






力扣82.删除排序链表中的重复元素
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
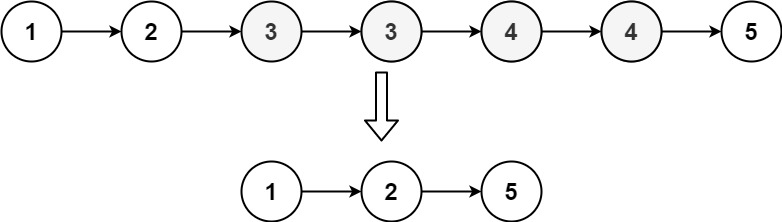
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]
示例 2:
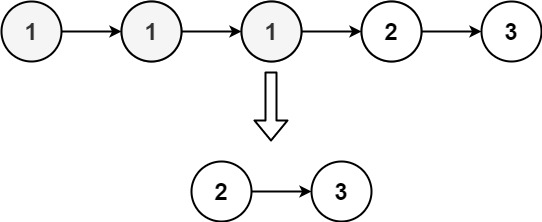
输入:head = [1,1,1,2,3]
输出:[2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
题目分析
找到所有重复的元素并在链表中删除。需要用到双指针。
解题思路
这道题不是单纯的删除重复的其中之一个元素,而是要把重复的元素全部删除。我们在遍历链表时需要格外注意这一点。我们的初步思路就是建立虚拟头结点,双指针,首先用pre为cur定位,用cur进行删除操作。因此我们用cur指针遍历链表,每次循环都将cur移动到pre下一个节点的位置。为了找出链表是从什么地方开始重复的,我们使用一个if判断。判断的内容为cur与cur下一节点的值是否相同,并且cur的下一节点不能为空。如果不满足判断条件,直接移动pre到下一节点即可。
如果满足条件,进入if后,我们首先要新建一个node指针来保存cur的位置,因为接下来我们就要移动node,并将node值与cur值进行比较。此时我们使用的是while循环而不是if判断,因为我们无法确定接下来还有多少个节点值是重复的,所以我们不能使用单次判断,而是用while进行多次判断。并且此时我们的判断条件不能是判断node的下一节点是非为空,因为node下一节点是非为空,并不影响我们对于多次重复元素的筛选。反而,如果写成node->next!=NULL,面对{1,2,3,3}这种例子,就会在循环到node指向第二个3时不满足条件而终止循环,从而就会漏删最后一个重复元素。因此我们可以得知,循环条件是非常重要的,多加一个少加一个都会对最后运行结果产生很大的影响。
node的循环结束后,我们让pre直接指向node,就可以把重复值都跳过了。最后返回虚拟头结点ahead的下一节点即可。最后,备注一个点,就是关于虚拟头结点的创建。我们可以像下面展示的一样,先将struct listnode重命名,然后只用写ListNode* ahead=malloc(sizeof(ListNode));即可。如果不进行重命名,就需要写 struct ListNode*ahead=(struct ListNode*)malloc(sizeof(struct ListNode)); ,两种写法需要分清楚。
代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head) {
typedef struct ListNode ListNode;
ListNode* ahead=malloc(sizeof(ListNode));
ahead->next=head;
struct ListNode* pre=ahead;
struct ListNode* cur=ahead->next;
while(cur!=NULL){
if(cur->next!=NULL&&cur->val==cur->next->val){
struct ListNode* node=cur;
while(node!=NULL&&node->val==cur->val){
node=node->next;
}
pre->next=node;
}
else{
pre=pre->next;
}
cur=pre->next;
}
return ahead->next;
}
力扣19.删除链表的倒数第N个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:
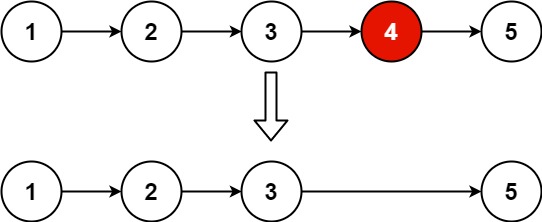
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]
示例 2:
输入:head = [1], n = 1
输出:[]
示例 3:
输入:head = [1,2], n = 1
输出:[1]
提示:
- 链表中结点的数目为
sz 1 <= sz <= 300 <= Node.val <= 1001 <= n <= sz
**进阶:**你能尝试使用一趟扫描实现吗?
题目分析
前后双指针遍历链表,后指针删除倒数第N个节点。
解题思路
在这道题中,我们需要找到倒数第N个节点并且删掉它,我们首先就会想到双指针。我们可以总结出来一个规律,凡是链表题里面涉及到找某个节点的,我们都可以使用双指针,这是双指针最基础的考法。我们首先设置一个虚拟头结点,方便我们对前后指针进行操作。我们将前指针指向head,后指针指向虚拟头指针。为什么这一步操作前后指针的起点不一样呢?原因就在于链表删除节点的方式比较特别。我们要删除某个节点,我们必须要知道它前一个节点的地址,移动前一个节点的指针,因此在前后指针移动完毕的时候,后指针其实需要指向倒数第n+1个节点。
那又有一个疑问了,为什么不让前指针多移动一个节点呢?这样前后指针的起点就都会在head处了,不需要再设虚拟头结点了。其实是不可行的,虚拟头结点是一定要设的,前后指针的起点也一定是不一样的。原因就在于对前指针先走几步的移动上。我们这个移动采用的是for循环,因为次数更可控。如果我们的测试用例为{1},1,如果我们按照上文所说,让前指针多移动一个节点,那就会访问到空节点,就会导致程序报错。因此,为避免以上情况的发生,我们要采用虚拟头结点帮助我们进行后指针的移动。最后输出虚拟头结点的下一个节点即可。
代码实现
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* removeNthFromEnd(struct ListNode* head, int n) {
struct ListNode* dummy = malloc(sizeof(struct ListNode));
dummy->val = 0;
dummy->next = head;
struct ListNode* fast = head;
struct ListNode* slow = dummy;
for (int i = 0; i < n; ++i) {
fast = fast->next;
}
while (fast) {
fast = fast->next;
slow = slow->next;
}
slow->next = slow->next->next;
return dummy->next;
}

















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









