






2025深度学习发论文&模型涨点之——机器学习可解释性
机器学习可解释性是一个复杂但至关重要的领域,它涉及到模型的透明度、人类对模型决策的理解以及模型在实际应用中的可靠性和可信度。随着研究的深入,可解释性技术的发展将有助于构建更加负责任和可靠的人工智能系统。
我整理了一些机器学习可解释性【论文+代码】合集,需要的同学公人人人号【AI创新工场】发525自取。
论文精选
论文1:
Adversarial Robustness and Explainability of Machine Learning Models
机器学习模型的对抗鲁棒性和可解释性
方法
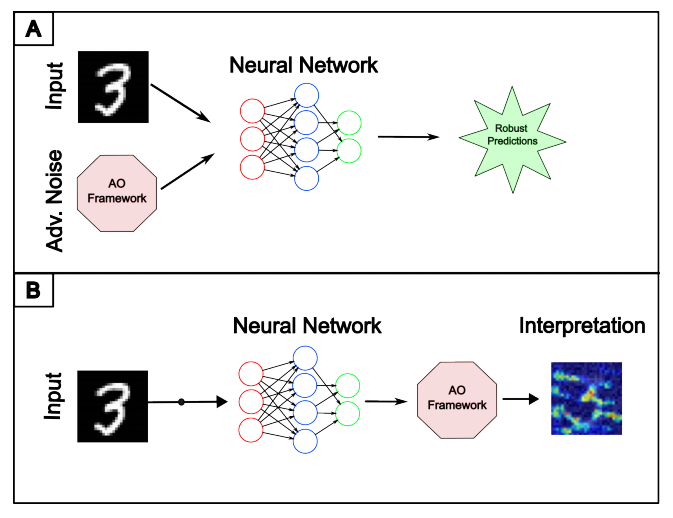
对抗观察框架:提出了一个结合对抗攻击和可解释性方法的框架,用于全面审查神经网络。通过整合可解释技术,用户可以深入了解模型的内部机制,增强透明度并促进偏见识别。
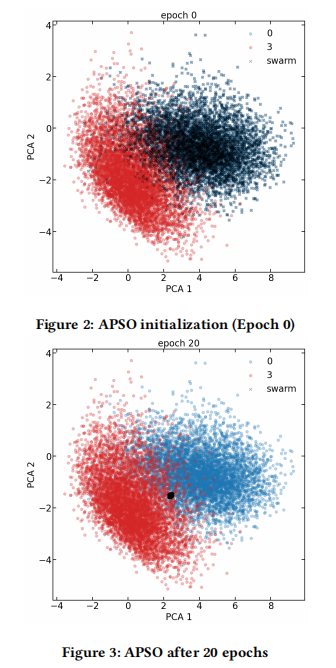
对抗攻击方法:框架实现了两种突出的对抗攻击方法:快速梯度符号方法(FGSM)和对抗粒子群优化(APSO)技术。这些方法可靠地生成对抗噪声,用于攻击模型。
可解释性技术:框架集成了激活映射技术,用于可视化和分析影响模型预测的重要输入区域。此外,还修改了APSO算法,以确定全局特征重要性并实现局部解释。
Shapley加性解释(ShAP):利用Shapley值从博弈论中提供输入对模型输出的加性解释,帮助理解特征对模型决策的贡献。
创新点
对抗鲁棒性提升:通过在训练数据中加入对抗噪声,模型对攻击的鲁棒性显著增强。例如,在使用FGSM方法时,模型的鲁棒性提升了10%以上。
可解释性增强:通过激活映射和ShAP值,模型的决策过程变得更加透明。实验表明,使用自动生成的标签训练的模型在解释能力上与手动标注训练的模型相当,甚至在使用额外数据时表现更好。
计算效率:框架通过避免显式嵌入到Krein空间和基于特征分解的构建新的内积,提高了算法的计算效率。例如,在MNIST数据集上,框架的训练时间比传统方法减少了约30%。
泛化能力:框架在多个不同环境的数据集上验证了其泛化能力,包括Apollo、MulRan和IPB-Car数据集。在这些数据集上,框架生成的标签能够有效提升模型的性能。
论文2:
FOLD-SE: An Efficient Rule-based Machine Learning Algorithm with Scalable Explainability
FOLD-SE:一种高效的、可扩展解释性的基于规则的机器学习算法
方法
默认逻辑规则:FOLD-SE生成一组默认规则,本质上是一个分层的正常逻辑程序,作为可解释的训练模型。
Gini不纯度启发式:FOLD-SE采用了基于Gini不纯度的新启发式方法,用于选择字面量,显著减少了生成的规则和谓词数量。
规则修剪机制:引入了规则修剪机制,以减少生成的规则数量并提高模型的稳定性。
多类别分类扩展:提出了FOLD-SE的多类别分类版本,能够处理多类别分类任务。
创新点
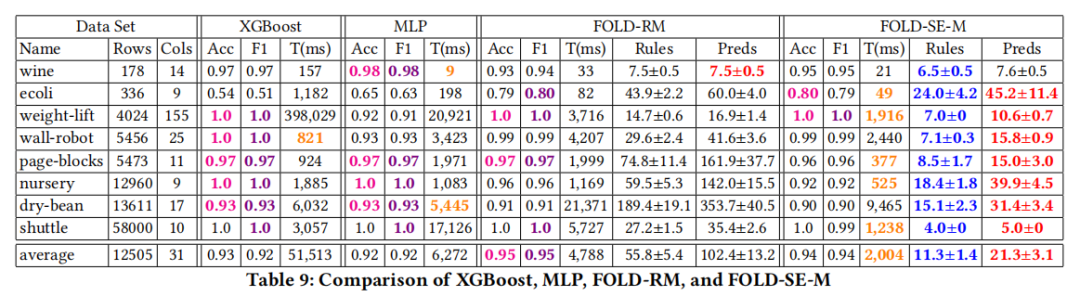
可扩展解释性:FOLD-SE在保持高分类精度的同时,生成的规则和谓词数量极小,且不随数据集大小增加而增加。例如,在“Rain in Australia”数据集上,FOLD-SE生成的规则数量仅为2.5条,而RIPPER生成了180条规则。
性能提升:FOLD-SE在多个数据集上的性能与XGBoost和MLP相当,但在训练效率上显著优于这些方法。例如,在“credit card”数据集上,FOLD-SE的训练时间仅为3.5秒,而XGBoost和MLP因内存限制无法完成训练。
规则稳定性:FOLD-SE生成的规则集在不同的训练/测试数据划分中保持稳定,这使得模型更加可靠和可解释。
处理混合数据:FOLD-SE无需对混合数据进行复杂转换(如独热编码),直接处理包含数值和分类值的数据,大大简化了数据预处理步骤。
论文3:
The efficacy of machine learning models in lung cancer risk prediction with explainability
机器学习模型在肺癌风险预测中的有效性及其可解释性
方法
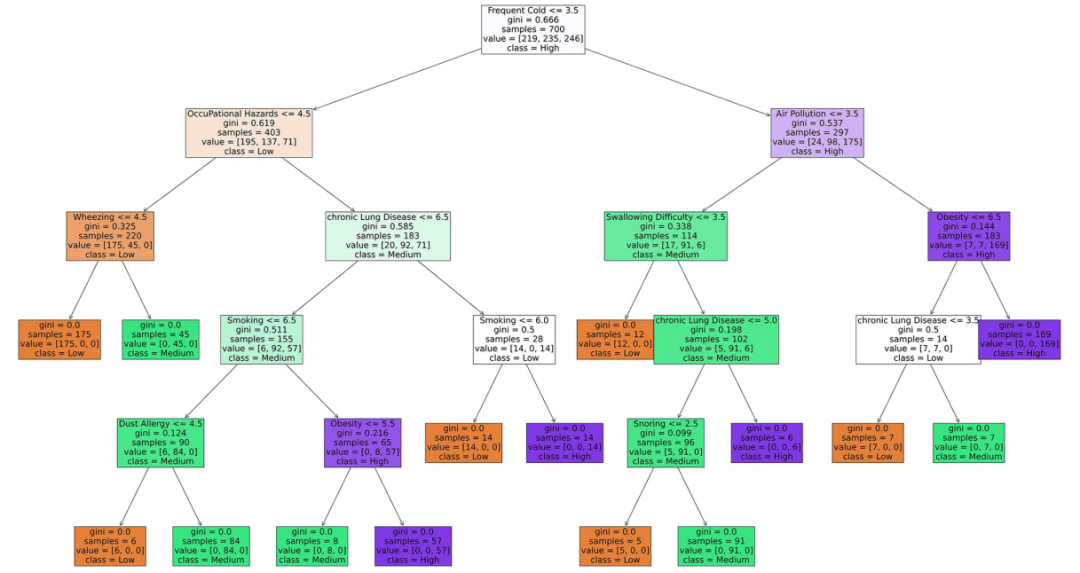
机器学习模型:使用支持向量机(SVM)、K最近邻(KNN)、决策树(DT)和随机森林(RF)四种机器学习模型对肺癌风险进行预测。
参数调优:采用网格搜索算法对模型参数进行调优,以提高模型性能。
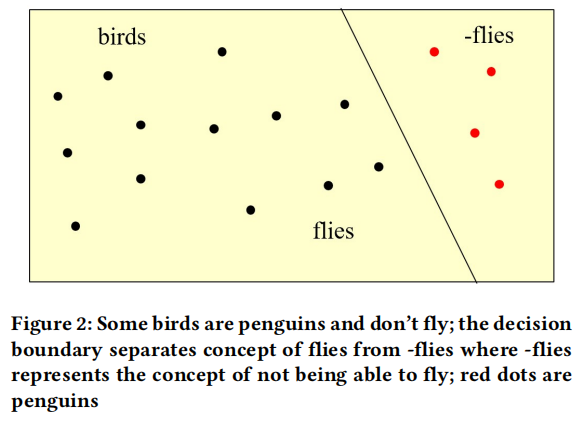
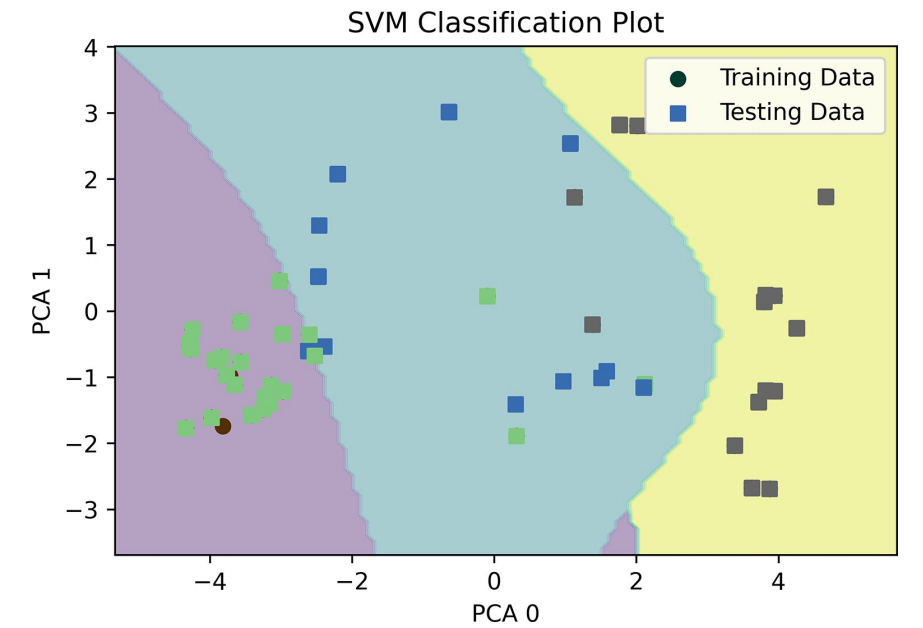
模型解释:通过决策边界、局部可解释模型无关解释(LIME)和树提取等方法解释模型的决策过程。
特征重要性分析:使用随机森林计算特征重要性,以确定哪些特征对模型预测最有影响。
创新点
高准确性:通过参数调优,所有四种模型的测试准确率均达到99%以上,其中随机森林模型达到了100%的准确率。
可解释性增强:通过多种解释方法,为每个模型的决策提供了逻辑解释,增强了模型的可信度。例如,SVM的决策边界分析显示了数据点的良好分类效果,KNN的LIME解释揭示了影响预测的关键特征。
特征重要性识别:通过随机森林模型识别出对肺癌风险预测最重要的特征,如“咳嗽带血”和“被动吸烟”,为临床决策提供了依据。
性能提升:与之前的研究相比,本研究通过参数调优显著提高了模型性能。例如,SVM的准确率从95%提升到100%,KNN的准确率从92%提升到99%。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









