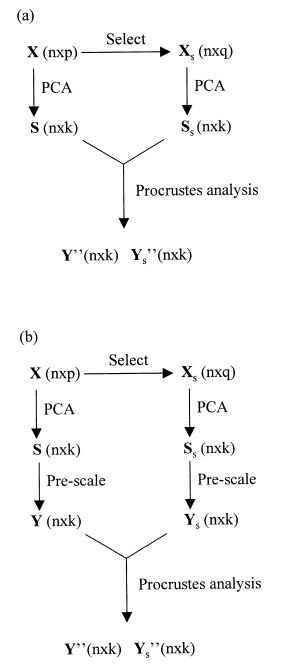
创新点
-
结构信息保留:提出了一种新的特征选择方法,能够在PCA中选择变量子集,同时尽可能保留完整数据中的信息。
-
遗传算法的应用:使用遗传算法代替逐步淘汰过程,提高了在高维数据中寻找最佳变量子集的效率。
-
一致性百分比的引入:通过引入一致性百分比,提供了一种更直观的方法来评估和比较数据结构,使得结果更容易解释。

















 2286
2286

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









